




MLPerf™ Inference 3.1 on Dell PowerEdge Server with Intel® 4th Generation Xeon® CPU


Introduction
MLCommons™ has released the v3.1 results for its machine learning inference benchmark suite, MLPerf™. This blog focuses on the impressive datacenter inference results obtained across different use cases by using the new 4th Generation Intel Xeon Scalable Processors on a Dell PowerEdge R760 server. This submission covers the benchmark results for all 7 use cases defined in MLPerf™, which are Natural Language Processing (BERT), Image Classification (ResNet50), Object Detection (RetinaNet), Speech-to-Text (RNN-T), Medical Imaging (3D-Unet), Recommendation Systems (DLRMv2), and Summarization (GPT-J).
These new Intel® Xeon® processors use an Intel AMX® matrix multiplication engine in each core to boost overall inferencing performance. With a focus on ease of use, Dell Technologies delivers exceptional CPU performance results out of the box with an optimized BIOS profile that fully unleashes the power of Intel’s OneDNN software – software which is fully integrated with both PyTorch and TensorFlow frameworks. The server configurations and the CPU specifications in the benchmark experiments are shown in Tables 1 and 2 respectively.
System Name | PowerEdge R760 |
Status | Available |
System Type | Data Center |
Number of Nodes | 1 |
Host Processor Model | 4th Generation Intel® Xeon® Scalable Processors |
Host Processors per Node | 2 |
Host Processor Core Count | 56 |
Host Processor Frequency | 2.0 GHz, 3.8 GHz Turbo Boost |
Host Memory Capacity | 1TB, 16 x 64GB DIMM 4800 MHz |
Host Storage Capacity | 4.8 TB, NVME |
Table 1. Dell PowerEdge R760 Server Configuration
Product Collection | 4th Generation Intel® Xeon® Scalable Processors |
Processor Name | Platinum 8480+ |
Status | Launched |
# of CPU Cores | 56 |
# of Threads | 112 |
Base Frequency | 2.0 GHz |
Max Turbo Speed | 3.8 GHz |
Cache L3 | 105 MB |
Memory Type | DDR5 4800 MT/s |
ECC Memory Supported | Yes |
Table 2. 4th Generation Intel® Xeon® Scalable Processor Technical Specifications
MLPerf™ Inference v3.1 - Datacenter
The MLPerf™ inference benchmark measures how fast a system can perform ML inference using a trained model with new data in a variety of deployment scenarios. There are two benchmark suites – one for Datacenter systems and one for Edge. Table 3 lists the 7 mature models with each targeting a different task in the official release v3.1 for Datacenter systems category that were run on this PowerEdge R760. Compared to the v3.0 release, v3.1 added the updated version of the recommendation model – DLRMv2 – and introduced the first Large-Language Model (LLM) – GPT-J.
Area | Task | Model | Dataset | QSL Size | Quality | Server latency constraint |
Vision | Image classification | ResNet50-v1.5 | ImageNet (224x224) | 1024 | 99% of FP32 (76.46%) | 15 ms |
Vision | Object detection | RetinaNet | OpenImages (800x800) | 64 | 99% of FP32 (0.20 mAP) | 100 ms |
Vision | Medical imaging | 3D-Unet | KITS 2019 (602x512x512) | 16 | 99.9% of FP32 (0.86330 mean DICE score) | N/A |
Speech | Speech-to-text | RNN-T | Librispeech dev-clean (samples < 15 seconds) | 2513 | 99% of FP32 (1 - WER, where WER=7.452253714852645%) | 1000 ms |
Language | Language processing | BERT-large | SQuAD v1.1 (max_seq_len=384) | 10833 | 99% of FP32 and 99.9% of FP32 (f1_score=90.874%) | 130 ms |
Language | Summarization | GPT-J-99 | CNN Dailymail (v3.0.0, max_seq_len=2048) | 13368 | 99% of FP32 (f1_score=80.25% rouge1=42.9865, rouge2=20.1235, rougeL=29.9881). | 20 s |
Commerce | Recommendation | DLRMv2 | Criteo 4TB Multi-hot | 204800 | 99% of FP32 (AUC=80.25%) | 60 ms |
Table 3. Datacenter Suite Benchmarks. Source: MLCommons™
Scenarios
The models are deployed in a variety of critical inference applications or use cases known as “scenarios” where each scenario requires different metrics, demonstrating production environment performance in practice. Following is the description of each scenario. Table 4 shows the scenarios required for each Datacenter benchmark included in this submission v3.1.
Offline scenario: represents applications that process the input in batches of data available immediately and do not have latency constraints for the metric performance measured in samples per second.
Server scenario: represents deployment of online applications with random input queries. The metric performance is measured in queries per second (QPS) subject to latency bound. The server scenario is more complicated in terms of latency constraints and input queries generation. This complexity is reflected in the throughput-degradation results compared to the offline scenario.
Each Datacenter benchmark requires the following scenarios:
Area | Task | Required Scenarios |
Vision | Image classification | Server, Offline |
Vision | Object detection | Server, Offline |
Vision | Medical imaging | Offline |
Speech | Speech-to-text | Server, Offline |
Language | Language processing | Server, Offline |
Language | Summarization | Server, Offline |
Commerce | Recommendation | Server, Offline |
Table 4. Datacenter Suite Benchmark Scenarios. Source: MLCommons™
Software stack and system configuration
The software stack and system configuration used for this submission is summarized in Table 5.
OS | CentOS Stream 8 (GNU/Linux x86_64) |
Intel® Optimized Inference SW for MLPerf™ | MLPerf™ Intel OneDNN integrated with PyTorch |
ECC memory mode | ON |
Host memory configuration | 1TiB |
Turbo mode | ON |
CPU frequency governor | Performance |
Table 5. System Configuration
What is Intel AMX (Advanced Matrix Extensions)?
Intel AMX is a built-in accelerator that enables 4th Gen Intel Xeon Scalable processors to optimize deep learning (DL) training and inferencing workloads. With the high-speed matrix multiplications enabled by Intel AMX, 4th Gen Intel Xeon Scalable processors can quickly pivot between optimizing general computing and AI workloads.
Imagine an automobile that could excel at city driving and then quickly shift to deliver Formula 1 racing performance. 4th Gen Intel Xeon Scalable processors deliver this level of flexibility. Developers can code AI functionality to take advantage of the Intel AMX instruction set as well as code non-AI functionality to use the processor instruction set architecture (ISA).
Intel has integrated the Intel® oneAPI Deep Neural Network Library (oneDNN) – its oneAPI DL engine – into popular open-source tools for AI applications, including TensorFlow, PyTorch, PaddlePaddle, and ONNX.
AMX architecture
Intel AMX architecture consists of two components, as shown in Figure 1:
- Tiles consist of eight two-dimensional registers, each 1 kilobyte in size. They store large chunks of data.
- Tile Matrix Multiplication (TMUL) is an accelerator engine attached to the tiles that performs matrix-multiply computations for AI.
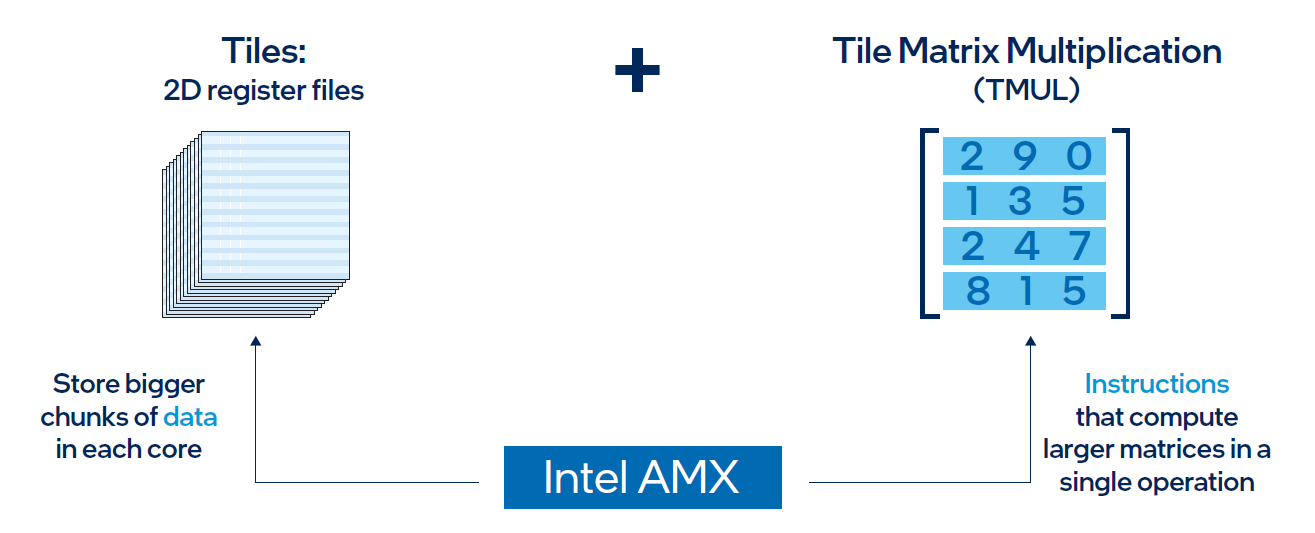
Figure 1. Intel AMX architecture consists of 2D register files (tiles) and TMUL
Results
Both MLPerf™ v3.0 and MLPerf™ v3.1 benchmark results are based on the latest Dell R760 server utilizing 4th Generation Intel® Xeon® Scalable Processors.
For the ResNet50 Image Classification, RetinaNet Object Detection, BERT Large Language, and RNN-T Speech Models – which are identical models with same datasets for both MLPerf™ v3.0 and MLPerf™ v3.1 – we re-run those for the latest submission. The results show negligible differences between two submissions.
We added three new benchmark results for MLPerf™ v3.1 submission compared to MLPerf™ v3.0 submission. Those are 3D-Unet Medical Imaging, DLRMv2 Recommendation, and GPT-J Summarization models. Given that there is no previous result for comparison, we simply show the current result on the R760.
Comparing Performance from MLPerfTM v3.1 to MLPerfTM v3.0
ResNet50 server & offline scenarios:
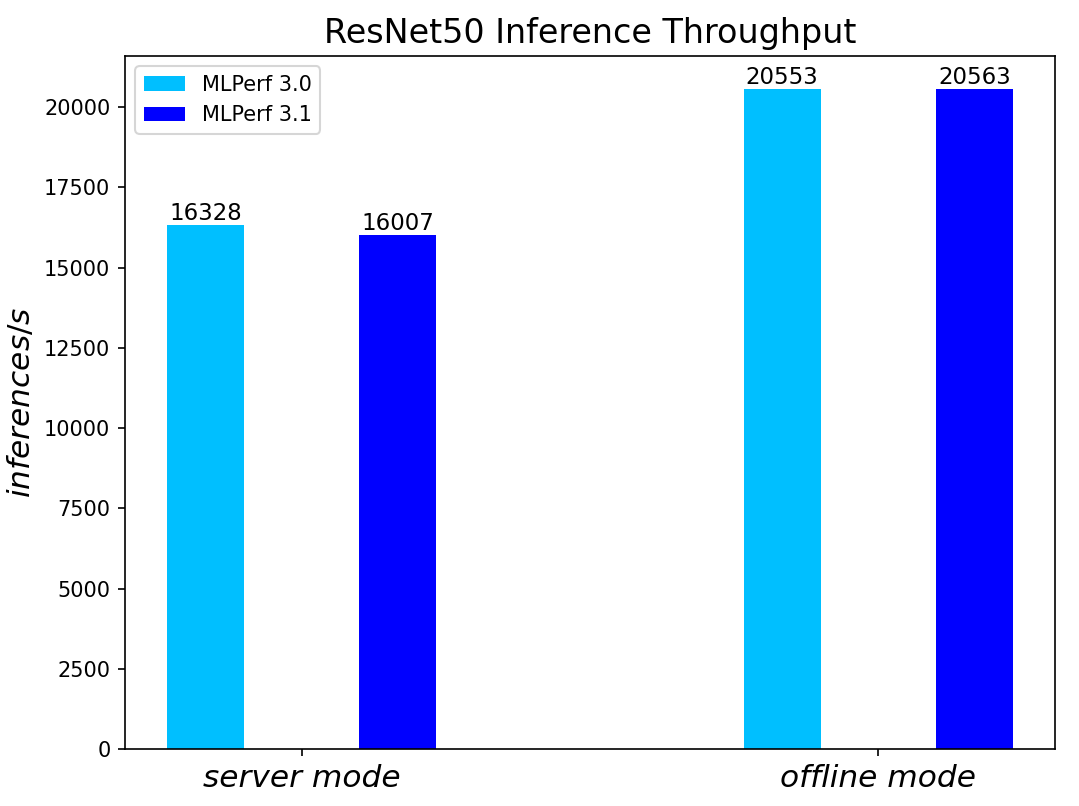
Figure 2. ResNet50 inference throughput in server and offline scenarios
BERT Large Language Model server & offline scenarios:
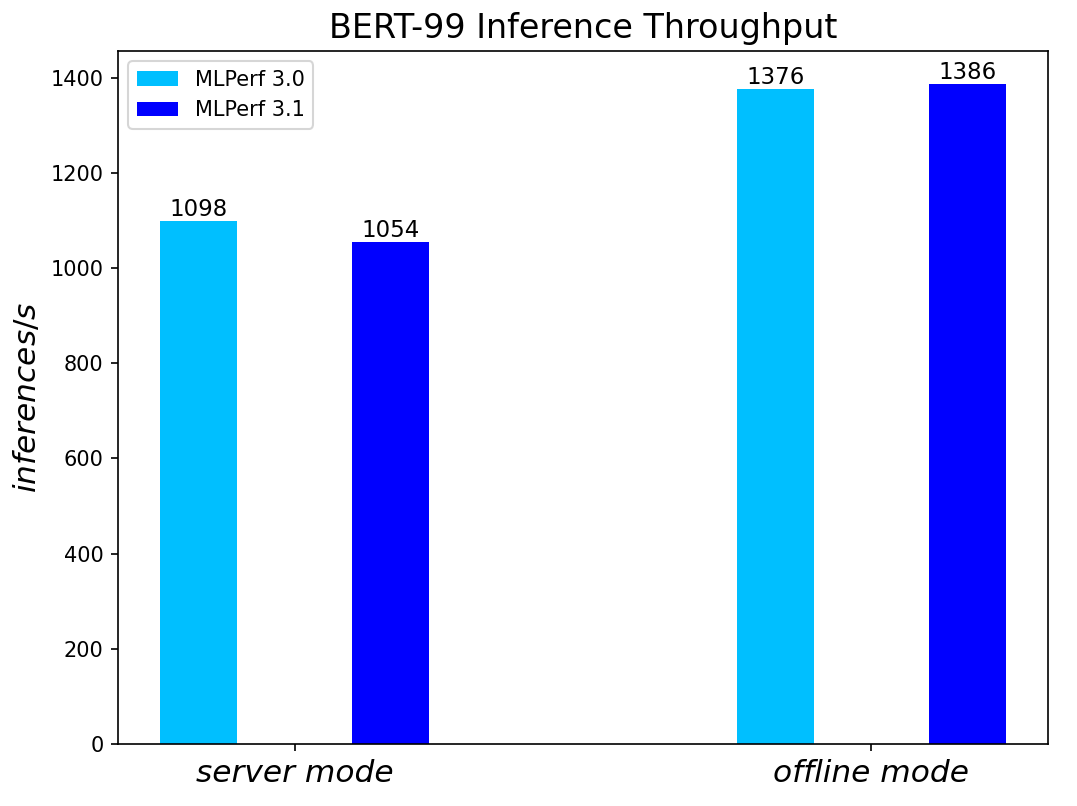
Figure 3. BERT Inference results for server and offline scenarios
RetinaNet Object Detection Model server & offline scenarios:
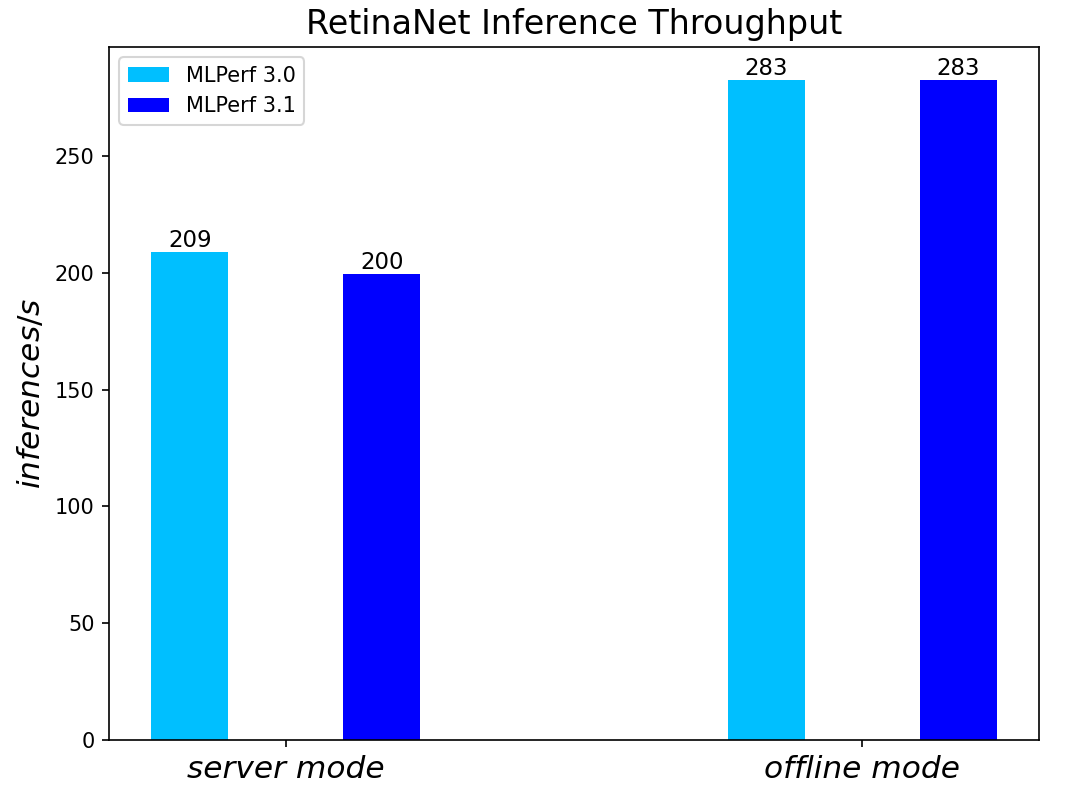
Figure 4. RetinaNet Object Detection Model Inference results for server and offline scenarios
RNN-T Text to Speech Model server & offline scenarios:
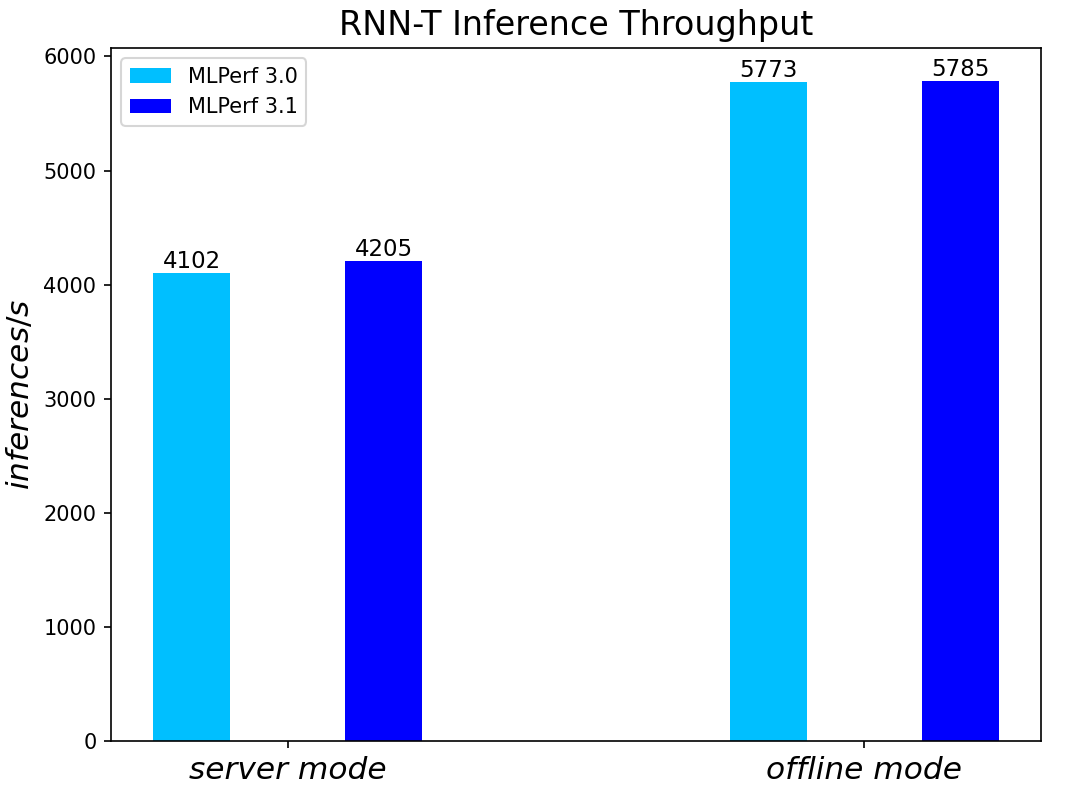
Figure 5. RNN-T Text to Speech Model Inference results for server and offline scenarios
3D-Unet Medical Imaging Model offline scenarios:
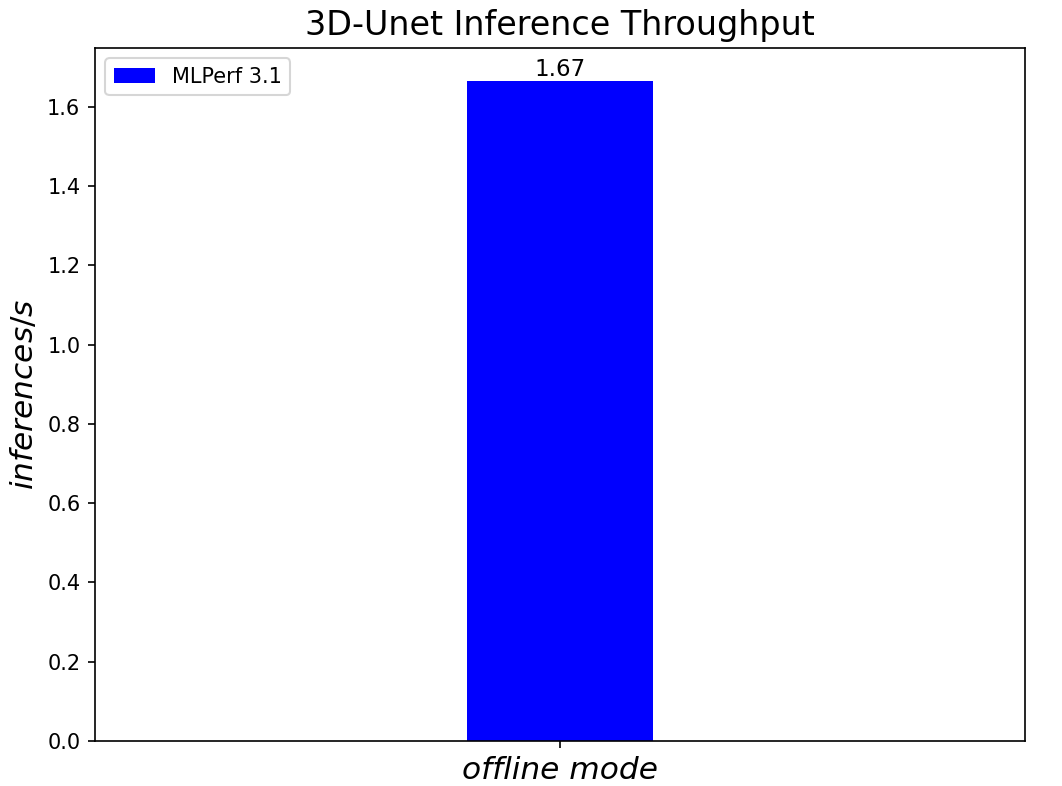
Figure 6. 3D-Unet Medical Imaging Model Inferencing results for server and offline scenarios
DLRMv2-99 Recommendation Model server & offline scenarios:
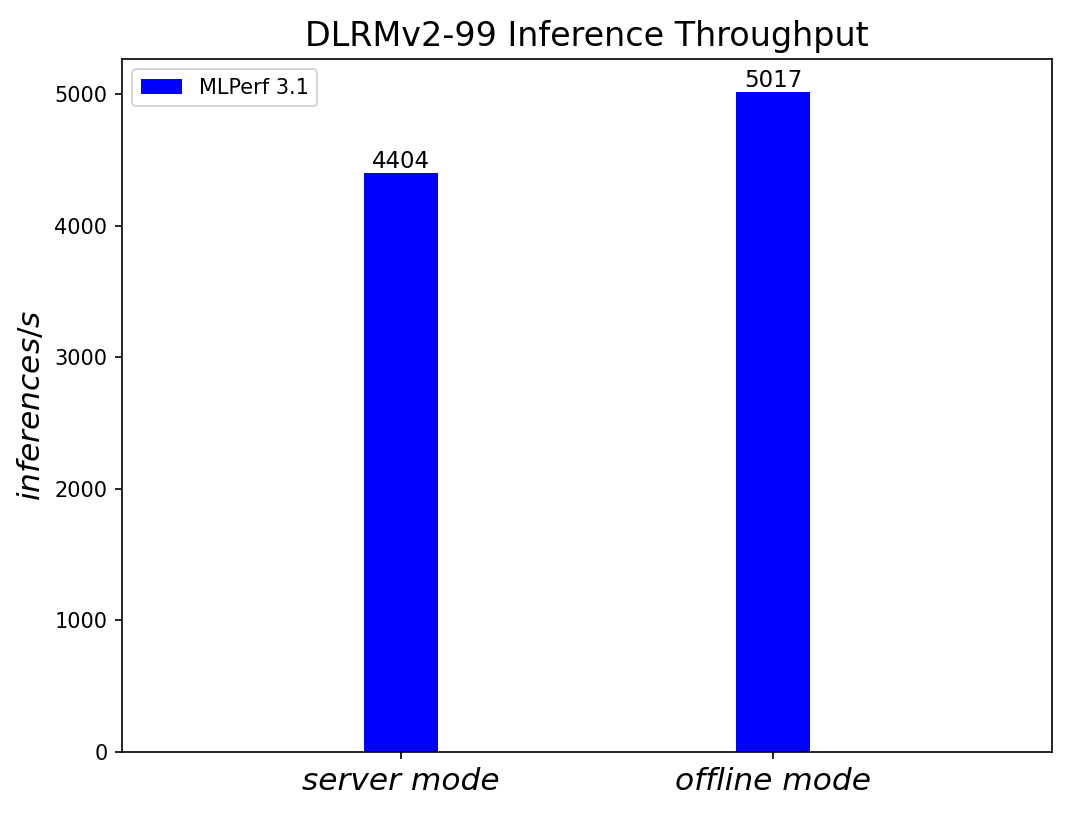
Figure 7. DLRMv2-99 Recommendation Model Inference results for server and offline scenarios (submitted in the open category)
GPT-J-99 Summarization Model server & offline scenarios:
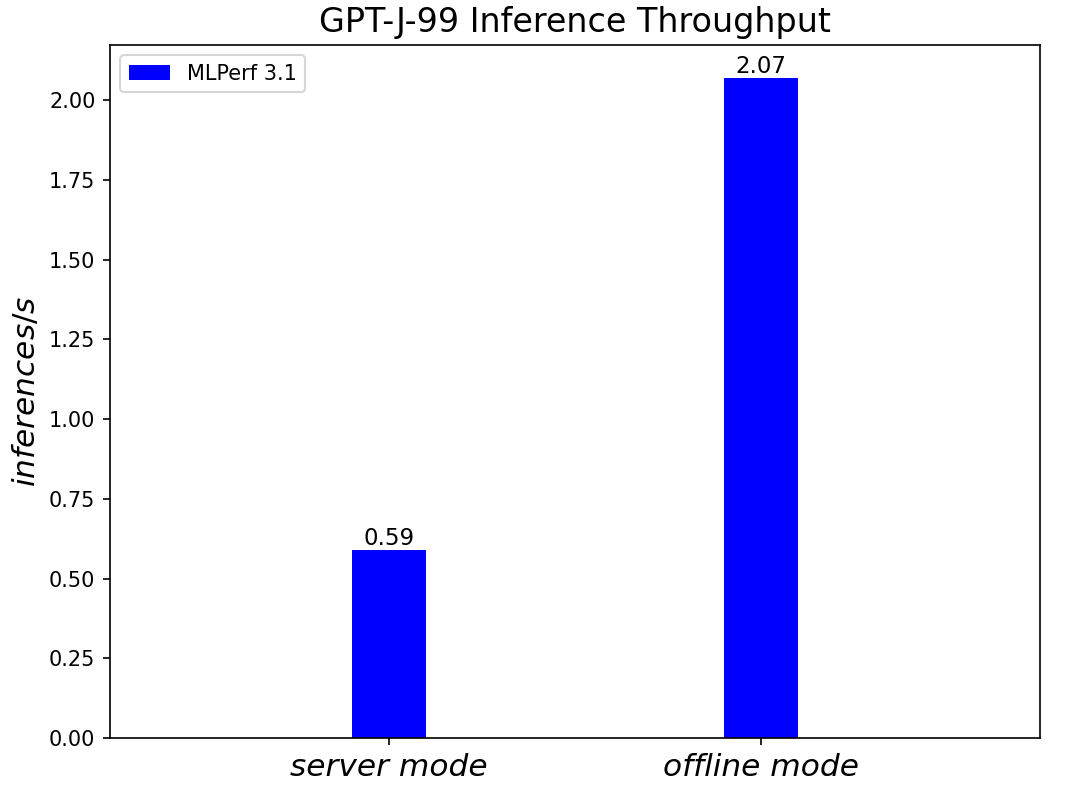
Figure 8. GPT-J-99 Summarization Model Inference results for server and offline scenarios
Conclusion
- The PowerEdge R760 server with 4th Generation Intel® Xeon® Scalable Processors produces strong data center inference performance, confirmed by the official version 3.1 MLPerfTM benchmarking results from MLCommonsTM.
- The high performance and versatility are demonstrated across natural language processing, image classification, object detection, medical imaging, speech-to-text inference, recommendation, and summarization systems.
- The R760 with 4th Generation Intel® Xeon® Scalable Processors show good performance in supporting generative AI models like GPT-J.
- The R760 supports different deep learning inference scenarios in the MLPerfTM benchmark scenarios as well as other complex workloads such as database and advanced analytics. It is an ideal solution for data center modernization to drive operational efficiency, lead higher productivity, and minimize total cost of ownership (TCO).
References
MLCommonsTM MLPerfTM v3.1 Inference Benchmark Submission IDs
ID | Submitter | System |
3.1-0059 | Dell | Dell PowerEdge Server R760 (1x Intel Xeon Platinum 8480+) |
3.1-0060 | Dell | Dell PowerEdge Server R760 (1x Intel Xeon Platinum 8480+) |
3.1-4184 | Dell | Dell PowerEdge Server R760 (1x Intel Xeon Platinum 8480+) |
Authors: Tao Zhang (tao.zhang9@dell.com); Brandt Springman (brandt.springman@dell.com); Bhavesh Patel (bhavesh_a_patel@dell.com); Louie Tsai (louie.tsai@intel.com); Yuning Qiu (yuning.qiu@intel.com); Ramesh Chukka (ramesh.n.chukka@intel.com)