




MLPerf Inference v0.7 Benchmarks on Dell EMC PowerEdge R740xd with Xilinx FPGA
Download PDF
Summary
MLPerf Consortium has released the second round of results v0.7 for its machine learning inference performance benchmark suite. Dell EMC has been participated in this contest in collaboration with several partners and configurations, including inferences with CPU only and with accelerators such as GPU’s and FPGA’s. This blog is focused on the submission results in the open division/datacenter & open division/edge category for the server Dell EMC Power Edge R740xd with Xilinx FPGA, in collaboration with Xilinx.
Introduction
Last week the MLPerf organization released its latest round of machine learning (ML) inference benchmark results. Launched in 2018, MLPerf is made up of an open-source community of over 23 submitting organizations with the mission to define a suite of standardized ML benchmarks. The group’s ML inference benchmarks provide an agreed upon process for measuring how quickly and efficiently different types of accelerators and systems can execute trained neural networks.
This marked the first time Xilinx has directly participated in MLPerf. While there’s a level of gratification in just being in the game, we’re excited to have achieved a leadership result in an image classification category. We collaborated with Mipsology for our submissions in the more rigid “closed” division, where vendors receive pre-trained networks and pre-trained weights for true “apples-to-apples” testing.
The test system used our Alveo U250 accelerator card based on a domain-specific architecture (DSA) optimized by Mipsology. The benchmark measures how efficiently our Alveo-based custom DSA can execute image classification tasks based on the ResNet-50 benchmark with 5,011 image/second in offline mode. ResNet-50 measures image classification performance in images/seconds.
We achieved the highest performance / peak TOP/s (trillions of operations per second). It’s a measure of performance efficiency that essentially means, given a X amount of peak compute in hardware, we delivered the highest throughput performance.
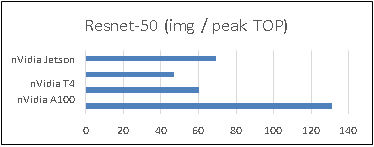
Figure 1: Performance Comparison
The MLPerf results also showed that we achieved 100% of the available TOP/s compared to our published data sheet performance. This impressive result showcases how raw peak TOP/s on paper are not always the best indicator of real-world performance. Our device architectures deliver higher efficiencies (effective TOP/s versus Peak TOP/s) for AI applications. Most vendors on the market are only able to deliver a fraction of their peak TOPS, often maxing out at 40% efficient. Our leadership result was also achieved while maintaining TensorFlow and Pytorch framework programmability without requiring users’ have hardware expertise.
Specs Server Dell EMC Power Edge R740xd
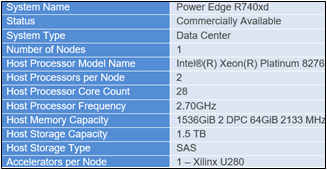
Figure 2: Server Configuration Details
Xilinx VCK5000

Figure 3: Xilinx VCK5000 Details
Xilinx U280 Accelerator
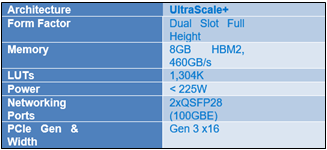
Figure 4: Xilinx FPGA Details
Vitis AI
The Vitis™ AI development environment is Xilinx’s development platform for AI inference on Xilinx hardware platforms, including both edge devices and Alveo cards. It consists of optimized IP, tools, libraries, models, and example designs. It is designed with high efficiency and ease of use in mind, unleashing the full potential of AI acceleration on Xilinx FPGA and ACAP.
MLPerf Inference v0.7
The MLPerf inference benchmark measures how fast a system can performs ML inference using a trained model with new data in a variety of deployment scenarios, see Table 1 with the list of seven mature models included in the official release v0.7
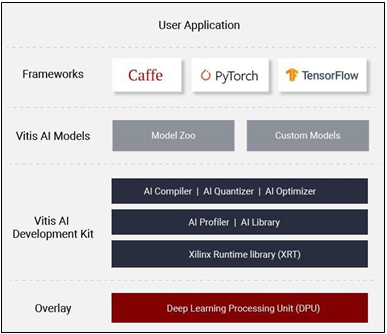
Figure 5: Xilinx Vitis AI stack
Model | Reference Application | Dataset |
resnet50-v1.5 | vision / classification and detection | ImageNet (224x224) |
ssd-mobilenet 300x300 | vision / classification and detection | COCO (300x300) |
ssd-resnet34 1200x1200 | vision / classification and detection | COCO (1200x1200) |
bert | language | squad-1.1 |
dlrm | recommendation | Criteo Terabyte |
3d-unet | vision/medical imaging | BraTS 2019 |
rnnt | speech recognition | OpenSLR LibriSpeech Corpus |
Table 1 : Inference Suite v0.7
The above models serve in a variety of critical inference applications or use cases known as “scenarios”, each scenario requires different metrics, demonstrating production environment performance in the real practice. MLPerf Inference consists of four evaluation scenarios: single-stream, multistream, server, and offline.
Scenario | Example Use Case | Throughput |
SingleStream | cell phone augmented vision | Latency in milliseconds |
MultiStream | multiple camera driving assistance | Number of Streams |
Server | translation site | QPS |
Offline | photo sorting | Inputs/second |
Results
Figure 6 and 7 below show the graphs with the inference results submitted for Xilinx VCK5000 and Xilinx U280 FPGA on Dell EMC PowerEdge R740xd:
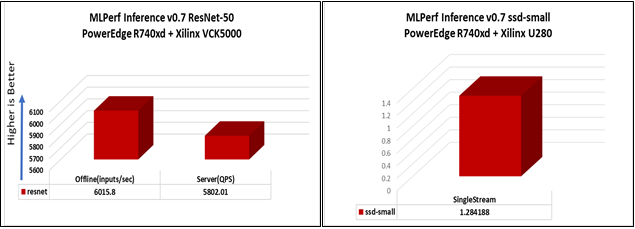
Figure 6: ResNet-50 Benchmark Figure 7: SSD-Small benchmark
Offline scenario: represents applications that process the input in batches of data available immediately, and don’t have latency constraint for the metric performance measured as samples per second.
Server scenario: this scenario represents deployment of online applications with random input queries, the metric performance is queries per second (QPS) subject to latency bound. The server scenario is more complicated in terms of latency constraints and input queries generation, this complexity is reflected in the throughput-degradation compared to offline scenario.
Conclusion
This was a milestone in terms of showcasing where FPGAs as accelerators can be used and optimized for Machine learning. It demonstrates the close partnership that Dell Technologies & Xilinx have established in exploring FPGA applications in the field of Machine learning.
Citation
@misc{reddi2019mlperf,
title={MLPerf Inference Benchmark},
author={Vijay Janapa Reddi and Christine Cheng and David Kanter and Peter Mattson and Guenther Schmuelling and Carole-Jean Wu and Brian Anderson and Maximilien Breughe and Mark Charlebois and William Chou and Ramesh Chukka and Cody Coleman and Sam Davis and Pan Deng and Greg Diamos and Jared Duke and Dave Fick and J. Scott Gardner and Itay Hubara and Sachin Idgunji and Thomas
B. Jablin and Jeff Jiao and Tom St. John and Pankaj Kanwar and David Lee and Jeffery Liao and Anton Lokhmotov and Francisco Massa and Peng Meng and Paulius Micikevicius and Colin Osborne and Gennady Pekhimenko and Arun Tejusve Raghunath Rajan and Dilip Sequeira and Ashish Sirasao and Fei Sun and Hanlin Tang and Michael Thomson and Frank Wei and Ephrem Wu and Lingjie Xu and Koichi Yamada and Bing Yu and George Yuan and Aaron Zhong and Peizhao Zhang and Yuchen Zhou}, year={2019},
eprint={1911.02549}, archivePrefix={arXiv}, primaryClass={cs.LG}
Related Documents

MLPerf Inference v0.7 Benchmarks on Dell EMC PowerEdge R740xd and R640 Servers
Mon, 16 Jan 2023 13:44:22 -0000
|Read Time: 0 minutes
Summary
MLPerf Consortium has released the second round of results v0.7 for its machine learning inference performance benchmark suite. Dell EMC has been participated in this contest in collaboration with several partners and configurations, including inferences with CPU only and with accelerators such as GPU’s and FPGA’s. This blog is focused on the submission results in the closed division/datacenter category for the servers Dell EMC PowerEdge R740xd and PowerEdge R640 with CPU only, in collaboration with Intel® and its Optimized Inference System based on OpenVINO™ 2020.4.
In this DfD we present the MLPerf Inference v0.7 results submission for the servers PowerEdge R740xd and R640 with Intel® processors, using the Intel® Optimized Inference System based on OpenVINO™ 2020.4. Table 1 shows the technical specifications of these systems.
Dell EMC PowerEdge R740xd and R640 Servers
Specs Dell EMC PowerEdge Servers
System Name | PowerEdge R740xd | PowerEdge R640 |
Status | Commercially Available | Commercially Available |
System Type | Data Center | Data Center |
Number of Nodes | 1 | 1 |
Host Processor Model Name | Intel®(R) Xeon(R) Platinum 8280M | Intel®(R) Xeon(R) Gold 6248R |
Host Processors per Node | 2 | 2 |
Host Processor Core Count | 28 | 24 |
Host Processor Frequency | 2.70 GHz | 3.00 GHz |
Host Memory Capacity | 384 GB 1 DPC 2933 MHz | 188 GB |
Host Storage Capacity | 1.59 TB | 200 GB |
Host Storage Type | SATA | SATA |
Accelerators per Node | n/a | n/a |
2nd Generation Intel® Xeon® Scalable Processors
The 2nd Generation Intel® Xeon® Scalable processor family is designed for data center modernization to drive operational efficiencies and higher productivity, leveraged with built-in AI acceleration tools, to provide the seamless performance foundation for data center and edge systems. Table 2 shows the technical specifications for CPU’s Intel® Xeon®.
Intel® Xeon® Processors
Product Collection | Platinum 8280M | Gold 6248R |
# of CPU Cores | 28 | 24 |
# of Threads | 56 | 48 |
Processor Base Frequency | 2.70 GHz | 3.00 GHz |
Max Turbo Speed | 4.00 GHz | 4.00 GHz |
Cache | 38.5 MB | 35.75 MB |
Memory Type | DDR4-2933 | DDR4-2933 |
Maximum memory Speed | 2933 MHz | 2933 MHz |
TDP | 205 W | 205 W |
ECC Memory Supported | Yes | Yes |
Table 2 - Intel Xeon Processors technical specifications

OpenVINO™ Toolkit
The OpenVINO™ toolkit optimizes and runs Deep Learning Neural Network models on Intel® Xeon CPUs. The toolkit consists of three primary components: inference engine, model optimizer, and intermediate representation (IP). The Model Optimizer is used to convert the MLPerf inference benchmark reference implementations from a framework into quantized INT8 models, optimized to run on Intel® architecture.
MLPerf Inference v0.7
The MLPerf inference benchmark measures how fast a system can perform ML inference using a trained model with new data in a variety of deployment scenarios. There are two benchmark suites, one for Datacenter systems and one for Edge as shown below in Table 3 with the list of six mature models included in the official release v0.7 for Datacenter systems category.
Area | Task | Model | Dataset |
Vision | Image classification | Resnet50-v1.5 | ImageNet (224x224) |
Vision | Object detection (large) | SSD-ResNet34 | COCO (1200x1200) |
Vision | Medical image segmentation | 3D UNET | BraTS 2019 (224x224x160) |
Speech | Speech-to-text | RNNT | Librispeech dev-clean (samples < 15 seconds) |
Language | Language processing | BERT | SQuAD v1.1 (max_seq_len=384) |
Commerce | Recommendation | DLRM | 1TB Click Logs |
The above models serve in a variety of critical inference applications or use cases known as “scenarios”, where each scenario requires different metrics, demonstrating production environment performance in the real practice. Below is the description of each scenario in Table 4 and the showing the scenarios required for each Datacenter benchmark.
Offline scenario: represents applications that process the input in batches of data available immediately, and don’t have latency constraint for the metric performance measured as samples per second.
Server scenario: this scenario represents deployment of online applications with random input queries, the metric performance is queries per second (QPS) subject to latency bound. The server scenario is more complicated in terms of latency constraints and input queries generation, this complexity is reflected in the throughput-degradation compared to offline scenario.
Area | Task | Required Scenarios |
Vision | Image classification | Server, Offline |
Vision | Object detection (large) | Server, Offline |
Vision | Medical image segmentation | Offline |
Speech | Speech-to-text | Server, Offline |
Language | Language processing | Server, Offline |
Commerce | Recommendation | Server, Offline |
Results
For MLPerf Inference v0.7, we focused on computer vision applications with the optimized models resnet50- v1.5 and ssd-resnet34 for offline and server scenarios (required for data center category). Figure 1 & Figure 2 show the graphs for Inference results on Dell EMC PowerEdge servers.
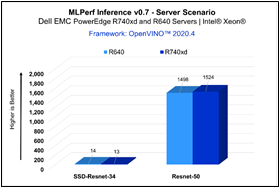
Figure 2 - Server Scenario
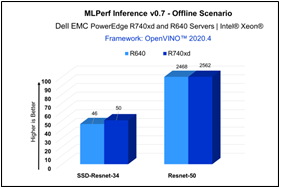
Figure 2 - Offline Scenario
| Resnet-50 | SSD-Resnet-34 | ||
Offline | Server | Offline | Server | |
PowerEdge R740xd | 2562 | 1524 | 50 | 13 |
PowerEdge R640 | 2468 | 1498 | 46 | 14 |
The results above demonstrate consistent inference performance using the 2nd Gen Intel® Xeon Scalable processors on the PowerEdge R640 and PowerEdge R740 platforms. The models Resnet-50 and SSD- Resnet34 are relatively smaller compared to other benchmarks included in the MLPerf Inference v0.7 suite, and customers looking to deploy image classification and object detection inference workloads with Intel CPUs can rely on these servers to meet their requirements, within the target throughput-latency budget.
Conclusion
Dell EMC PowerEdge R740xd and R640 servers with Intel® Xeon® processors and leveraging OpenVINO™ toolkit enables high-performance deep learning inference workloads for data center modernization, bringing efficiency and improved total cost of ownership (TCO).
Citation
@misc{reddi2019mlperf,
title={MLPerf Inference Benchmark},
author={Vijay Janapa Reddi and Christine Cheng and David Kanter and Peter Mattson and Guenther Schmuelling and Carole-Jean Wu and Brian Anderson and Maximilien Breughe and Mark Charlebois and William Chou and Ramesh Chukka and Cody Coleman and Sam Davis and Pan Deng and Greg Diamos and Jared Duke and Dave Fick and J. Scott Gardner and Itay Hubara and Sachin Idgunji and Thomas B. Jablin and Jeff Jiao and Tom St. John and Pankaj Kanwar and David Lee and Jeffery Liao and Anton Lokhmotov and Francisco Massa and Peng Meng and Paulius Micikevicius and Colin Osborne and Gennady Pekhimenko and Arun Tejusve Raghunath Rajan and Dilip Sequeira and Ashish Sirasao and Fei Sun and Hanlin Tang and Michael Thomson and Frank Wei and Ephrem Wu and Lingjie Xu and Koichi Yamada and Bing Yu and George Yuan and Aaron Zhong and Peizhao Zhang and Yuchen Zhou}, year={2019},
eprint={1911.02549}, archivePrefix={arXiv}, primaryClass={cs.LG}
}

MLPerf Inference v0.7 Benchmarks on Dell EMC PowerEdge R740xd and R640 Servers
Tue, 17 Jan 2023 05:53:17 -0000
|Read Time: 0 minutes
Summary
MLPerf Consortium has released the second round of results v0.7 for its machine learning inference performance benchmark suite. Dell EMC has been participated in this contest in collaboration with several partners and configurations, including inferences with CPU only and with accelerators such as GPU’s and FPGA’s. This blog is focused on the submission results in the closed division/datacenter category for the servers Dell EMC PowerEdge R740xd and PowerEdge R640 with CPU only, in collaboration with Intel® and its Optimized Inference System based on OpenVINO™ 2020.4.
In this DfD we present the MLPerf Inference v0.7 results submission for the servers PowerEdge R740xd and R640 with Intel® processors, using the Intel® Optimized Inference System based on OpenVINO™ 2020.4. Table 1 shows the technical specifications of these systems.
Dell EMC PowerEdge R740xd and R640 Servers
Specs Dell EMC PowerEdge Servers
System Name | PowerEdge R740xd | PowerEdge R640 |
Status | Commercially Available | Commercially Available |
System Type | Data Center | Data Center |
Number of Nodes | 1 | 1 |
Host Processor Model Name | Intel®(R) Xeon(R) Platinum 8280M | Intel®(R) Xeon(R) Gold 6248R |
Host Processors per Node | 2 | 2 |
Host Processor Core Count | 28 | 24 |
Host Processor Frequency | 2.70 GHz | 3.00 GHz |
Host Memory Capacity | 384 GB 1 DPC 2933 MHz | 188 GB |
Host Storage Capacity | 1.59 TB | 200 GB |
Host Storage Type | SATA | SATA |
Accelerators per Node | n/a | n/a |
2nd Generation Intel® Xeon® Scalable Processors
The 2nd Generation Intel® Xeon® Scalable processor family is designed for data center modernization to drive operational efficiencies and higher productivity, leveraged with built-in AI acceleration tools, to provide the seamless performance foundation for data center and edge systems. Table 2 shows the technical specifications for CPU’s Intel® Xeon®.
Intel® Xeon® Processors
Product Collection | Platinum 8280M | Gold 6248R |
# of CPU Cores | 28 | 24 |
# of Threads | 56 | 48 |
Processor Base Frequency | 2.70 GHz | 3.00 GHz |
Max Turbo Speed | 4.00 GHz | 4.00 GHz |
Cache | 38.5 MB | 35.75 MB |
Memory Type | DDR4-2933 | DDR4-2933 |
Maximum memory Speed | 2933 MHz | 2933 MHz |
TDP | 205 W | 205 W |
ECC Memory Supported | Yes | Yes |
Table 2 - Intel Xeon Processors technical specifications
OpenVINO™ Toolkit
The OpenVINO™ toolkit optimizes and runs Deep Learning Neural Network models on Intel® Xeon CPUs. The toolkit consists of three primary components: inference engine, model optimizer, and intermediate representation (IP). The Model Optimizer is used to convert the MLPerf inference benchmark reference implementations from a framework into quantized INT8 models, optimized to run on Intel® architecture.
MLPerf Inference v0.7
The MLPerf inference benchmark measures how fast a system can perform ML inference using a trained model with new data in a variety of deployment scenarios. There are two benchmark suites, one for Datacenter systems and one for Edge as shown below in Table 3 with the list of six mature models included in the official release v0.7 for Datacenter systems category.
Area | Task | Model | Dataset |
Vision | Image classification | Resnet50-v1.5 | ImageNet (224x224) |
Vision | Object detection (large) | SSD-ResNet34 | COCO (1200x1200) |
Vision | Medical image segmentation | 3D UNET | BraTS 2019 (224x224x160) |
Speech | Speech-to-text | RNNT | Librispeech dev-clean (samples < 15 seconds) |
Language | Language processing | BERT | SQuAD v1.1 (max_seq_len=384) |
Commerce | Recommendation | DLRM | 1TB Click Logs |
The above models serve in a variety of critical inference applications or use cases known as “scenarios”, where each scenario requires different metrics, demonstrating production environment performance in the real practice. Below is the description of each scenario in Table 4 and the showing the scenarios required for each Datacenter benchmark.
Offline scenario: represents applications that process the input in batches of data available immediately, and don’t have latency constraint for the metric performance measured as samples per second.
Server scenario: this scenario represents deployment of online applications with random input queries, the metric performance is queries per second (QPS) subject to latency bound. The server scenario is more complicated in terms of latency constraints and input queries generation, this complexity is reflected in the throughput-degradation compared to offline scenario.
Area | Task | Required Scenarios |
Vision | Image classification | Server, Offline |
Vision | Object detection (large) | Server, Offline |
Vision | Medical image segmentation | Offline |
Speech | Speech-to-text | Server, Offline |
Language | Language processing | Server, Offline |
Commerce | Recommendation | Server, Offline |
Results
For MLPerf Inference v0.7, we focused on computer vision applications with the optimized models resnet50- v1.5 and ssd-resnet34 for offline and server scenarios (required for data center category). Figure 1 & Figure 2 show the graphs for Inference results on Dell EMC PowerEdge servers.
Figure 2 - Server Scenario
Figure 2 - Offline Scenario
| Resnet-50 | SSD-Resnet-34 | ||
Offline | Server | Offline | Server | |
PowerEdge R740xd | 2562 | 1524 | 50 | 13 |
PowerEdge R640 | 2468 | 1498 | 46 | 14 |
The results above demonstrate consistent inference performance using the 2nd Gen Intel® Xeon Scalable processors on the PowerEdge R640 and PowerEdge R740 platforms. The models Resnet-50 and SSD- Resnet34 are relatively smaller compared to other benchmarks included in the MLPerf Inference v0.7 suite, and customers looking to deploy image classification and object detection inference workloads with Intel CPUs can rely on these servers to meet their requirements, within the target throughput-latency budget.
Conclusion
Dell EMC PowerEdge R740xd and R640 servers with Intel® Xeon® processors and leveraging OpenVINO™ toolkit enables high-performance deep learning inference workloads for data center modernization, bringing efficiency and improved total cost of ownership (TCO).
Citation
@misc{reddi2019mlperf,
title={MLPerf Inference Benchmark},
author={Vijay Janapa Reddi and Christine Cheng and David Kanter and Peter Mattson and Guenther Schmuelling and Carole-Jean Wu and Brian Anderson and Maximilien Breughe and Mark Charlebois and William Chou and Ramesh Chukka and Cody Coleman and Sam Davis and Pan Deng and Greg Diamos and Jared Duke and Dave Fick and J. Scott Gardner and Itay Hubara and Sachin Idgunji and Thomas B. Jablin and Jeff Jiao and Tom St. John and Pankaj Kanwar and David Lee and Jeffery Liao and Anton Lokhmotov and Francisco Massa and Peng Meng and Paulius Micikevicius and Colin Osborne and Gennady Pekhimenko and Arun Tejusve Raghunath Rajan and Dilip Sequeira and Ashish Sirasao and Fei Sun and Hanlin Tang and Michael Thomson and Frank Wei and Ephrem Wu and Lingjie Xu and Koichi Yamada and Bing Yu and George Yuan and Aaron Zhong and Peizhao Zhang and Yuchen Zhou}, year={2019},
eprint={1911.02549}, archivePrefix={arXiv}, primaryClass={cs.LG}
}