




Lab Insight: Dell AI PoC for Transportation & Logistics
Read the Report Executive Summary View the InfographicIntroduction
As part of Dell’s ongoing efforts to help make industry-leading AI workflows available to its clients, this paper outlines a sample AI solution for the transportation and logistics market. The reference solution outlined in this paper specifically targets challenges in the maritime industry by creating an AI powered cargo monitoring PoC built with DellTM hardware.
AI as a technology is currently in a rapid state of advancement. While the area of AI has been around for decades, recent breakthroughs in generative AI and large language models (LLMs) have led to significant interest across almost all industry verticals, including transportation and logistics. Futurum intelligence projects a 24% growth of AI in the transportation industry in 2024 and a 30% growth for logistics.
The advancements in AI now open significant possibilities for new value-adding applications and optimizations, however different industries will require different hardware and software capabilities to overcome industry specific challenges. When considering AI applications for transportation and logistics, a key challenge is operating at the edge. AI-powered applications for transportation will typically be heavily driven by on-board sensor data with locally deployed hardware. This presents a specific challenge, requiring hardware that is compact enough for edge deployments, powerful enough to run AI workloads, and robust enough to endure varying edge conditions.
This paper outlines a PoC for an AI-based transportation and logistics solution that is specifically targeted at maritime use cases. Maritime environments represent some of the most rigorous edge environments, while also presenting an industry with significant opportunity for AI-powered innovation. The PoC outlined in this paper addresses the unique challenges of maritime focused AI solutions with hardware from Dell and BroadcomTM.
The PoC detailed in this paper serves as a reference solution that can be leveraged for additional maritime, transportation, or logistics applications. The overall applicability of AI in these markets is much broader than the single maritime cargo monitoring solution, however, the PoC demonstrates the ability to quickly deploy valuable edge-based solutions for transportation and logistics using readily available edge hardware.
Importance for the Transportation and Logistics Market
Transportation and logistics cover a broad industry with opportunity for AI technology to create a significant impact. While the overarching segment is widespread, including public transportation, cargo shipping, and end-to-end supply chain management, key to any transportation or logistics process is optimization. These processes are dependent on a high number of specific details and variables such as specific routes, number and types of goods transported, compliance regulations, and weather conditions. By optimizing for the many variables that may arise in a logistical process, organizations can be more efficient, save money, and avoid risk.
In order to create these optimal processes, however, the data surrounding the many variables involved needs to be captured. Further, this data needs to be analyzed, understood, and acted on. The large quantity of data required and the speed at which it must be processed in order to make impactful decisions to complex logistical challenges often surpasses what a human can achieve manually.
By leveraging AI technology, impactful decisions to transportation and logistics processes can be achieved quicker and with greater accuracy. Cameras and other sensors can capture relevant data that is then processed and understood by an AI model. AI can quickly process vast amounts of data and lead to optimized logistics conclusions that would otherwise be too timely, costly, or complex for organizations to make.
The potential applications for AI in transportation are vast and can be applied to various means of transportation including shipping, rail, air, and automotive, as well as associated logistical processes such as warehouses and shipping yards. One possible example is AI optimized route planning which could pertain to either transportation of cargo or public transportation and could optimize for several factors including cost, weather conditions, traffic, or environmental impact. Additional applications could include automated fleet management, AI powered predictive vehicle maintenance, and optimized pricing. As AI technology improves, many transportation services may be additionally optimized with the use of autonomous vehicles.
By adopting such AI-powered applications, organizations can implement optimizations that may not otherwise be achievable. While new AI applications show promise of significant value, many organizations may find adopting the technology a challenge due to unfamiliarity with the new and rapidly advancing technology. Deploying complex applications such as AI in transportation environments can pose an additional challenge due to the requirements of operating in edge environments.
The following PoC solution outlines an example of a transportation focused AI application that can offer significant value to maritime shipping by providing AI-powered cargo monitoring using Dell hardware at the edge.
Solution Overview
To demonstrate an AI-powered application focused on transportation and logistics, Scalers AITM, in partnership with Dell, Broadcom, and The Futurum Group implemented a proof-of-concept for a maritime cargo monitoring solution. The solution was designed to capture sensor data from cargo ships as well as image data from on-board cameras. Cargo containers can be monitored for temperature and humidity to ensure optimal conditions are maintained for the shipped cargo. In addition, cameras can be used to monitor workers in the cargo area to ensure worker safety and prevent injury. The captured data is then utilized by an LLM to create an AI generated compliance report at the end of the ship’s voyage.
This proof-of-concept addresses several problems that can be encountered in maritime shipping. Refrigerated cargo, known as reefer, is utilized to ship perishable items and pharmaceuticals that must be kept at specific temperatures. Without proper monitoring to ensure optimal temperatures, reefer may experience swings in temperature, resulting in spoiled products and ultimately financial loss. Predictive forecasting of the power requirements for refrigerated cargo can provide additional cost and environmental savings by providing greater power usage insights.
Similarly, dry cargo can become spoiled or damaged when exposed to excessive moisture. Moisture can be introduced in the form of condensation – known as cargo sweat – due to changes in climate and humidity during the ships journey. By monitoring the temperature and humidity of the cargo, alerts can be raised signaling the possibility of cargo sweat and allowing ventilation adjustments to be made which can prevent moisture related damage.
A third issue addressed by the maritime cargo monitoring PoC is that of worker safety. The possibility of shifting cargo containers can lead to dangerous situations and potential injuries for those working in container storage areas. By using video surveillance of workers in cargo areas, these potential injuries can be avoided.
The PoC provides monitoring of these challenges with an additional visualization dashboard that displays information such as number of cargo containers, forecasted energy consumption, container temperature and humidity, and a video feed of workers. The dashboard additionally raises alerts as issues arise in any of these areas. This information is further compiled in to an end of voyage report for compliance and logging purposes, automatically generated with an LLM.
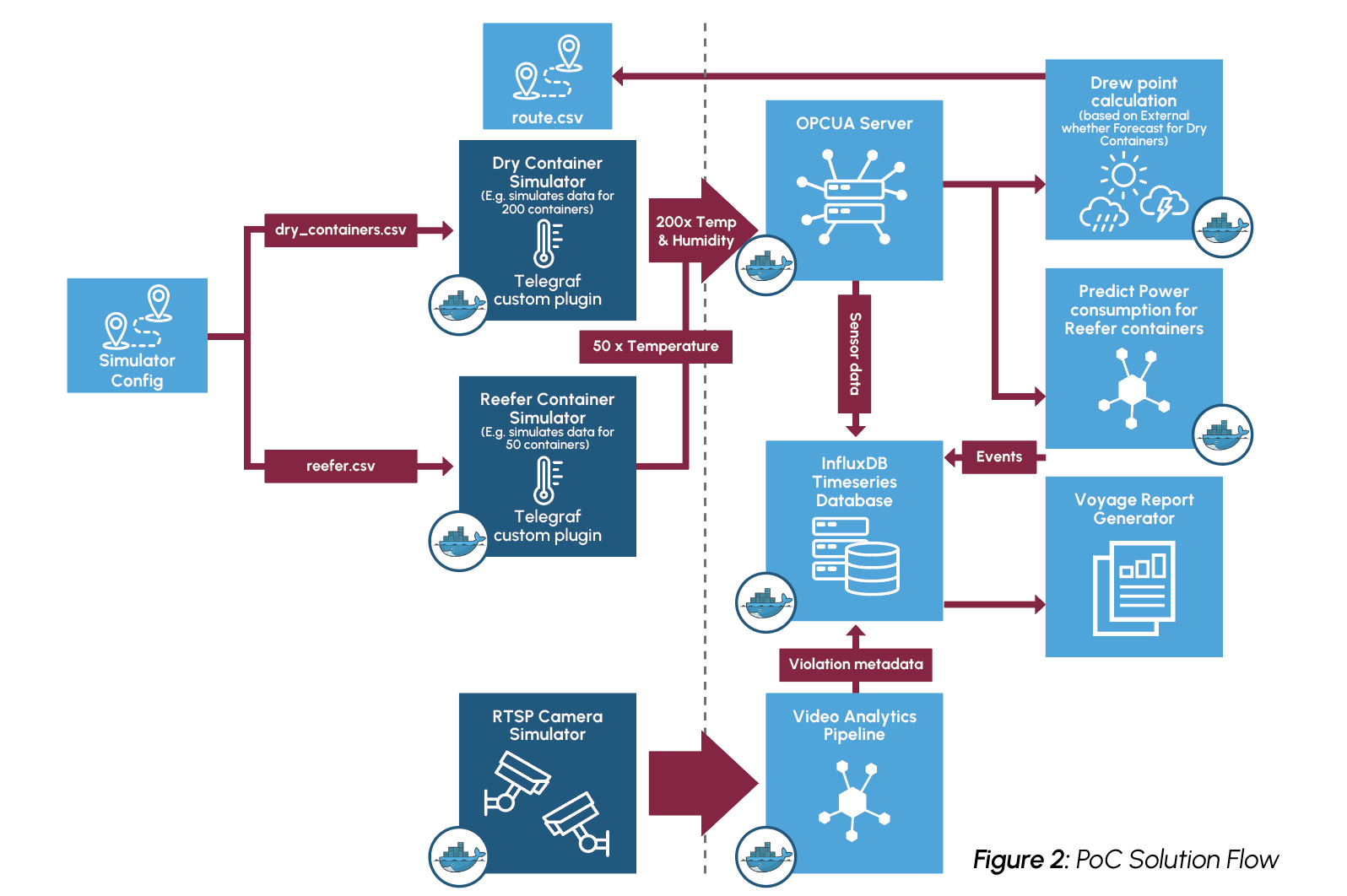
To achieve the PoC solution, simulated sensor data is generated for both reefers and dry containers, approximating the conditions undergone during a real voyage. The sensor data is written to an OPCUA server which then supplies data to a container sweat analytics module and a power consumption predictor. For dry containers, the temperature and humidity data is utilized alongside the forecasted weather of the route to create dew point calculations and monitor potential container sweat. Sensor data recording the temperature of reefer containers is monitored to ensure accurate temperatures are maintained, and a decision tree regressor model is leveraged to predict future power consumption for the next hour.
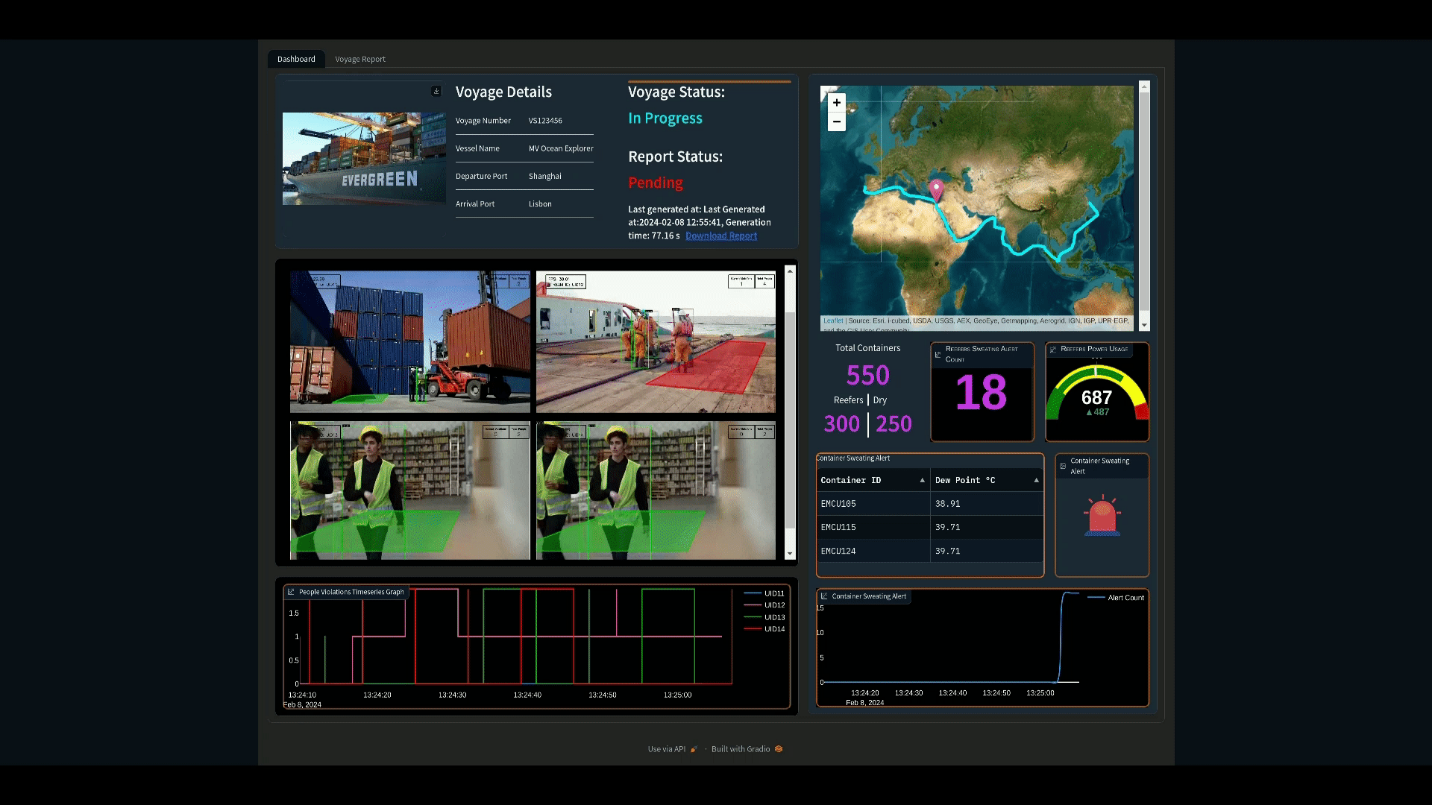
Figure 1: Visualization Dashboard
For monitoring worker safety, RTSP video data is captured into a video analytics pipeline built on NVIDIATM DeepStream. Streaming data is decoded and then inferenced using the YoloV8s model to detect workers entering dangerous, restricted zones. The restricted zones are configured as x,y coordinate pairs stored as JSON objects. Uncompressed video is then published to the visualization service using the Zero Overhead Network Protocol (Zenoh).
Monitoring and alerts for all of these challenges is displayed on a visualization dashboard as can be seen in Figure 1, as well as summarized in an end of voyage compliance report. The resulting compliance report that details the information collected on the voyage is AI generated using the Zephyr 7B model. Testing of the PoC found that the report could be generated in approximately 46 seconds, dramatically accelerating the reporting process compared to a manual approach.
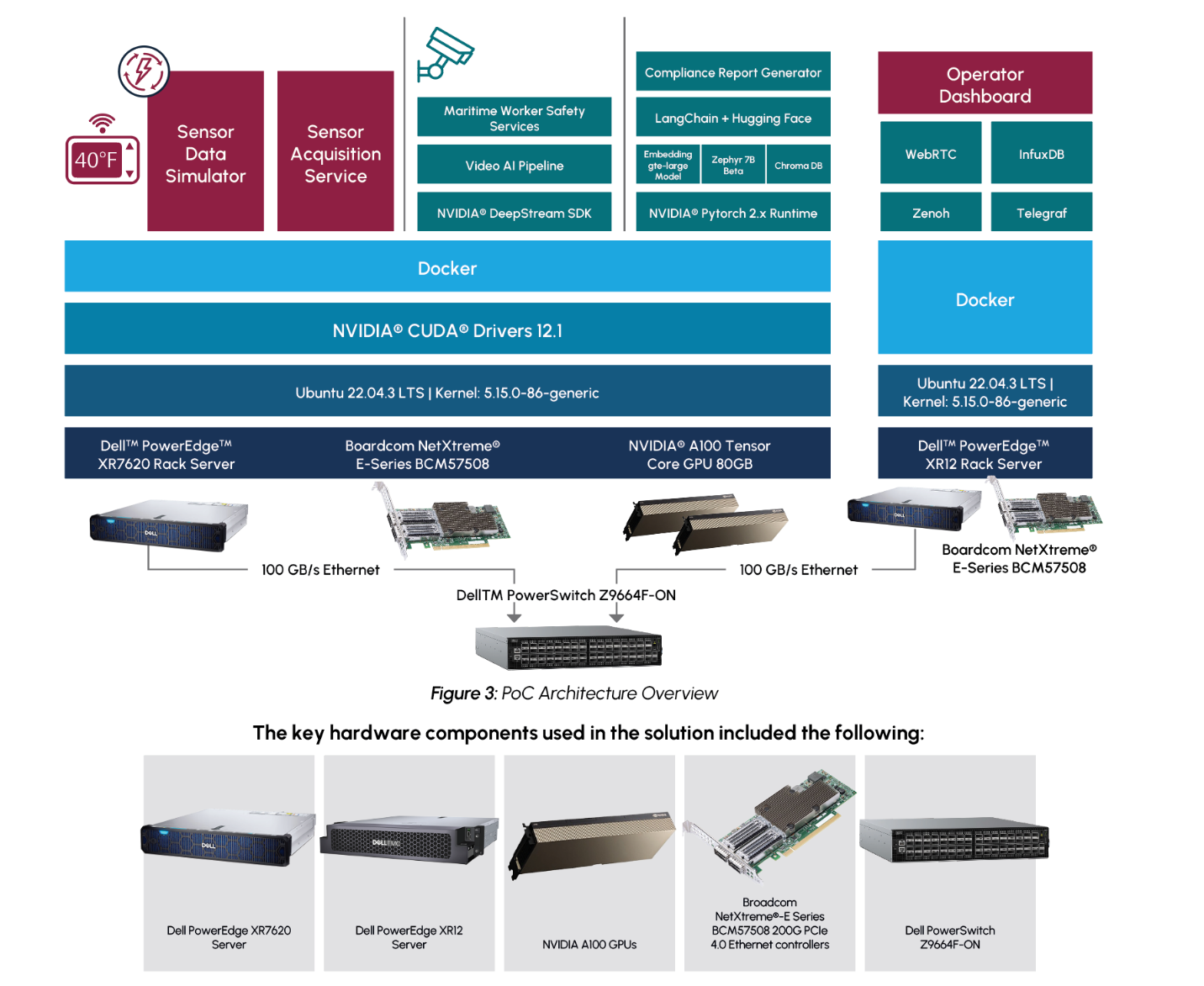
To achieve the PoC solution in-line with the restraints of a typical maritime use case, the solution was deployed using Dell PowerEdge servers designed for the edge. The sensor data calculations and predictions, video pipeline, and AI report generation were achieved on a Dell PowerEdge XR7620 server with dual NVIDIA A100 GPUs. A Dell PowerEdge XR12 server was deployed to host the visualization dashboard. The two servers were connected with high bandwidth Broadcom NICs.
An overview of the solution can be seen in Figure 2
Additional details about the implementation and performance testing of the PoC on GitHub, including:
- Configuration information including diagrams and YAML code
- Instructions for doing the performance tests
- Details of performance results
- Source code
- Samples for test process
https://github.com/dell-examples/generative-ai/tree/main/transportation-maritime
Highlights for AI Practitioners
The cargo monitoring PoC demonstrates a solution that can avoid product loss, enhance compliance and logging, and improve worker safety, all by using AI. The creation of these AI processes was done using readily available AI tools. The process of creating valuable, real-world solutions by utilizing such tools should be noted by AI practitioners.
The end of voyage compliance report is generated using the Zephyr 7B LLM model created by Hugging Face’s H4 team. The Zephyr 7B model, which is a modified version of Mistral 7B, was chosen as it is a publicly available model that is both lightweight and highly accurate. The Zephyr 7B model was created using a process called Distilled Supervised Fine Tuning (DSFT) which allows the model to provide similar performance to much larger models, while utilizing far fewer parameters. Zephyr 7B, which is a 7 Billion parameter model, has demonstrated performance comparable to 70 Billion parameter models. This ability to provide the capabilities of larger models in a smaller, distilled model makes Zephyr 7B an ideal choice for edge-based deployments with limited resources, such as in maritime or other transportation environments.
While Zephyr 7B is a very powerful and accurate LLM model, it was trained on a broad data set and it is intended for general purpose usage, rather than specific tasks such as generating a maritime voyage compliance report. In order to generate a report that is accurate to the maritime industry and the specific voyage, more context must be supplied to the model. This was achieved using a process called Retrieval Augmented Generation (RAG). By utilizing RAG, the Zephyr 7B model is able to incorporate the voyage specific information to generate an accurate report which detailed the recorded container and worker safety alerts. This is notable for AI practitioners as it demonstrates the ability to use a broad, pre-trained LLM model, which is freely available, to achieve an industry specific task.
To provide the voyage specific context to the LLM generated report, time series data of recorded events, such as container sweating, power measurements, and worker safety violations, is queried from InfluxDB at the end of the voyage. This text data is then embedded using the Hugging Face LangChain API with the gte-large embedding model and stored in a ChromaDB vector database. These vector embeddings are then used in the RAG process to provide the Zephyr 7B model with voyage specific context when generating the report.
AI practitioners should also note that AI image detection is utilized to detect workers entering into restricted zones. This image detection capability was built using the YOLOv8s object detection model and NVIDIA DeepStream. YOLOv8s is a state of the art, open source, AI model for object detection built by Ultralytics. The model is used to detect workers within a video frame and detect if they enter into pre-configured restricted zones. NVIDIA DeepStream is a software development toolkit provided by NVIDIA to build and accelerate AI solutions from streaming video data, which is optimized for NVIDIA hardware such asthe A100 GPUs used in this PoC. It is notable that NVIDIA DeepStream can be utilized for free to build powerful video-based AI applications, such as the worker detection component of the maritime cargo monitoring solution. In this case, the YOLOv8s model and the DeepStream toolkit are utilized to build a solution that has the potential to prevent serious workplace injuries.
Key Highlights for AI Practitioners
- Maritime compliance report generated with Zephyr 7B LLM model
- Retrieval Augmented Generation (RAG) approach used to provide Zephyr 7B with voyage specific information
- YOLOv8s and NVIDIA DeepStream used to create powerful AI worker detection solution using video streaming data
Considerations for IT Operations
The maritime cargo monitoring PoC is notable for IT operations as it demonstrates the ability to deploy a powerful AI driven solution at the edge. For many in IT, AI deployments in any setting may be a challenge, due to overall unfamiliarity with AI and its hardware requirements. Deployments at the edge introduce even further complexity.
Hardware deployed at the edge requires additional considerations, including limited space and exposure to harsh conditions, such as extreme temperature changes. For AI applications deployed at the edge, these requirements must be maintained, while simultaneously providing a system powerful enough to handle such a computationally intensive workload.
For the maritime cargo monitoring PoC, Dell PowerEdge XR7620 and PowerEdge XR12 servers were chosen for their ability to meet both the most demanding edge requirements, as well as the most demanding computational requirements. Both servers are ruggedized and are capable of operating in temperatures ranging from -5°C to 55°C, as well as withstanding dusty or otherwise hazardous environments. They additionally offer a compact design that is capable of fitting into tight environments. This provides servers that are ideal for a demanding edge environment, such as in maritime shipping, which may experience large temperature swings and may have limited space for servers. Meanwhile, the Dell PowerEdge XR7620 is also equipped with NVIDIA GPUs, providing it with the compute power necessary to handle AI workloads.

Dell PowerEdge XR7620
NVIDIA A100 GPUs were chosen as they are well suited for various types of AI workflows. The PoC includes both a video classification component and a large language model component, requiring hardware that is well suited for both workloads. While there are other processors that are more specialized specifically for either video processing or language models, the A100 GPU provides flexibility to perform both well on a single platform.
The use of high bandwidth Broadcom NICs is also a notable component of the PoC solution for IT operations to be aware of. The Broadcom NICs are responsible for providing a high bandwidth Ethernet connection between the cargo and worker monitoring applications and the visualization and alerting dashboard. The use of scalable, high bandwidth NICs is crucial to such a solution that requires transmitting large amounts of sensor and video data, which may include time sensitive information.
Detection of issues with either reefer or dry containers may require quick action to protect the cargo, and quick detection of workers in hazardous environments can prevent serious harm or injury. The use of a high bandwidth Ethernet connection ensures that data can be quickly transmitted and received by the visualization dashboard for operators to respond to alerts as they arise.
Key Highlights for IT Operations
- AI solution deployed on rugged Dell PowerEdge XR7620 and PowerEdge XR12 servers to accommodate edge environmentand maintain high computational requirements.
- NVIDIA A100 GPUs provide flexibility to support both video and LLM workloads.
- Broadcom NICs provide high bandwidth connection between monitoring applications and visualization dashboard.
Solution Performance Observations
Key to the performance of the maritime cargo monitoring PoC is its ability to scale to support multiple concurrent video streams for monitoring worker safety. The solution must be able to quickly decode and inference incoming video data to detect workers in restricted areas. The ability for the visualization dashboard to quickly receive this data is additionally critical for actions to be taken on alerts as they are raised. The solution was separated into a distinct inference server, to capture and inference data, and an encode server, to display the visualization service. This architecture allows the solution to scale the services independently as needed for varying requirements of video streams and application logic. The separate services are then connected with high bandwidth Ethernet using Broadcom NetXtreme®-E Series Ethernet controllers. The following performance data demonstrates the ability to scale the solution with an increasing number of data streams. Each test was run for a total of 10 minutes and video streams were scaled evenly across the two NVIDIA A100 GPUs. Additional performance results are available in the appendix.
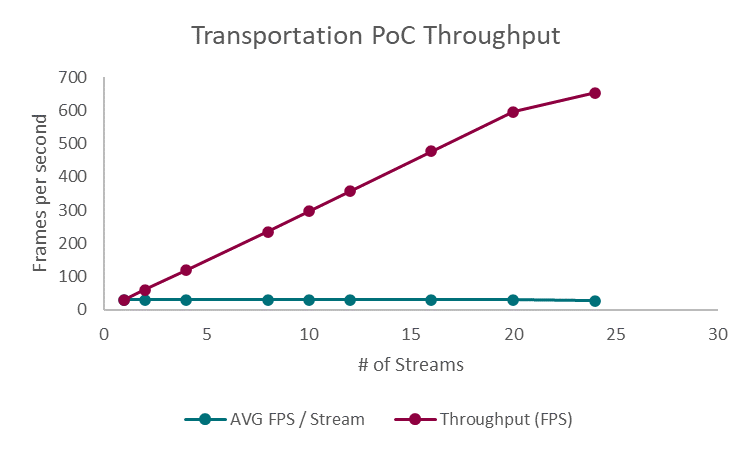
Figure 4: Transportation PoC Throughput
Figure 4 displays the total throughput of frames per second as well as the average throughput as the number of streams increased. The frames per second metric includes video decoding, inference, post-processing, and publishing of an uncompressed stream. The PoC displayed increasing throughput with a maximum of 653.7 frames per second when tested with 24 concurrent streams. Notably, the average frames per second remained steady at approximately 30 frames per second for up to 20 streams, which is considered an industry standard for video processing workloads. When tested with 24 streams, the solution did experience a slight drop, with an average of 27.24 frames per second. Overall, the throughput performance demonstrates the ability of the Dell PowerEdge Server and the NVIDIA A100 GPUs to successfully handle a demanding video-based AI workload with a significant number of concurrent streams.
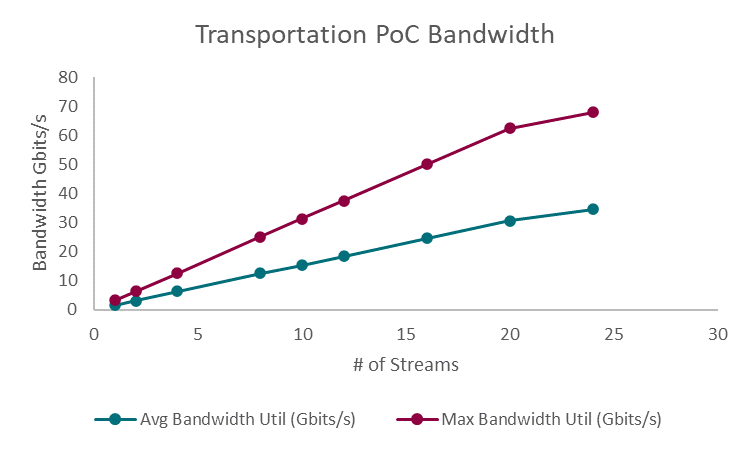
Figure 5: Transportation PoC Bandwidth Utilization
Figure 5 displays the solution’s bandwidth utilization as the number of streams increased from 1 to 24. The results demonstrate the increase in required bandwidth, both at a maximum and on average, as the number of streams increased. The average bandwidth utilization scaled from 1.56 Gb/s with a single video stream, to 34.6 Gb/s when supporting 24 concurrent streams The maximum bandwidth utilization was observed to be 3.13 Gb/s with a single stream, up to 67.9 Gb/s with 24 streams. By utilizing scalable, high bandwidth 100Gb/s Broadcom Ethernet, the solution is able to achieve the increasing bandwidth utilization required when adding additional video streams.
The performance results showcase the PoC as a flexible solution that can be scaled to accommodate varying levels of video requirements while maintaining performance and scaling bandwidth as needed. The solution also provides the foundation for additional AI-powered transportation and logistics applications that may require similar transmission of sensor and video data.
Final Thoughts
The maritime cargo monitoring PoC provides a concrete example of how AI can improve transportation and logistics processes by monitoring container conditions, detecting dangerous working environments, and generating automated compliance reports. While the PoC presented in this paper is limited in scope and executed using simulated sensor datasets, the solution serves as a starting point for expanding such a solution and a reference for developing related AI applications.
The solution additionally demonstrates several notable results. The solution utilizes readily available AI tools including Zephyr 7B, YOLOv8s, and NVIDIA DeepStream to create valuable AI applications that can be deployed to provide tangible value in industry specific environments. The use of RAG in the Zephyr 7B implementation is especially notable, as it provides customization to a general-purpose language model, enabling it to function for a maritime specific use case. The PoC also showcased the ability to deploy an AI solution in demanding edge environments with the use of Dell PowerEdge XR7620 and XR12 servers and to provide high bandwidth when transmitting critical data by using Broadcom NICs.
When tested, the PoC solution demonstrated the ability to scale up to 24 concurrent streams while experience little loss of throughput and successfully supporting increased bandwidth requirements. Testing of the LLM report generation showed that an AI augmented maritime compliance report could be generated in as little as 46 seconds. The testing of the PoC demonstrate both its real-world applicability in solving maritime challenges, as well as its flexibility to scale to individual deployment requirements.
Transportation and logistics are areas that rely heavily upon optimization. With the advancements in AI technology, these markets are well positioned to benefit from AI-driven innovation. AI is capable of processing data and deriving solutions to optimize transportation and logistics processes at a scale and speed that humans are not capable of achieving manually. The opportunity for AI to create innovative solutions in this market is broad and extends well beyond the maritime PoC detailed in this paper. By understanding the approach to creating an AI application and the hardware components used, however, organizations in the transportation and logistics market can apply similar solutions to innovate and optimize their business.
Appendix
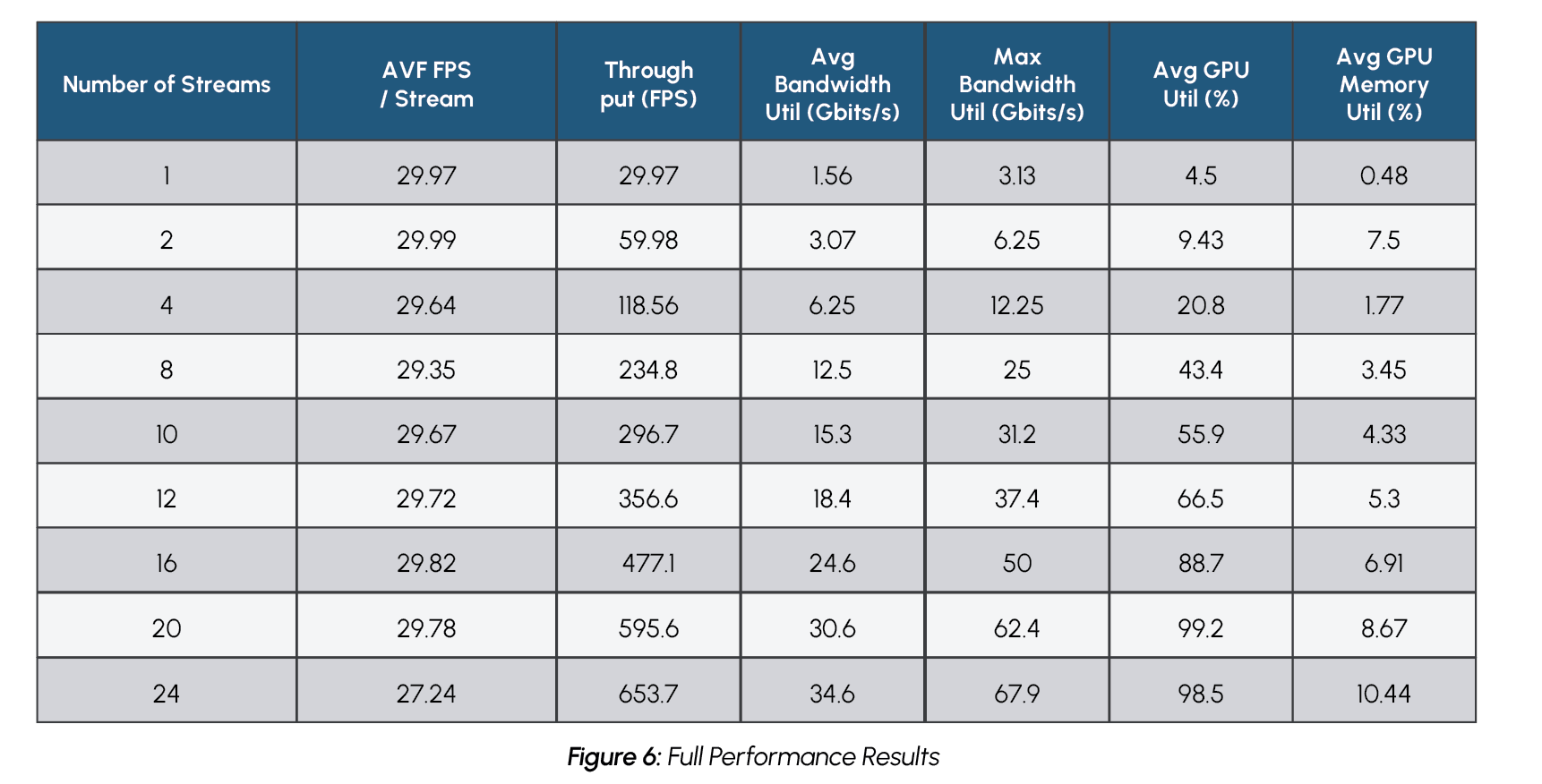
Figure 6 shows full performance testing results for the cargo monitoring PoC.
CONTRIBUTORS
Mitch Lewis
Research Analyst | The Futurum Group
PUBLISHER
Daniel Newman
CEO | The Futurum Group
INQUIRIES
Contact us if you would like to discuss this report and The Futurum Group will respond promptly.
CITATIONS
This paper can be cited by accredited press and analysts, but must be cited in-context, displaying author’s name, author’s title, and “The Futurum Group.” Non-press and non-analysts must receive prior written permission by The Futurum Group for any citations.
LICENSING
This document, including any supporting materials, is owned by The Futurum Group. This publication may not be
reproduced, distributed, or shared in any form without the prior written permission of The Futurum Group.
DISCLOSURES
The Futurum Group provides research, analysis, advising, and consulting to many high-tech companies, including those mentioned in this paper. No employees at the firm hold any equity positions with any companies cited in this document.
ABOUT THE FUTURUM GROUP
The Futurum Group is an independent research, analysis, and advisory firm, focused on digital innovation and market-disrupting technologies and trends. Every day our analysts, researchers, and advisors help business leaders from around the world anticipate tectonic shifts in their industries and leverage disruptive innovation to either gain or maintain a competitive advantage in their markets.
© 2024 The Futurum Group. All rights reserved.
Related Documents

Dell POC for Scalable and Heterogeneous Gen-AI Platform
Fri, 08 Mar 2024 18:35:58 -0000
|Read Time: 0 minutes

Introduction
As part of Dell’s ongoing efforts to help make industry leading AI workflows available to their clients, this paper outlines a scalable AI concept that can utilize heterogeneous hardware components. The featured Proof of Concept (PoC) showcases a Generative AI Large Language Model (LLM) in active production, capable of functioning across diverse hardware systems.
Currently, most AI offerings are highly customized and designed to operate with specific hardware, either a particular vendor's CPUs or a specialized hardware accelerator such as a GPU. Although the operational stacks in use vary across different operational environments, they maintain a core similarity and adapt to each specific hardware requirement.
Today, the conversation around Generative-AI LLMs often revolves around their training and the methods for enhancing their capabilities. However, the true value of AI comes to light when we deploy it in production. This PoC focuses on the application of generative AI models to generate useful results. Here, the term 'inferencing' is used to describe the process of extracting results from an AI application.
As companies transition AI projects from research to production, data privacy and security emerge as crucial considerations. Utilizing corporate IT-managed equipment and AI stacks, firms ensure the necessary safeguards are in place to protect sensitive corporate data. They effectively manage and control their AI applications, including security and data privacy, by deploying AI applications on industry-standard Dell servers within privately managed facilities.
Multiple PoC examples on Dell PowerEdge hardware, offering support for both Intel and AMD CPUs, as well as Nvidia and AMD GPU accelerators. These configurations showcase a broad range of performance options for production inferencing deployments. Following our previous Dell AI Proof of Concept,[1] which examined the use of distributed fine-tuning to personalize an AI application, this PoC can serve as the subsequent step, transforming a trained model into one that is ready for production use.
Designed to be industry-agnostic, this PoC provides an example of how we can create a general-purpose generative AI solution that can utilize a variety of hardware options to meet specific Gen-AI application requirements.
In this Proof of Concept, we investigate the ability to perform scale-out inferencing for production and to utilize a similar inferencing software stack across heterogeneous CPU and GPU systems to accommodate different production requirements. The PoC highlights the following:
- A single CPU based system can support multiple, simultaneous, real-time sessions
- GPU augmented clusters can support hundreds of simultaneous, real-time sessions
- A common AI inferencing software architecture is used across heterogenous hardware
| Futurum Group Comment: The novel aspect of this proof of concept is the ability to operate across different hardware types, including Intel and AMD CPUs along with support for both Nvidia and AMD GPUs. By utilizing a common inferencing framework, organizations are able to choose the most appropriate hardware deployment for each application’s requirements. This unique approach helps reduce the extensive customization required by AI practitioners, while also helping IT operations to standardize on common Dell servers, storage and networking components for their production AI deployments. |
Distributed Inferencing PoC Highlights
The inferencing examples include both single node CPU only systems, multi-node CPU clusters, along with single node and clusters of GPU augmented systems. Across this range of hardware options, the resulting generative AI application provides a broad range of performance, ranging from the ability to support several interactive query and response streams on a CPU, up to the highest performing example supporting thousands of queries utilizing a 3-node cluster with GPU cards to accelerate performance.
The objective of this PoC was to evaluate the scalability of production deployments of Generative-AI LLMs on various hardware configurations. Evaluations included deployment on CPU only, as well as GPU assisted configurations. Additionally, the ability to scale inferencing by distributing the workload across multiple nodes of a cluster were investigated. Various metrics were captured in order to characterize the performance and scaling, including the total throughput rate of various solutions, the latency or delay in obtaining results, along with the utilization rates of key hardware elements.
The examples included between one to three Dell PowerEdge servers with Broadcom NICs, with additional GPU acceleration provided in some cases by either AMD or Nvidia GPUs. Each cluster configuration was connected using Broadcom NICs to a Dell Ethernet switch for distributed inferencing. Each PoC uses one or more PowerEdge servers, with some examples also using GPUs. Dell PowerEdge Servers used included a Dell XE8545, a Dell XE9680 and a Dell R760XA. Each Dell PowerEdge system also included a Broadcom network interface (NIC) for all internode communications connected via a Dell PowerSwitch.
Shown in Figure 1 below is a 3-node example that includes the hardware and general software stack.
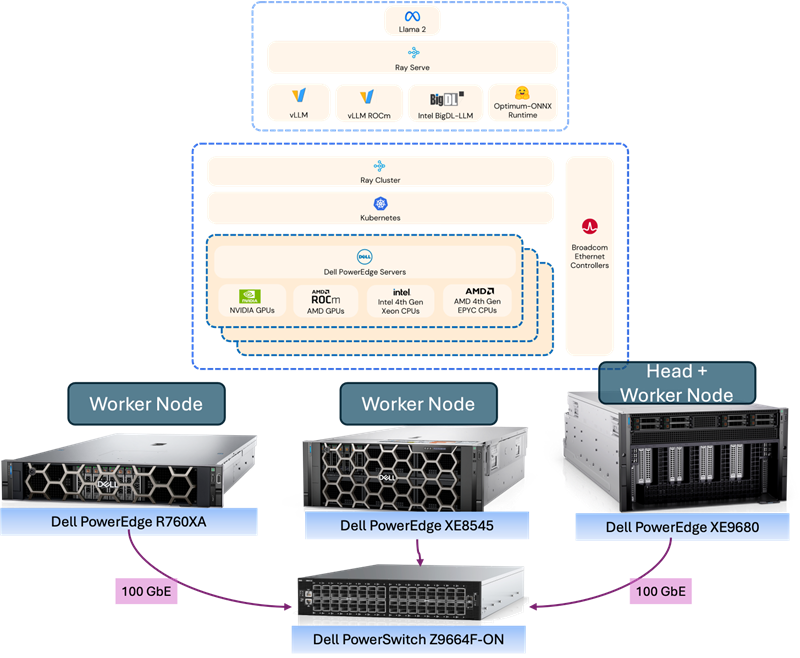
Figure 1: General, Scale-Out AI Inferencing Stack (Source: Scalers.AI)
There are several important aspects of the architecture utilized, enabling organizations to customize and deploy generative AI applications in their choice of colocation or on-premises data center. These include:
- Dell PowerEdge Sixteenth Gen Servers, with 4th generation CPUs and PCIe Gen 5 connectivity
- Broadcom NetXtreme BCM57508 NICs with up to 200 Gb/s per ethernet port
- Dell PowerSwitch Ethernet switches Z line support up to 400 Gb/s connectivity
This PoC demonstrating both heterogeneous and distributed inferencing of LLMs provides multiple advantages compared to typical inferencing solutions:
- Enhanced Scalability: Distributed inferencing enables the use of multiple nodes to scale the solution to the desired performance levels.
- Increased Throughput: By distributing the inferencing processes across multiple nodes, the overall throughput increases.
- Increased Performance: The speed of generated results may be an important consideration, by supporting both CPU and GPU inferencing, the appropriate hardware can be selected.
- Increased Efficiency: Providing a choice of using CPU or GPUs and the number of nodes enables organizations to align the solutions capabilities with their application requirements.
- Increased Reliability: With distributed inferencing, even if one node fails, the others can continue to function, ensuring that the LLM remains operational. This redundancy enhances the reliability of the system
Although each of the capabilities outlined above are related, certain considerations may be more important than others for specific deployments. Perhaps more importantly, this PoC demonstrates the ability to stand up multiple production deployments, using a consistent set of software that can support multiple deployment scenarios, ranging from a single user up to thousands of simultaneous requests. In this PoC, there are multiple hardware solution deployment examples, summarized as follows:
- CPU based inferencing using both AMD and Intel CPUs, scaled from 1 to 2 nodes
- GPU based inferencing using Nvidia and AMD GPUs, scaled from 1 to 3 nodes
For the GPU based configurations, a three node 12-GPU configuration achieved nearly 3,000 words per second in total output generation. For the scale-out configurations, inter-node communications were an important aspect of the solution. Each configuration utilized a Broadcom BCM-57508 Ethernet card enabling high-speed and low latency communications. Broadcom’s 57508 NICs allow data to be loaded directly into accelerators from storage and peers, without incurring extra CPU or memory overhead.
Futurum Group Comment: By using a scale out inferencing solution leveraging industry standard Dell servers, networking and optional GPU accelerators provides a highly adaptable reference that can be deployed as an edge solution where few inferencing sessions are required, up to enterprise deployments supporting hundreds of simultaneous inferencing outputs. |
Evaluating Solution Performance
In order to compare the performance of the different examples, it is important to understand some of the most important aspects of commonly used to measure LLM inferencing. These include the concept of a token, which typically consists of a group of characters, which are groupings of letters, with larger words comprised of multiple tokens. Currently, there is no standard token size utilized across LLM models, although each LLM typically utilizes common token sizes. Each of the PoCs utilize the same LLM and tokenizer, resulting in a common ratio of tokens to words across the examples. Another common metric is that of a request, which is essentially the input provided to the LLM and may also be called a query.
A common method of improving the overall efficiency of the system is to batch requests, or submit multiple requests simultaneously, which improves the total throughput. While batching requests increases total throughput, it comes at the cost of increasing the latency of individual requests. In practice, batch sizes and individual query response delays must be balanced to provide the response throughput and latencies that best meet a particular application’s needs.
Other factors to consider include the size of the base model utilized, typically expressed in billions of parameters, such as Mistral-7B (denoting 7 billion parameters), or in this instance, Llama2-70B, indicating that the base model utilized 70 billion parameters. Model parameter sizes are directly correlated to the necessary hardware requirements to run them.
Performance testing was performed to capture important aspects of each configuration, with the following metrics collected:
- Requests per Second (RPS): A measure of total throughput, or total requests processed per second
- Token Throughput: Designed to gauge the LLMs performance using token processing rate
- Request Latency: Reports the amount of delay (latency) for the complete response, measured in seconds, and for individual tokens, measured in milli-seconds.
- Hardware Metrics: These include CPU, GPU, Network and Memory utilization rates, which can help determine when resources are becoming overloaded, and further splitting or “sharding” of a model across additional resources is necessary.
Note: The full testing details are provided in the Appendix.
Testing evaluated the following aspects and use cases:
- Effects of scaling for interactive use cases, and batch use cases
- Scaling from 1 to 3 nodes, for GPU configurations, using 4, 8, 12 and 16 total GPUs
- Scaling from 1 to 3 nodes for CPU only configurations (using 112, 224 and 448 total CPU cores)
- For GPU configuration, the effect of moderate batch sizes (32) vs. large batching (256)
- Note: for CPU configurations, the batch size was always 1, meaning a single request per instance
We have broadly stated that two different use cases were tested, interactive and batch. An interactive use case may be considered an interactive chat agent, where a user is interacting with the inferencing results and expects to experience good performance. We subsequently define what constitutes “good performance” for an interactive user. An additional use case could be batch processing of large numbers of documents, or other scenarios where a user is not directly interacting with the inferencing application, and hence there is no requirement for “good interactive performance”.
As noted, for GPU configurations, two different batch sizes per instance were used, either 32 or 256. Interactive use of an LLM application may be uses such as chatbots, where small delays (i.e. low latency) is the primary consideration, and total throughput is a secondary consideration. Another use case is that of processing documents for analysis or summarization. In this instance, total throughput is the most important objective and the latency of any one process is inconsequential. For this case, the batch operation would be more appropriate, in order to maximize hardware utilization and total processing throughput.
Interactive Performance
For interactive performance, the rate of text generation should ideally match, or exceed the users reading or comprehension rate. Also, each additional word output should be created with relatively small delays. According to The Futurum Group’s analysis of reading rates, 200 words per minute can be considered a relatively fast rate for comprehending unseen, non-fiction text. Using this as a guideline results in a rate of 3.33 words per second.
- 200 wpm / 60 sec / minute = 3.33 words per second
Moreover, we will utilize a rate of 3.33 wps as the desired minimum generation rate for assessing the ability to meet the needs of a single interactive user. In terms of latency, 1 over 3.33, or 300 milliseconds would be considered an appropriate maximum delay threshold.
Note: For Figures 2 – 5, each utilizes two axes, the primary (left) vertical axis represents the throughput for the bars in words per second. The second (right) vertical axis represents the 95th percentile of latency results for each word generated.
In Figure 2 below, we show the total throughput of 3 different CPU configurations, along with the associated per word latency. As seen, a CPU only example can support over 40 words per second, significantly greater than the 3.33 word per second rate required for good interactive performance, while maintaining a latency of 152 ms., well under 300 ms.
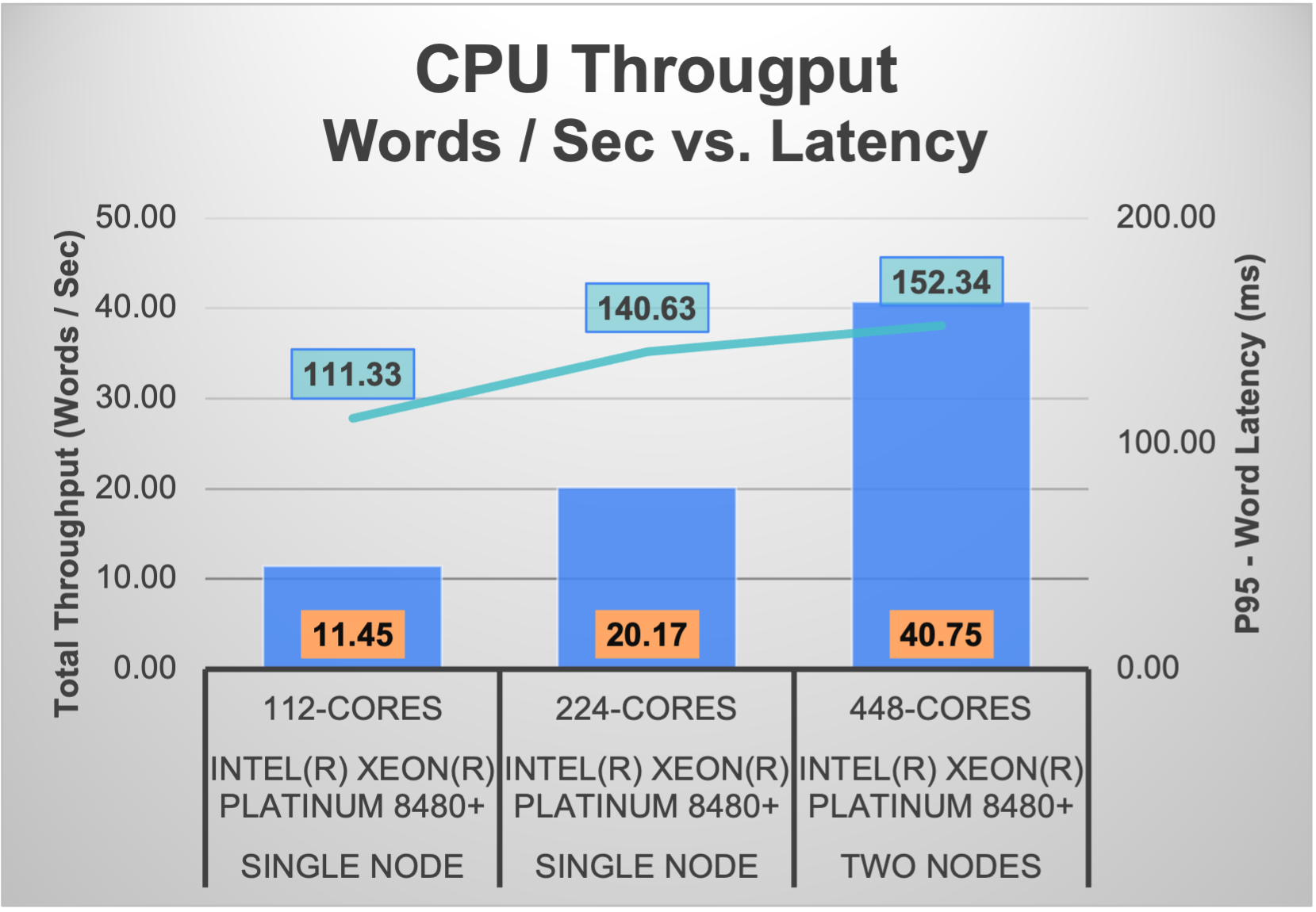
Figure 2: Interactive Inferencing Performance for CPUs (Source: Futurum Group)
Using a rate of 3.33 words / sec., we can see that two system, each with 224 CPU cores can support inferencing of up to 12 simultaneous sessions.
- Calculated as: 40 wps / 3.33 wps / session = 12 simultaneous sessions.
Futurum Group Comment: It is often expected that all generative AI applications require the use of GPUs in order to support real-time deployments. As evidenced by the testing performed, it can be seen that a single system can support multiple, simultaneous sessions, and by adding a second system, performance scales linearly, doubling from 20 words per second up to more than 40 words per second. Moreover, for smaller deployments, a single CPU based system supporting inferencing may be sufficient. |
In Figure 3 below, we show the total throughput of 4 different configurations, along with the associated per word latency. As seen, even at the rate of 1,246 words per second, latency remains at 100 ms., well below our 300 ms. threshold.

Figure 3: Interactive Inferencing Performance for GPUs (Source: Futurum Group)
Again, using 3.33 words / sec., each example can support a large number of interactive sessions:
- 1 node + 4 GPUs: 414 wps / 3.33 wps / session = 124 simultaneous sessions
- 2 nodes + 8 GPUs: 782 wps / 3.33 wps / session = 235 simultaneous sessions
- 2 nodes + 12 GPUs: 1,035 wps / 3.33 wps / session = 311 simultaneous sessions
- 3 nodes + 16 GPUs: 1,246 wps / 3.33 wps / session = 374 simultaneous sessions
Futurum Group Comment: Clearly, the GPU based results significantly exceed those of the CPU based deployment examples. In these examples, we can see that once again, performance scales well, although not quite linearly. Perhaps more importantly, as additional nodes are added, the latency does not increase above 100 ms., which is well below our established desired threshold. Additionally, the inferencing software stack was very similar to the CPU only stack, with the addition of Nvidia libraries in place of Intel CPU libraries. |
Batch Processing Performance
Inferencing of LLMs becomes memory bound as the model size increases. For larger models such as Llama2-70B, memory bandwidth, between either the CPU and main memory, or GPU and GPU memory is the primary bottleneck. By batching requests, multiple processes may be processed by the GPU or CPU without loading new data into memory, thereby improving the overall efficiency significantly.
Having an inference serving system that can operate at large batch sizes is critical for cost efficiency, and for large models like Llama2-70B the best cost/performance occurs at large batch sizes.
In Figure 4 below we show the throughput capabilities of the same hardware configuration used in Figure 3, but this time with a larger batch size of 256.

Figure 4: Batch Inferencing Performance for GPUs (Source: The Futurum Group)
For this example, we would not claim the ability to support interactive sessions. Rather the primary consideration is the total throughput rate, shown in words per second. By increasing the batch size by a factor of 4X (from 32 to 256), the total throughput more than doubles, along with a significant increase in the per word latency, making this deployment appropriate for offline, or non-interactive scenarios.
Futurum Group Comment: Utilizing the exact same inferencing software stack, and hardware deployment, we can show that for batch processing of AI, the PoC example is able to achieve rates up to nearly 3,000 words per second. |
Comparison of Batch vs. Interactive
As described previously, we utilized a total throughput rate of 200 words per minute, or 3.33 words per second, which yields a maximum delay of 300 ms per word as a level that would produce acceptable interactive performance. In Figure 4 below, we compare the throughput and associated latency of the “interactive” configuration to the “batch” configuration.

Figure 5: Comparison of Interactive vs. Batch Inferencing on GPUs (Source: The Futurum Group)
As seen above, while the total throughput, measured in words per second increases by 2.4X, the latency of individual word output slows substantially, by a factor of 6X. It should be noted that in both cases batching was utilized. The batch size of the “interactive” results was set to 32, while the batch size of the “batch” results utilized a setting of 256. The “interactive” label was applied to the lower results, due to the fact that the latency delay of 100 ms. was significantly below the threshold of 300 ms. for typical interactive use. In summary:
- Throughput increase of 2.4X (1,246 to 2,962) for total throughput, measured in words per second
- Per word delays increased 6X (100 ms. to 604 ms.) measured as latency in milli-seconds
These results highlight that total throughput can be improved, albeit at the expense of interactive performance, with individual words requiring over 600 ms (sixth tenths of a second) when the larger batch size of 256 was used. With this setting, the latency significantly exceeded the threshold of what is considered acceptable for interactive use, where a latency of 300 ms would be acceptable.
Highlights for IT Operations
While terms such as tokens per second, and token latency have relevancy to AI practitioners, these are not particularly useful terms for IT professionals or users attempting to interact with generative LLM models. Moreover, we have translated these terms into more meaningful terminology that can help IT operations correctly size the hardware requirements to match expected usage. In particular, for interactive sessions requiring a rate of 200 words per second, and maximum delay of 300 ms. per word, we can then translate a total word per second throughput, into simultaneous streams. By using a rate of 3.33 words per second as the minimum per interactive session, we can determine the number of interactive sessions supported at a certain throughput and latency levels.
Nodes | Total Cores | Words /sec. | Word. Lat. (ms) | # Sessions |
1 | 112 | 11.45 | 111 | 3.4 |
1 | 224 | 20.17 | 140 | 6.1 |
2 | 448 | 40.75 | 152 | 12.2 |
Table 1: Interactive Inferencing Sessions using CPUs (Source: The Futurum Group)
Nodes | Total GPUs | Words /sec. | Word. Lat. (ms) | # Sessions |
1 | 4 | 414 | 76 | 124 |
2 | 8 | 782 | 100 | 235 |
2 | 12 | 1035 | 100 | 310 |
3 | 16 | 1246 | 100 | 374 |
Table 2: Interactive Inferencing Sessions using GPUs (Source: The Futurum Group)
The ability to scale inferencing solutions is important, as outlined previously. Additionally, perhaps the most unique aspect of this PoC is the ability to support operating an AI inferencing stack across both CPU only and GPU enhanced hardware architectures, using an optimized inferencing stacks for each hardware type.
For environments requiring only a few simultaneous inferencing sessions, it is possible to meet these needs with CPU only deployments, even when using a larger LLM model such as Llama2-70B utilized during testing. A current Dell PowerEdge server with a 4th generation processor can support up to 3 simultaneous interactive inferencing sessions per server, with a 3-node CPU cluster able to support up to 12 simultaneous sessions, at a total rate of 40 words per second across all three systems.
Use cases that require higher throughput, or the ability to support a greater number of simultaneous inferencing sessions can utilize a single GPU based PowerEdge server with 4 GPUs, which was found to support up to 124 simultaneous interactive sessions. Scaling beyond this, a 3-node, 16 GPU system was able to support 373 simultaneous inferencing sessions at a rate of 200 words per minute, for a total throughput of 1,245 words per second.
Highlights for AI Practitioners
A key aspect of the PoC is the software stack that helps provide a platform for AI deployments, enabling scale-out infrastructure to significantly increase content creation rates. Importantly, this AI Platform as a Service architecture was built using Dell and Broadcom hardware components, coupled with cloud native components to enable containerized software platform with open licensing to reduce deployment friction and reduce cost.
At a high-level, the inferencing stack is comprised of Ray-Serve, under-pined by vLLM to improve memory utilization during inferencing, including Hugging Face Optimum libraries and ONNX. Additionally, specific libraries were used to further enhance performance, including ROCm for AMD CPUs and GPUs, BigDL for Intel CPUs and CUDA for Nvidia GPUs. Other AI frameworks include the use of PyTorch within each container, along with Kubernetes and KubeRay for distributed cluster management. Shown in Figure 5 is a high-level architecture of the inferencing stack used for all hardware deployments.
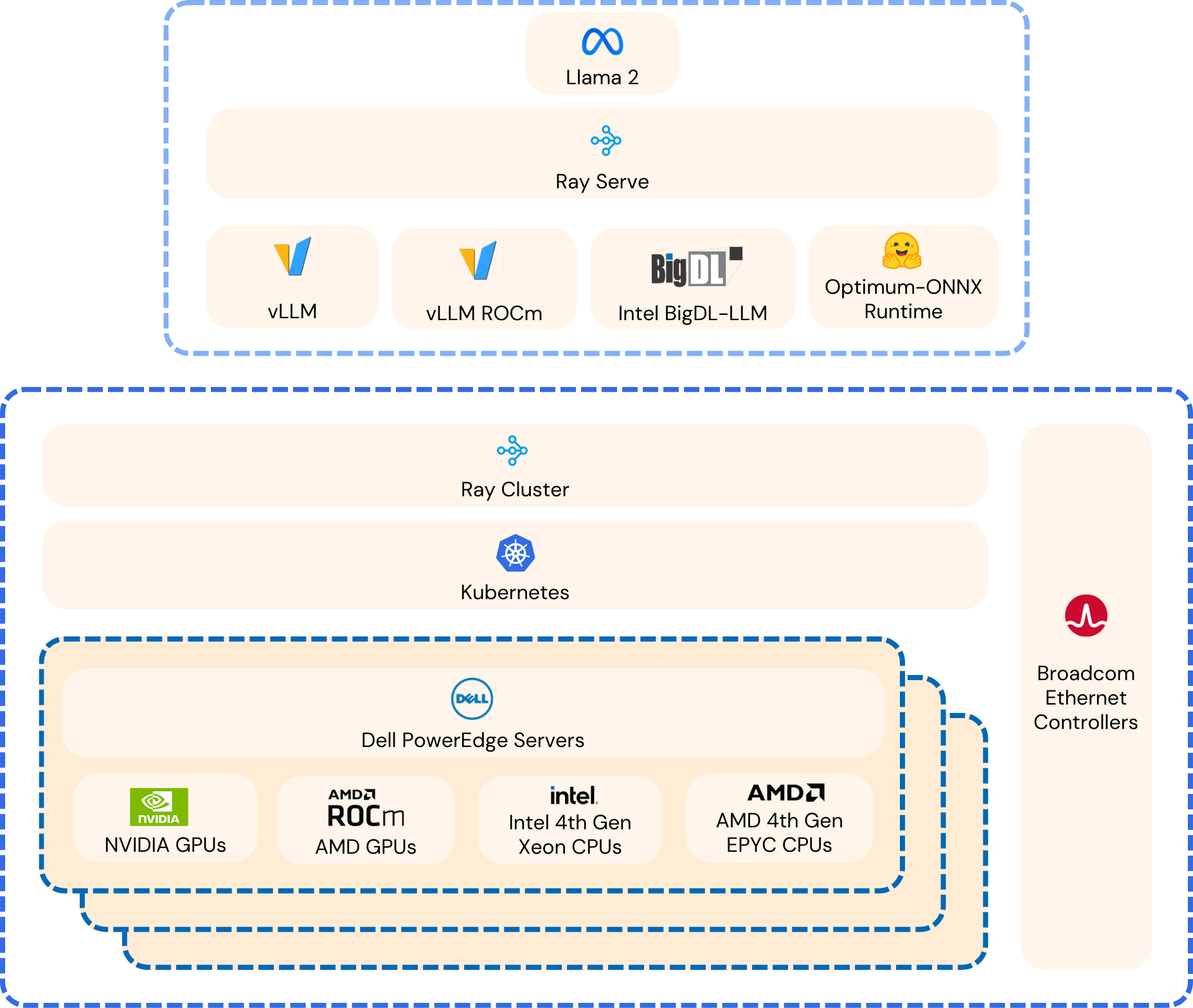
Figure 6: Distributed Inferencing Framework for Heterogeneous Hardware (Source: Scalers.AI)
Variations of the depicted inferencing framework were utilized for the four different hardware types, (AMD CPU, Intel CPU, AMD GPU and Nvidia GPU). The specifics of each of these are provided in the Appendix, in Figures A1-A4.
Note: It is important to recognize that while both Intel and AMD CPUs were verified and tested, only the Intel CPU results are presented here. This is for several reasons, including the fact that comparing CPU performance was not an objective of this PoC. If competing systems performance was provided, the focus would artificially become more about comparing CPU results than showcasing the ability to run across different CPU types. Similarly, while both AMD and Nvidia GPU inferencing was verified, only the Nvidia GPU results are presented, to maintain the focus on the PoC capabilities rather than comparing different GPU vendors performance.
Final Thoughts
As artificial intelligence, and in particular Generative-AI matures, companies are seeking ways to leverage this new technology to provide advantages for their firms, helping to improve efficiency and other measures of user satisfaction. GenAI based Large Language Models are quickly showing their ability to augment some applications focused both on empowering internal users with additional knowledge and insights, and is also becoming increasingly useful for assisting clients, via chatbots or other similar interfaces. However, organizations often have concerns about becoming tied to proprietary, or cloud-based solutions, due to their privacy concerns, lack of transparency or potential vendor lock in.
As part of Dell’s continuing efforts to democratize AI solutions, this proof-of-concept outlines specifically how organizations can build, deploy and operate production use of generative AI models using industry standard Dell servers. In particular, the scale-out PoC detailed in this paper showcases the ability to scale a solution efficiently from supporting a few simultaneous interactive users, up to a deployment supporting hundreds of simultaneous inferencing sessions simultaneously using as few as 3 Dell PowerEdge servers augmented by Nvidia GPUs. In an offline, or batch processing use, the same hardware example can support a throughput of nearly 3,000 words per second when processing multiple documents.
Critically, all the examples leverage a common AI framework, consisting of minimal K3s Kubernetes deployments, along with the Ray framework for distributed processing and vLLM to improve distributed inferencing performance. The outlined PoC utilizes the Hugging Face repository and libraries, along with hardware specific optimizations for each specific deployment of CPU or GPU type. By using a common framework, AI practitioners are better able to focus on enhancing the accuracy of the models and improved training methodologies, rather than trying to debug multiple solution stacks. Likewise, IT operations staff can utilize standard hardware, along with common IT technologies such as Kubernetes running on standard Linux distributions.
References
[1] Futurum Group Labs: Dell and Broadcom Release Scale-Out Training for Large Language Models
Appendix
Due to the fact that LLM inferencing is often memory bound, and due to the manner in which LLMs iteratively generate output, it is possible to optimize performance by batching input. By batching input, more queries are present within the GPU memory card, for the LLM to generate output leveraging the GPU processing. In this way, the primary bottleneck of moving data into and out of GPU memory is reduced per output generated, thereby increasing the throughput, with some increase in latency per request. These optimizations include the use of vLLM, Ray-Serve and Hugging Face Optimizations available through their Optimum inferencing models.
Moreover, continuous batching was utilized, in order to increase throughput with the vLLM library, which helps to manage memory efficiently. Two batch sizes were used with GPU configurations, 32 to provide a lower latency with good throughput, and a larger batch size of 256 to provide the highest throughput for non-interactive use cases where latency was not a concern.
Note: other metrics such as time to first token (TTFT) may be gathered; however, in our testing, the TTFT was not deemed to be a critical element for analysis.
3. Test Scenarios
The Llama 2 70B Chat HF model is loaded with a tensor parallelism of 4 GPUs. A 70B model (Float 32 precision) requires ~260 GB of GPU memory to load the model. Based on the model weight GPU memory requirement and inference requirements, we recommend using 4x80GB GPUs to load a single Llama 2 70B Chat model.
The Llama 2 70B Chat model with bfloat16 precision was used for all test configurations.
AI Inferencing Stack Details
In the figures below, we highlight the various specific stacks utilized for each hardware deployment.

Figure A1: Nvidia GPU inferencing stack (Source: Scalers.AI)

Figure A2: AMD GPU inferencing stack (Source: Scalers.AI)

Figure A3: Intel CPU inferencing stack (Source: Scalers.AI)

Figure A4: AMD CPU inferencing stack (Source: Scalers.AI)
Single Node Inferencing
The below table describes the single node inferencing Kubernetes deployment configuration with 4 GPUs (1 replica).
Device | Node Type | GPU | GPU Count | CPU Cores | Memory | Disk |
Dell PowerEdge XE9680 | Head | - | - | 160 | 300 GB | 1 TB |
Dell PowerEdge XE8545 | Worker | NVIDIA A100 SXM 80GB | 4 | 160 | 300 GB | 1 TB |
Table A1: Interactive Inferencing Sessions using GPUs (Source: Futurum Group)
Two Node Inferencing
Scenario 1: 8 GPUs, 2 Replicas, shown below.
Device | Node Type | GPU | GPU Count | CPU Cores | Memory | Disk |
Dell PowerEdge XE9680 | Head+ Worker | NVIDIA A100 SXM 80GB | 4 | 160 | 300 GB | 1 TB |
Dell PowerEdge XE8545 | Worker | NVIDIA A100 SXM 80GB | 4 | 160 | 300 GB | 1 TB |
Table A2: Interactive Inferencing Sessions using GPUs (Source: Futurum Group)
Scenario 2: 12 GPUs, 3 Replicas
Device | Node Type | GPU | GPU Count | CPU Cores | Memory | Disk |
Dell PowerEdge XE9680 | Head+ Worker | NVIDIA A100 SXM 80GB | 8 | 160 | 300 GB | 1 TB |
Dell PowerEdge XE8545 | Worker | NVIDIA A100 SXM 80GB | 4 | 160 | 300 GB | 1 TB |
Table A3: Interactive Inferencing Sessions using GPUs (Source: Futurum Group)
Three Node Inferencing
The below table describes the two node inferencing hardware configuration with 16 GPUs(4 replicas).
Device | Node Type | GPU | GPU Count | CPU Cores | Memory | Disk |
Dell PowerEdge XE9680 | Head+ Worker | NVIDIA A100 SXM 80GB | 8 | 160 | 300 GB | 1 TB |
Dell PowerEdge XE8545 | Worker | NVIDIA A100 SXM 80GB | 4 | 160 | 300 GB | 1 TB |
Dell PowerEdge R760xa | Worker | NVIDIA H100 PCIe 80GB | 4 | 160 | 300 GB | 1 TB |
Table A4: Interactive Inferencing Sessions using GPUs (Source: Futurum Group)
Test Workload Configuration
The workload consists of a set of 1000+ prompts passed randomly for each test [ML1] with different concurrent requests. The concurrent requests are generated by Locust tool.
The inference configuration is as below
- Input token length: 14 to 40.
- Output token length: 256
- Temperature: 1
The tests were run with two different batch sizes per replica - 32 and 256.
Test Metrics
The below are the metrics measured for each tests
Metric | Explanation |
Requests Per Second (RPS) | Evaluate system throughput, measuring requests processed per second. |
Total Token Throughput (tokens/s) | Quantify language model efficiency by assessing token processing rate. |
Request Latency (P50, P95, P99) | Gauge system responsiveness through different latency percentiles. |
Average CPU, Memory, GPU Utilization | Assess system resource usage, including CPU, memory, and GPU. |
Network Bandwidth (Average, Maximum) | Measure efficiency in data transfer with average and maximum network bandwidth. |
Table A5: Interactive Inferencing Sessions using GPUs (Source: Futurum Group)
Performance Results
Scalability results for batch size of 32 per replica
Inference Nodes | Devices | GPUs | Concurrent Requests | RPS | Tokens/s | P95 Latency(s) | P95 Token Latency(ms) | |
Single Node | Dell PowerEdge XE8545 | 4xNVIDIA A100 SXM 80GB | 32 | 2.7 | 621.4 | 13 | 50.78 | |
Two Nodes | Dell PowerEdge XE9680(4 GPUs) | 8xNVIDIA A100 SXM 80GB | 64 | 4.8 | 1172.63 | 17 | 66.41 | |
Two Nodes | Dell PowerEdge XE9680 | 12xNVIDIA A100 SXM 80GB | 96 | 6.8 | 1551.94 | 17 | 66.4 | |
Three Nodes | Dell PowerEdge XE9680 Dell PowerEdge R760xa | 12xNVIDIA A100 SXM 80GB 4xNVIDIA H100 PCIe 80GB | 128 | 8.3 | 1868.76 | 17 | 66.4 |
Table A6: Interactive Inferencing Sessions using GPUs (Source: Futurum Group)
Scalability results for batch size of 256 per replica
Inference Nodes | Devices | GPUs | Concurrent Requests | RPS | Throughput | P95 Latency | P95 Token Latency(ms) | |
Single Node | Dell PowerEdge XE8545 | 4xNVIDIA A100 SXM 80GB | 256 | 6.4 | 1475.64 | 45 | 175.78 | |
Two Nodes | Dell PowerEdge XE9680(4 GPUs) | 8xNVIDIA A100 SXM 80GB | 512 | 10.3 | 2542.32 | 61 | 238.28 | |
Two Nodes | Dell PowerEdge XE9680 | 12xNVIDIA A100 SXM 80GB | 768 | 14.5 | 3222.89 | 64 | 250 | |
Three Nodes | Dell PowerEdge XE9680 Dell PowerEdge R760xa | 12xNVIDIA A100 SXM 80GB 4xNVIDIA H100 PCIe 80GB | 1024 | 17.5
| 4443.5 | 103 | 402.34 |
Table A7: Interactive Inferencing Sessions using GPUs (Source: Futurum Group)
For more detailed report refer: Dell Distributed Inference Data
Test Methodology for Distributed Inferencing on CPUs
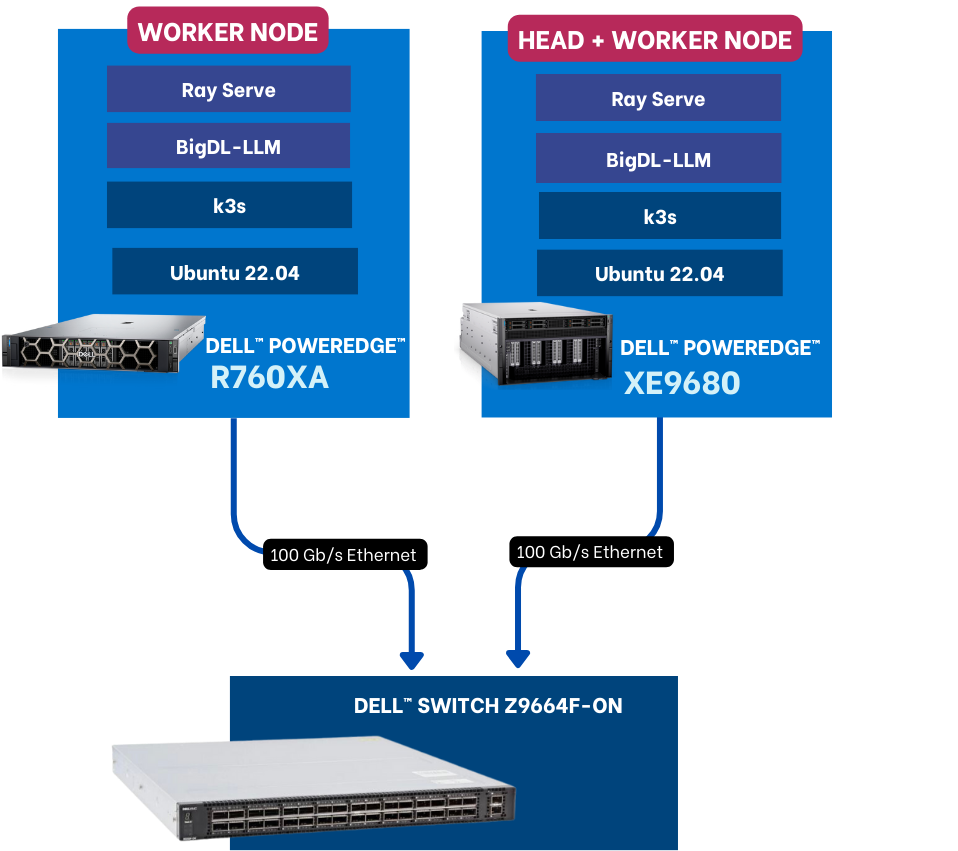
Server | CPU | RAM | Disk |
Dell PowerEdge XE9680 | Intel(R) Xeon(R) Platinum 8480+ | 2 TB | 3 TB |
Dell PowerEdge R760xa | Intel(R) Xeon(R) Platinum 8480+ | 1 TB | 1 TB |
Table A8: Interactive Inferencing Sessions using CPUs (Source: Futurum Group)
Each server is networked to a Dell PowerSwitch Z9664F-ON through Broadcom BCM57508 NICs with 100 Gb/s bandwidth.
3. Test Scenarios
The Llama 2 7B Chat HF model is tested on CPU with int8 precision.
3.1 Single Node Inferencing
Three are two scenarios for single node inferencing
Scenario 1: 112 Cores, 1 Replicas
The below table describes the single node inferencing Kubernetes deployment configuration with 112 CPU Cores of Dell PowerEdge R760xa server (1 replica).
Device | Node Type | CPU Cores | Memory | Disk |
Dell PowerEdge XE9680 | Head | - | 500 GB | 1 TB |
Dell PowerEdge R760xa | Worker | 112 | 500 GB | 1 TB |
Table A9: Interactive Inferencing Sessions using GPUs (Source: Futurum Group)
Scenario 2: 224 Cores, 2 Replicas
The below table describes the single node inferencing Kubernetes deployment configuration with 224 CPU Cores of Dell PowerEdge R760xa server (2 replicas).
Device | Node Type | CPU Cores | Memory | Disk |
Dell PowerEdge XE9680 | Head | 10 | 500 GB | 1 TB |
Dell PowerEdge R760xa | Worker | 224 | 500 GB | 1 TB |
Table A10: Interactive Inferencing Sessions using GPUs (Source: Futurum Group)
3.2 Two Node Scenario
The below table describes the two-node inferencing hardware configuration with both the servers, 448 Cores of CPU (4 replicas).
Device | Node Type | CPU Cores | Memory | Disk |
Dell PowerEdge XE9680 | Head | 224 | 500 GB | 1 TB |
Dell PowerEdge R760xa | Worker | 224 | 500 GB | 1 TB |
Table A11: Interactive Inferencing Sessions using GPUs (Source: Futurum Group)
3. Test Workload Configuration
The workload consists of a set of 1000+ prompts passed randomly for each test with different concurrent requests. The concurrent requests are generated by Locust tool.
The inference configuration is as below
- Input token length: 14 to 40.
- Output token length: 256
- Temperature: 1
The tests were run with 1 batch size per replica.
5. Test Metrics
The below are the metrics measured for each tests
Metric | Explanation |
Requests Per Second (RPS) | Evaluate system throughput, measuring requests processed per second. |
Total Token Throughput (tokens/s) | Quantify language model efficiency by assessing token processing rate. |
Request Latency (P50, P95, P99) | Gauge system responsiveness through different latency percentiles. |
Average CPU, Memory | Assess system resource usage, including CPU, memory. |
Network Bandwidth (Average, Maximum) | Measure efficiency in data transfer with average and maximum network bandwidth. |
Table A12: Interactive Inferencing Sessions using GPUs (Source: Futurum Group)
4. Performance Reports
Inference Nodes | Devices | CPU Cores | Concurrent Requests | RPS | Throughput | P95 Latency(s) | P95 Token Latency(ms) | |
Single Node | Dell PowerEdge R760xa | Intel Xeon Platinum 8480+ (112 Cores) | 1 | 0.1 | 17.18 | 18 | 70.31 | |
Single Node | Dell PowerEdge R760xa | Intel Xeon Platinum 8480+ (224 Cores) | 2 | 0.1 | 30.26 | 21 | 82.03
| |
Two Nodes | Dell PowerEdge XE9680 | Intel Xeon Platinum 8480+ (448 Cores) | 4 | 0.3 | 61.13
| 23 | 89.84 |
Table A13: Interactive Inferencing Sessions using GPUs (Source: Futurum Group)
About The Futurum Group
The Futurum Group is dedicated to helping IT professionals and vendors create and implement strategies that make the most value of their storage and digital information. The Futurum Group services deliver in-depth, unbiased analysis on storage architectures, infrastructures, and management for IT professionals. Since 1997 The Futurum Group has provided services for thousands of end-users and vendor professionals through product and market evaluations, competitive analysis, and education.
Copyright 2024 The Futurum Group. All rights reserved.
No part of this publication may be reproduced or transmitted in any form or by any means, electronic or mechanical, including photocopying and recording, or stored in a database or retrieval system for any purpose without the express written consent of The Futurum Group. The information contained in this document is subject to change without notice. The Futurum Group assumes no responsibility for errors or omissions and makes no expressed or implied warranties in this document relating to the use or operation of the products described herein. In no event shall The Futurum Group be liable for any indirect, special, inconsequential, or incidental damages arising out of or associated with any aspect of this publication, even if advised of the possibility of such damages. All trademarks are the property of their respective companies.
This document was developed with funding from Dell Inc. and Broadcom. Although the document may utilize publicly available material from various vendors, including Dell, Broadcom and others, it does not necessarily reflect such vendors' positions on the issues addressed in this document.

Foundation for Enterprise Security and Cyber Resiliency: Dell PowerEdge and Broadcom
Wed, 13 Mar 2024 20:49:09 -0000
|Read Time: 0 minutes
Executive Summary
There are numerous challenges companies face to establish and maintain the cybersecurity capabilities required to operate in today’s complex and increasingly hostile digital world. Companies are reminded daily of the potential cost to their reputation, revenue and more for failing to maintain a competent cyber resiliency profile. Often, even a single breach can result in regulatory fines, loss of revenue and customers, and in some cases may even cause existential implications for a firm.
A Futurum Group study conducted in 2023, with more than 150 IT Security professionals from companies with 1,000 or more employees resulted in several insights. More than 80% of companies surveyed reported an increase in their cybersecurity budgets while nearly 50% are increasing their cybersecurity headcount in response to these growing threats. In terms of challenges faced, the top two items were limited budgets and high solution costs, indicating a need to improve cybersecurity without significant cost implications.
As part of The Futurum Group’s ongoing research and analysis, The Futurum Group Labs has developed a cyber-resiliency framework that is designed as a holistic tool for evaluating how well a product or service offering helps a company meet their cybersecurity requirements. This framework incorporates multiple industry standards and best practices to provide a comprehensive perspective for evaluating their security requirements. The Futurum Group utilizes this framework when evaluating security aspects of products and services.
In this paper we review the important security features of Dell and Broadcom components, and how they can help companies improve their security posture and overall cyber resiliency. The Futurum Group Labs tested Dell 16th Generation PowerEdge servers with Broadcom 57508 Ethernet Network Interface Card (NIC) and PERC RAID controller cards both within our lab facilities, and remotely within Dell’s lab. This analysis provides a real-world use case of managing security across a multi-site, distributed environment.
Summary of Findings
The Futurum Group Labs performed hands on testing and review of many of the security features and capabilities of Dell PowerEdge 16th Generation servers, together with Broadcom 57508 dual port 100 Gb Ethernet NIC and Broadcom SAS4116W ROC based Dell PERC 12, H965i RAID cards. Our evaluation included analyzing security best practices, along with overall system security features and capabilities.
Additionally, The Futurum Group has developed a security framework comprising areas for review across multiple areas of enterprise security. The Futurum Group’s Security Framework builds upon industry best practices and multiple NIST standards and provided the basis for our evaluation process.
Against this framework, we found the Dell PowerEdge servers, together with Dell PowerEdge RAID Controller 12 (PERC) and Broadcom NICs provided an integrated security solution that met or exceeded requirements in all areas evaluated. Strengths included the following areas:
- Adherence to standards, including the NIST concepts of Identify, Protect, Detect, Respond & Recover
- Zero Trust security principles utilized by both Dell and Broadcom for all aspects of the systems
- Integrated security management via iDRAC, OME and CloudIQ provide enterprise-wide capabilities
- Dell’s Secure Component Verification Process helps ensure security from order to delivery
Futurum Group’s Security Framework
The Futurum Group has developed a security framework for evaluating the overall cyber resiliency rating of products operating within IT environments. This framework encompasses multiple inter-related aspects of security including ensuring that secure design methodologies are utilized during product creation.
The first area assessed is the design methodology utilized for developing products and services. Next the security features of a product are evaluated, along with the security of the manufacturing and supply chain processes. Finally, the IT security implementation of a company using the product is important. Taken together, these components provide a comprehensive tool for evaluating and analyzing the security profile of a product operating within a particular company. An overview is shown in Figure 1.
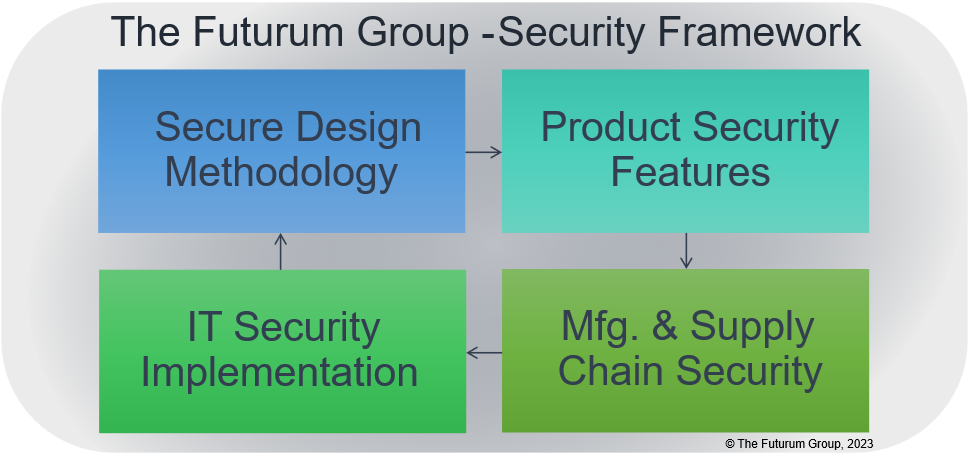
Figure 1: Security Framework Overview (Source: The Futurum Group)
It should be noted that “IT Security Implementation” was outside of the scope of work for this project. Since security responsibilities fall upon each company to utilize and implement security features appropriately.
Dell Solution Overview
As a foundation for securing PowerEdge server products, intrinsic security practices are incorporated into hardware product design and software or firmware code development. These practices include the following processes to ensure security features are implemented at the time of product inception and continue throughout the development cycle. To perform this practice effectively, Dell engineers are required to take mandatory security training before handling the code. Security “champions” are assigned to each development team to drive a security culture within the organization. Dell combines all components to create an integrated solution with hardware, software and services that together address security threats companies are facing.
Dell and Broadcom asked The Futurum Group Labs to evaluate Dell’s servers together with Broadcom add-in cards with respect to how these products can help IT clients address security vulnerabilities and achieve the levels of cyber resiliency necessary for operations in today’s challenging environment.
Specifically, The Futurum Group Labs validated the latest, 16th Generation Dell PowerEdge servers, together with Dell - Broadcom PERC 12 RAID cards and Broadcom 57508 NIC cards, along with relevant firmware and software that address security and cyber resiliency within IT environments. The Broadcom components helped provide overall end-to-end security capabilities through integration into Dell’s management tools.

Figure 2: Dell PowerEdge and Broadcom NIC Products (Source: Dell and Broadcom)
Dell’s Security Principles for Cyber Resiliency
As companies have become increasingly sophisticated in their approach to security, it is clear that point solutions are insufficient to address today’s complex cybersecurity requirements. While there is naturally a focus on the hardware components themselves, an important part of the overall Dell and partner security ecosystem is the use of critical software elements that help enable security features and provide easy-to-use interfaces for IT users.
| Futurum Group Comment: Too often, security features require IT administrators to choose between usability or security. As a result, IT administrators may ignore or circumvent security best practices to improve ease of use. The management tools of the PowerEdge systems enable IT users to easily follow best practices while utilizing the comprehensive security features of Dell servers and Broadcom. This functionality helps reduce attack surfaces for malicious actors, while maintaining usability and performance. |
As described previously, The Futurum Group’s Security Framework incorporates multiple best practices and industry standards, including NIST Cybersecurity Framework (CSF) which outlines five tenants:
- Identify: Ensure that an organization understands and can manage cybersecurity risk, assets, and data
- Protect: Develop and implement appropriate safeguards to ensure critical infrastructure is protected
- Detect: Quickly detect cyber events via anomaly detection and continuous monitoring
- Respond: Prepare and implement the ability to take appropriate action in response to a cyber event
- Recover: Establish the ability to maintain business resiliency and restore impacted systems
The Futurum Group Security Framework extends the NIST framework, including the following areas for assessing Dell’s Cyber Resilient Architecture for security:
- User authentication and authorization using multi-factor authentication applied to users and devices (User AA and Device AA) with role-based and least privileged access controls.
- Dell PowerEdge hardware RoT creates a chain of trust from firmware to devices and supports complete customization of Secure Boot, including removal of all industry-standard certificates provided by Microsoft, VMware, or the UEFI CA.
- Using PowerEdge cyber resilient platform RoT extends to Secure Enterprise Key Management for data-at-rest protection.
- Applications and workload security to protect runtime environments, leveraging data and network security technologies including end-to-end encryption and cryptographic signatures.
- Utilize Security Protocol and Data Model (SPDM) capabilities for device attestation as part of the Zero-Trust/cyber resiliency architecture. Future capabilities include internal encrypted communication capabilities.
- Auditing and analytics for visibility and alerting of security issues using persistent event logging and real-time code and firmware scanning.
- Automation and orchestration technologies to enable automated API and CLI driven actions, along with enterprise web UI tools to provide easy-to-use global management of security alerting, reporting and automation.
Test and Validation Findings
The Futurum Group Labs Security Framework shown previously in Figure 1, was used to analyze the overall security capabilities of products or features. Our analysis examined each aspect of the Security Framework with details provided in the following four sections.
1 - Secure Design Methodology
Requirements
Confirm that security considerations begin at product inception with cybersecurity and resiliency capabilities integrated throughout product design and development.
Verify that hardware security features based on Zero Trust, such as tamper proof TPM often form the basis of software security, to deliver an integrated secure system.
Asses if the software architectures leverage hardware security and utilize the available security capabilities. Additionally, validate that threat modeling and penetration testing along with external audits and ongoing mitigation of vulnerabilities are performed.
Dell PowerEdge and Broadcom Design
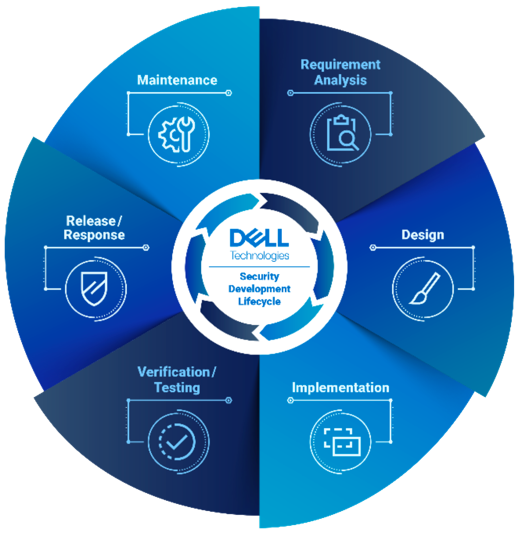
Dell utilizes a secure Software Development Lifecycle (SDL) as the basis for instilling security throughout the design process. A comprehensive SDL process should ensure that any identifiable attack methods are mitigated utilizing standards-based security mechanisms to thwart these attack vectors.
As outlined previously, security starts with using a secure design methodology, with multiple considerations required to help products provide cyber resiliency:
| - Security is considered for each feature - Following industry best practices, Dell software is designed to obstruct, oppose and counter malicious attacks - External audits of security features - On-going evaluation of new vulnerabilities - Rapid response to common vulnerability exposures (CVEs) with remediation | |
Table 1: Dell SDL Principles | Figure 2: Dell SDL Model |
Additional aspects of secure design include end-to-end secure communication based upon cryptographically signing certificates used to authenticate and authorize components such as with Device-ID, 802.1x, and SPDM.
Finally, even with good design and secure implementations, vulnerabilities and breaches may still occur. Thus, it is important for products to be designed with resiliency and Zero Trust implementation, so that when penetrations do occur, their impact is limited. Dell’s rapid response to critical CVEs and patching of identified components is an important aspect of mitigating threats from CVE’s as they arise.
| Futurum Group Comment: Dell’s rapid response to critical CVEs and patching of identified components is an important aspect of mitigating threats from CVE’s as they arise. As one of the largest system vendors, Dell leverages their significant real-time monitoring via CloudIQ and other tools, to quickly respond to emerging threats and provide their customers with tools and processes to thwart attacks. |
2 – Product Security Features
Product security was an area of particular focus by The Futurum Group Labs when measuring how Dell PowerEdge servers, together with Broadcom based PERC 12 and 57508 Ethernet NICs met Futurum’s Security Framework. System security requires a layered approach, with hardware security features and capabilities utilized by the firmware, that provides a secure foundation for the operating system (OS) and applications running within the OS. The hardware root of trust provides several foundational security capabilities including a secure, tamper-proof key storage location, a unique hardware encryption key, and other facilities required as part of a cryptographic framework.
Specifically, The Futurum Group Labs tested the following system components:
- Dell PowerEdge 16th Generation systems with a Trusted Platform Module (TPM)
- Dell PERC 12 (PowerEdge RAID Controller, 12th generation)
- Broadcom 57508 Dual Port, 100 Gb Ethernet NIC with QSFP adapter connectivity
- Secure BIOS management system settings, via iDRAC
- Device identification via cryptographic framework (devices attestation uses a devices hardware RoT)
Each aspect of a system must be secured, ideally with each element utilizing industry best practices including Zero Trust principles, enabled via a silicon Root of Trust (RoT) as the foundation of physical security. Utilizing a certified RoT device that provides tamper resistance, the hardware protects the device firmware, which in turn is utilized to ensure critical software security features are verifiably operating securely. Security breach examples could include the exchange of entire PCIe cards, uploading compromised firmware or other attacks that target PCIe cards.
Delivering end-to-end security requires the entire solution integrates multiple hardware RoT devices, together with software features that leverage the underlying hardware capabilities. Dell’s PowerEdge servers together with Broadcom NIC and RAID controllers provide this capability by validating each layer, from hardware to firmware and the OS using cryptographic attestation. Dell’s iDRAC and other management tools leverage this integrated security environment to deliver a secure, easy to manage solution.
| Futurum Group Comment: A key aspect of the Zero Trust approach is to utilize hardware RoT devices to provide cryptographic verification to build a secure ecosystem. Using Zero Trust, each component first verifies, then trusts their counterpart based upon certified key exchanges and mutual authentication, attestation and authorization. These features are critical for the additional security mechanisms used throughout the Dell servers along with supported devices. |
As part of a standards-based approach to secure system management, a new Security Protocol and Data Model (SPDM) standard has emerged. This standard leverages Zero Trust principles and enables devices to securely verify each other (device attestation) and then establish secure communications over a variety of internal, server transport connections. Dell’s 16th Generation servers, along with 12th generation PERC and Broadcom 57508 NICs now utilize SPDM, to enhance security. The SPDM standard leverages existing technologies including public key encryption, and cryptographic signing of certificates to provide device attestation between Dell’s servers and Broadcom devices. In future implementations, the SPDM standard can also enable secure communication channels between devices.
Broadcom Networking
Broadcom 57508 Ethernet NIC, with speeds from 25 Gb to 200 Gb operate with Dell’s security features and leverage some of the same Zero Trust principles. Broadcom’s NICs also have a hardware based, silicon RoT which enable multiple additional benefits, including:
- Silicon RoT with secure key storage on servers and PCIe devices
- Secure firmware loading, updates and recovery on servers and PCIe devices
- Signed UEFI drivers, with Secure PXE boot for onboard NICs and PCIe NICs
- Device attestation (SPDM 1.2) between servers and devices, and audit logging of all devices
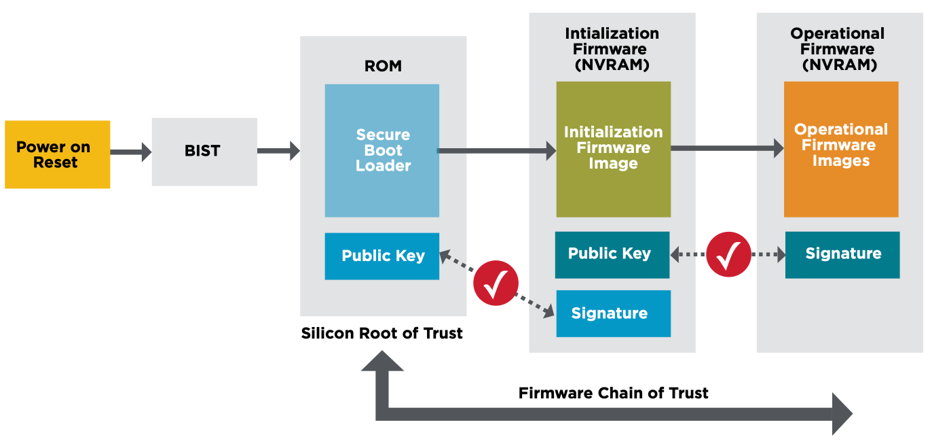
Figure 3: Broadcom’s Silicon RoT w/ Secure Firmware Loading (Source: Broadcom)
Hardware TPM
The Futurum Group Labs verified that Dell PowerEdge’s hardware security operated correctly by testing the supplied TPM version 2.0. Testing verified that all supplied features operated correctly including key generation using a true random number generator, and a secure key store. Additionally, after verifying TPM functionality, we then enabled security features including secure boot, secure lifecycle management, out of band management, and firmware updating.
Dell PowerEdge RAID Controller (PERC)
Dell’s PowerEdge RAID Controllers, aka PERC 12th generation use Broadcom controller interfaces and support a variety of RAID levels and device connectivity. The PERC 12 H965i controllers tested are designed for internal and external device support and include multiple RAID levels along with SAS and NVMe connectivity.
The Dell 12th gen PERC security features include:
- Silicon based hardware RoT: Foundation for Zero Trust
- Onboard RoT builds a chain of trust by authenticating all PERC firmware prior to execution, permits only authenticated firmware upgrades
- SPDM support: Provides device attestation and secure communications
- UEFI secure boot: Helps reduce attack vectors, and root kit installations
- Secure Firmware Updates: Simplifies administrative security updates
As shown above previously in Figure 3, the process for secure booting from a Dell PERC 12 controller card is similar to securely booting via a NIC.
Dell PowerEdge 16th Generation Servers
Multiple areas of evaluation and testing were performed with the PowerEdge servers together with PERC RAID cards and Broadcom NICs. One of NIST’s specifications (NIST SP 800-193) specifically addresses platform firmware resiliency. It stipulates methods for securing the BIOS, boot ROMS, along with firmware and driver signatures to verify authenticity. This guideline also outlines a method for providing a “secure boot” mechanism, whereby each component verifies subsequent components in the stack from hardware all the way to the operating system.
Secure Boot
Dell PowerEdge secure boot via Broadcom NIC, Dell PERC or local disk occurs via similar mechanisms. The secure boot process is important to ensure that a validated OS image is ultimately loaded and is used to operate the system. If an OS is altered, system security cannot be guaranteed. At a high-level, secure boot validates the UEFI drivers and boot loaders which then guarantees the authenticity and integrity of each subsequent component, firmware or software element that is loaded. This chain of trust is one of the basic elements of the Zero Trust model and basic system security. Secure boot functionality was verified with multiple devices, including secure boot of a verified OS image from Dell’s PERC 12 controller, and via PXE boot using a Broadcom 100 GbE NIC card.
Authentication Access, Authorization and Auditing (IAM)
These areas include identity and access management of systems (IAM), components and users, multi-factor authentication, audit logging and alerting, and access based upon authenticated authorization. The IAM capabilities are implemented throughout Dell’s management tools, including iDRAC, OME and CloudIQ.
Secure Lifecycle Management
Secure lifecycle management features were verified by first establishing a baseline, and then updating to the latest firmware and drivers via iDRAC. The secure process was verified both via the successful updates and notices, along with one image that did not update due to an invalid security certificate. The test properly identified an invalid certificate, and would not allow the firmware to be updated, which was the correct behavior. Upon obtaining a firmware image with the proper security certificate, the firmware update was successfully applied, which again was the desired security behavior.
Management, Alerting and Reporting
A critical part of Dell’s cybersecurity capabilities are the management tools available. Dell’s iDRAC tool continues to evolve and add capabilities for BIOS and low-level system management of PowerEdge servers and attached devices. Incorporating standards such as Redfish for secure remote manageability, enables secure programmatic API, CLI and scripting access, while also enabling secure web UI access for users preferring a graphical interface.
The Futurum Group Labs utilized and validated numerous functions and capabilities of each of Dell’s enterprise management solution. iDRAC, Open Manage Enterprise and CloudIQ are designed to work together to enable a spectrum of management, alerting and reporting capabilities.
- Dell’s iDRAC: system level management software pre-installed on all Dell PowerEdge servers, providing secure out-of-the box management capabilities for individual systems.
- OpenManage Enterprise (OME): Designed for IT staff to monitor and manage Dell servers within a datacenter. OME provides roll-up features to aggregate information while still providing the ability to manage individual systems, either from within OME or via linking to iDRAC.
- CloudIQ: Enables multi-site and enterprise-wide monitoring and management, with high-level management and reporting while also providing drill-down system management of some features and function.
A key part of iDRAC with OME is the integration of Broadcom components throughout, including the ability to monitor Broadcom-based PERC and NICs for firmware levels, vulnerabilities and provide updates through the secure lifecycle management capabilities.
The Dell OME management server was utilized throughout testing. Installation was straightforward and accomplished without needing to consult manuals. Downloading a preconfigured VMware image (OVA) and deploying to a VMware cluster, the OME server was operational in under 30 minutes. OME provided a way to both perform health monitoring and alerting, along with active management of desired systems. The OME interface was intuitive and provided significant fleet management features, by helping to highlight potential issues and providing the ability to resolve problems.
| Futurum Group Comment: Looking specifically at the security features of iDRAC, OME and CloudIQ, we found the health and security scoring mechanism and recommendations to be extremely effective. A significant challenge for most IT environments is prioritizing which updates are the most critical and then quickly remediating these issues. Dell’s management tools enable finding and applying critical updates quickly, and is one of the most effective solutions for security we have evaluated to date. |
With CloudIQ’s health scores and recommendations, it required only a few clicks to sort by the most critical issues, and then utilize the appropriate management tools to apply remediation for the vulnerabilities. Some issues may be resolved entirely from CloudIQ, with others enabled via links to OME for remediation.
Dell’s CloudIQ service has continued to evolve since its storage system origins into a Dell product-wide SaaS application that effectively provides health monitoring and alerting, along with recommendations. Dell’s overall management architecture provides robust security manageability, alerting and reporting capabilities that provide the critical link IT administrators require to effectively manage a secure IT environment.
3 - Manufacturing & Supply Chain Security
The concept of evaluating a product’s manufacturing and supply chain for security is relatively new to many companies. Although these practices have been standard for regulated industries for years, only recently have companies began to apply supply chain security practices to products designed for commercial use. One reason is that due to increased focus on other threats, the supply chain is now seen as an area of increasing vulnerability.
One area of supply chain security that sets Dell apart from their competitors is Dell’s Secured Component Verification (SCV), which is designed to help verify that the security of all components is maintained from order until it is delivered and installed at the customers location. Dell’s approach to supply chain threats includes supply chain integrity with ISO certification of sites, software bill of materials and the Dell SCV process, which all help to prevent counterfeit components or malware being inserted into systems or components.
| Futurum Group Comment: Dell’s approach to securing product manufacturing and supply chain is perhaps the best processes the Futurum Group Labs has evaluated. In particular, Dell’s Secured Component Verification process provides unique value, enabling IT clients to quickly and easily ensure their products have not been altered or modified, including verification of both hardware and firmware components. Dell SCV is an important tool for addressing overall cybersecurity. |
An overview of the Dell SCV process is shown below in Figure 4.
Figure 4: Dell’s Secured Component Verification Process (Source: Dell)
The Futurum Group Labs verified that Dell’s SCV can accurately report on each major system element, showing whether it is a verifiable component that was part of the original bill of materials or not. The SCV leverages the earlier security principles and technologies outlined, including Secure RoT and hardware TPM modules, cryptographic signatures for device attestation and Zero Trust principles to create a process to verify that a system has not been altered in any way.
During testing The Futurum Group Labs verified that the SCV correctly verified components that were part of the original bill of material and order, and items that were added afterwards. This capability provides a unique and easy-to-use method for IT users to attest to the authenticity and integrity of their systems.
4 - IT Security Implementation
The last major component of the Futurum Group’s Security Framework is how well a company and the IT organization operates with respect to security. IT security has multiple standards, industry best practices and recommendations to help inform and guide companies towards implementations that provide the necessary security and cyber resiliency.
One guideline covering IT security is the NIST CSF [1] which includes the key phrases, Identify, Protect, Detect, Respond and Recover. The most recent update to this framework, the version 2.0 draft, adds a sixth area “Govern” to the previous list, placing more emphasis on corporate oversight and implementations.
Although important, this area falls largely outside the scope of vendors’ product offerings but may be supplemented via professional services and training. As a result, The Futurum Group did not formally assess the IT Security aspects of the Futurum Group’s Security Framework.
| Futurum Group Comment: The Futurum Group’s Security Framework evaluates IT security through the lens of a products ease-of-use and ability to implement security best practices. In this regard, Dell enables IT security by making security best practices the default option when possible, and ensuring security features are easy-to-use. As a result of security integration between PowerEdge servers, Broadcom 57508 NICs and Dell management tools helps companies implement security best practices. |
For companies that desire security consulting to help supplement their capabilities, Dell and their partners offer a variety of security services, including cybersecurity advisory services that are designed to assess a company’s security posture, and help improve internal procedures and help elevate security capabilities to attain proficiency in this area. Based upon the principles outlined previously, Dell security services include Cybersecurity Advisory Services, Recovery Services for Cyber-attacks, along with managed services for cyber-attack detection and response.
Moreover, the product design, product features, together with the secure supply chain features and security consulting services all provide sufficient tools to enable IT organizations to manage and maintain a highly secure environment that meets NIST and industry best practices for maintaining a cyber resilient posture.
Final Thoughts
Security and cyber resiliency have become areas of critical focus for enterprises according to The Futurum Group’s research. Additionally, conversations with IT clients often include a discussion of ransomware and cyber resiliency. Organizations that follow best practices follow the NIST or other frameworks to integrate security throughout their organization and operational procedures.
Attempting to purchase point products, or simply “add security” to existing infrastructure is challenging at best. Starting with products that are designed from the ground up with security is a key priority. According to The Futurum Group’s research, a significant number of security breaches utilize compromised servers as part of their attack vector. Thus, securing servers, their networking interfaces and storage devices is an ideal area of focus for companies looking to improve their cyber resiliency.
In assessing Dell PowerEdge servers together with Broadcom add-in cards against the Futurum Group’s Security Framework, we found that the systems meet or exceed requirements in all categories. There were several areas of strength noted, where PowerEdge significantly exceeded expectations. These include several security integrations between Dell’s silicon RoT and Zero Trust approach, together with Broadcom NICs and PERC RAID cards own embedded RoT and Zero Trust capabilities and importantly with Dell’s management tools.
Another area where PowerEdge exceeded expectations is the seamless management capabilities of iDRAC for baseboard system management, with OME for datacenter management, coupled with CloudIQ for global monitoring, alerting and reporting of multiple datacenters. The particular focus on security alerting and recommended actions of CloudIQ help IT administrators move from inaction due to an overwhelming number of issues, to action focused on the most important configuration or security issues.
Finally, Dell’s SCV process significantly exceeded expectations, offering a best-in-class end-to-end process for ensuring system integrity from suppliers, manufacturing and configuration, shipping, delivery and installation. A significant area of concern for organizations is ensuring their systems do not contain malicious hardware elements that could circumvent even robust security practices. Dell’s SCV provides a simple and easy way for organizations to ensure their infrastructure has not been compromised.
Taken together, Dell PowerEdge servers, with Broadcom NIC cards provide comprehensive security capabilities that provide a foundation for IT users to quickly and efficiently establish a highly secure computing environment that leverages industry best practices.
Resources
[1] NIST Cybersecurity Framework, draft version 2.0, August 2023:
About The Futurum Group
The Futurum Group is dedicated to helping IT professionals and vendors create and implement strategies that make the most value of their storage and digital information. The Futurum Group services deliver in-depth, unbiased analysis on storage architectures, infrastructures, and management for IT professionals. Since 1997 The Futurum Group has provided services for thousands of end-users and vendor professionals through product and market evaluations, competitive analysis, and education.
Copyright 2023 The Futurum Group. All rights reserved.
No part of this publication may be reproduced or transmitted in any form or by any means, electronic or mechanical, including photocopying and recording, or stored in a database or retrieval system for any purpose without the express written consent of The Futurum Group. The information contained in this document is subject to change without notice. The Futurum Group assumes no responsibility for errors or omissions and makes no expressed or implied warranties in this document relating to the use or operation of the products described herein. In no event shall The Futurum Group be liable for any indirect, special, inconsequential, or incidental damages arising out of or associated with any aspect of this publication, even if advised of the possibility of such damages. All trademarks are the property of their respective companies.
This document was developed with funding from Dell Inc. and Broadcom. Although the document may utilize publicly available material from various vendors, including Dell, Broadcom and others, it does not necessarily reflect such vendors' positions on the issues addressed in this document.