




Have you sized your Oracle database lately? Understanding server core counts and Oracle performance.
Mon, 24 Oct 2022 14:08:36 -0000
|Read Time: 0 minutes
Oracle specialists at Dell Technologies are frequently engaged by customers to help with database (DB) server sizing. That is, sizing DB servers that are stand-alone or part of a VxRail or PowerFlex system.
Server sizing is important in the fact that it helps ensure the CPU core count matches your workload needs, provides optimal performance, and helps manage Oracle DB software licensing costs.
Understanding CPU frequency
When sizing a server for an Oracle DB, CPU frequency matters. By CPU frequency, we are referring to the CPU cycle time, which can basically be thought of as the time it takes for the CPU to execute a simple instruction, for example, an Addition instruction.
In this blog post, we will use the base CPU frequency metric, which is the frequency the CPU would run at if turbo-boost and power management options were disabled in the system BIOS.
Focus during the sizing process is therefore on:
- Single-threaded transactions
- The best host-based performance per DB session
Packing as many CPU cores as possible into a server will increase the aggregate workload capability of the server more than it will improve per-DB session performance. Moreover, in most cases, a server that runs Oracle does not require 40+ CPU cores. Using the highest base-frequency CPU will provide the best performance per DB session.
Why use a 3.x GHz frequency CPU?
CPU cycle time is essentially the time it takes to perform a simple instruction, for example, an Addition instruction. A 3.x GHz CPU cycle time is lower on the higher frequency CPU:
- A 2.3 GHz CPU cycle time is .43 ns
- A 3.4 GHz CPU cycle time is .29 ns
A 3.x GHz CPU achieves an approximate 33% reduction in cycle time with the higher base frequency CPU.
Although a nanosecond may seem like an extremely short period of time, in a typical DB working environment, those nanoseconds add up. For example, if a DB is driving 3,000,000+ logical reads per second while also doing all the other host-based work, speed may suffer.
An Oracle DB performs an extreme amount of host-based processing that eats up CPU cycles. For example:
- Traversing the Cache Buffer Chain (CBC)
- The CBC is a collection of hash buckets and linked lists located in server memory.
- They are used to locate a DB block in the server buffer cache and then find the needed row and column the query needs.
- SQL Order by processing
- Sorting and/or grouping the SQL results set helps the server memory create the results set in the order the user intended to see.
- Parsing SQL
- Before a SQL statement can be started, it must be parsed.
- CPU is used for soft and hard parsing.
- PLSQL
- PLSQL is the procedural logic the application uses to run IF-THEN-ELSE, and DO-WHILE logic. It is the application logic on the DB server.
- Chaining a DB block just read from storage
- Once a new DB block is read from storage, it must be placed on the CBC and a memory buffer is “allocated” for its content.
- DB session logons and logoffs
- Session logons and logoffs allocate and de-allocate memory areas for the DB session to run.
- ACO – Advanced Compression Option
- ACO is eliminating identical column data in a DB block – once again, more CPU and RAM work to walk through server memory to eliminate redundant data.
- TDE – Transparent Data Encryption
- TDE encrypts and decrypts data in server memory when accessed by the user – on large data Inserts/Updates extra CPU is needed to encrypt the data during the transaction.
All of this host-based processing drives CPU instruction execution and memory access (remote/local DIMMs and L1, L2, and L3 caches). When there are millions of these operations occurring per second, it supports the need for the fastest CPU to complete CPU instruction execution in the shortest amount of time. Nanosecond execution time adds up.
Keep in mind, the host O/S and the CPU itself are:
- Running lots of background memory processes supporting the SGA and PGA accesses
- Using CPU cycles to traverse memory addresses to find and move the data the DB session needs
- Working behind the scenes to transfer cache lines from NUMA node to NUMA node, DIMM to the CPU core, and Snoopy/MESI protocol work to keep cache lines in-sync
In the end, these processes consume some additional CPU cycles on top of what the DB is consuming, adding to the need for the fastest CPU for our DB workload.
SLOB Logical Read testing:
The 3.x GHz recommendation is based on various Oracle logical read tests that were run with a customer using various Intel CPU models of the same family. The customer goal was to find the CPU that performs the highest number of logical read tests per second to support a critical application that predominantly runs single-threaded queries (such as no PQ – Parallel Query).
Each of the tests showed a higher base-frequency CPU outperformed a lower base-frequency CPU on a per-CPU core basis running SLOB logical read tests (i.e., no physical I/O was done, all host-based processing – only using CPU, Cache, DIMMs, and remote NUMA accesses).
In the tests performed, the comparison point across the various CPUs and their tests was the number of logical reads per second per CPU core. Moreover, the host was 100% dedicated to our testing and no physical I/O was done for the transactions to avoid introducing physical I/O response times in the results.
The following graphic depicts a few examples from the many tests run using a single SLOB thread (a DB session), and the captured logical read-per-second counts per test.
The CPU baseline was an E5-4627 v2, which has a 3.3GHz base frequency, but a 7.2GTs QPI and 4 x DDR3-1866 DIMM channels, versus the Skylake CPUs having a 10.2GTs UPI and 6 x DDR4-2666 DIMMs.
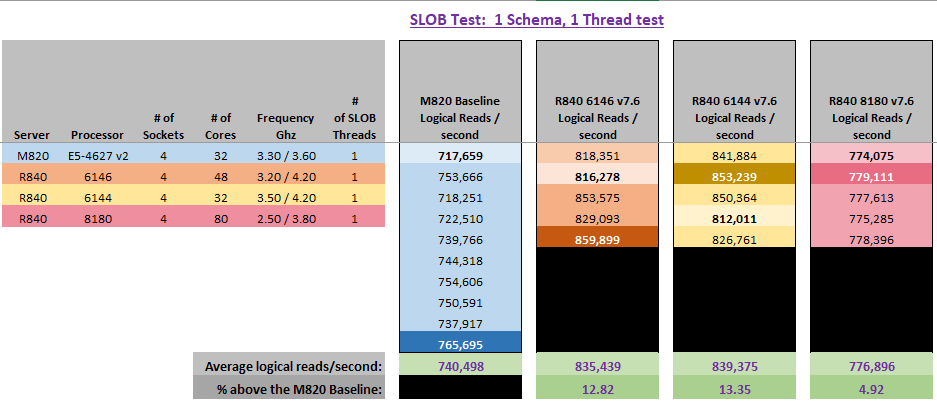
Why is there a variance in the number of logical reads per second between the test run of the same CPU model on the same server? Because SLOB runs a random read DB block profile which leads to more or less DB blocks being found on the local NUMA node the DB session was running on in the various tests. Hence, where fewer DB blocks were present, the remote NUMA node had to transfer DB blocks over the UPI to the local NUMA node, which takes time to complete.
If you are still wondering if Dell Technologies can help you find the right CPU and PowerEdge server for your Oracle workloads, consider the following:
- Dell has many PowerEdge server models to choose from, all of which provide the ability to support specific workload needs.
- Dell PowerEdge servers let you choose from several Intel and AMD CPU models and RAM sizes.
- The Oracle specialists at Dell Technologies can perform AWR workload assessments to ensure you get the right PowerEdge server, CPU model, and RAM configurations to achieve optimal Oracle performance.
Summary
If per-DB session, host-based performance is important to you and your business, then CPU matters. Always use the highest base-frequency CPU you can, to meet CPU power needs and maintain faster cycle times for Oracle DB performance.
If you need more information or want to discuss this topic further, a Dell Oracle specialist is ready to help analyze your application and database environment and to recommend the appropriate CPU and PowerEdge server models to meet your needs. Contact your Dell representative for more information or email us at askaworkloadspecialist@dell.com
Related Blog Posts

CPU to the Rescue: LLMs for Everyone

Wed, 24 Apr 2024 13:25:19 -0000
|Read Time: 0 minutes
Optimizing Large Language Models
The past year has shown remarkable advances in large language models (LLMs) and what they can achieve. What started as tools for text generation have grown into multimodal models that can translate languages, hold conversations, generate music and images, and more. That said, training and running inference servers of these massive, multi-billion parameter models require immense computational resources and lots of high-end GPUs.
The surge in popularity of LLMs has fueled intense interest in porting these frameworks to mainstream CPUs. Open-source projects like llama.cpp and the Intel® Extension for Transformers aim to prune and optimize models for efficient execution on CPU architectures. These efforts encompass plain C/C++ implementations, hardware-specific optimizations for AVX, AVX2, and AVX512 instruction sets, and mixed precision model representations. Quantization and compression techniques are exploited to shrink models from 16-bit down to 8-bit or even 2-bit sizes. The goal is to obtain smaller, leaner models tailored for inferencing on widely available CPUs from the data center to your laptop.
While GPUs may still be preferred for training, CPUs in data centers and on devices can be used for efficient deployment to inference with these optimized models. CPUs can leverage recent advancements in architecture and provide broader access to large language model capabilities. The past year's advances in model optimization and CPU inferencing show promise in bringing natural language technologies powered by large models to more users.
Hardware
To evaluate these new CPU inferencing tools, we leveraged Dell Omnia cluster provisioning software to deploy Rocky Linux on a Dell PowerEdge C6620 server. Omnia allows rapid deployment of several operating system choices across a cluster of PowerEdge servers featuring Intel® Xeon® processors. By using Omnia for automated OS installation and configuration, we could quickly stand up a test cluster to experiment with the inference capabilities of the CPU-optimized models on our Intel® hardware.
Table 1. Dell PowerEdge C6620 specifications
Hardware | Details |
Server | Dell PowerEdge C6620 |
Processor Model | Intel® Xeon® Gold 6414U (Sapphire Rapids) |
Processors per Node | 2 |
Processor Core Count | 32 |
Processor Frequency | 2GHz |
Host Memory | 256 GB, 8 x 32GB |
Table 2. Involved software specifications
Software | Details |
Omnia | |
Rocky Linux 8.8 | |
Intel® Extensions for Transformers | |
Llama 2 with Intel® Neural Speed
Intel® has open sourced several tools under permissive licenses on GitHub to facilitate development with the Intel® Extensions for Transformers. One key offering is Neural Speed, which aims to enable efficient inferencing of large language models on Intel® hardware. Neural Speed leverages Intel® Neural Compressor, a toolkit for deep learning model optimization, to apply low-bit quantization and sparsity techniques that compress and accelerate the performance of leading LLMs. This allows Neural Speed to deliver state-of-the-art efficient inferencing for major language models. Neural Speed provides an inference stack that can maximize the performance of the latest Transformer-based language models on Intel® platforms ranging from edge to cloud. By open sourcing these technologies with permissive licensing, Intel® enables developers to easily adopt and innovate with optimized LLM inferencing across Intel® hardware.
To get started, clone the Intel® Neural Speed repo and install packages:
git clone https://github.com/intel/neural-speed.git pip install -r requirements.txt pip install .
Neural Speed can support 3 different model types:
- GGUF models generated by llama.cpp
- GGUF models from HuggingFace
- Pytorch models from HuggingFace – quantized by Neural Speed
We began our experiments by working directly with Meta's Llama-2-7B-chat model in Pytorch from Hugging Face. This 7 billion parameter conversational model served as an ideal test case for evaluating end-to-end model conversion, quantization, and inferencing using the Neural Speed toolkit. To streamline testing, Neural Speed provides handy scripts to handle the full pipeline, beginning with taking the original Pytorch model and porting it to a GGUF model, then applying quantization policies to compress the model down to lower precisions like int8 or int4, and finally running inference to assess the performance. In this case, we did not compress the model and retained 32-bit values.
The following command will run a one-click conversion, quantization, and inference:
python scripts/run.py \ /home/models/ Llama-2-7b-chat-hf \ --weight_dtype f32 \ -p "always answer with Haiku. What is the greatest thing about sailing?
Sailing's greatest joy, Freedom on the ocean blue, Serenity found.
Conclusion
In our testing, the converted and quantized Llama-2 model provided not only accurate responses but also excellent response latency, which we will dig deeper into with future blogs. While we demonstrated this workflow on Meta's 7 billion parameter Llama-2 conversational AI, the same process can be applied to port and optimize many other leading large language models to run efficiently on CPUs. Other suitable candidates include chat-centric LLMs like NeuralChat, GPT-J, GPT-NEOX, Dolly-v2, and MPT, as well as general purpose models like Falcon, BLOOM, Mistral, OPT, and Hugging Face's DistilGPT2. Code-focused models like CodeLlama, MagicCoder, and StarCoder could also potentially benefit. Additionally, Chinese models including Baichuan, Baichuan2, and Qwen are prime targets for improved deployment on Intel® CPUs.
The key advantage of this CPU inferencing approach is harnessing all available CPU cores for cost-effective parallel inferencing. By converting and quantizing models to run natively on Intel® CPUs, we can take full advantage of ubiquitous Intel®-powered machines ranging from laptops to servers. For platforms lacking high-end GPUs, optimizing models to leverage existing CPU resources is a compelling way to deliver responsive AI experiences.
Author: John Lockman III, Distinguished Engineer | https://www.linkedin.com/in/johnlockman/

Improving Oracle Performance with New Dell 4 Socket Servers

Mon, 02 Oct 2023 21:23:14 -0000
|Read Time: 0 minutes
Deploying Oracle on a PowerEdge Server presents various challenges, typical of intricate software and hardware integrations. As servers age, they become increasingly expensive to maintain and can have detrimental effects on business productivity. This is primarily due to the heightened demand for IT personnel's time and the heightened risk of unscheduled downtime.
In the case of older servers hosting virtualized Oracle® Database applications, they might struggle to keep up with growing usage demands. This can result in slower operations that, for example, dissuade customers from browsing a website for products and completing online transactions. Aging hardware is also more susceptible to data loss or corruption, potential security vulnerabilities, and elevated maintenance and repair expenses.
One effective solution to address these issues is migrating Oracle Database workloads from older servers to newer ones, such as the 16th Generation Dell™ PowerEdge™ R960 featuring 4th Gen Intel® Xeon® Scalable processors. This upgrade not only mitigates the aforementioned concerns but also opens doors to further IT enhancements and facilitates the achievement of business objectives. It can lead to improved customer responsiveness and quicker time-to-market.
Additionally, transitioning workloads from virtualized environments to bare metal solutions has the potential to significantly enhance transactional database performance, particularly for databases that come with high-performance service-level agreements (SLAs).
We recently submitted one of the new Dell PowerEdge R960’s to Principled Technologies for testing with an Oracle database 19c and compared the results to previous generations. The performance exceeded even our own lofty expectations. As the graph below shows, the R960 was able to process almost 8 times more transactions than the PowerEdge R920 and over double the transactions of the previous generation PowerEdge R940.
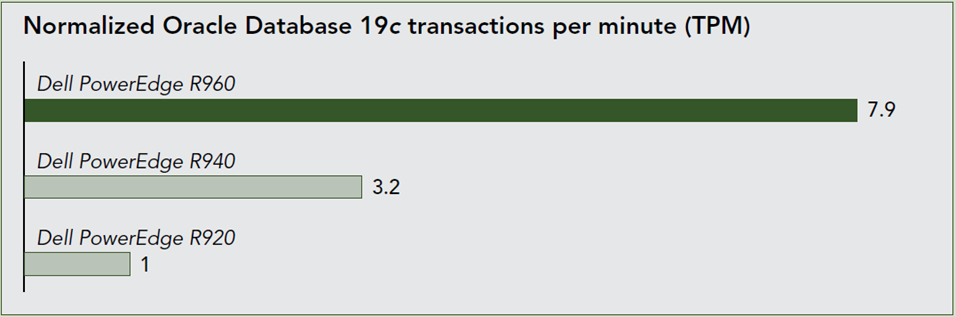
For more details read the full report here: Improving Oracle Database performance: Moving to Dell PowerEdge R960 servers with Intel processors | Dell Technologies Info Hub
When refreshing platforms it is critical to consider these performance characteristics and other common top 10 concerns such as:
- Compatibility Issues: Ensuring that the version of Oracle Database you want to deploy is compatible with the specific PowerEdge server hardware, operating system, and other software components can be a significant challenge. Compatibility matrices provided by Oracle and Dell (the manufacturer of PowerEdge servers) need to be thoroughly reviewed.
- Hardware Selection: Selecting the right PowerEdge server model with the appropriate CPU, memory, storage, and networking capabilities to meet the performance and scalability requirements of Oracle can be tricky. Overestimating or underestimating these requirements can lead to performance bottlenecks or wasted resources.
- Operating System Configuration: Configuring the operating system (typically, a Linux distribution like Oracle Linux or Red Hat Enterprise Linux) to meet Oracle's specific requirements can be complex. This includes setting kernel parameters, file system configurations, and installing necessary packages.
- Storage Configuration: Setting up storage correctly is critical for Oracle databases. Customers need to configure RAID levels, partitioning, and file systems optimally. Ensuring high I/O throughput and low latency is essential for database performance.
- Network Configuration: Proper network configuration, including setting up the network stack and configuring firewalls, is important for database security and accessibility.
- Oracle Database Configuration: Configuring Oracle Database itself, including memory allocation, database parameters, and storage management, requires a deep understanding of Oracle's architecture and best practices. Misconfigurations can lead to poor performance and stability issues.
- Backup and Recovery Strategy: Developing a robust backup and recovery strategy is crucial to protect the database against data loss. This includes configuring Oracle Recovery Manager (RMAN) and ensuring that backups are performed regularly and can be restored successfully.
- High Availability and Disaster Recovery: Implementing high availability and disaster recovery solutions, such as Oracle Real Application Clusters (RAC) or Data Guard, can be complex and requires careful planning and testing.
- Licensing and Compliance: Managing Oracle licenses and ensuring compliance with Oracle's licensing policies can be challenging, especially in virtualized or clustered environments.
- Performance Tuning: Continuously monitoring and tuning the Oracle database and the underlying PowerEdge server to optimize performance can be an ongoing challenge. This includes identifying and addressing performance bottlenecks and ensuring that the hardware is used efficiently.
To address these challenges, it is often advisable for customers to work with experienced system administrators, database administrators, and consultants who have expertise in both Oracle and PowerEdge server deployments. Additionally, staying informed about the latest updates, patches, and best practices from Oracle and Dell can help mitigate potential issues all of which can be found by partnering with Dell Technologies to take advantage of these performance enhancements found within the PowerEdge R960.
Author: Seamus Jones
Director, Server Technical Marketing Engineering