

Assets

CPU to the Rescue: LLMs for Everyone
Wed, 24 Apr 2024 13:25:19 -0000
|Read Time: 0 minutes
Optimizing Large Language Models
The past year has shown remarkable advances in large language models (LLMs) and what they can achieve. What started as tools for text generation have grown into multimodal models that can translate languages, hold conversations, generate music and images, and more. That said, training and running inference servers of these massive, multi-billion parameter models require immense computational resources and lots of high-end GPUs.
The surge in popularity of LLMs has fueled intense interest in porting these frameworks to mainstream CPUs. Open-source projects like llama.cpp and the Intel® Extension for Transformers aim to prune and optimize models for efficient execution on CPU architectures. These efforts encompass plain C/C++ implementations, hardware-specific optimizations for AVX, AVX2, and AVX512 instruction sets, and mixed precision model representations. Quantization and compression techniques are exploited to shrink models from 16-bit down to 8-bit or even 2-bit sizes. The goal is to obtain smaller, leaner models tailored for inferencing on widely available CPUs from the data center to your laptop.
While GPUs may still be preferred for training, CPUs in data centers and on devices can be used for efficient deployment to inference with these optimized models. CPUs can leverage recent advancements in architecture and provide broader access to large language model capabilities. The past year's advances in model optimization and CPU inferencing show promise in bringing natural language technologies powered by large models to more users.
Hardware
To evaluate these new CPU inferencing tools, we leveraged Dell Omnia cluster provisioning software to deploy Rocky Linux on a Dell PowerEdge C6620 server. Omnia allows rapid deployment of several operating system choices across a cluster of PowerEdge servers featuring Intel® Xeon® processors. By using Omnia for automated OS installation and configuration, we could quickly stand up a test cluster to experiment with the inference capabilities of the CPU-optimized models on our Intel® hardware.
Table 1. Dell PowerEdge C6620 specifications
Hardware | Details |
Server | Dell PowerEdge C6620 |
Processor Model | Intel® Xeon® Gold 6414U (Sapphire Rapids) |
Processors per Node | 2 |
Processor Core Count | 32 |
Processor Frequency | 2GHz |
Host Memory | 256 GB, 8 x 32GB |
Table 2. Involved software specifications
Software | Details |
Omnia | |
Rocky Linux 8.8 | |
Intel® Extensions for Transformers | |
Llama 2 with Intel® Neural Speed
Intel® has open sourced several tools under permissive licenses on GitHub to facilitate development with the Intel® Extensions for Transformers. One key offering is Neural Speed, which aims to enable efficient inferencing of large language models on Intel® hardware. Neural Speed leverages Intel® Neural Compressor, a toolkit for deep learning model optimization, to apply low-bit quantization and sparsity techniques that compress and accelerate the performance of leading LLMs. This allows Neural Speed to deliver state-of-the-art efficient inferencing for major language models. Neural Speed provides an inference stack that can maximize the performance of the latest Transformer-based language models on Intel® platforms ranging from edge to cloud. By open sourcing these technologies with permissive licensing, Intel® enables developers to easily adopt and innovate with optimized LLM inferencing across Intel® hardware.
To get started, clone the Intel® Neural Speed repo and install packages:
git clone https://github.com/intel/neural-speed.git pip install -r requirements.txt pip install .
Neural Speed can support 3 different model types:
- GGUF models generated by llama.cpp
- GGUF models from HuggingFace
- Pytorch models from HuggingFace – quantized by Neural Speed
We began our experiments by working directly with Meta's Llama-2-7B-chat model in Pytorch from Hugging Face. This 7 billion parameter conversational model served as an ideal test case for evaluating end-to-end model conversion, quantization, and inferencing using the Neural Speed toolkit. To streamline testing, Neural Speed provides handy scripts to handle the full pipeline, beginning with taking the original Pytorch model and porting it to a GGUF model, then applying quantization policies to compress the model down to lower precisions like int8 or int4, and finally running inference to assess the performance. In this case, we did not compress the model and retained 32-bit values.
The following command will run a one-click conversion, quantization, and inference:
python scripts/run.py \ /home/models/ Llama-2-7b-chat-hf \ --weight_dtype f32 \ -p "always answer with Haiku. What is the greatest thing about sailing?
Sailing's greatest joy, Freedom on the ocean blue, Serenity found.
Conclusion
In our testing, the converted and quantized Llama-2 model provided not only accurate responses but also excellent response latency, which we will dig deeper into with future blogs. While we demonstrated this workflow on Meta's 7 billion parameter Llama-2 conversational AI, the same process can be applied to port and optimize many other leading large language models to run efficiently on CPUs. Other suitable candidates include chat-centric LLMs like NeuralChat, GPT-J, GPT-NEOX, Dolly-v2, and MPT, as well as general purpose models like Falcon, BLOOM, Mistral, OPT, and Hugging Face's DistilGPT2. Code-focused models like CodeLlama, MagicCoder, and StarCoder could also potentially benefit. Additionally, Chinese models including Baichuan, Baichuan2, and Qwen are prime targets for improved deployment on Intel® CPUs.
The key advantage of this CPU inferencing approach is harnessing all available CPU cores for cost-effective parallel inferencing. By converting and quantizing models to run natively on Intel® CPUs, we can take full advantage of ubiquitous Intel®-powered machines ranging from laptops to servers. For platforms lacking high-end GPUs, optimizing models to leverage existing CPU resources is a compelling way to deliver responsive AI experiences.
Author: John Lockman III, Distinguished Engineer | https://www.linkedin.com/in/johnlockman/

Code Llama – How Meta Can an Open Source Coding Assistant Get?

Tue, 26 Sep 2023 14:10:49 -0000
|Read Time: 0 minutes
Introduction
The past few years have been an exciting adventure in the field of AI, as increasingly sophisticated AI models continue to be developed to analyze and comprehend vast amounts of data. From predicting protein structures to charting the neural anatomy of a fruit fly to creating optimized math operations that accelerate supercomputers, AI has achieved impressive feats across varied disciplines. Large language models (LLMs) are no exception. Although producing human-like language garners attention, large language models were also created for code generation. By training on massive code datasets, these systems can write code by forecasting the next token in a sequence.
Companies like Google, Microsoft, OpenAI, and Anthropic are developing commercial LLMs for coding such as Codex, GitHub Copilot, and Claude. In contrast to closed systems, Meta has opened up its AI coding tool Code Llama, an AI coding assistant that aims to boost software developer productivity. It is released under a permissive license for both commercial and research use. Code Llama is an LLM capable of generating code and natural language descriptions of code from both code snippets and user-engineered prompts to automate repetitive coding tasks and enhance developer workflows. The open-source release allows the wider tech community to build upon Meta’s foundational model in natural language processing and code intelligence. For more information about the release, see Meta’s blog Introducing Code Llama, an AI Tool for Coding.
Code Llama is a promising new AI assistant for programmers. It can autocomplete code, search through codebases, summarize code, translate between languages, and even fix issues. This impressive range of functions makes Code Llama seem almost magical—like a programmer's dream come true! With coding assistants like Code Llama building applications could become far easier. Instead of writing every line of code, we may one day be able to describe what we want the program to do in a natural language prompt and the model can generate the necessary code for us. This workflow of the future could allow programmers to focus on the high-level logic and architecture of applications, without getting bogged down in implementation details.
Getting up and running with Code Llama was straightforward and fast. Meta released a 7 B, 13 B, and 34 B version of the model including instruction models that were trained with fill-in-the-middle (FIM) capability. This allows the models to insert into existing code, perform code completion, and accept natural language prompts. Using a Dell PowerEdge R740XD equipped with a single Nvidia A100 40GB GPU experimented with the smaller 7 billion parameter model, CodeLlama-Instruct-7 B. We used our Rattler Cluster in the HPC AI Innovation Lab to take advantage of PowerEdge XE8545 servers each equipped with four Nvidia A100 40 GB GPUs for the larger 34 billion parameter model (CodeLlama-Instruct-34 B). The examples provided by Meta were running a few minutes after downloading the model files and we began experimenting with natural language prompts to generate code. By engineering the prompts in a strategic manner, we aimed to produce the scaffolding for a web service wrapping the Code Llama model with an API that could be accessed over the web.
Accept user input from command line
The examples provided in example_instructions.py must be edited manually to add wanted user prompts. To make Code Llama a bit easier to use, we copied example_instructions.py into test_instructions.py and added the ability to send in a prompt from the command line.
The full file with changes:
# Copyright (c) Meta Platforms, Inc. and affiliates.
# This software may be used and distributed according to the terms of the Llama 2 Community License Agreement.
from typing import Optional
import fire
from llama import Llama
def main(
ckpt_dir: str,
tokenizer_path: str,
content:str,
temperature: float = 0.2,
top_p: float = 0.95,
max_seq_len: int = 512,
max_batch_size: int = 8,
max_gen_len: Optional[int] = None,
):
generator = Llama.build(
ckpt_dir=ckpt_dir,
tokenizer_path=tokenizer_path,
max_seq_len=max_seq_len,
max_batch_size=max_batch_size,
)
instructions = [
[
{
"role": "user",
"content": content,
}
]
]
results = generator.chat_completion(
instructions, # type: ignore
max_gen_len=max_gen_len,
temperature=temperature,
top_p=top_p,
)
for instruction, result in zip(instructions, results):
for msg in instruction:
print(f"{msg['role'].capitalize()}: {msg['content']}\n")
print(
f"> {result['generation']['role'].capitalize()}: {result['generation']['content']}"
)
print("\n==================================\n")
if __name__ == "__main__":
fire.Fire(main)
It is possible to run the standard torchrun command with a --content option to pass in the prompt. Rather than evaluating the model on complex tasks, we started with simple coding challenges. To test the model, we designed a few experiments involving straightforward coding prompts posing basic programming problems. The manual process of directly prompting the model allows us to evaluate the strengths and weaknesses in generating code with this model.
Our first prompt: “Show an example of recursion in Python”
Command:
torchrun test_instructions.py \ --nproc_per_node 1 \ --ckpt_dir CodeLlama-7b-Instruct/ \ --tokenizer_path CodeLlama-7b-Instruct/tokenizer.model \ --max_seq_len 512 \ --max_batch_size 1 \ --content "Show an example of recursion in Python"
Output:
> Assistant: Sure! Here's an example of recursion in Python: ``` def factorial(n): if n == 0: return 1 else: return n * factorial(n-1) ``` In this example, the `factorial` function takes an integer `n` as input and returns its factorial. The function calls itself with the argument `n-1` until the base case is reached, where `n` is equal to 0. The base case returns 1, and the recursive calls return the factorial of `n-1`. The final result is the product of `n` and the factorial of `n-1`. Here's an example of how the function would work for different values of `n`: * `factorial(5)` would call `factorial(4)`, which would call `factorial(3)`, which would call `factorial(2)`, which would call `factorial(1)`, which would return 1. The final result would be 5! = 120. * `factorial(0)` would return 1. * `factorial(-1)` would raise a `ValueError` because negative numbers are not allowed. Recursion can be a powerful tool for solving problems that have a recursive structure, but it can also be difficult to understand and debug. It's important to use recursion judiciously and to make sure that it's the best approach for the problem you're trying to solve. ==================================
The model not only generates example code, but it also explains how the code works through examples. By providing both code snippets and clarifying descriptions, the model enables a deeper understanding of the functionality. Users can both see concrete implementations and learn the rationale behind them. Now that we have made it easier to provide a prompt to the model, let’s build an API endpoint by prompting Code Llama to build its own server.
Create An API endpoint for Code Llama
RESTful APIs are a popular way to build backend services that can be consumed by various applications over a network with tools such as curl. However, instead of manually coding this, we asked Code Llama to write the code for its own REST server.
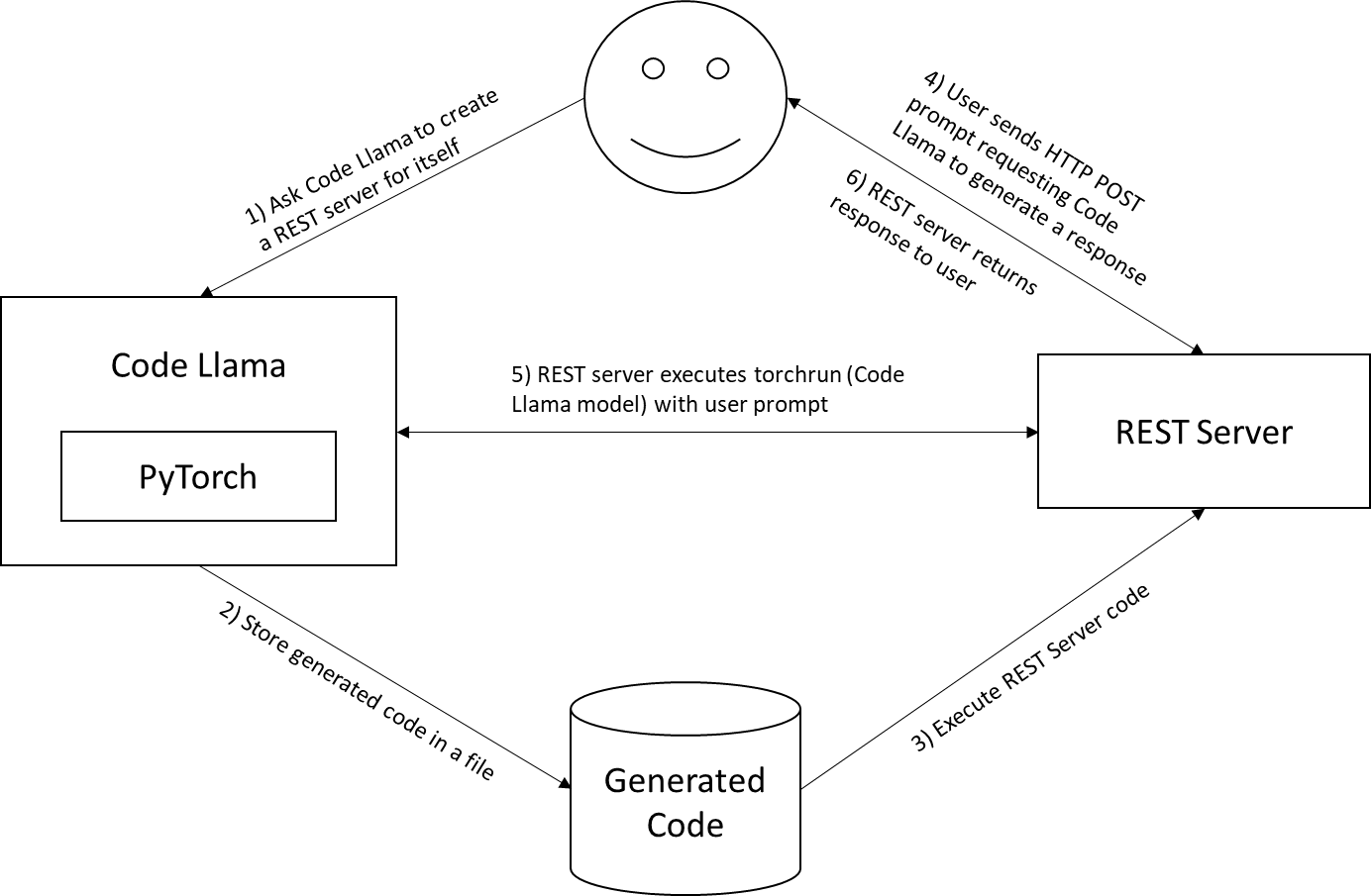
Our process for using Code Llama to produce a web service of itself:
- Step 1: Ask Code Llama to create a REST server for itself
- Step 2: Store the generated code in a file
- Step 3: Run the REST app on same GPU enabled server
- Step 4: Send prompts using HTTP POST requests to Code Llama service on the local host
- Step 5: REST server runs torchrun command with user prompt
- Step 6: REST server returns response to user
We needed to add some context to the prompt for Code Llama to generate the correct code, as the engineered prompt is a bit more complex and includes how to call torchrun with the correct parameters:
torchrun \ --nproc_per_node 1 \ test_instructions.py \ --ckpt_dir CodeLlama-7b-Instruct/ \ --tokenizer_path CodeLlama-7b-Instruct/tokenizer.model\ --max_seq_len 512 \ --max_batch_size 1 \ --content "Create a REST server in Python with a POST /codellama URL, expect a JSON payload with a 'content' field, use a subprocess.run(['torchrun', '--nproc_per_node', '1', 'test_instructions.py', '--ckpt_dir', 'CodeLlama-7b-Instruct/', '--tokenizer_path', 'CodeLlama-7b-Instruct/tokenizer.model', '--max_seq_len', '512', '--max_batch_size', '1', '--content', content], stdout=subprocess.PIPE) and return stdout from subprocess.run"
All torchrun command line options, except for --content, are defined by Code Llama itself. Let’s break down what our engineered prompt is requesting:
- “Create a REST server in Python” – No framework was defined; Code Llama chose Flask
- “with a POST /codellama URL” – Expect to receive HTTP POSTS to the /codellama URL
- “expect a JSON payload with a ‘content’ field” – Expect a ‘content’ key in the POST JSON. This holds the user prompt.
- “use a subprocess.run(…)” – This is where we tell Code Llama how to call itself
- “return stdout from subprocess.run” – Return any text that Code Llama produces over HTTP
The resulting output:
> Assistant: Here is an example of how you can create a REST server in Python with a POST /codellama URL that expects a JSON payload with a 'content' field, and uses a subprocess.run command to run the torchrun command with the specified arguments:
```
import json
import subprocess
from flask import Flask, request
app = Flask(__name__)
@app.route('/codellama', methods=['POST'])
def codellama():
if request.method == 'POST':
data = request.get_json()
content = data['content']
args = ['torchrun', '--nproc_per_node', '1', 'test_instructions.py', '--ckpt_dir', 'CodeLlama-7b-Instruct/', '--tokenizer_path', 'CodeLlama-7b-Instruct/tokenizer.model', '--max_seq_len', '512', '--max_batch_size', '1', '--content', content]
result = subprocess.run(args, stdout=subprocess.PIPE)
return result.stdout
else:
return 'Invalid request'
if __name__ == '__main__':
app.run(debug=True)
```
This code defines a Flask application with a single route, '/codellama', that handles POST requests. The route expects a JSON payload with a 'content' field, and uses the subprocess.run command to run the torchrun command with the specified arguments. The result of the
==================================We clipped the Code Llama generated code and pasted it into server.py:
import json
import subprocess
from flask import Flask, request
app = Flask(__name__)
@app.route('/codellama', methods=['POST'])
def codellama():
if request.method == 'POST':
data = request.get_json()
content = data['content']
args = ['torchrun', '--nproc_per_node', '1', 'test_instructions.py', '--ckpt_dir', 'CodeLlama-7b-Instruct/', '--tokenizer_path', 'CodeLlama-7b-Instruct/tokenizer.model', '--max_seq_len', '512', '--max_batch_size', '1', '--content', content]
result = subprocess.run(args, stdout=subprocess.PIPE)
return result.stdout
else:
return 'Invalid request'
if __name__ == '__main__':
app.run(debug=True)After running the code:
python server.py
… the REST-like server will be running and waiting for commands.
Using curl, we can send commands over the network to Code Llama now:
curl -X POST -H "Content-Type: application/json" -d '{"content": " Show an example of recursion in Python"}' http://localhost:5000/codellama… and will receive a result like:
> Assistant: Sure! Here's an example of recursion in Python: ``` def factorial(n): if n == 0: return 1 else: return n * factorial(n-1) ``` In this example, the `factorial` function takes an integer `n` as input and returns its factorial. The function calls itself with the argument `n-1` until the base case is reached, where `n` is equal to 0. The base case returns 1, and the recursive calls return the factorial of `n-1`. The final result is the product of `n` and the factorial of `n-1`. Here's an example of how the function would work for different values of `n`: * `factorial(5)` would call `factorial(4)`, which would call `factorial(3)`, which would call `factorial(2)`, which would call `factorial(1)`, which would return 1. The final result would be 5! = 120. * `factorial(0)` would return 1. * `factorial(-1)` would raise a `ValueError` because negative numbers are not allowed Recursion can be a powerful tool for solving problems that have a recursive structure, but it can also be difficult to understand and debug. It's important to use recursion judiciously and to make sure that it's the best approach for the problem you're trying to solve. ==================================
Conclusion
The capabilities of AI and LLMs continue to rapidly evolve. What we find most compelling about an open source model like Code Llama is the potential for customization and data privacy. Unlike closed, proprietary models, companies can run Code Llama on their own servers and fine-tune it using internal code examples and data. This allows enforcement of coding styles and best practices while keeping code and data private. Rather than relying on external sources and APIs, teams can query a customized expert trained on their unique data in their own data center. Whatever your use cases, we found standing up an instance of Code Llama using Dell servers accelerated with Nvidia GPUs a simple and powerful solution that enables an exciting innovation for development teams and enterprises alike.
AI coding assistants such as Code Llama have the potential to transform software development in the future. By automating routine coding tasks, these tools could save developers significant time that can be better spent on higher-level system design and logic. With the ability to check for errors and inconsistencies, AI coders may also contribute to improved code quality and reduced technical debt. However, our experiments reaffirm that generative AI is still prone to limitations like producing low-quality or non-functional code. Now that we have a local API endpoint for Code Llama, we plan to conduct more thorough testing to further evaluate its capabilities and limitations. We encourage developers to try out Code Llama themselves using the resources we provided here. Getting experience with this open-sourced model is a great way to start exploring the possibilities of AI for code generation while contributing to its ongoing improvement.

Omnia: Open-source deployment of high-performance clusters to run simulation, AI, and data analytics workloads
Mon, 12 Dec 2022 18:31:28 -0000
|Read Time: 0 minutes
High Performance Computing (HPC), in which clusters of machines work together as one supercomputer, is changing the way we live and how we work. These clusters of CPU, memory, accelerators, and other resources help us forecast the weather and understand climate change, understand diseases, design new drugs and therapies, develop safe cars and planes, improve solar panels, and even simulate life and the evolution of the universe itself. The cluster architecture model that makes this compute-intensive research possible is also well suited for high performance data analytics (HPDA) and developing machine learning models. With the Big Data era in full swing and the Artificial Intelligence (AI) gold rush underway, we have seen marketing teams with their own Hadoop clusters attempting to transition to HPDA and finance teams managing their own GPU farms. Everyone has the same goals: to gain new, better insights faster by using HPDA and by developing advanced machine learning models using techniques such as deep learning and reinforcement learning. Today, everyone has a use for their own high-performance computing cluster. It’s the age of the clusters!
Today's AI-driven IT Headache: Siloed Clusters and Cluster Sprawl
Unfortunately, cluster sprawl has taken over our data centers and consumes inordinate amounts of IT resources. Large research organizations and businesses have a cluster for this and a cluster for that. Perhaps each group has a little “sandbox” cluster, or each type of workload has a different cluster. Many of these clusters look remarkably similar, but they each need a dedicated system administrator (or set of administrators), have different authorization credentials, different operating models, and sit in different racks in your data center. What if there was a way to bring them all together?
That’s why Dell Technologies, in partnership with Intel, started the Omnia project.
The Omnia Project
The Omnia project is an open-source initiative with a simple aim: To make consolidated infrastructure easy and painless to deploy using open open source and free use software. By bringing the best open source software tools together with the domain expertise of Dell Technologies' HPC & AI Innovation Lab, HPC & AI Centers of Excellence, and the broader HPC Community, Omnia gives customers decades of accumulated expertise in deploying state-of-the-art systems for HPC, AI, and Data Analytics – all in a set of easily executable Ansible playbooks. In a single day, a stack of servers, networking switches, and storage arrays can be transformed into one consolidated cluster for running all your HPC, AI, and Data Analytics workloads. Omnia project logo
Omnia project logo
Simple by Design
Omnia’s design philosophy is simplicity. We look for the best, most straightforward approach to solving each task.
- Need to run the Slurm workload manager? Omnia assembles Ansible plays which build the right rpm files and deploy them correctly, making sure all the correct dependencies are installed and functional.
- Need to run the Kubernetes container orchestrator? Omnia takes advantage of community supported package repositories for Linux (currently CentOS) and automates all the steps for creating a functional multi-node Kubernetes cluster.
- Need a multi-user, interactive Python/R/Julia development environment? Omnia takes advantage of best-of-breed deployments for Kubernetes through Helm and OperatorHub, provides configuration files for dynamic and persistent storage, points to optimized containers in DockerHub, Nvidia GPU Cloud (NGC), or other container registries for unaccelerated and accelerated workloads, and automatically deploys machine learning platforms like Kubeflow.
Before we go through the process of building something from scratch, we will make sure there isn’t already a community actively maintaining that toolset. We’d rather leverage others' great work than reinvent the wheel.
Inclusive by Nature
Omnia’s contribution philosophy is inclusivity. From code and documentation updates to feature requests and bug reports, every user’s contributions are welcomed with open arms. We provide an open forum for conversations about feature ideas and potential implementation solutions, making use of issue threads on GitHub. And as the project grows and expands, we expect the technical governance committee to grow to include the top contributors and stakeholders from the community.
What's Next?
Omnia is just getting started. Right now, we can easily deploy Slurm and Kubernetes clusters from a stack of pre-provisioned, pre-networked servers, but our aim is higher than that. We are currently adding capabilities for performing bare-metal provisioning and supporting new and varying types of accelerators. In the future, we want to collect information from the iDRAC out-of-band management system on Dell EMC PowerEdge servers, configure Dell EMC PowerSwitch Ethernet switches, and much more.
What does the future hold? While we have plans in the near-term for additional feature integrations, we are looking to partner with the community to define and develop future integrations. Omnia will grow and develop based on community feedback and your contributions. In the end, the Omnia project will not only install and configure the open source software we at Dell Technologies think is important, but the software you – the community – want it to, as well! We can’t think of a better way for our customers to be able to easily setup clusters for HPC, AI, and HPDA workloads, all while leveraging the expertise of the entire Dell Technologies' HPC Community.
Omnia is available today on GitHub at https://github.com/dellhpc/omnia. Join the community now and help guide the design and development of the next generation of open-source consolidated cluster deployment tools!

Increased Automation, Scale, and Capability with Omnia 1.1
Mon, 15 Nov 2021 23:08:56 -0000
|Read Time: 0 minutes
The release of Omnia version 1.0 in March of 2020 was a huge milestone for the Omnia community. It was the culmination of nearly a year of planning, conversations with customers and community members, development, and testing. Omnia version 1.0 included:
- bare-metal provisioning with Cobbler,
- automated Slurm and Kubernetes cluster deployment, and
automated Kubeflow deployment.
The Omnia project was designed to rapidly add features and evolve, and we are proud to announce the first update to Omnia just 7 months later. While version 1.0 had a ton of great features for a first release, version 1.1 turned out to be even bigger!
The Omnia Project
Omnia is an open-source, community-driven framework for deploying high-performance computing (HPC) clusters for simulation & modeling, artificial intelligence, and data analytics. By automating the entire process, Omnia reduces deployment time for these complex systems from weeks to hours.
Omnia incubated at Dell Technologies in partnership with Intel. The project was initiated by two HPC & AI experts who needed to quickly setup proof-of-concept clusters in Dell’s HPC & AI Innovation Lab, and has since grown into a much larger effort to create production-grade clusters on demand and at scale. Today, Omnia has thirty collaborators from nearly a dozen organizations, including five official community member organizations. The code repo has been cloned over a thousand times and has over forty thousand views! The project is off to a great start with more new features releasing regularly!
Omnia 1.1
Omnia version 1.1 includes a multitude of new features and capabilities that expand datacenter automation beyond the compute server. This latest release sets the groundwork for Omnia to handle future exascale supercomputer deployments while simultaneously growing the set of end-user features and platforms more rapidly.
New in Omnia 1.1
- iDRAC-based provisioning
- PowerVault provisioning/configuration (automatically turns a PV array into an NFS file share)
- Parallel gang scheduling for Kubernetes (for MPI and Spark jobs)
- User authentication/management using LDAP/Kerberos
- Automatic firmware updating for PowerEdge servers with Intel® 2nd-generation Xeon® Scalable processors when using iDRAC for provisioning
- Automatic configuration of Dell PowerSwitch 100Gb Ethernet and Nvidia InfiniBand switches
- Updated AWX GUI for deploying logical clusters
- Additional MLOps platform options (Polyaxon, in addition to the existing KubeFlow)
A brand-new control plane designed for future growth
The new control plane (formerly called the Omnia appliance) is now a full Kubernetes-based deployment with a wealth of features. The new control plane includes Dell iDRAC integration for firmware updates and OS provisioning when iDRAC Enterprise or Datacenter licenses are detected, plus automatic fallback to Cobbler-based PXE provisioning when those licenses are not available. This allows cluster administrators using Dell servers to take full advantage of their iDRAC Enterprise or Datacenter licenses while continuing to offer a fully open-source and vendor-agnostic alternative. This new Kubernetes-based control plane is the first step in providing an expandable, multi-server control plane that could be used to manage the bare-metal provisioning and deployment of thousands of compute nodes for petascale and eventual exascale systems.
Automatically detect and deploy more than just servers
The development team has also extended Omnia’s automation capability beyond compute servers. The control plane is now able to automatically detect and configure Dell EMC PowerSwitches, Nvidia/Mellanox InfiniBand switches, and Dell EMC PowerVault storage arrays. This allows users to now deploy complete HPC environments using Omnia’s one-touch philosophy, with compute, network, and storage pieces ready to go! Dell EMC PowerSwitches are automatically configured for both management and fabric deployments, with automatic configuration of RoCEv2 for supported 100Gbps Ethernet switches. Nvidia InfiniBand fabrics will automatically be deployed when an InfiniBand switch is detected, with the subnet manager running on the control plane. And when the control plane detects a Dell EMC PowerVault ME4 storage array, it will automatically configure the RAID, format the array, and setup an NFS service that can have shared access by the various logical clusters in the Omnia resource pool. In less than a day a loading dock full of servers, storage, and networking can be transformed into a functional Omnia resource pool, ready to be configured into logical Slurm and Kubernetes clusters on demand.
Automated deployment of LDAP services
Starting with version 1.1, Omnia also reduces the pain of user management. When logical Slurm clusters are created Omnia takes care of all the backend services needed for a fully functional, batch scheduled, simulation and modeling environment including Kerberos user authentication with FreeIPA. System administrators immediately have access to both a CLI and web-based interface for user management built upon well-known open-source components and standard protocols. Systems can also be configured to point to an existing LDAP service elsewhere in the data center.
Preparing Kubernetes for HPC workloads
Interest in Kubernetes has been growing in the HPC community, especially for data science and data analytics workloads. Interest in those use cases is precisely why Omnia included the ability to deploy Kubernetes from the start. However, default configurations of Kubernetes are missing some of the key components needed to make it useful for parallel and distributed data processing. Omnia version 1.0 included the mpi-operator from the Kubeflow project that provides custom resource descriptions (CRDs) for MPI job execution. Version 1.1 now includes the spark-operator to make executing Spark jobs simpler, as well. Another feature of version 1.1 is the option to use gang scheduling for Kubernetes pods through the Volcano project. This gives Kubernetes the ability to understand that all the pods in an MPI job should be scheduled simultaneously, rather than deploying pods a few at a time when resources come available.
A new platform for neural network research
Artificial intelligence research has been central workload for Omnia. Being able to provide users easy-to-deploy MLOps platforms like Kubeflow is critical to enabling data scientists and AI researchers the flexibility to experiment with new neural network architectures. In addition to Kubeflow, Omnia now offers automated installation of the Polyaxon deep learning platform. Polyaxon gives neural network researchers and data science teams the ability to:
- index and catalog experiments,
- execute Distributed TensorFlow experiments,
- train MPI-enabled TensorFlow and PyTorch models, and
- tune/optimize models using parametric sweeps of hyperparameter values.
Even greater things are on the horizon!
Version 1.1 is a big release, but the Omnia community has even greater things planned. Soon we will be adding support for the entire line of Dell EMC PowerEdge servers with Intel® 3rd-generation Xeon® Scalable (code name “Ice Lake”) processors. Additionally, Omnia will soon be able to deploy logical clusters on top of servers provisioned with either Rocky Linux or CentOS, offering users a choice of base operating systems. Looking farther out, we are working with our customers, technology partners, and community members to bring support for creating BeeGFS filesystems on demand, deploying new user platforms like Open OnDemand, and providing better administrative interfaces for Kubernetes cluster administration through Lens. Anyone is free to look at what we’re working on (and suggest new things to try) by going to the Omnia GitHub.
Learn More
Learn more about Omnia by visiting Omnia on GitHub.
Read the Dell Technologies solution overview on Omnia here.

Taming the Accelerator Cambrian Explosion with Omnia
Thu, 23 Sep 2021 18:29:00 -0000
|Read Time: 0 minutes
We are in the midst of a compute accelerator renaissance. Myriad new hardware accelerator companies are springing up with novel architectures and execution models for accelerating simulation and artificial intelligence (AI) workloads, each with a purported advantage over the others. Many are still in stealth, some have become public knowledge, others have started selling hardware, and still others have been gobbled up by larger, established players. This frenzied activity in the hardware space, driven by the growth of AI as a way to extract even greater value from new and existing data, has led some to liken it to the “Cambrian Explosion,” when life on Earth diversified at a rate not seen before or since.
If you’re in the business of standing up and maintaining infrastructure for high-performance computing and AI, this type of rapid diversification can be terrifying. How do I deal with all of these new hardware components? How do I manage all of the device drivers? What about all of the device plugins and operators necessary to make them function in my container-orchestrated environment? Data scientists and computational researchers often want the newest technology available, but putting it into production can be next to impossible. It’s enough to keep HPC/AI systems administrators lying awake at night.
At Dell Technologies, we now offer many different accelerator technologies within our PowerEdge server portfolio, from Graphics Processing Units (GPUs) in multiple sizes to Field-Programmable Gate Array (FPGA)-based accelerators. And there are even more to come. We understand that it can be a daunting task to manage all of this different hardware – it’s something we do every day in Dell Technologies’ HPC & AI Innovation Lab. So we’ve developed a mechanism for detecting, identifying, and deploying various accelerator technologies in an automated way, helping us to simplify our own deployment headaches. And we’ve integrated that capability into Omnia, an open-source, community-driven high-performance cluster deployment project started by Dell Technologies and Intel.
Deploy-time accelerator detection and installation
We recognize that tomorrow’s high-performance clusters will not be fully homogenous, consisting of exact copies of the same compute building block replicated tens, hundreds, or thousands of times. Instead clusters are becoming more heterogeneous, consisting of as many as a dozen different server configurations, all tied together under a single (or in some cases – multiple) scheduler or container orchestrator.
This heterogeneity can be a problem for many of today’s cluster deployment tools, which rely on the concept of the “golden image” – a complete image of the server's operating system, hardware drivers, and software stack. The golden image model is extremely useful in many environments, such as homogeneous and diskless deployments. But in the clusters of tomorrow, which will try to capture the amazing potential of this hardware diversity, the golden image model becomes unmanageable.
Instead, Omnia does not rely on the golden image. We think of cluster deployment like 3D-printing – rapidly placing layer after layer of software components and capabilities on top of the hardware until a functional server building block emerges. This allows us, with the use of some intelligent detection and logic, to build bespoke software stacks for each server building block; on demand, at deploy time. From Omnia’s perspective, there’s really no difference between deploying a compute server with no accelerators into a cluster versus deploying a compute server with GPUs or FPGAs into that same cluster. We simply pick different component layers during the process.
What does this mean for cluster deployment?
It means that clusters can now be built from a variety of heterogeneous server building blocks, all managed together as a single entity. Instead of a cluster of CPU servers, another cluster of GPU-accelerated servers, and yet another cluster of FPGA-accelerated servers, research and HPC IT organizations can manage a single resource with all of the different types of technologies that their users demand, all connected by a unified network fabric and sharing a set of unified storage solutions.
And by using Omnia, the process of deploying clusters of heterogeneous building blocks has been dramatically simplified. Regardless of how many types of building blocks an organization wants to use within their next-generation cluster, it can all be deployed using the same approach, and at the same time. There’s no need to build special images for this type of server and that type of server, simply start the Omnia deployment process and Omnia’s intelligent software deployment system will do the rest.
Learn more
Omnia is available to download on GitHub today. You can learn more about the Omnia project in our previous blog post.

Containerized HPC Workloads Made Easy with Omnia and Singularity
Mon, 28 Jun 2021 14:35:14 -0000
|Read Time: 0 minutes
Maximizing application performance and system utilization has always been important for HPC users. The libraries, compilers, and applications found on these systems are the result of heroic efforts by HPC system administrators and teams of HPC specialists who fine tune, test, and maintain optimal builds of complex hierarchies of software for users. Fortunately for both researchers and administrators, some of that burden can be relieved with the use of containers, where software solutions can be built to run reliably when moved from one computing environment to another. This includes moving from one research lab to another, or from the developer’s laptop to a production lab, or even from an on-prem data center to the cloud.
Singularity has provided HPC system administrators and users a way to take advantage of application containerization while running on batch-scheduled systems. Singularity is a container runtime that can build containers in its own native format, as well as execute any CRI-compatible container. By default, Singularity enforces security restrictions on containers by running in user space and can preserve user identification when run through batch schedulers, providing a simple method to deploy containerized workloads on multi-user HPC environments.
Best practices for HPC systems deployment and use is the goal of Omnia and we recognize those practices vary in industry and research institutions. Omnia is developed with the entire community in mind and we aim to provide the tools that help them be productive. To this end, we recently included Singularity as an automatically installed package when deploying Slurm clusters with Omnia.
Building a Singularity-enabled cluster with Omnia
Installing a Slurm cluster with Omnia and running a Singularity job is simple. We provide a repository of Ansible playbooks to configure a pile of metal or cloud resources into a ready-to-use Slurm cluster by applying the Slurm role in AWX or by applying the playbook on the command line.
ansible-playbook -i inventory omnia.yaml --skip-tags kubernetes
Once the playbook has completed users are presented with a fully functional Slurm cluster with Singularity installed. We can run a simple “hello world” example, using containers directly from Singularity Hub. Here is an example Slurm submission script to run the “Hello World” example.
#!/bin/bash #SBATCH -J singularity_test #SBATCH -o singularity_test.out.%J #SBATCH -e singularity_test.err.%J #SBATCH -t 0-00:10 #SBATCH -N 1 # pull example Singularity container singularity pull --name hello-world.sif shub://vsoch/hello-world # execute Singularity container singularity exec hello-world.sif cat /etc/os-release
Executing HPC applications without installing software
The “hello world” example is great but doesn’t demonstrate running real HPC codes, fortunately several hardware vendors have begun to publish containers for both HPC and AI workloads, such as Intel's oneContainer and Nvidia's NGC. Nvidia NGC is a catalog of GPU-accelerated software arranged in collections, containers, and Helm charts. This free to use repository has the latest builds of popular software used for deep learning and simulation with optimizations for Nvidia GPU systems. With Singularity we can take advantage of the NGC containers on our bare-metal Slurm cluster. Starting with the LAMMPS example on the NGC website we demonstrate how to run a standard Lennard-Jones 3D melt experiment, without having to compile all the libraries and executables.
The input file for running this benchmark, in.lj.txt, can be downloaded from the Sandia National Laboratory site:
wget https://lammps.sandia.gov/inputs/in.lj.txt
Next make a local copy of the lammps container from NGC and name it lammps.sif
singularity build lammps.sif docker://nvcr.io/hpc/lammps:29Oct2020
This example can be executed directly from the command line using srun. This example runs 8 tasks on 2 nodes with a total of 8 GPUs:
srun --mpi=pmi2 -N2 --ntasks=8 --ntasks-per-socket=2 singularity run --nv -B ${PWD}:/host_pwd --pwd /host_pwd lammps.sif lmp -k on g 8 -sf kk -pk kokkos cuda/aware on neigh full comm device binsize 2.8 -var x 8 -var y 8 -var z 8 -in /host_pwd/in.lj.txtAlternatively, the following example Slurm submission script will permit batch execution with the same parameters as above, 8 tasks on 2 nodes with a total of 8 GPUs:
#!/bin/bash
#SBATCH --nodes=2
#SBATCH --ntasks=8
#SBATCH --ntasks-per-socket=2
#SBATCH --time 00:10:00
set -e; set -o pipefail
# Build SIF, if it doesn't exist
if [[ ! -f lammps.sif ]]; then
singularity build lammps.sif docker://nvcr.io/hpc/lammps:29Oct2020
fi
readonly gpus_per_node=$(( SLURM_NTASKS / SLURM_JOB_NUM_NODES ))
echo "Running Lennard Jones 8x4x8 example on ${SLURM_NTASKS} GPUS..."
srun --mpi=pmi2 \
singularity run --nv -B ${PWD}:/host_pwd --pwd /host_pwd lammps.sif lmp -k on g ${gpus_per_node} -sf kk -pk kokkos cuda/aware on neigh full comm device binsize 2.8 -var x 8 -var y 8 -var z 8 -in /host_pwd/in.lj.txtContainers provide a simple solution to the complex task of building optimized software to run anywhere. Researchers are no longer required to attempt building software themselves or wait for a release of software to be made available at the site they are running. Whether running on the workstation, laptop, on-prem HPC resource, or cloud environment they can be sure they are using the same optimized version for every run.
Omnia is an open source project that makes it easy to setup a Slurm or Kubernetes environment. When we combine the simplicity of Omnia for system deployment and Nvidia NGC containers for optimized software, both researchers and system administrators can concentrate on what matters most, getting results faster.
Learn more
Learn more about Singularity containers at https://sylabs.io/singularity/. Omnia is available for download at https://github.com/dellhpc/omnia.