




Deploying the Llama 3.1 405b Model Using Dell Enterprise Hub

This blog is one in a series of three that shows how Dell Technologies and our partner AI ecosystem can help you to provision the most powerful open-source model available easily. In this series of blogs, we share information about the ease of deploying the Llama 3.1 405b model on the Dell PowerEdge XE9680 server by using NVIDIA NIM, Dell Enterprise Hub using Text Generation Inference (TGI), or vLLM for Large Language Models (LLMs). We hope this series equips you with the knowledge and tools needed for a successful deployment.
This blog describes the Dell Enterprise Hub for LLMs option.
Overview
In this blog, we describe how to deploy the Llama 3.1 405b model on a Dell PowerEdge XE9680 server using the Dell Enterprise Hub portal developed in partnership with Hugging Face.
We also published the steps to run models using Kubernetes and the Dell Enterprise Hub with Hugging Face in the Scale your Model Deployments with the Dell Enterprise Hub blog, in which we used the Llama 3.1 70b model. We recommend reading this blog for more details about the Text Generation Inference (TGI) implementation and the infrastructure used. TGI is a toolkit for deploying and serving LLMs that enables high-performance text generation for the most popular open-source LLMs.
Dell Enterprise Hub
The Dell Enterprise Hub (https://dell.huggingface.co/) revolutionizes access to and use of optimized models on cutting-edge Dell hardware. It offers a curated collection of models that have been thoroughly tested and validated on Dell systems.
The Dell Enterprise Hub has curated examples for deploying the models with Docker and Kubernetes. In this blog, we show how easy it is to start inferencing with the Llama 3.1 405b model.
The Scale your Model Deployments with the Dell Enterprise Hub blog describes how to access the portal and retrieve the examples, therefore we do not include this information. For more information, see the blog.
Deploying with Docker
To deploy the model with Docker:
- Go to https://dell.huggingface.co/authenticated/models/meta-llama/Meta-Llama-3.1-405B-Instruct-FP8/deploy/docker to access the portal.
- Run the following command to deploy the Llama 3.1 405b model:
docker run \ -it \ --gpus 8 \ --shm-size 1g \ -p 80:80 \ -e NUM_SHARD=8 \ -e MAX_BATCH_PREFILL_TOKENS=16182 \ -e MAX_INPUT_TOKENS=8000 \ -e MAX_TOTAL_TOKENS=8192 \ registry.dell.huggingface.co/enterprise-dell-inference-meta-llama-meta-llama-3.1-405b-instruct-fp8
The following example shows a deployment and the output of the command:
fbronzati@node005:~$ docker run \
-it \
--gpus 8 \
--shm-size 1g \
-p 80:80 \
-e NUM_SHARD=8 \
-e MAX_BATCH_PREFILL_TOKENS=16182 \
-e MAX_INPUT_TOKENS=8000 \
-e MAX_TOTAL_TOKENS=8192 \
registry.dell.huggingface.co/enterprise-dell-inference-meta-llama-meta-llama-3.1-405b-instruct-fp8
Unable to find image 'registry.dell.huggingface.co/enterprise-dell-inference-meta-llama-meta-llama-3.1-405b-instruct-fp8:latest' locally
latest: Pulling from enterprise-dell-inference-meta-llama-meta-llama-3.1-405b-instruct-fp8
43f89b94cd7d: Pull complete
45f7ea5367fe: Pull complete
.
.
.
.
e4fdac914fb9: Pull complete
Digest: sha256:c6819ff57444f51abb2a2a5aabb12b103b346bfb056738a613f3fcc0eecbd322
Status: Downloaded newer image for registry.dell.huggingface.co/enterprise-dell-inference-meta-llama-meta-llama-3.1-405b-instruct-fp8:latest
2024-09-14T01:06:21.279409Z INFO text_generation_launcher: Args {
model_id: "/model",
revision: None,
validation_workers: 2,
sharded: None,
num_shard: Some(
8,
),
quantize: None,
speculate: None,
dtype: None,
trust_remote_code: false,
max_concurrent_requests: 128,
max_best_of: 2,
max_stop_sequences: 4,
max_top_n_tokens: 5,
max_input_tokens: Some(
8000,
),
max_input_length: None,
max_total_tokens: Some(
8192,
),
waiting_served_ratio: 0.3,
max_batch_prefill_tokens: Some(
16182,
),
max_batch_total_tokens: None,
max_waiting_tokens: 20,
max_batch_size: None,
cuda_graphs: None,
hostname: "1adda5a941d3",
port: 80,
shard_uds_path: "/tmp/text-generation-server",
master_addr: "localhost",
master_port: 29500,
huggingface_hub_cache: Some(
"/data",
),
weights_cache_override: None,
disable_custom_kernels: false,
cuda_memory_fraction: 1.0,
rope_scaling: None,
rope_factor: None,
json_output: false,
otlp_endpoint: None,
otlp_service_name: "text-generation-inference.router",
cors_allow_origin: [],
watermark_gamma: None,
watermark_delta: None,
ngrok: false,
ngrok_authtoken: None,
ngrok_edge: None,
tokenizer_config_path: None,
disable_grammar_support: false,
env: false,
max_client_batch_size: 4,
lora_adapters: None,
disable_usage_stats: false,
disable_crash_reports: false,
}
2024-09-14T01:06:21.280278Z INFO text_generation_launcher: Using default cuda graphs [1, 2, 4, 8, 16, 32]
2024-09-14T01:06:21.280285Z INFO text_generation_launcher: Sharding model on 8 processes
2024-09-14T01:06:21.280417Z INFO download: text_generation_launcher: Starting check and download process for /model
2024-09-14T01:06:25.598785Z INFO text_generation_launcher: Files are already present on the host. Skipping download.
2024-09-14T01:06:26.485957Z INFO download: text_generation_launcher: Successfully downloaded weights for /model
2024-09-14T01:06:26.486723Z INFO shard-manager: text_generation_launcher: Starting shard rank=1
2024-09-14T01:06:26.486744Z INFO shard-manager: text_generation_launcher: Starting shard rank=2
.
.
.
.
2024-09-14T01:09:41.599375Z WARN tokenizers::tokenizer::serialization: /usr/local/cargo/registry/src/index.crates.io-6f17d22bba15001f/tokenizers-0.19.1/src/tokenizer/serialization.rs:159: Warning: Token '<|reserved_special_token_247|>' was expected to have ID '128255' but was given ID 'None'
2024-09-14T01:09:41.601329Z INFO text_generation_router: router/src/main.rs:357: Using config Some(Llama)
2024-09-14T01:09:41.601337Z WARN text_generation_router: router/src/main.rs:366: no pipeline tag found for model /model
2024-09-14T01:09:41.601339Z WARN text_generation_router: router/src/main.rs:384: Invalid hostname, defaulting to 0.0.0.0
2024-09-14T01:09:42.024203Z INFO text_generation_router::server: router/src/server.rs:1572: Warming up model
2024-09-14T01:09:48.458410Z INFO text_generation_launcher: Cuda Graphs are enabled for sizes [32, 16, 8, 4, 2, 1]
2024-09-14T01:09:51.114877Z INFO text_generation_router::server: router/src/server.rs:1599: Using scheduler V3
2024-09-14T01:09:51.114907Z INFO text_generation_router::server: router/src/server.rs:1651: Setting max batch total tokens to 55824
2024-09-14T01:09:51.221691Z INFO text_generation_router::server: router/src/server.rs:1889: ConnectedConfirming the deployment
To confirm that the model is working, send a curl command. Ensure that you use the localhost if you submit the request from the node or the IP address of the host if you are testing from other system.
fbronzati@login01:/mnt/f710/vllm$ curl -X 'POST' 'http://localhost:80/v1/completions' -H 'accept: application/json' -H 'Content-Type: application/json' -d '{
"model": "meta-llama/Meta-Llama-3.1-405B-Instruct-FP8",
"prompt": "Once upon a time",
"max_tokens": 64
}' The following example is a response from the model:
{"object":"text_completion","id":"","created":1726319779,"model":"/model","system_fingerprint":"2.2.0-sha-db7e043","choices":[{"index":0,"text":" in the not so distant past, “EarthFirst” – a search word in the Datastream terminal in the university’s Reference Library brought up a thumbnail entry for Earth First!\nAccording to the International Association of Scholarly Publishers Second Nature Project, published in The Open Library the Earth First! movement held an impressive set of un","logprobs":null,"finish_reason":"length"}],"usage":{"prompt_tokens":5,"completion_tokens":64,"total_tokens":69}}Because the container being used supports the OpenAI API, you can use Python or other languages to interact with the model.
Deploying with Kubernetes
For deploying the model with Kubernetes, go to https://dell.huggingface.co/authenticated/models/meta-llama/Meta-Llama-3.1-405B-Instruct-FP8/deploy/kubernetes?gpus=8&replicas=1&sku=xe9680-nvidia-h100 to access the Dell Enterprise Hub.
Creating the deployment file
To create the deployment file, copy the example available at https://dell.huggingface.co/authenticated/models/meta-llama/Meta-Llama-3.1-405B-Instruct-FP8/deploy/kubernetes?gpus=8&replicas=1&sku=xe9680-nvidia-h100 and save it to a YAML file. For our example, we saved the file as deploy-hf-llama3.1-405B-8xH100-9680.yaml.
The following example is a copy of the content from the Dell Enterprise Hub. We recommend that you always consult the Dell Enterprise Hub for the latest updates.
apiVersion: apps/v1 kind: Deployment metadata: name: tgi-deployment spec: replicas: 1 selector: matchLabels: app: tgi-server template: metadata: labels: app: tgi-server hf.co/model: meta-llama--Meta-Llama-3.1-405B-Instruct-FP8 hf.co/task: text-generation spec: containers: - name: tgi-container image: registry.dell.huggingface.co/enterprise-dell-inference-meta-llama-meta-llama-3.1-405b-instruct-fp8 resources: limits: nvidia.com/gpu: 8 env: - name: NUM_SHARD value: "8" - name: MAX_BATCH_PREFILL_TOKENS value: "16182" - name: MAX_INPUT_TOKENS value: "8000" - name: MAX_TOTAL_TOKENS value: "8192" volumeMounts: - mountPath: /dev/shm name: dshm volumes: - name: dshm emptyDir: medium: Memory sizeLimit: 1Gi nodeSelector: nvidia.com/gpu.product: NVIDIA-H100-80GB-HBM3 --- apiVersion: v1 kind: Service metadata: name: tgi-service spec: type: LoadBalancer ports: - protocol: TCP port: 80 targetPort: 80 selector: app: tgi-server --- apiVersion: networking.k8s.io/v1 kind: Ingress metadata: name: tgi-ingress annotations: nginx.ingress.kubernetes.io/rewrite-target: / spec: ingressClassName: nginx-ingress rules: - http: paths: - path: / pathType: Prefix backend: service: name: tgi-service port: number: 80
Creating the Kubernetes namespace and secrets
After creating the deployment file, create a namespace. For our example, we used deh for simple identification on the pods:
fbronzati@login01:/mnt/f710/DEH$ kubectl create namespace deh namespace/deh created
Deploying the deh pod
To deploy the pod and the services that are required to access the model, run the following command:fbronzati@login01:/mnt/f710/DEH$ kubectl apply -f deploy-hf-llama3.1-405B-8xH100-9680.yaml -n dehdeployment.apps/tgi-deployment created service/tgi-service created ingress.networking.k8s.io/tgi-ingress created
For a first-time deployment, the process of downloading the image takes some time because the container is approximately 507 GB and the model is built in to the container image.- To monitor the deployment of the pod and services, run the following commands:
fbronzati@helios25:~$ kubectl get pods -n deh -o wideNAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES tgi-deployment-69fd54c8dd-9fzgn 0/1 ContainerCreating 0 4h49m <none> helios25 <none> <none> fbronzati@helios25:~$ kubectl get services -n deh -o wide NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE SELECTOR tgi-service LoadBalancer *.*.*.* <pending> 80:30523/TCP 4h49m app=tgi-server
- To verify any errors or if the container image is being downloaded, run the kubectl describe command:
fbronzati@login01:/mnt/f710/DEH$ kubectl describe pod tgi-deployment-69fd54c8dd-9fzgn -n deh
Name: tgi-deployment-69fd54c8dd-9fzgn
Namespace: deh
Priority: 0
Service Account: default
Node: helios25/*.*.*.*
Start Time: Fri, 13 Sep 2024 07:19:38 -0500
Labels: app=tgi-server
hf.co/model=meta-llama--Meta-Llama-3.1-8B-Instruct
hf.co/task=text-generation
pod-template-hash=69fd54c8dd
Annotations: cni.projectcalico.org/containerID: c68dc175a1e11bb85435c6b8aaf193c106959087af26f496d7d71cba1b43b779
cni.projectcalico.org/podIP: *.*.*.*/32
cni.projectcalico.org/podIPs: *.*.*.*/32
k8s.v1.cni.cncf.io/network-status:
[{
"name": "k8s-pod-network",
"ips": [
"*.*.*.*"
],
"default": true,
"dns": {}
}]
k8s.v1.cni.cncf.io/networks-status:
[{
"name": "k8s-pod-network",
"ips": [
"*.*.*.*"
],
"default": true,
"dns": {}
}]
Status: Running
IP: *.*.*.*
IPs:
IP: *.*.*.*
Controlled By: ReplicaSet/tgi-deployment-69fd54c8dd
Containers:
tgi-container:
Container ID: containerd://813dc0f197e53d51cfd1a2e9df531cacdfeec0ad205ca517f6c536de509f6182
Image: registry.dell.huggingface.co/enterprise-dell-inference-meta-llama-meta-llama-3.1-405b-instruct-fp8
Image ID: registry.dell.huggingface.co/enterprise-dell-inference-meta-llama-meta-llama-3.1-405b-instruct-fp8@sha256:c6819ff57444f51abb2a2a5aabb12b103b346bfb056738a613f3fcc0eecbd322
Port: <none>
Host Port: <none>
State: Running
Started: Fri, 13 Sep 2024 17:30:38 -0500
Ready: True
Restart Count: 0
Limits:
nvidia.com/gpu: 8
Requests:
nvidia.com/gpu: 8
Environment:
NUM_SHARD: 8
PORT: 80
MAX_BATCH_PREFILL_TOKENS: 16182
MAX_INPUT_TOKENS: 8000
MAX_TOTAL_TOKENS: 8192
Mounts:
/dev/shm from dshm (rw)
/var/run/secrets/kubernetes.io/serviceaccount from kube-api-access-zxwnf (ro)
Conditions:
Type Status
Initialized True
Ready True
ContainersReady True
PodScheduled True
Volumes:
dshm:
Type: EmptyDir (a temporary directory that shares a pod's lifetime)
Medium: Memory
SizeLimit: <unset>
kube-api-access-zxwnf:
Type: Projected (a volume that contains injected data from multiple sources)
TokenExpirationSeconds: 3607
ConfigMapName: kube-root-ca.crt
ConfigMapOptional: <nil>
DownwardAPI: true
QoS Class: BestEffort
Node-Selectors: nvidia.com/gpu.product=NVIDIA-H100-80GB-HBM3
Tolerations: node.kubernetes.io/not-ready:NoExecute op=Exists for 300s
node.kubernetes.io/unreachable:NoExecute op=Exists for 300s
Events:
Type Reason Age From Message
---- ------ ---- ---- -------
Normal Pulled 52m kubelet Successfully pulled image "registry.dell.huggingface.co/enterprise-dell-inference-meta-llama-meta-llama-3.1-405b-instruct-fp8" in 10h10m58.973s (10h10m58.973s including waiting)
Normal Created 52m kubelet Created container tgi-container
Normal Started 52m kubelet Started container tgi-containerModel Initialization
The model is integrated in the container in the Dell Enterprise Hub. When the container image is downloaded and the container is running, the model is loaded on the GPUs and is ready for use in a few minutes.
To monitor the logs of the pod to verify if the loading process worked or if verification is required, run the following command:
fbronzati@helios25:~$ kubectl logs tgi-deployment-69fd54c8dd-9fzgn -n deh
2024-09-13T22:30:38.886576Z INFO text_generation_launcher: Args {
model_id: "/model",
revision: None,
validation_workers: 2,
sharded: None,
num_shard: Some(
8,
),
quantize: None,
speculate: None,
dtype: None,
trust_remote_code: false,
max_concurrent_requests: 128,
max_best_of: 2,
max_stop_sequences: 4,
max_top_n_tokens: 5,
max_input_tokens: Some(
8000,
),
max_input_length: None,
max_total_tokens: Some(
8192,
),
waiting_served_ratio: 0.3,
max_batch_prefill_tokens: Some(
16182,
),
max_batch_total_tokens: None,
max_waiting_tokens: 20,
max_batch_size: None,
cuda_graphs: None,
hostname: "tgi-deployment-69fd54c8dd-9fzgn",
port: 80,
shard_uds_path: "/tmp/text-generation-server",
master_addr: "localhost",
master_port: 29500,
huggingface_hub_cache: Some(
"/data",
),
weights_cache_override: None,
disable_custom_kernels: false,
cuda_memory_fraction: 1.0,
rope_scaling: None,
rope_factor: None,
json_output: false,
otlp_endpoint: None,
otlp_service_name: "text-generation-inference.router",
cors_allow_origin: [],
watermark_gamma: None,
watermark_delta: None,
ngrok: false,
ngrok_authtoken: None,
ngrok_edge: None,
tokenizer_config_path: None,
disable_grammar_support: false,
env: false,
max_client_batch_size: 4,
lora_adapters: None,
disable_usage_stats: false,
disable_crash_reports: false,
}
2024-09-13T22:30:38.886713Z INFO text_generation_launcher: Using default cuda graphs [1, 2, 4, 8, 16, 32]
2024-09-13T22:30:38.886717Z INFO text_generation_launcher: Sharding model on 8 processes
2024-09-13T22:30:38.886793Z INFO download: text_generation_launcher: Starting check and download process for /model
2024-09-13T22:30:45.130039Z INFO text_generation_launcher: Files are already present on the host. Skipping download.
2024-09-13T22:30:45.991211Z INFO download: text_generation_launcher: Successfully downloaded weights for /model
2024-09-13T22:30:45.991407Z INFO shard-manager: text_generation_launcher: Starting shard rank=0
2024-09-13T22:30:45.991421Z INFO shard-manager: text_generation_launcher: Starting shard rank=1
.
.
.
.
2024-09-13T22:33:22.394579Z INFO shard-manager: text_generation_launcher: Shard ready in 156.399351673s rank=7
2024-09-13T22:33:22.394877Z INFO shard-manager: text_generation_launcher: Shard ready in 156.4004131s rank=5
2024-09-13T22:33:22.490441Z INFO text_generation_launcher: Starting Webserver
2024-09-13T22:33:22.875150Z WARN tokenizers::tokenizer::serialization: /usr/local/cargo/registry/src/index.crates.io-6f17d22bba15001f/tokenizers-0.19.1/src/tokenizer/serialization.rs:159: Warning: Token '<|begin_of_text|>' was expected to have ID '128000' but was given ID 'None'
.
.
.
.
2024-09-13T22:33:22.875571Z WARN tokenizers::tokenizer::serialization: /usr/local/cargo/registry/src/index.crates.io-6f17d22bba15001f/tokenizers-0.19.1/src/tokenizer/serialization.rs:159: Warning: Token '<|reserved_special_token_247|>' was expected to have ID '128255' but was given ID 'None'
2024-09-13T22:33:22.877378Z INFO text_generation_router: router/src/main.rs:357: Using config Some(Llama)
2024-09-13T22:33:22.877385Z WARN text_generation_router: router/src/main.rs:366: no pipeline tag found for model /model
2024-09-13T22:33:22.877388Z WARN text_generation_router: router/src/main.rs:384: Invalid hostname, defaulting to 0.0.0.0
2024-09-13T22:33:23.514440Z INFO text_generation_router::server: router/src/server.rs:1572: Warming up model
2024-09-13T22:33:28.860027Z INFO text_generation_launcher: Cuda Graphs are enabled for sizes [32, 16, 8, 4, 2, 1]
2024-09-13T22:33:30.914329Z INFO text_generation_router::server: router/src/server.rs:1599: Using scheduler V3
2024-09-13T22:33:30.914341Z INFO text_generation_router::server: router/src/server.rs:1651: Setting max batch total tokens to 54016
2024-09-13T22:33:30.976105Z INFO text_generation_router::server: router/src/server.rs:1889: ConnectedVerifying the model’s use of GPU memory
You can verify GPU use by using the nvidia-smi utility. However, with the Dell AI Factory, you can also monitor GPU use with Base Command Manager. The following figure shows that 590 GB of the memory is being used for the PowerEdge XE9680 server with eight NVIDIA H100 GPUs with 80 GB, for a total of 640 GB:
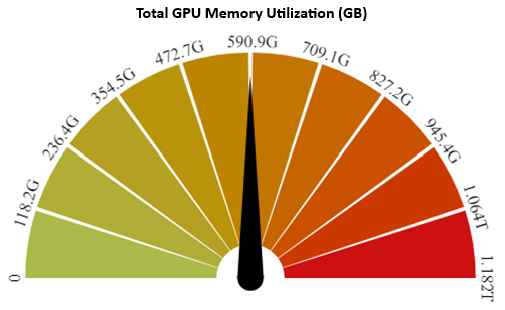
Figure 1: Total GPU memory use
There is an option to identify the memory use of each GPU. The following figure shows that all GPUs are being evenly used with approximately 73 GB of memory:
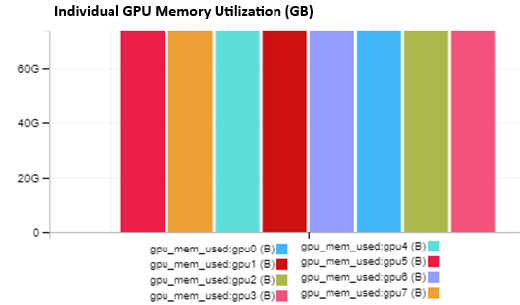
Figure 2: Individual GPU memory use
Confirming the model
When the model is loaded on the GPUs, send a curl command to confirm that is working as planned:
fbronzati@login01:/mnt/f710/DEH$ curl -X 'POST' 'http://*.*.*.*:80/v1/completions' -H 'accept: application/json' -H 'Content-Type: application/json' -d '{
"model": "meta-llama/Meta-Llama-3.1-405B-Instruct-FP8",
"prompt": "Once upon a time",
"max_tokens": 64
}'The following example is a response from the model:
{"object":"text_completion","id":"","created":1726269695,"model":"/model","system_fingerprint":"2.2.0-sha-db7e043","choices":[{"index":0,"text":", in a small village nestled in the rolling hills of the countryside, there lived a young girl named Emily. Emily was a curious and adventurous child, with a mop of curly brown hair and a smile that could light up the darkest of rooms. She loved to explore the world around her, and spent most of her days","logprobs":null,"finish_reason":"length"}],"usage":{"prompt_tokens":5,"completion_tokens":64,"total_tokens":69}}Because the container that is being used deploys the OpenAI API, you can use Python or other languages to interact with the model.
Conclusion
Using the Dell Enterprise Hub using TGI platform is an exceptional and easy option to deploy the Llama 3.1 405b model. The Dell partnership with Hugging Face prepares, optimizes, and tests the containers so that you can focus on the development of the application. It will solve your business problems and alleviates worry about the complexities of optimizing and building your deployment environment.
The Llama 3.1 405b model is a powerful open-source tool that offers various deployment options that can often lead to dilemmas in the deployment process. This blog series aims to clarify what to expect by providing practical examples, including code snippets and outputs, to enhance your understanding. For additional deployment assistance, we developed the Dell AI Factory, which embodies Dell’s strategy for embracing and implementing AI. It ensures successful and consistent deployments at any scale and in any location.
Ultimately, the Llama 3.1 405b model deploys seamlessly on a single Dell PowerEdge XE9680 server, making it an excellent choice for organizations looking to leverage AI technology effectively.