



Dell PowerEdge Servers Achieve Stellar Scores with MLPerf™ Training v3.1
Wed, 08 Nov 2023 17:43:48 -0000
|Read Time: 0 minutes
Abstract
MLPerf is an industry-standard AI performance benchmark. For more information about the MLPerf benchmarks, see Benchmark Work | Benchmarks MLCommons.
Today marks the release of a new set of results for MLPerf Training v3.1. The Dell PowerEdge XE9680, XE8640, and XE9640 servers in the submission demonstrated excellent performance. The tasks included image classification, medical image segmentation, lightweight and heavy-weight object detection, speech recognition, language modeling, recommendation, and text to image. MLPerf Training v3.1 results provide a baseline for end users to set performance expectations.
What is new with MLPerf Training 3.1 and the Dell Technologies submissions?
The following are new for this submission:
- For the benchmarking suite, a new benchmark was added: stable diffusion with the Laion400 dataset.
- Dell Technologies submitted the newly introduced Liquid Assisted Air Cooled (LAAC) PowerEdge XE9640 system, which is a part of the latest generation Dell PowerEdge servers.
Overview of results
Dell Technologies submitted 30 results. These results were submitted using five different systems. We submitted results for the PowerEdge XE9680, XE8640, and XE9640 servers. We also submitted multinode results for the PowerEdge XE9680 and XE8640 servers. The PowerEdge XE9680 server was powered by eight NVIDIA H100 Tensor Core GPUs, while the PowerEdge XE8640 and XE9640 servers were powered by four NVIDIA H100 Tensor Core GPUs each.
Datapoints of interest
Interesting datapoints include:
- Our new stable diffusion results with the PowerEdge XE9680 server have been submitted for the first time and are exclusive. Dell Technologies, NVIDIA, and Habana Labs are the only submitters to have made an official submission. This submission is important because of the explosion of Generative AI workloads. The submission uses the NVIDIA NeMo framework, included in NVIDIA AI Enterprise for secure, supported, and stable production AI.
- Dell PowerEdge XE8640 and XE9640 servers secured several top performer titles (#1 titles) among other systems equipped with four NVIDIA H100 GPUs. The tasks included language modeling, recommendation, heavy-weight object detection, speech to text, and medical image segmentation.
- A number of multinode results were submitted for the previous round, which can be compared with this round. PowerEdge XE9680 multinode results were submitted. Additionally, this round was the first time multinode results with the newer generation PowerEdge XE8640 servers were submitted. The results show near linear scaling. Furthermore, Dell Technologies is the only submitter in addition to NVIDIA, Habana Labs, and Intel making multinode, on-premises result submissions.
- The results for the PowerEdge XE9640 server with liquid assisted air cooling (LAAC) are similar to the PowerEdge XE8640 air-cooled server.
The following figure shows all the convergence times for Dell systems and corresponding workloads in the benchmark. Because different benchmarks are included in the same graph, the y axis is expressed logarithmically. Overall, these numbers show an excellent time to converge for the workload in question.
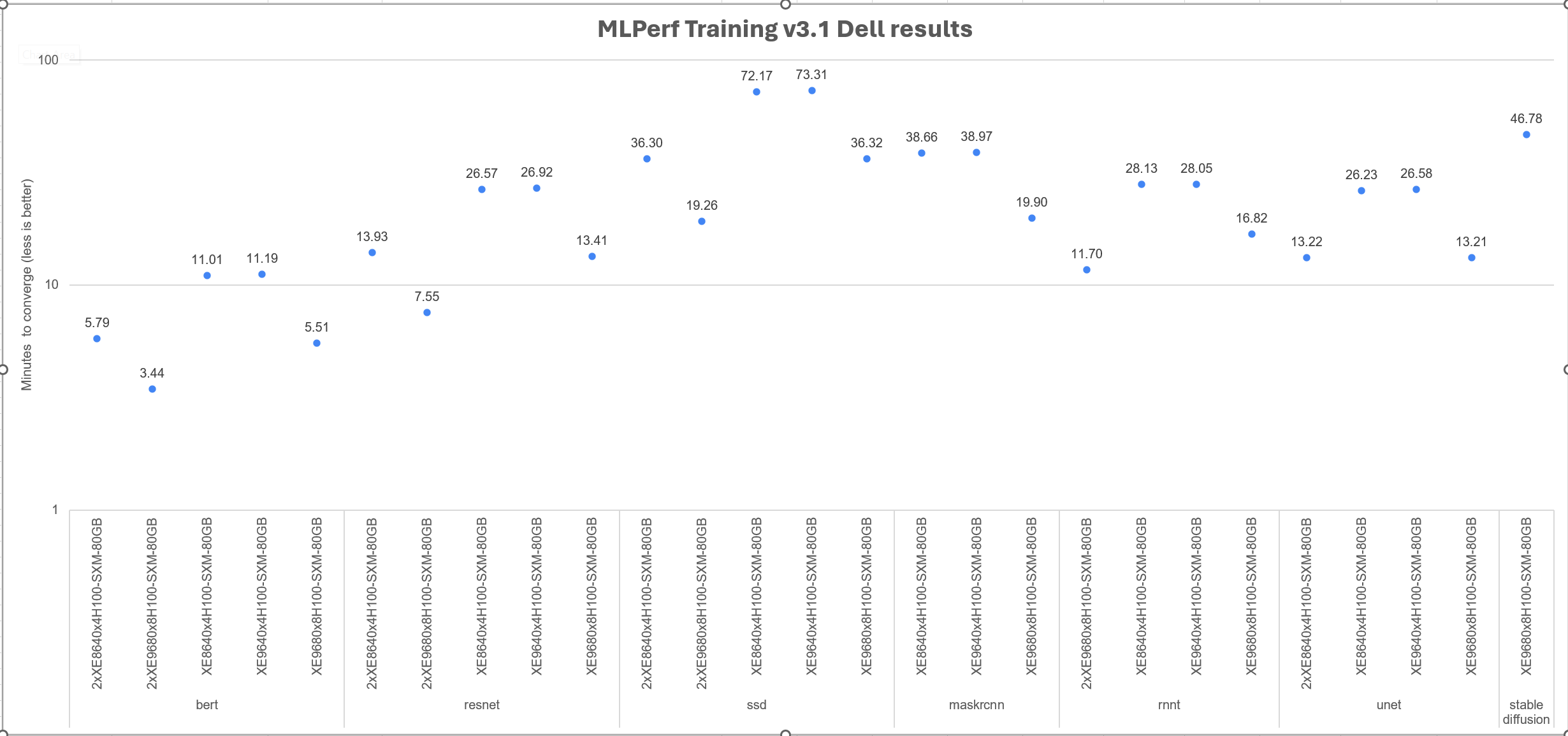
Figure 1. Logarithmic y axis: Overview of Dell MLPerf Training v3.1 results
Conclusion
We submitted compliant results for the MLCommons Training v3.1 benchmark. These results are based on the latest generation of Dell PowerEdge XE9680, XE8640, and XE9640 servers, powered by NVIDIA H100 Tensor Core GPUs. All results are stellar. They demonstrate that multinode scaling is linear and that more servers can help to solve the same problem faster. Different results allow end users to make decisions about expected performance before deploying their compute-intensive training workloads. The workloads in the submission include image classification, medical image segmentation, lightweight and heavy-weight object detection, speech recognition, language modeling, recommendation, and text to image. Enterprises can enable and maximize their AI transformation with Dell Technologies efficiently with Dell solutions.
MLCommons Results
https://mlcommons.org/benchmarks/training/
The preceding graphs are MLCommons results for MLPerf IDs from 3.1-2005 to 3.1-2009.
The MLPerf™ name and logo are trademarks of MLCommons Association in the United States and other countries. All rights reserved. Unauthorized use strictly prohibited. See www.mlcommons.org for more information.
Related Blog Posts
Dell Technologies Shines in MLPerf™ Stable Diffusion Results
Tue, 12 Dec 2023 14:51:21 -0000
|Read Time: 0 minutes
Abstract
The recent release of MLPerf Training v3.1 results includes the newly launched Stable Diffusion benchmark. At the time of publication, Dell Technologies leads the OEM market in this performance benchmark for training a Generative AI foundation model, especially for the Stable Diffusion model. With the Dell PowerEdge XE9680 server submission, Dell Technologies is differentiated as the only vendor with a Stable Diffusion score for an eight-way system. The time to converge by using eight NVIDIA H100 Tensor Core GPUs is 46.7 minutes.
Overview
Generative AI workload deployment is growing at an unprecedented rate. Key reasons include increased productivity and the increasing convergence of multimodal input. Creating content has become easier and is becoming more plausible across various industries. Generative AI has enabled many enterprise use cases, and it continues to expand by exploring more frontiers. This growth can be attributed to higher resolution text to image, text-to-video generations, and other modality generations. For these impressive AI tasks, the need for compute is even more expansive. Some of the more popular generative AI workloads include chatbot, video generation, music generation, 3D assets generation, and so on.
Stable Diffusion is a deep learning text-to-image model that accepts input text and generates a corresponding image. The output is credible and appears to be realistic. Occasionally, it can be hard to tell if the image is computer generated. Consideration of this workload is important because of the rapid expansion of use cases such as eCommerce, marketing, graphics design, simulation, video generation, applied fashion, web design, and so on.
Because these workloads demand intensive compute to train, the measurement of system performance during their use is essential. As an AI systems benchmark, MLPerf has emerged as a standard way to compare different submitters that include OEMs, accelerator vendors, and others in a like-to-like way.
MLPerf recently introduced the Stable Diffusion benchmark for v3.1 MLPerf Training. It measures the time to converge a Stable Diffusion workload to reach the expected quality targets. The benchmark uses the Stable Diffusion v2 model trained on the LAION-400M-filtered dataset. The original LAION 400M dataset has 400 million image and text pairs. A subset of those images (approximately 6.5 million) is used for training in the benchmark. The validation dataset is a subset of 30 K COCO 2014 images. Expected quality targets are FID <= 90 and CLIP>=0.15.
The following figure shows a latent diffusion model[1]:
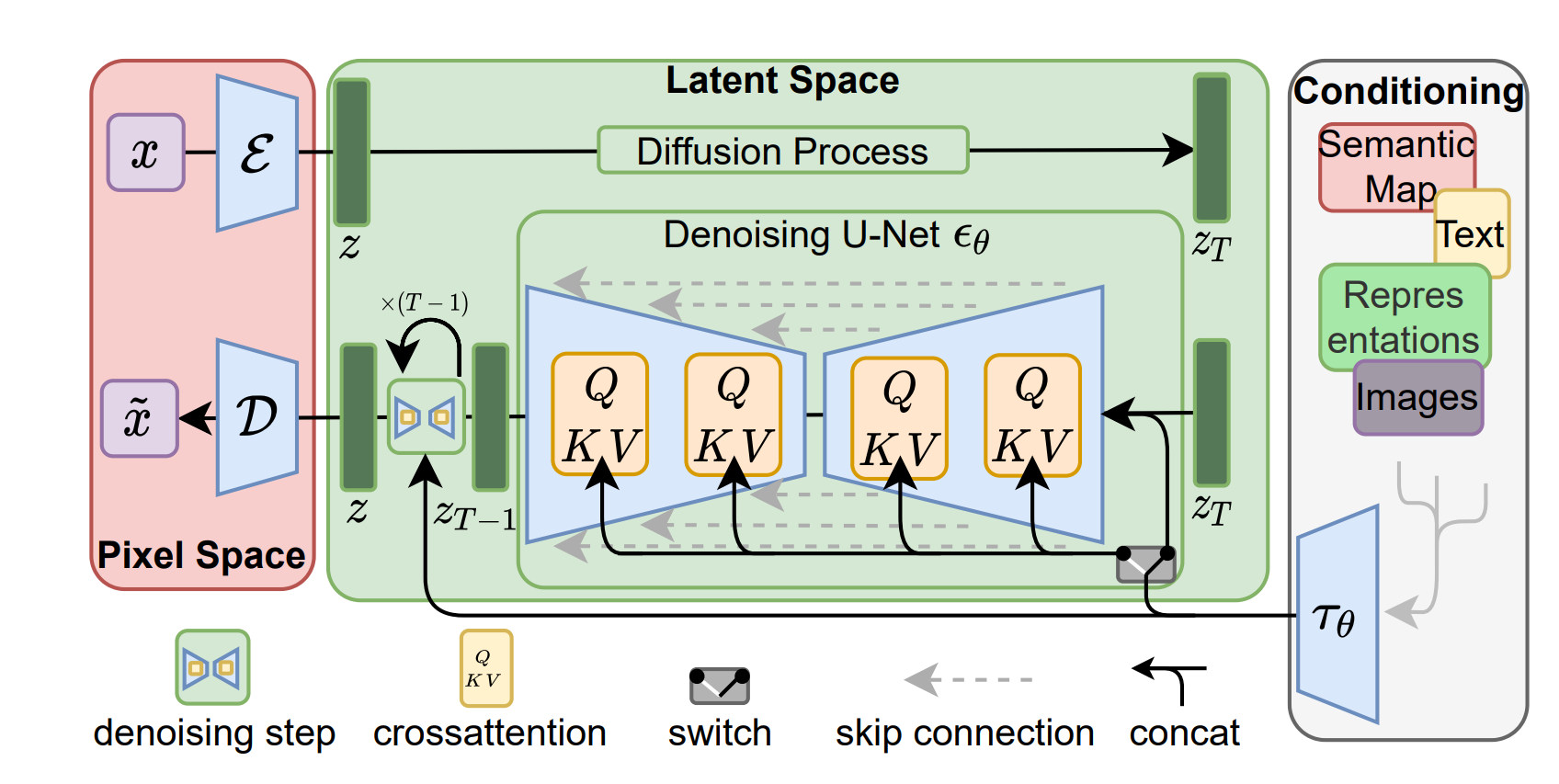
Figure 1: Latent diffusion model
[1] Source: https://arxiv.org/pdf/2112.10752.pdf
Stable Diffusion v2 is a latent diffusion model that combines an autoencoder with a diffusion model that is trained in the latent space of the autoencoder. MLPerf Stable Diffusion focuses on the U-Net denoising network, which has approximately 865 M parameters. There are some deviations from the v2 model. However, these adjustments are minor and encourage more submitters to make submissions with compute constraints.
The submission uses the NVIDIA NeMo framework, included with NVIDIA AI Enterprise, for secure, supported, and stable production AI. It is a framework to build, customize, and deploy generative AI models. It includes training and inferencing frameworks, guard railing toolkits, data curation tools, and pretrained models, offering enterprises an easy, cost effective, and a fast way to adopt generative AI.
Performance of the Dell PowerEdge XE9680 server and other NVIDIA-based GPUs on Stable Diffusion
The following figure shows the performance of NVIDIA H100 Tensor Core GPU-based systems on the Stable Diffusion benchmark. It includes submissions from Dell Technologies and NVIDIA that use different numbers of NVIDIA H100 GPUs. The results shown vary from eight GPUs (Dell submission) to 1024 GPUs (NVIDIA submission). The following figure shows the expected performance of this workload and demonstrates that strong scaling is achievable with less scaling loss.
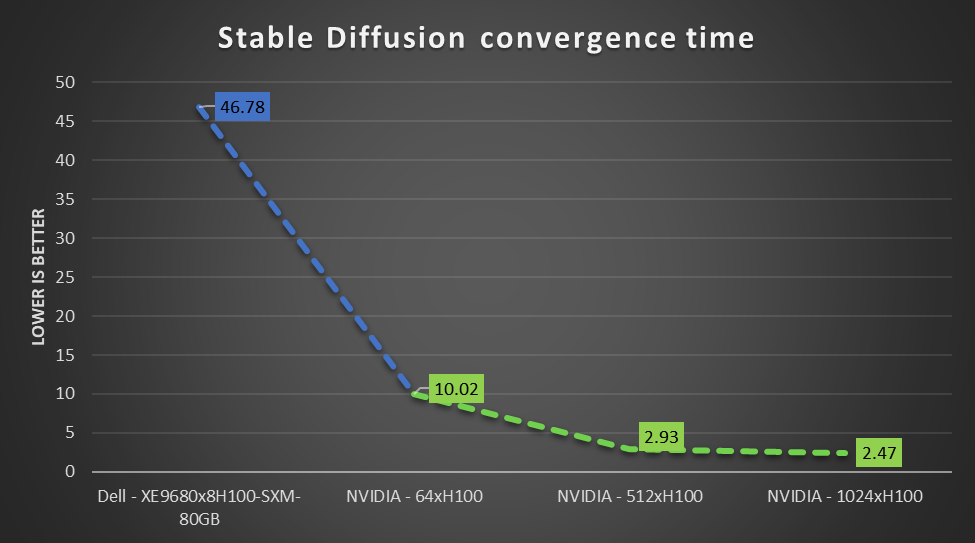
Figure 2: MLPerf Training Stable Diffusion scaling results on NVIDIA H100 GPUs from Dell Technologies and NVIDIA
End users can use state-of-the-art compute to derive faster time to value.
Conclusion
The key takeaways include:
- The latest released MLPerf Training v3.1 measures Generative AI workloads like Stable Diffusion.
- Dell Technologies is the only OEM vendor to have made an MLPerf-compliant Stable Diffusion submission.
- The Dell PowerEdge XE9680 server is an excellent choice to derive value from Image Generation AI workloads for marketing, art, gaming, and so on. The benchmark results are outstanding for Stable Diffusion v2.
MLCommons Results
https://mlcommons.org/benchmarks/training/
The preceding graphs are MLCommons results for MLPerf IDs 3.1-2019, 3.1-2050, 3.1-2055, and 3.1-2060.
The MLPerf™ name and logo are trademarks of MLCommons Association in the United States and other countries. All rights reserved. Unauthorized use strictly prohibited. See www.mlcommons.org for more information.
Promising MLPerf™ Inference 3.1 Performance of Dell PowerEdge XE8640 and XE9640 Servers with NVIDIA H100 GPUs
Wed, 04 Oct 2023 20:54:55 -0000
|Read Time: 0 minutes
Abstract
The recent release of MLPerf Inference v3.1 showcased the latest performance results from Dell's new PowerEdge XE8640 and PowerEdge XE9640 servers, and another submission from the PowerEdge R760xa server. The data underscores the outstanding performance of PowerEdge servers. These benchmarks illustrate the surging demand for compute power, with PowerEdge servers consistently emerging on top across various models, claiming numerous top titles. This blog examines the expected performance for image classification, object detection, question answering, speech recognition, medical image segmentation and summarization, focusing specifically on the capabilities of the PCIe and SXM form factor NVIDIA H100 Tensor Core GPUs in the new generation PowerEdge systems.
Overview of top title results
The PowerEdge XE8640 and XE9640 servers won several #1 titles.
For instance, the PowerEdge XE8640 server emerged as a winner in all benchmarks in the data center suite such as image classification, object detection, question answering, speech recognition, medical image segmentation, and summarization relative to other systems having four NVIDIA H100 SXM GPUs. The PowerEdge XE9640 server received #1 titles for all benchmarks previously mentioned relative to other liquid-cooled systems having four NVIDIA H100 SXM GPUs.
Comparison from the previous rounds of submission
The following figure shows the improvement customers can derive by using the new generation PowerEdge XE8640 and XE9640 servers from our previous generation PowerEdge XE8545 server.
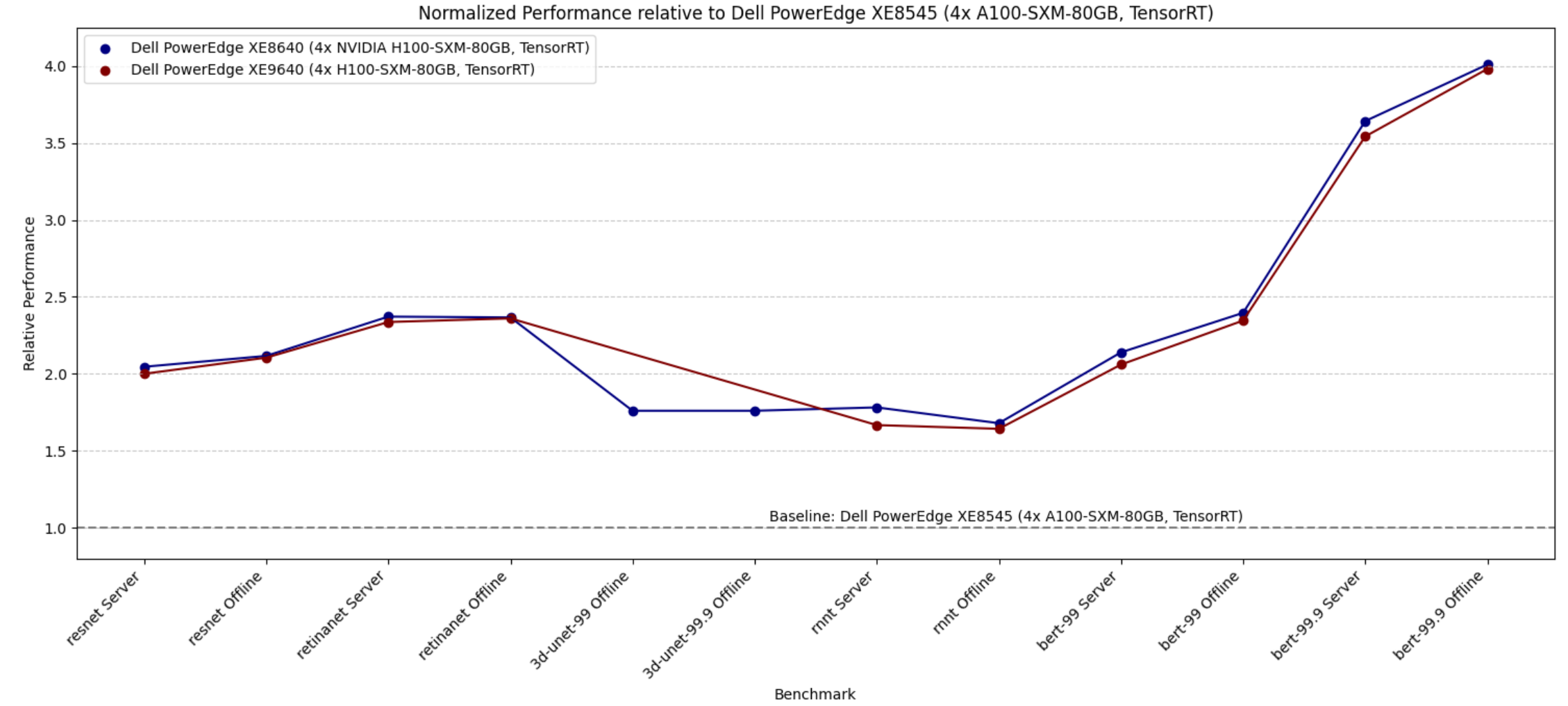
Figure 1. Relative performance of PowerEdge XE8640 and PowerEdge XE9640 servers using the PowerEdge XE8545 server as a baseline reference (for the Y axis, the higher the better)
The graph shows that the relative performance improvement from the PowerEdge XE8545 server with four NVIDIA A100 SXM Tensor Core GPUs as a baseline (from MLPerf Inference v3.0) and the new generation severs such as the PowerEdge XE8640 and PowerEdge XE9640 servers using NVIDIA H100 Tensor Core GPUs. The improvement in performance is substantial, as evident from the graph. End users can derive a two- to four-times improvement in performance for different tasks in MLPerf Inference benchmarks. We see relatively higher performance with BERT benchmarks because of the NVIDIA H100 GPU’s FP8 support.
Comparing air-cooled and liquid-cooled servers
The following figure shows the raw performance of PowerEdge XE8640 and XE9640 servers; this graph and the following graph provide relative scores. The graph includes all the benchmarks in the Inference closed data center suite that we submitted. Note that different benchmarks have different scales. All the benchmarks are presented in one graph, therefore, the y-axis is expressed logarithmically.
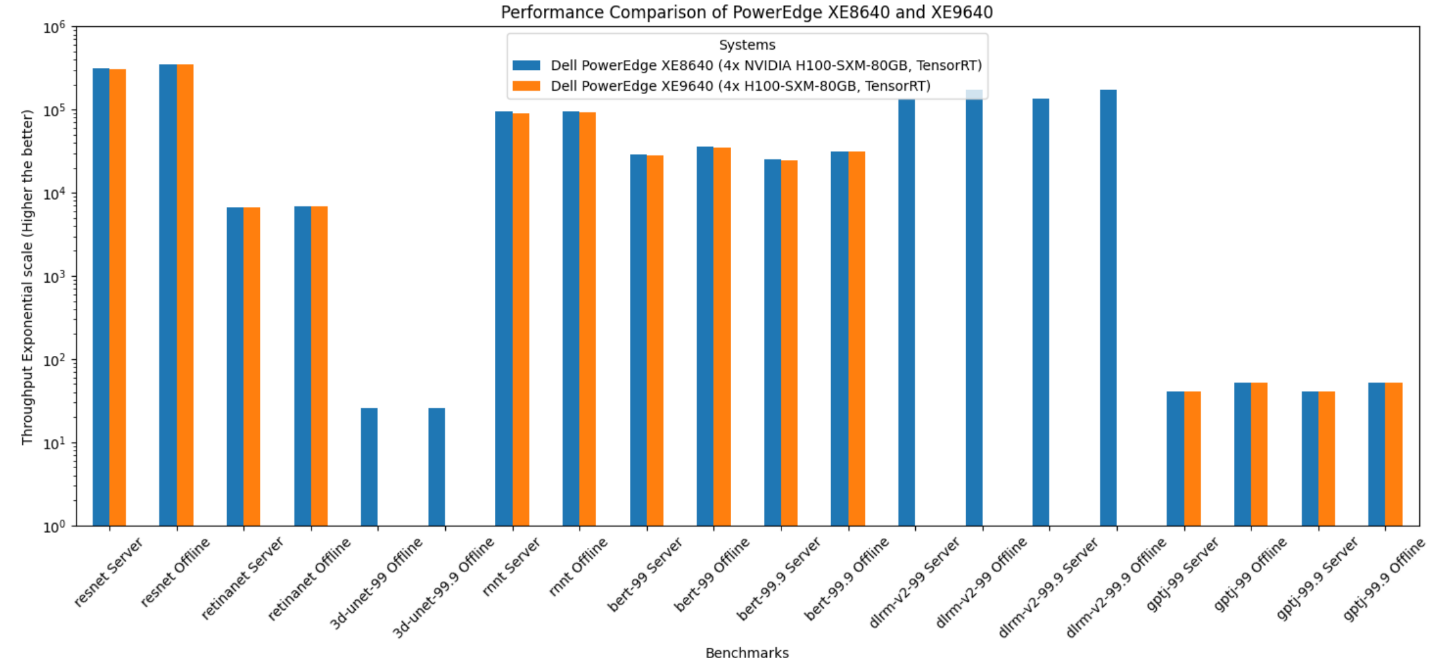
Figure 2. Performance of PowerEdge XE8640 and PowerEdge XE9640 servers
PowerEdge XE8640 and XE9640 servers are both great choices for inference workloads with four NVIDIA H100 SXM Tensor Core GPUs. The PowerEdge XE9640 server is a liquid-cooled server and the PowerEdge XE8640 server is an air-cooled server. The following figure shows the difference in performance between these systems; they both performed optimally. Both systems have similar effective throughput and render excellent performance as the CPU and GPU configurations are the same.
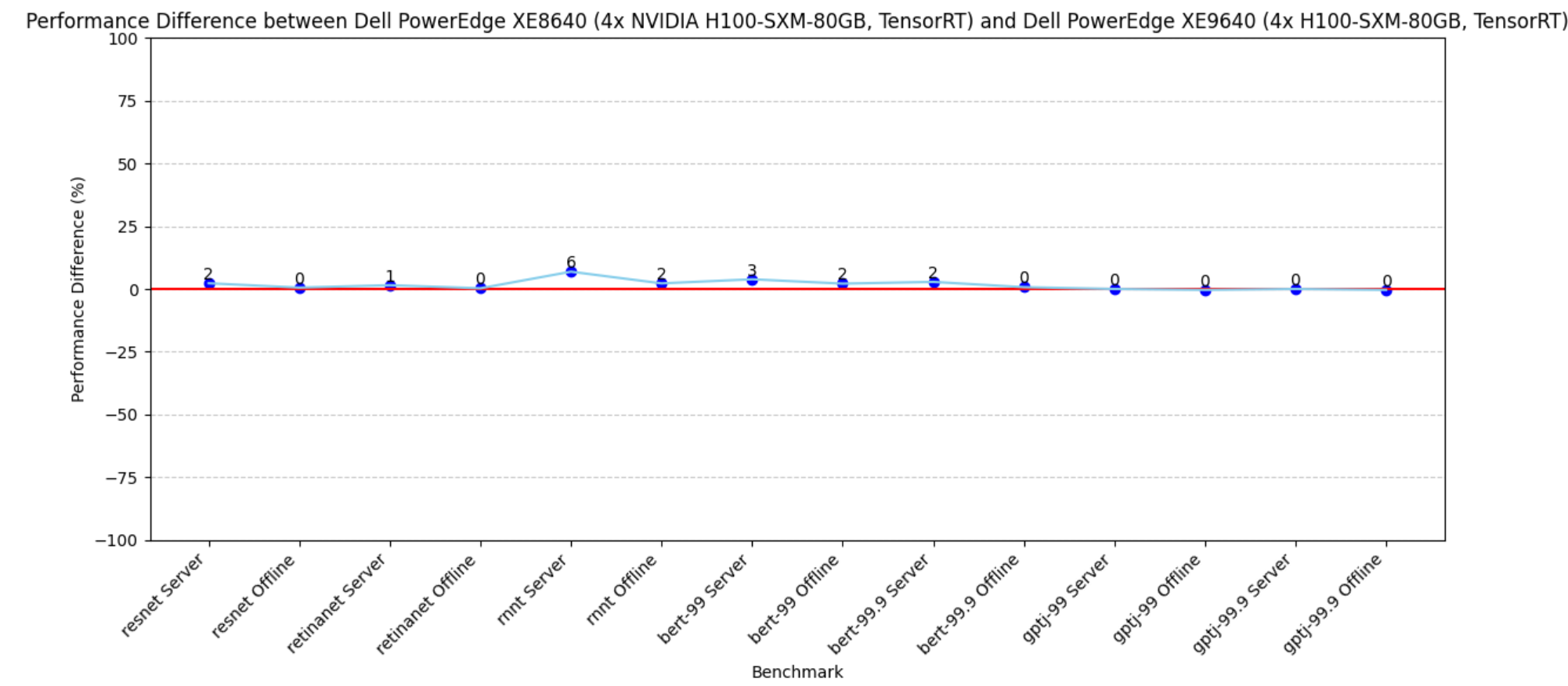
Figure 3. Performance difference between PowerEdge XE9640 and XE8640 servers using the PowerEdge XE9640 server as a baseline
Impact of SXM over PCIe form factors
The following figure shows the performance of the PowerEdge R760xa server with NVIDIA H100 PCIe GPUs as the baseline and shows the performance improvement of PowerEdge XE9640 and PowerEdge XE8640 servers with NVIDIA H100 Tensor Core SXM GPUs. The graph demonstrates that the PowerEdge XE8640 server with NVIDIA H100 SXM GPUs performs approximately 1.25 to 1.7 times better than the PowerEdge R760xa server with NVIDIA H100 PCIe GPUs.
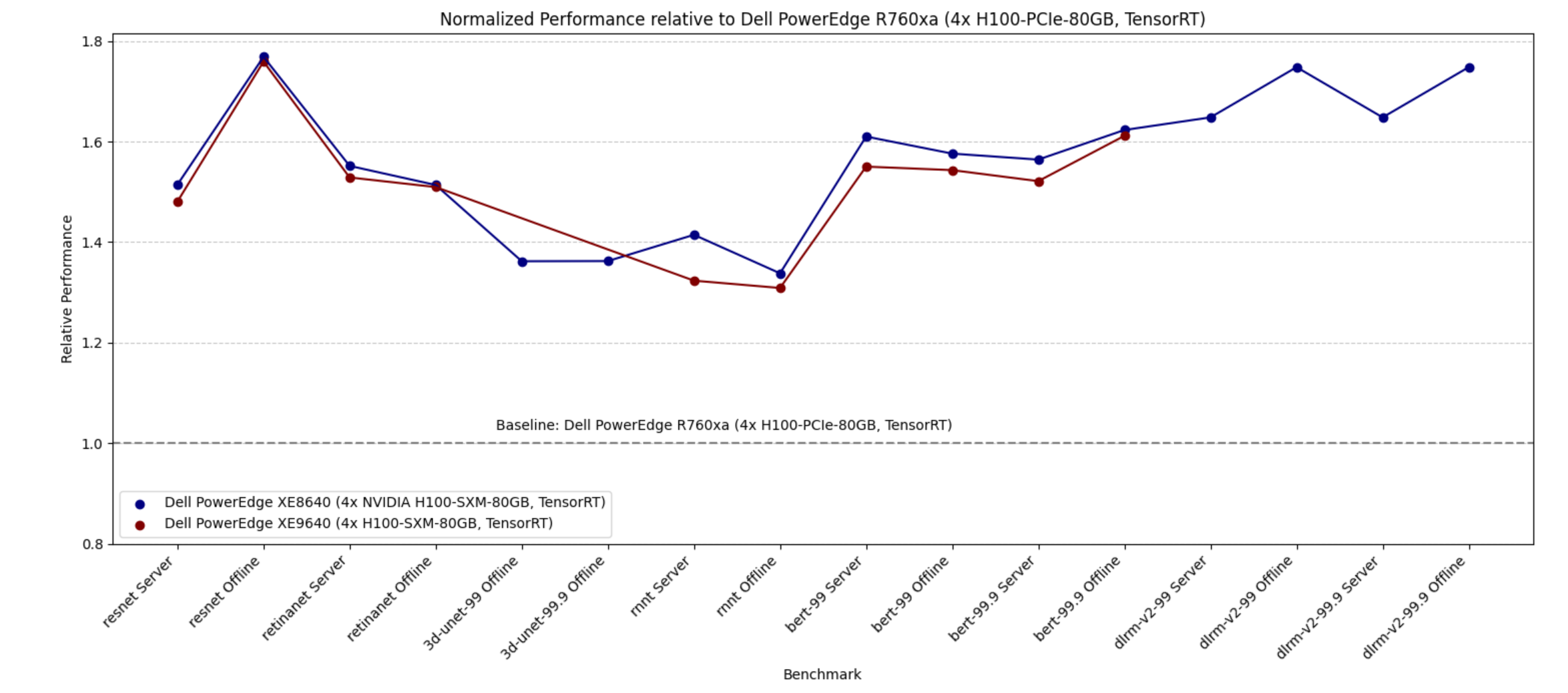
Figure 4. Performance difference between PowerEdge XE9640 and XE8640 servers with 4x H100 SXM and PowerEdge R760xa server with 4x H100 PCIe as a baseline
Because the NVIDIA H100 SXM GPUs have higher Thermal Design Power (TDP), if high performance is imperative, then using NVIDIA SXM GPUs is a great choice.
Comparing efficiency of new and previous generation servers
The following figure shows the performance of the previous generation PowerEdge XE8545 server with NVIDIA A100 SXM GPUs compared to the new generation servers such as the PowerEdge R760xa server with the NVIDIA H100 PCIE form factor and the PowerEdge XE8640 and XE9640 servers with the NVIDIA H100 SXM form factor. We see that all the new generation servers rendered higher performance. Furthermore, our new generation PowerEdge R760xa server with four NVIDIA H100 PCIe GPUs is more power efficient than our previous generation PowerEdge XE8545 server with four NVIDIA A100 SXM GPUs. This result is because NVIDIA A100 SXM GPUs have higher TDP relative to the NVIDIA H100 PCIe GPU.
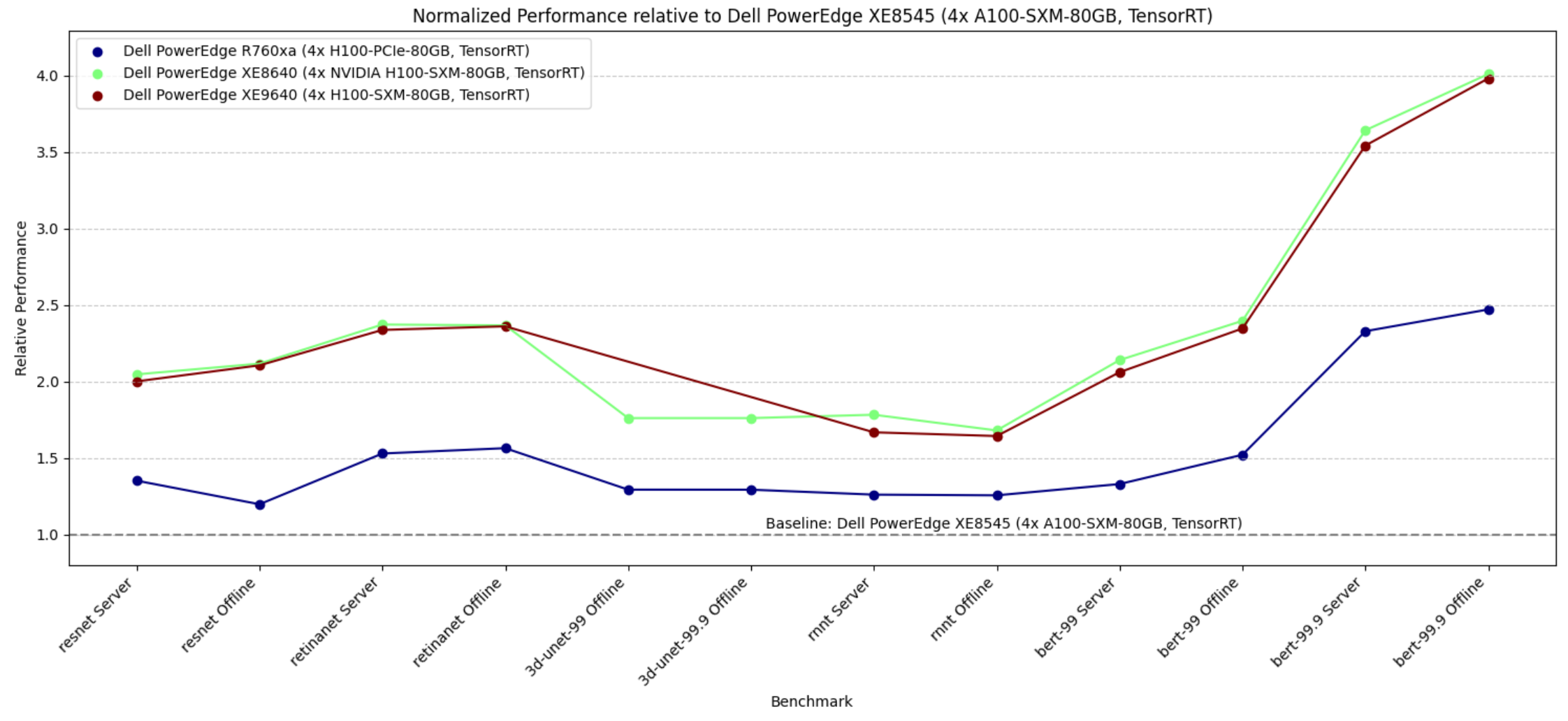
Figure 5. Relative performance of PowerEdge R760xa, PowerEdge XE9640, and PowerEdge XE8640 servers using the PowerEdge XE8545 server as a baseline
Hardware overview
The following sections describe the system components. The appendix lists the system configurations in the benchmark.
Dell PowerEdge XE8640 server
The PowerEdge XE8640 server is an air-cooled 4U server that accelerates traditional AI training and inferencing, modeling, simulation, and other high-performance computing (HPC) applications with optimized compute, turning data and automating insights into outcomes with a four-way GPU platform. Its powerful architecture and the power of two 4th Generation Intel Xeon processors with a high core count of up to 56 cores and the latest on-chip innovations to boost AI and machine learning operations.
The following figure shows the PowerEdge XE8640 server:

Figure 6. Dell PowerEdge XE8640 server
Dell PowerEdge XE9640 server
The PowerEdge XE9640 server is a purpose-built direct liquid-cooled (DLC) 2U server for AI and HPC workloads. NVIDIA NVLink and Intel Xelink technologies in the PowerEdge XE9640 server allow seamless communication between the GPUs, pooling their memory and cores to tackle memory-coherent workloads such as large language models (LLM) efficiently.
The following figure shows the PowerEdge XE9640 server:

Figure 7. Dell PowerEdge XE8640
NVIDIA H100 Tensor core GPU
The NVIDIA H100 GPU is an integral part of the NVIDIA data center platform. Built for AI, HPC, and data analytics, the platform accelerates over 3,000 applications, and is available everywhere from the data center to the edge, delivering both dramatic performance gains and cost-saving opportunities. The NVIDIA H100 Tensor Core GPU delivers unprecedented performance, scalability,
and security for every workload. With NVIDIA® NVLink® Switch System, up to 256
NVIDIA H100 GPUs can be connected to accelerate exascale workloads, while the dedicated
Transformer Engine supports trillion-parameter language models. The NVIDIA H100 GPU uses
breakthrough innovations in the NVIDIA Hopper™ architecture to deliver industry-leading conversational AI, speeding up large language models by 30 times over the previous generation.
The following figure shows the NVIDIA H100 PCIe accelerator:

Figure 8. NVIDIA H100 PCIe accelerator
The following figure shows the NVIDIA H100 SXM accelerator:

Figure 9. NVIDIA H100 SXM accelerator
Conclusion
The key takeaways include:
- Both the Dell PowerEdge XE8640 and Dell PowerEdge XE9640 servers are an excellent choice for inference. The performance of the air-cooled PowerEdge XE8640 server is almost identical to the liquid-cooled PowerEdge XE9640 server. While the PowerEdge XE9640 server is a 2U server, it requires additional cooling unit attachments. It is a good choice if there are space and temperature constraints, otherwise the PowerEdge XE8640 server is a great choice.
- PowerEdge XE8640 and PowerEdge 9640 servers have received several top titles. They are clear leaders in inference compute.
- New generation PowerEdge XE8640 and PowerEdge XE9640 servers with NVIDIA H100 GPUs have delivered 2- to 4-times improvement relative to the previous generation PowerEdge XE8545 server with NVIDIA A100 GPUs. Upgrading from the PowerEdge XE8545 sever would render higher performance.
- The PowerEdge XE9640 and PowerEdge XE8640 servers with four NVIDIA H100 SXM form-factor GPUs are significantly more effective than the PowerEdge R760xa server with four NVIDIA H100 PCIe GPUs by a factor of 1.25 to 1.7 times.
Our submission results to MLPerf Inference since its inception have continuously demonstrated significant performance improvements. We have submitted to different tasks to provide customers with a wide spectrum of possible results to review. This round marked a new and the first submission to MLPerf with PowerEdge XE8640 and XE9640 servers. Customers can rely on these high compute machines for their fast/low latency inference needs. If constrained by TDP or other factors, the PowerEdge R760xa server with the PCIe form factor is an excellent choice on which to run inference workloads.
Appendix
The following table lists the system configuration details for the servers described in this blog:
Table 1. System configurations
| Dell PowerEdge XE 8640 (4x NVIDIA H100-SXM-80GB, TensorRT) | Dell PowerEdge XE 9640 (4x H100-SXM-80GB, TensorRT) | Dell PowerEdge R760xa (4x H100-PCIe-80GB, TensorRT) | Dell PowerEdge XE 8545 (4x A100-SXM-80GB, TensorRT) |
MLPerf submission ID | 3.1-0066 | 3.1-0067 | 3.1-0064 | 3.0-0011 |
MLPerf system ID | XE8640_H100_SXM_80GBx4_TRT | XE9640_H100_SXM_80GBx4_TRT | R760xa_H100_PCIe_80GBx4_TRT | XE8545_A100_SXM4_80GBx4_TRT |
Operating system | Rocky Linux 9.1 | Ubuntu 22.04 | Ubuntu 20.04.4 | Ubuntu 22.04 |
CPU | Intel Xeon Platinum 8480 | Intel Xeon Platinum 8480+ | Intel Xeon Platinum 8480+ | AMD EPYC 7763 |
Memory | 1 TB | 1 TB | 2 TB | 2 TB |
GPU | NVIDIA H100 SXM 80 GB | NVIDIA H100 PCIE 80 GB | NVIDIA A100 SXM 80 GB CTS | |
GPU count | 4 | |||
Software stack | TensorRT 9.0.0 CUDA 12.2 | TensorRT 8.6.0 CUDA 12.2 | ||
MLCommons results
MLPerf system IDs:
- ID 3.0-0011
- ID 3.1-0064
- ID 3.1-0066
- ID 3.1-0067
Note: We reran the RetinaNet Offline benchmark for the PowerEdge R760xa server and the DLRMv2 benchmark for the PowerEdge XE8640 server to reflect the correct performance that the servers can render. Only these two results are not official due to MLCommons rules.
The MLPerf™ name and logo are trademarks of MLCommons Association in the United States and other countries. All rights reserved. Unauthorized use strictly prohibited. See www.mlcommons.org for more information.