




Dell PowerEdge 16G Server BIOS Settings for Optimized Performance: R7625, R6625, R7615, R6615, C6615
Download PDFTue, 26 Mar 2024 22:46:05 -0000
|Read Time: 0 minutes
Related Documents

Improve performance by easily migrating to a modern OpenShift environment on PowerEdge R7615 servers
Tue, 14 May 2024 20:15:19 -0000
|Read Time: 0 minutes
Improve performance and gain room to grow by easily migrating to a modern OpenShift environment on Dell PowerEdge R7615 servers with 4th Generation AMD EPYC processors and high-speed 100GbE Broadcom NICs
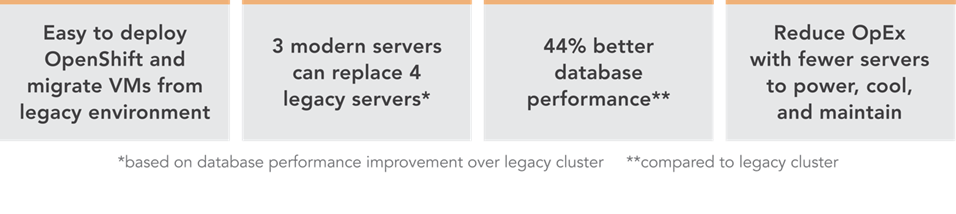
We deployed this modern environment, then migrated database VMs from legacy servers and saw performance improvements that support consolidation.
Transactional databases are the backbone of many business operations, powering ecommerce and order fulfillment, human resources and payroll, and a host of other activities. If your company is running these kinds of workloads on server infrastructure that is several years old, you might believe that performance is adequate and that you have little reason to consider upgrading to new servers with modern processors, networking, and a Red Hat® OpenShift® container-based environment. In fact, by continuing to use this older gear, you could be incurring higher than necessary operating expenditures by maintaining and powering more servers than you need to perform a given volume of work. You could also be risking downtime with aging hardware that is likelier to break down. By upgrading to a modern environment, you could mitigate these issues and future-proof your infrastructure. A 2019 Forrester Consulting report recommended that organizations refresh their servers at least every three years to maximize agility and productivity.[1] The report states not only that modern servers allow organizations to adopt more emerging technologies at a faster rate, but also “modern hardware has a profound impact on business benefits such as better customer experience, employee productivity, and innovation.”[2]
We explored the process of migrating VMs from a legacy environment and conducted testing to quantify the resulting improvements in network and database performance. We started with a legacy environment consisting of MySQL™ virtual machines (VMs) running on a cluster of three Dell™ PowerEdge™ R7515 servers with 3rd Generation AMD EPYC™ processors and 25Gb Broadcom® NICs. We then deployed a modern OpenShift container-based environment comprising three Dell PowerEdge R7615 servers with 4th Generation AMD EPYC processors and high-speed 100Gb Broadcom NICs. While the primary application of OpenShift is typically for containerized workloads, we used OpenShift Virtualization, which presents a familiar VM layer to administrators while utilizing the containerized technology on the underlying layer. Both environments used a Dell PowerStore 1200T for external storage that the servers accessed using iSCSI. We measured database performance using the HammerDB TPROC-C benchmark.
We found that the modern cluster environment of Dell PowerEdge R7615 servers with 4th Generation AMD EPYC processors and high-speed 100Gb Broadcom NICs outperformed the legacy cluster environment, delivering 44 percent greater database performance. These improvements mean that companies that upgrade can enjoy savings by meeting their workload requirements with fewer servers to license, maintain, power, and cool. Selecting 100Gb Broadcom NICs also positions companies well to take advantage of increasingly popular network-intensive technologies such as artificial intelligence (AI).
The benefits of containerization and Red Hat OpenShift Virtualization
Many organizations choose containers for DevOps due to their easy scalability and portability. Because a container encapsulates an application as well as everything necessary to run that application, it’s simple to move the container from development to test and production environments, adding instances of the application by replicating the container. Containers can also be useful for microservices, data streaming, and other use cases.[3]
Containers aren’t necessarily ideal for every use case, however, and for some infrastructures, IT teams may wish to incorporate both containers and VMs. Red Hat OpenShift Virtualization, which we used in our testing, enables organizations to run both VMs and containers on the same platform by bringing VMs into containers.[4] This lets IT reap the benefits of both containers and VMs with the efficiency benefit of relying on one management tool, rather than having to maintain two distinct infrastructures.
About our testing
We explored the process of deploying a modern data center environment and migrating VMs to it from a legacy environment. We also measured the database performance the VMs achieved in both environments:
Legacy environment
- Three Dell PowerEdge R7515 servers with 3rd Generation AMD EPYC 7663 56-core processors and Broadcom Advanced Dual 25Gb Ethernet NICs
- External storage using Dell PowerStore 1200T over iSCSI
- VMware® vSphere® 8
Modern environment
- Three Dell PowerEdge R7615 servers with 4th Generation AMD EPYC 9554 64-core processors and Broadcom NetExtreme-E BCM57508 100GB NICs
- External storage using Dell PowerStore 1200T over iSCSI
- Red Hat OpenShift 4.14
Figure 1 presents a diagram of our test configuration. In addition to our test server clusters, we needed three servers to host infrastructure VMs, workload client VMs, and the OpenShift control node VMs. We configured a Dell PowerEdge R7525 to serve as the host for our infrastructure VMs for services such as AD, DHCP, and DNS, as well as HammerDB client VMs. We also configured a Dell PowerEdge R7625 to host additional HammerDB client VMs. For the OpenShift environment, we deployed a Dell PowerEdge R540 to host the OCP control nodes. We virtualized the control nodes to reduce the number of servers needed for the test bed.
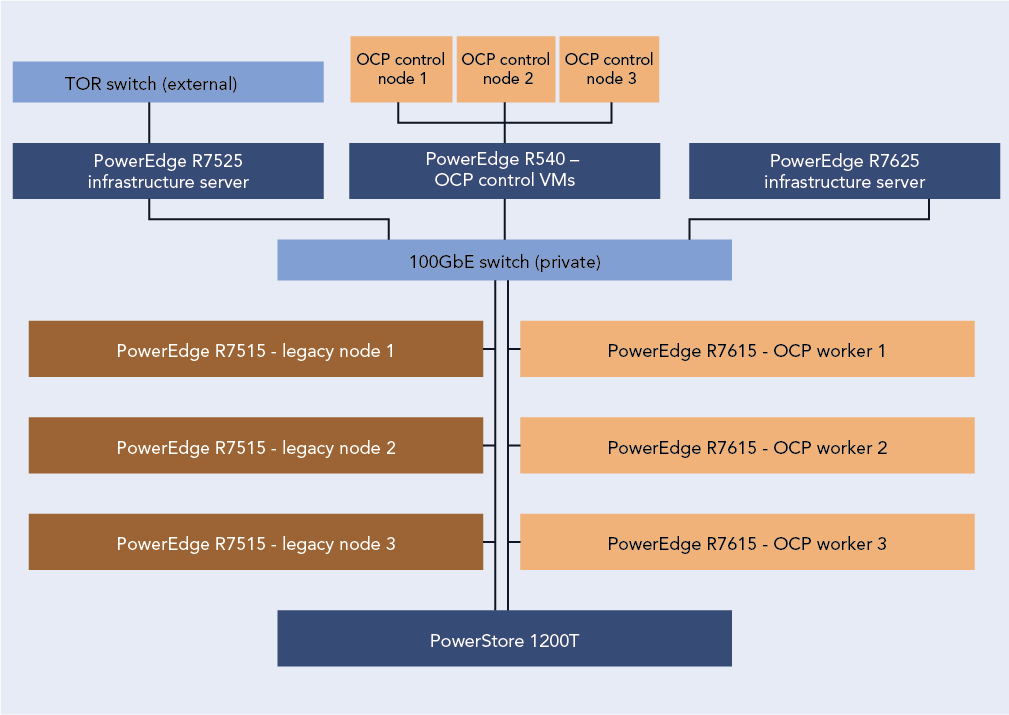
Figure 1: Our test configuration. Source: Principled Technologies.
To test the MySQL database performance of each environment, we used the TPROC-C workload from the HammerDB benchmark. HammerDB developers derived their OLTP workload from the TPC-C benchmark specifications; however, as this is not a full implementation of the official TPC-C standards, the results in this paper are not directly comparable to published TPC-C results. For more information, please visit https://www.hammerdb.com/docs/ch03s01.html.
Each VM had a single MySQL instance with a TPROC-C database. We targeted the maximum transactions per minute (TPM) each environment could achieve by increasing the user count until performance degraded.
What we learned
Finding 1: Deploying OpenShift in the modern environment was easy
For our environment, the OpenShift installation process using the Red Hat Assisted Installer to install an OpenShift Installer-Provisioned Cluster was straightforward and simple. We started by setting up the prerequisites for the environment, which included a VM for Active Directory, DNS, and DHCP. We created a domain for our private network and added the API and ingress routes as DNS A records. Next, we set up a VM as a router so that our OpenShift environment could access the internet from our private network. Finally, we created three blank VMs to serve as our OpenShift controller nodes. Once we had met the pre-requisite requirements, we logged into the Red Hat Hybrid Console and navigated to the Assisted Installer to create the cluster.
The Assisted Installer streamlined the process by walking us through configuration menus for storage, network, and access to the cluster. We started the cluster creation by assigning it a name, providing the domain, and selecting an OpenShift version. From there the installer guided us through the process of providing an installer image using the SSH public key of the server running the installer. After downloading the ISO, we booted each of the controller and worker nodes into the image and the Assisted Installer discovered each node. After discovering the controller and worker nodes, the installer walked us through the rest of the configuration process and then began the installation. The Assisted Installer made the process very simple with only six configuration tabs to advance through, and with our total install time after configuration taking around three hours. Once the installation was complete, each node rebooted into the OpenShift OS and the Assisted Installer provided us with a cluster console fully qualified domain name (FQDN) to connect to and manage the cluster from. For detailed steps on the OpenShift deployment process, see the science behind the report.
Finding 2: Migrating VMs from the legacy VMware environment to the modern OpenShift environment was easy
Migrating a VM from the VMware environment to OpenShift was also a straightforward process and quick to set up. While the actual migration time will vary depending on VM size and hardware speed, the setup consists of only a few steps and took us less than 10 minutes. We first installed the Migration Toolkit for Virtualization from the OpenShift OperatorHub. We then entered the IP address and credentials for the vCenter as a new provider. Next, we created a NetworkMap and a StorageMap to connect the respective resources between the environments. We then created a new migration plan to map the VMs to a namespace in OCP. We ran the migration plan on a single VM, and confirmed that we were able to enter the VM console once the migration was complete. For detailed steps on the process of migrating VMs from the legacy environment to the modern environment, see the science behind the report.
About 4th Gen AMD EPYC 9554 processors
According to AMD, EPYC 9554 processors deliver fast performance “for cloud, enterprise, and HPC workloads—helping accelerate your business.”[5] EPYC processors include AMD Infinity Guard, which per AMD is “a set of layered, cutting-edge security features that help you protect sensitive data and avoid the costly downtime cause by security breaches.”[6]
In addition to performance and security features, AMD claims their processors are energy-efficient, which can reduce energy costs and “minimize environmental impacts from data center operations while advancing your company’s sustainability objectives.”[7]
When comparing SPECCPU Floating Point peak rates and the default thermal design power (TDP) of the AMD EPYC 9554 and the AMD EPYC 7663, the 9554 has 54 percent better performance per watt, which demonstrates the improved power efficiency with the new 4th Gen AMD EPYC process.[8],[9]
For more information about 4th Gen AMD EPYC processors visit: https://www.amd.com/en/processors/epyc-server-cpu-family.
Finding 3: Database performance improved by 44 percent in the new environment
Figure 2 shows the results of our database performance testing using the TPROC-C workload from the HammerDB benchmark suite. The modern OpenShift cluster of Dell PowerEdge R7615 servers outperformed the legacy cluster by 44 percent. This extra capability could benefit companies upgrading to the new environment in several ways. The company could provide a better user experience, perform more work—or support more users—with a given number of servers, or reduce the number of servers necessary to execute a given workload.

Figure 2: Performance in transactions per minute using the TPROC-C workload of the HammerDB benchmark suite. Higher is better. Source: Principled Technologies.
Finding 4: Performance improved in the modern cluster, supporting consolidation, which leads to savings
Based on the results of our performance tests (see Figure 3), a company could consolidate the database workloads of a four-node Dell PowerEdge 7515 cluster with some additional headroom into three modern Dell PowerEdge R7615 servers with 4th Generation AMD EPYC processors and high-speed 100Gb Broadcom NICs.
The cluster of three modern servers delivered a total of 9,674,180 transactions per minute (3,224,726 TPMs per server). The cluster of three legacy servers delivered a total of 6,714,712 TPM (2,238,237 per server). Based on these results, four legacy servers would achieve a total of 8,952,948 TPM, which would leave 721,231 additional TPM room for growth on the modern three-node cluster.
Reducing the number of servers you need means that operational expenditures such as data center power and cooling and administrator time for maintenance also decrease, leading to ongoing savings.

Figure 3: Performance in transactions per minute that three modern servers and four legacy servers could achieve, based on our hands-on testing. Higher is better. Source: Principled Technologies.
About Dell PowerEdge R7615 servers
The Dell PowerEdge R7615 is a 2U, single-socket rack server. Dell states that it has designed this server to provide “performance and flexible, low-latency storage options in an air or Direct Liquid Cooling (DLC) configuration.”[10]
According to Dell, this server uses the AMD EPYC 4th generation processor to deliver up to 50 percent higher core count per single-socket platform in an innovative air-cooled chassis.[11] It also supports DDR5 at 4800 MT/s memory and PCIe® Gen5 with double the speed of previous Gen4 for faster access and transport of data, optimizing application output.[12] It supports up to six single-wide full-length GPUs or three double-wide full-length GPUs, to improve responsiveness or reduce app load time for power users, plus lower-latency, high-performance NVMe SSDs to help maximize compute performance.[13]
Learn more at https://www.delltechnologies.com/asset/en-us/products/servers/technicalsupport/poweredge-r7615-spec-sheet.pdf.
How high-speed 100Gb Broadcom NICs can help your organization
Even if a 25Gb NIC is sufficient to meet a company’s current networking needs, opting to equip new servers with the high-speed 100Gb Broadcom NIC can be a smart move. Future-proofing your network can allow you to meet the increasing demands of emerging technologies.
Advanced technologies such as artificial intelligence and machine learning, which can require the processing and transmission of large amounts of data, are becoming increasingly prevalent across businesses of all sizes. In a June 2023 survey of small business decision-makers, 74 percent were interested in using AI or automation in their business and 55 percent said their interest in these technologies had grown in the first half of 2023.[14] Upgrading to a modern environment with a highspeed 100Gb Broadcom NIC positions companies to take advantage of AI applications for social media, content creation, marketing, customer support, and many other use cases.
Another way that investing in the high-speed 100Gb Broadcom NIC can help your company is through improved efficiency. You might be tempted to go with a 25Gb NIC, thinking that as your networking needs increase, you can simply add more NICs of this size. However, consider a 2023 Principled Technologies study that compared the performance of a server solution with a 100Gb Broadcom 57508 NIC and a solution with four 25Gb NICs.[15] Testing revealed that the 100Gb NIC solution achieved up to 2.3 times the throughput of the solution with 25Gb NICs. It also delivered greater bandwidth consistency, which can translate to providing a better user experience; the report states that applications using the 25Gb NICs network configuration “would experience significant variation in available bandwidth, potentially causing jittery or interrupted service to multiple streams.”[16]
About the Broadcom BCM57508-P2100G Dual-Port 100GbE PCle 4.0 ethernet controller
A higher performing NIC can reduce latency, increase throughput, and allow the server to transmit and receive a great volume of data. The Dell PowerEdge R7615 we tested features the Broadcom BCM57508-P2100G DualPort 100GbE PCle 4.0 ethernet controller, which supports speeds of up to 200 Gigabits per second. Broadcom designed the BCM57508-P2100G “to build highlyscalable, feature-rich networking solutions in servers for enterprise and cloud-scale networking and storage applications, including high-performance computing, telco, machine learning, storage disaggregation, and data analytics.”[17]
The BCM57508-P2100G features BroadSAFE® technology, “to provide unparalleled platform security” and a “unique set of highly-optimized hardware acceleration engines to enhance network performance and improve server efficiency.”[18]
 BCM57508-P2100G Dual-Port 100GbE PCle 4.0 ethernet controller. Image provided by Dell.
BCM57508-P2100G Dual-Port 100GbE PCle 4.0 ethernet controller. Image provided by Dell.
Conclusion
If your organization’s transactional databases are running on gear that is several years old, you have much to gain by upgrading to modern servers with new processors and networking components and an OpenShift environment. In our testing, a modern OpenShift environment with a cluster of three Dell PowerEdge R7615 servers with 4th Generation AMD EPYC processors and high-speed 100Gb Broadcom NICs outperformed a legacy environment with MySQL VMs running on a cluster of three Dell PowerEdge R7515 servers with 3rd Generation AMD EPYC processors and 25Gb Broadcom NICs. We also easily migrated a VM from the legacy environment to the modern environment, with only a few steps required to set up and less than ten minutes of hands-on time. The performance advantage of the modern servers would allow a company to reduce the number of servers necessary to perform a given amount of database work, thus lowering operational expenditures such as power and cooling and IT staff time for maintenance. The high-speed 100Gb Broadcom NICs in this solution also give companies better network performance and networking capacity to grow as they embrace emerging technologies such as AI that put great demands on networks.
This project was commissioned by Dell Technologies.
May 2024
Principled Technologies is a registered trademark of Principled Technologies, Inc.
All other product names are the trademarks of their respective owners.
Read the report on the PT site at https://facts.pt/2V6p3FG and see the science at https://facts.pt/Dj53ZJb.
Author: Principled Technologies
[1] Forrester, “Why Faster Refresh Cycles and Modern Infrastructure Management are Critical to Business Success,” accessed May 1, 2024, www.techrepublic.com/resource-library/casestudies/forrester-why-faster-refresh-cycles-and-modern-infrastructure-management-are-critical-to-business-success/.
[2] Forrester, “Why Faster Refresh Cycles and Modern Infrastructure Management are Critical to Business Success,” accessed May 1, 2024, www.techrepublic.com/resource-library/casestudies/forrester-why-faster-refresh-cycles-and-modern-infrastructure-management-are-critical-to-business-success/.
[3] Red Hat, “Understanding containers,” accessed April 12, 2024, https://www.redhat.com/en/topics/containers.
[4] Red Hat, “Red Hat OpenShift Virtualization,” accessed April 12, 2024,
https://www.redhat.com/en/technologies/cloud-computing/openshift/virtualization.
[5] AMD, “AMD EPYC Processors,” accessed April 12, 2024, https://www.amd.com/en/processors/epyc-server-cpu-Family.
[6] AMD, “AMD EPYC Processors.”
[7] AMD, “AMD EPYC Processors.”
[8] SPEC, “SPEC CPU®2017 Floating Point Rate Result for Dell PowerEdge R6615 (AMD EPYC 9554 64-Core Processor),” accessed May 2, 2024, https://www.spec.org/cpu2017/results/res2024q1/cpu2017-20240212-41481.html.
[9] SPEC, “SPEC CPU®2017 Floating Point Rate Result for Dell PowerEdge R6515 (AMD EPYC 7663 56-Core Processor),” accessed May 2, 2024, https://www.spec.org/cpu2017/results/res2021q3/cpu2017-20210913-29288.html.
[10] Dell, “PowerEdge R7615 Specification Sheet,” accessed April 12, 2024, https://www.delltechnologies.com/asset/en-us/products/servers/technical-support/poweredge-r7615-spec-sheet.pdf.
[11] Dell, “PowerEdge R7615 Specification Sheet.”
[12] Dell, “PowerEdge R7615 Specification Sheet.”
[13] Dell, “PowerEdge R7615 Specification Sheet.”
[14] Constant Contact, “AI Stats and Trends Small Businesses Need to Know Now,” accessed April 12, 2024, https://news.constantcontact.com/small-business-now-ai-2023.
[15] Principled Technologies, “Opt for modern 100Gb Broadcom 57508 NICs in your
Dell PowerEdge R750 servers for improved networking performance,” accessed April 12, 2024,
https://www.principledtechnologies.com/Dell/PowerEdge-R750-networking-iPerf-1023.pdf.
[16] Principled Technologies, “Opt for modern 100Gb Broadcom 57508 NICs in your
Dell PowerEdge R750 servers for improved networking performance,” accessed April 12, 2024,
https://www.principledtechnologies.com/Dell/PowerEdge-R750-networking-iPerf-1023.pdf.
[17] Broadcom, “BCM57508 – 200GbE,” accessed April 12, 2024,
https://www.broadcom.com/products/ethernet-connectivity/network-adapters/bcm57508-200g-ic.
[18] Broadcom, “BCM57508 – 200GbE.”

Lab Insight: Dell CPU-Based AI PoC for Retail
Mon, 13 May 2024 20:45:53 -0000
|Read Time: 0 minutes
Introduction
As part of Dell’s ongoing efforts to help make industry-leading AI workflows available to its clients, this paper outlines a sample AI solution for the retail market. The PoC leverages DellTM technology to showcase an AI-powered inventory management application for retail organizations.
AI technology has been in development for some time, but recent technological advancements have greatly accelerated AI’s ability to provide value across a wide range of enterprise applications. AI solutions have become a key initiative for many organizations. While the advancement of AI technology provides the basis for a diverse set of AI-powered applications, the specific requirements of different verticals provide distinct hardware and software challenges. IT organizations might be unsure of the technical requirements for deploying such a solution. This uncertainty may be due to unfamiliarity with AI, as well as an expectation that AI applications will require specialized hardware, often with limited availability.
This paper covers a solution specifically designed to capture the requirements of a retail-based AI deployment using a standard AMDTM CPU for AI training and inference. The solution leverages hardware from Dell, AMD , and BroadcomTM, to create a solution powerful enough to capture and analyze large-scale video data from cameras in retail environments, as well as flexible enough to scale to the unique needs of individual retail environments. Training of the model was achieved in two days, utilizing the same Dell PowerEdge server that is used for inferencing. The scalability of the solution was tested with up to 20 video streams. The PoC additionally demonstrates AI optimizations for AMD CPUs by utilizing AMD’s ZenDNN library. The utilization of the ZenDNN library, along with node pinning, resulted in an average throughput increase of 1.5x.
While the overall applications of AI in retail environments are much broader than the single inventory management solution outlined in this paper, the PoC demonstrates a framework for how IT organizations can quickly deploy an AI solution that delivers practical value in a retail environment by using readily available hardware.
Importance for the Retail Market
As with many other industries, the retail market has become increasingly data driven. Data can provide greater insight into areas such as customer behavior and product demand, as well as assist in optimizing operational areas such as procurement and inventory management. The emergence of AI technology provides even greater opportunity for valuable data-driven insights and optimizations within the retail industry.
Possibilities for retail-focused AI solutions include both customer experience (CX)-driven solutions and operations-focused applications. CX might be enhanced with personalized recommendation systems based on customer purchase trends, or virtual assistants capable of providing product recommendations for online retail experiences. Retail operations may be optimized through solutions such as AI-enhanced surveillance to detect fraud or theft, inventory management systems, or AI-powered product pricing systems.
These examples, as well as the more in-depth PoC study outlined in this paper, are a small subset of possible AI applications that may be implemented by retail organizations. While the exact solution implementations that are most appropriate may vary between organizations based on several factors such as location, size, type of goods sold, and distribution of online versus in-person sales, it is clear that AI applications can provide immense value in retail environments.
While a proactive approach to AI adoption may be beneficial to retail organizations, unfamiliarity with AI technology and the hardware and software components needed to deploy and optimize such solutions act as a barrier to adoption. The following solution demonstrates a PoC for an AI-powered retail inventory management system that can be quickly deployed and further expanded upon by retail organizations using commonly available hardware.
Solution Overview
The retail inventory management solution addresses a common challenge in retail environments of inventory distortion. Without accurate and timely inventory management, retail organizations can be challenged with stock levels that are either too low or too high. Both situations can prove to be costly. Too much inventory requires additional storage, commitment of capital, and potential waste of perishable items. Conversely, too low of inventory can lead to customer dissatisfaction and loss of sales. In many cases, low inventory leads to customers purchasing at competitive retailers and may lead to overall loss of brand loyalty. By utilizing computer vision and object detection AI models to monitor and track inventory, retailers can achieve real-time insights into their stock to balance their inventory more appropriately and provide valuable insights back to suppliers.
To demonstrate a real-world example solution of an AI application that could be deployed to address such retail challenges, Scalers AITM, in partnership with Dell, Broadcom, and The Futurum Group, implemented a PoC solution for a retail inventory management system. The solution was designed to capture data from store cameras and use an object-detection AI model to monitor and manage product stock levels. The solution was capable of detecting products on store shelves, keeping track of inventory, and raising alerts of low or out of stock items.
All of this was accomplished using standard Dell PowerEdge servers with 32 core 4th Gen AMD EPYC processors and Broadcom networking. No GPUs were required. The CPU-based solution was further optimized with AMD’s Zen Deep Neural Network (ZenDNN) library, which provides optimizations for deep learning inferencing on AMD CPU hardware. AMD’s ZenDNN optimizations delivered an average of 1.5x increased throughput performance to the PoC. By utilizing modest, CPU-based hardware, this PoC solution demonstrates a clear example of a readily deployable and broadly applicable AI retail solution.
To achieve the solution, store shelves were configured in zones with the product names and corresponding x,y coordinate pairs that indicated the shelf location. The products, location, and the maximum capacity for each item were stored as JSON objects.
Solution Highlights
|
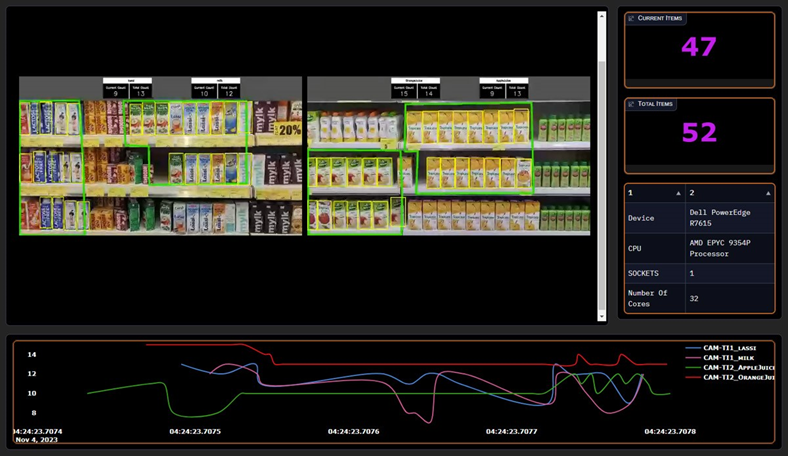
Figure 1: Visualization Dashboard.
The identification and monitoring of products in each zone is achieved by capturing video data from store cameras into a video pipeline for processing. The live video stream is captured, decoded, and then inferenced using an object-detection AI model. The video pipeline is run on a typical Dell PowerEdge server without requiring any GPUs or specialized accelerators. The video streams can additionally be directed to Dell PowerScale NAS storage for long term retention. Zenoh (Zero Overhead Network Protocol) is then utilized for distribution to an additional Dell server running a visualization process. The visualization engine enables the video stream to be shared over the web for remote viewing and analysis. The visualization dashboard can be seen in Figure 1. Figure 2 depicts a high-level diagram of the solution pipeline.
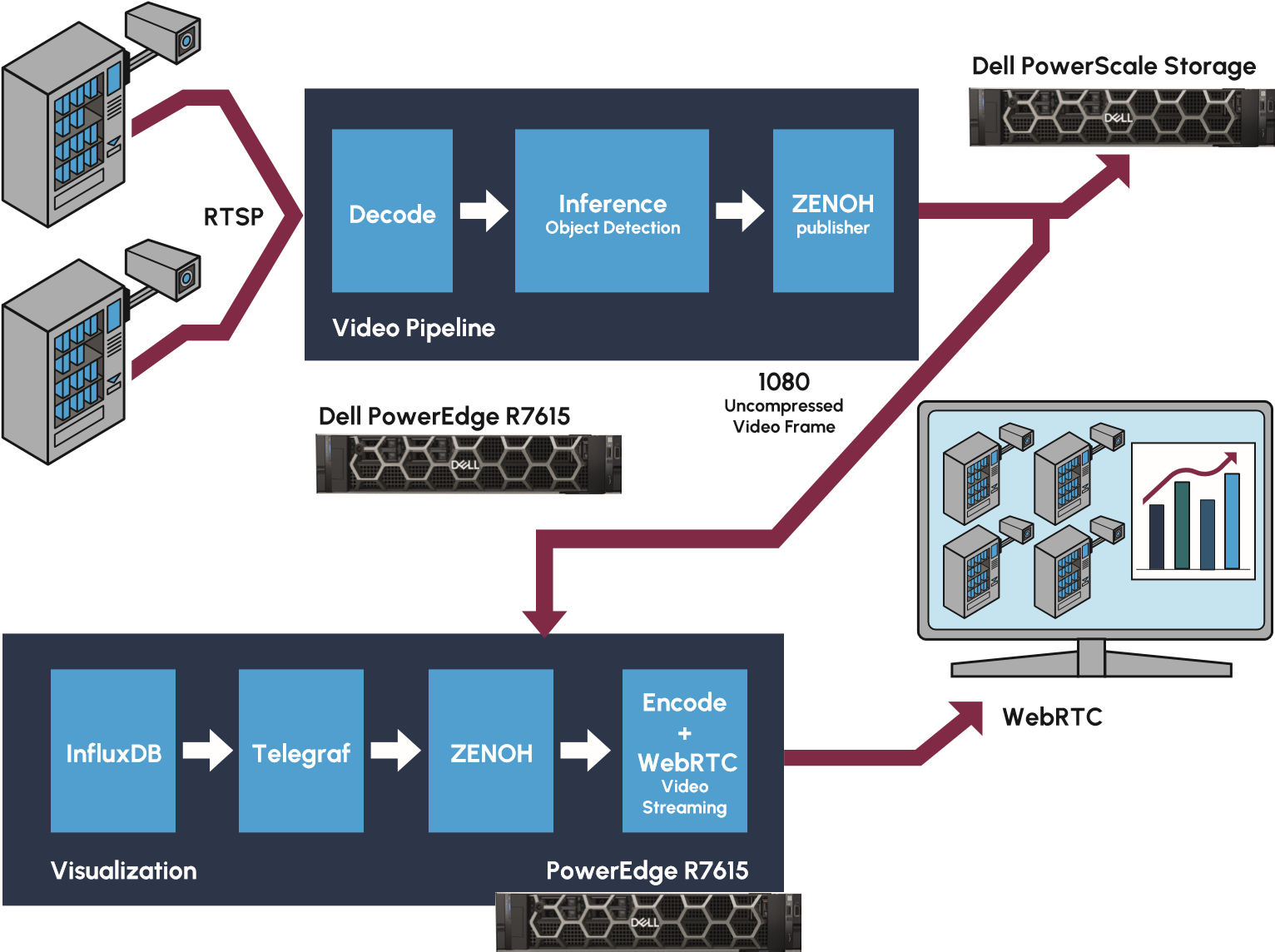
Figure 2: Retail Inventory Management AI Pipeline (Source: Scalers AI)
By separating the architecture into two distinct pieces, with one server powering video decoding and object detection, and a separate server for the visualization process, the PoC provides a framework for a highly scalable solution. Traditional approaches would combine the processes into a single pipeline, however, this architecture can prove challenging to scale due to the different computational needs of the services. Utilizing a dual service approach, provides greater flexibility to scale the processes as needed for retail organizations further expanding upon this PoC. Both the video pipeline and the visualization service can be scaled independently as requirements such as the number of video streams or application logic are adjusted. The dual service architecture and scalability of the overall solution is enabled by utilizing high speed Broadcom NetXtreme-E NICs which maintain high bandwidth between the video inferencing and visualization services.
Additional details about the implementation and performance testing of the PoC have been made available by Dell on GitHub.
The key hardware components used in the solution include the following: Dell PowerEdge R7615 Servers
|
Highlights for AI Practitioners
It is notable for AI practitioners that the project was not limited to the deployment and inferencing of the AI model. The solution additionally involved customization of the pre-trained base model using a process known as Transfer Learning. The solution began with the SSD_MobileNet_v2 model for object detection, which was an ideal model for this PoC as it provides a one-stage object detection model that does not require exceptional compute power. The model was then customized via Transfer Learning with the SKU110K image data set. The training process involved 23,000 images and resulted in a mean average precision (mAP) of 0.7. The training process was completed in approximately two days.
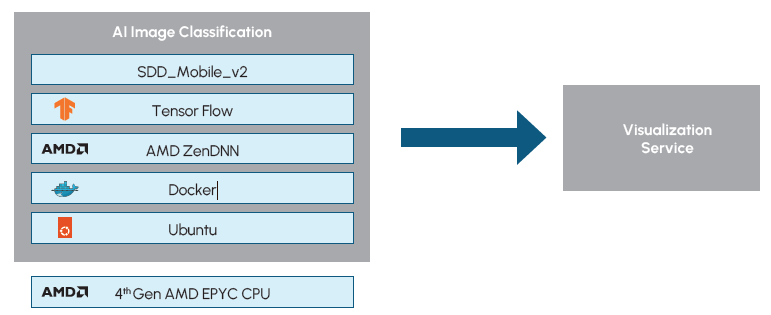
Figure 3: Object Detection Software Overview
It should also be noted that both the model training and deployment of the video pipeline solution were accomplished using the same 32 core Dell PowerEdge R7615 server. The PoC demonstrates the ability to achieve useful AI applications on CPU-based hardware that is commonly found in retail environments. The solution is further optimized for inferencing on AMD CPUs by utilizing AMD’s ZenDNN library and node pinning. The ZenDNN library provides performance tuning for deep learning inferencing on AMD CPUs while node pinning can further optimize the application by binding processes to dedicated compute resources.
The below table shows the ZenDNN parameter configurations used.
Variable | Value | Notes |
TF_ENABLE_ZENDNN_OPTS | 0 | Sets native TensorFlow code path |
ZENDNN_CONV_ALGO | 3 | Direct convolution algorithm with blocked inputs and filters |
ZENDNN_TF_CONV_ADD_FUSION_SAFE | 0 | Default Value |
ZENDNN_TENSOR_POOL_LIMIT | 512 | Set to 512 to optimize for Convolutional Neural Network |
OMP_NUM_THREADS | 32 | Sets threads to 32 to match # of cores |
GOMP_CPU_AFFINITY | 0-31 | Binds threads to physical CPUs. Set to number of cores in the system |
Figure 4: ZenDNN Configurations
Key Highlights for AI Practitioners
|
Considerations for IT Operations
The hardware used in this AI application, including Dell PowerEdge R7615 servers with 4th Gen 32 core AMD EPYC 9354P Processors, Dell PowerScale NAS, Dell PowerSwitch Z9664, and Broadcom NetXtreme-E NICs, is familiar and available to IT operations, yet each component provides valuable characteristics needed to support this type of solution.
The Dell PowerEdge servers provide powerful 4th Generation AMD EPYC processors that are capable of supporting both the AI and application workloads, and the Dell PowerScale NAS provides a high-performance, highly scalable NAS storage system capable of handling large-scale video and image data. The solution is then tied together using Broadcom Ethernet capable of supporting the high bandwidth requirements of video streaming. Most notably, these components all provide scalability for IT organizations to further build out this application with more demanding requirements such as additional video streams or additional application logic.
Futurum Group Comment: The specific use of Dell PowerEdge R7615 servers should be noted, as it demonstrates the ability to run AI workloads on standard hardware, commonly deployed in retail environments. While not considered a high-end compute server, the R7615 servers with mid-range 32 core 9354P Processors proved capable of all processes including model training, inferencing, and the separate visualization engine. This enables retail IT organizations to deploy such solutions without acquiring GPUs or requiring the datacenter level cooling needed for higher end servers. Additionally, by separating the architecture into separate video and visualization pipelines, the solution can be scaled to meet the size and performance requirements of a broad range of retail environments.
The on-premises deployment of this solution additionally enables IT operations to achieve their data security and data privacy requirements. While public cloud has been utilized for many early iterations of AI applications, data privacy becomes a concern for many organizations as they build further AI applications leveraging private data. By deploying this, or similar, retail solutions on-premises, IT operations have greater control over the privacy of their data, which may include sensitive consumer or product information. The on-premises deployment of this solution also offers a potential economic advantage in its ability to avoid cloud storage costs when storing large capacities of video data. It additionally avoids the high networking requirements of uploading many video streams to the cloud.
Specifications of the Dell PowerEdge servers used in this PoC can be found in Figure 5
PowerEdge R7615 |
| |
Device Name |
| Dell PowerEdge R7615 |
CPU | Model Name | AMD EPYC 9354P 32-Core Processor |
Number Of Cores per Socket | 32 | |
Number Of Sockets | 1 | |
Memory | Size | 768 GB |
Storage | Size | 1 TB |
Network |
| Broadcom NetXtreme-E BCM57508 |
OS | Name | Ubuntu 22.04.3 LTS |
Kernel | 5.15.0-86-generic | |
Figure 5: Dell PowerEdge Server Details
Key Highlights for IT Operations
|
Retail Solution Performance Observations
A key performance metric for the retail inventory management reference solution is the throughput of images per second as they are streamed by the in-store video cameras, decoded, and inferenced by the video pipeline. Video data is a common source for AI applications in the retail market, due to the prevalence of existing cameras deployed in stores, and the value of information that can be obtained by the video data. Because of this, the throughput performance insights gained from this PoC can translate to additional retail solutions that rely on image processing.
To examine the performance of the 32 core AMD EPYC 9354P processor for data capture and inferencing, the video pipeline was tested both with and without ZenDNN performance tuning, as well as with core pinning and node pinning. ZenDNN is a library that optimizes the performance of AMD processors for deep learning inferencing applications. The node pinning and core pinning are techniques offer optimization by binding processes to specific NUMA nodes or cores. The tests were run with up to 64 processes running on a 32 core server. The results of this testing can be seen in Figure 6.
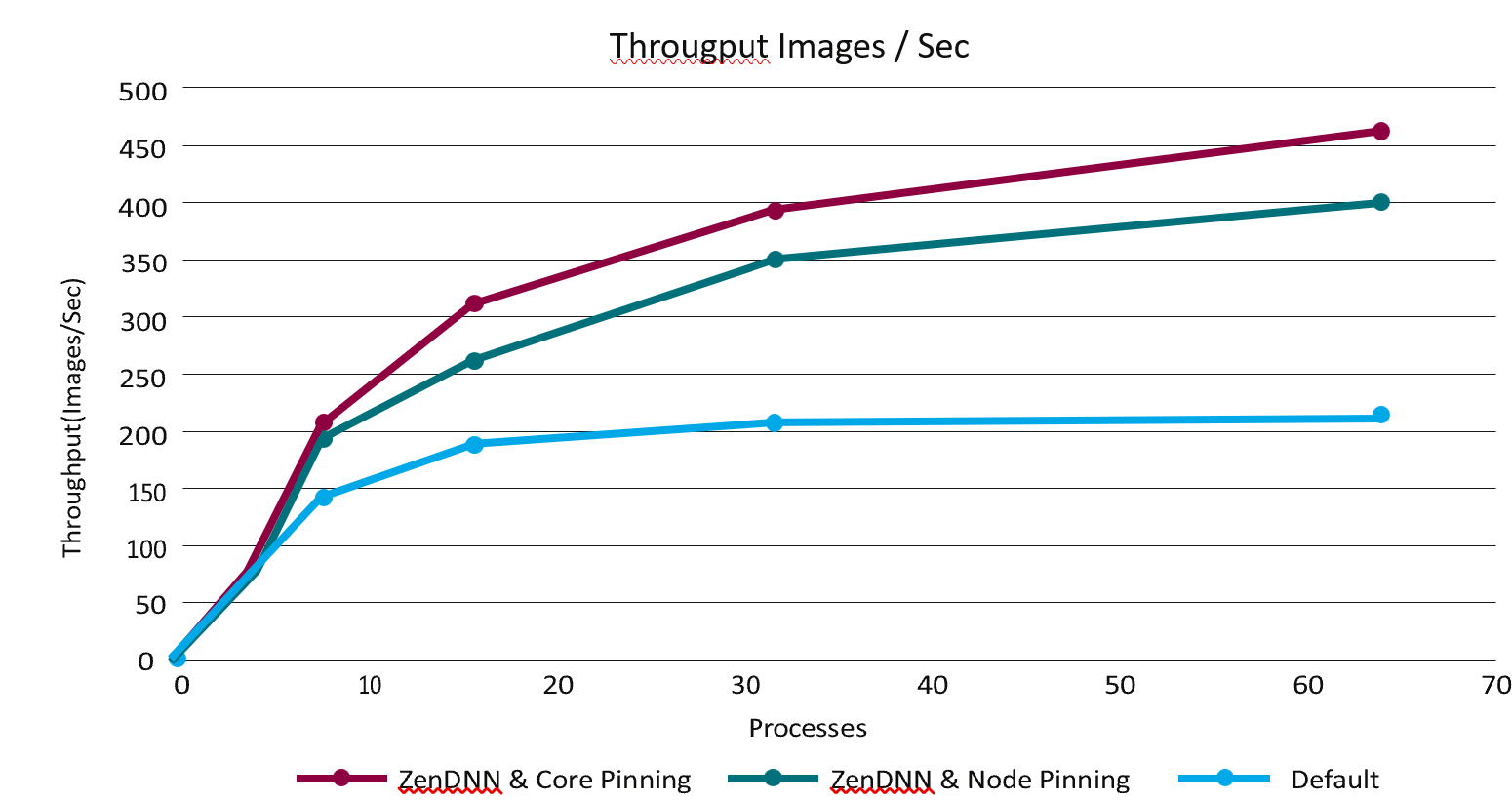 Figure 6: Throughput Performance
Figure 6: Throughput Performance
The performance results demonstrate that the use of ZenDNN with node pinning can provide a dramatic increase in throughput, with mostly lower CPU utilization. On average, ZenDNN with node pinning achieved a throughput increase of approximately 1.5x. Further throughput increases were additionally achieved by utilizing core pinning. Full results can be seen in Figure 7.
Processes | Throughput Images/sec - ZenDNN | Throughput Images/sec - ZenDNN OFF |
| |||
Core Pinning | Node pinning | CPU utilization | Default | CPU utilization | Difference ZenD- NN(Node pinning) vs Default | |
1 | 29.86 | 31.72 | 7.808695652 | 25.06 | 10.75217391 | 1.27 |
8 | 195.7 | 188.26 | 46.27717391 | 125.02 | 59.36684783 | 1.51 |
16 | 305.06 | 264.24 | 62.7548913 | 176.99 | 75.2388587 | 1.49 |
32 | 389.1 | 347.58 | 78.978125 | 204.98 | 83.00978261 | 1.7 |
64 | 460.88 | 392.32 | 93.09952446 | 214.43 | 91.55903533 | 1.83 |
Figure 7: Video Pipeline Throughput Test
The performance gains achieved with ZenDNN, core pinning, and node pinning demonstrate the ability to optimize CPUs for AI applications. Commonly, computationally demanding AI processes, such as the computer vision and object detection utilized in this PoC, are expected to require GPUs. Hardware alone, however, is not the only component that affects performance. Software such as ZenDNN plays a key role in optimizing the performance of the chosen hardware, as does configuration details such as utilizing core pinning or node pinning. By utilizing these configurations, organizations can achieve AI applications that meet their performance needs with a CPU-based solution utilizing readily available hardware.
The PoC solution was additionally tested with an increasing number of video streams to assess the bandwidth of the networked video pipeline and visualization service. 1080p video was streamed to the video pipeline where it was decoded and inferenced. It was then transmitted and received by the visualization pipeline to be encoded and shared. The number of video streams was increased incrementally between 1 and 20 which resulted in an increasing bandwidth utilization. The bandwidth scaled from an average utilization of 1.65 Gbits/s and a max utilization of 3.4 Gbits/s with 1 stream, to an average utilization of 13.9 Gbits/s and a max utilization of 27.4 Gbits/s with 20 streams. An overview of the results can be seen in Figure 8.
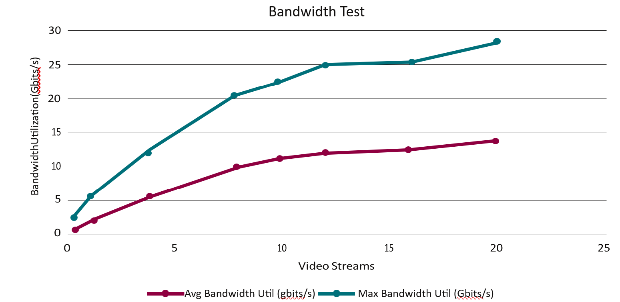
Figure 8: Inventory Management System Bandwidth
Notably, the bandwidth does not increase linearly in relation to the number of streams, allowing the solution to scale as additional streams are needed. As the number of streams increases, however, the solution does experience a decrease in frames-per-second. While frames-per-second decreases, the overall utility of the solution is not significantly impacted. Higher frame rates are of greater importance when considering video with large amounts of motion, or when viewing quality is a major priority. In this particular solution, lower frame rates are acceptable as the focus is stationary store shelves, and real time viewing is not the primary use case. Full results of testing the networked solution, including both bandwidth utilization and frames per second, can be seen in Figure 9.
Number of Streams | AVG FPS / Stream | Throughput (FPS) | Avg Bandwidth Util (Gbits/s) | Max Bandwidth Util (Gbits/s) | Avg CPU Util (%) | Avg Memory Util (GB) |
1 | 31.14 | 31.14 | 1.65 | 3.4 | 12.61 | 6.5 |
2 | 30.92 | 61.84 | 3.2 | 6.7 | 21.8 | 7.27 |
4 | 28.78 | 115.12 | 6.2 | 12.2 | 41.38 | 9.2 |
8 | 22.17 | 177.36 | 9.86 | 20.5 | 65.06 | 13.9 |
10 | 20.53 | 205.3 | 11.2 | 22.4 | 73.18 | 16.4 |
12 | 18.8 | 225.6 | 12.1 | 24.7 | 78.76 | 18.2 |
16 | 13.97 | 223.52 | 12.6 | 25.6 | 81.39 | 22.2 |
20 | 11.7 | 234 | 13.9 | 27.4 | 84.1 | 26.7 |
Figure 9: Inventory Management System Bandwidth Test
The results of this performance testing demonstrate that the bandwidth of the networked servers is capable of scaling alongside more demanding video requirements. The separation of the video pipeline and the visualization service onto distinct servers allows the architecture to independently scale the compute resources for the two services. To capitalize on this architecture however, the networking between the servers must be capable of providing adequate bandwidth between the services. To do so, the PoC solution utilizes Broadcom BCM57508 NetXtreme-E Ethernet controllers capable of supporting up to 200GbE. By utilizing a modular architecture that’s connected with scalable, high bandwidth networking, the retail inventory management PoC provides a flexible starting point for retail organizations to scale to their individual needs, including the number of video streams, FPS requirements, and additional application logic.
Final Thoughts
With the rapid development of AI technology, the retail market presents many opportunities to deploy valuable new AI-powered applications. With the broad range of value that AI can bring to retail environments, both in improving CX and optimizing store operations, retail organizations should look to be proactive in adopting the emerging technology.
As a new technology, there are many unknowns and misconceptions for those in IT who may be unfamiliar with AI deployments, complicating and delaying new AI applications. A common challenge faced by IT is the expectation that AI applications will require specialized hardware solutions that are inaccessible. The AI-powered retail inventory management solution outlined in this paper serves as a demonstration of a broadly applicable AI solution for retail that can be deployed on off-the-shelf hardware solutions. The Dell hardware solutions used in the PoC deployment were demonstrated to handle the high-bandwidth video requirements as well as the AI modeling and inferencing requirements without the use of purpose-built accelerators, GPUs, or custom hardware.
The PoC solution outlined in this paper additionally serves as a reference for retail organizations to quickly deploy their own inventory management solution. While the solution discussed in this paper is limited to a PoC, it was designed with scalability in mind for organizations to further develop and scale a solution for their needs.
The use of an AI-powered inventory management system can provide real value and cost savings to organizations by avoiding over- or under-stocking products. By using readily available hardware and reference solutions, the barrier of entry for deploying such an AI solution is dramatically lowered, allowing retail organizations to achieve quicker deployments of new AI applications and quicker time to value.
CONTRIBUTORS
Mitch Lewis
Research Analyst | The Futurum Group
PUBLISHER Daniel Newman
CEO | The Futurum Group
INQUIRIES
Contact us if you would like to discuss this report and The Futurum Group will respond promptly.
CITATIONS
This paper can be cited by accredited press and analysts, but must be cited in-context, displaying author’s name, author’s title, and “The Futurum Group.” Non-press and non-analysts must receive prior written permission by The Futurum Group for any citations.
LICENSING
This document, including any supporting materials, is owned by The Futurum Group. This publication may not be reproduced, distributed, or shared in any form without the prior written permission of The Futurum Group.
DISCLOSURES
The Futurum Group provides research, analysis, advising, and consulting to many high-tech companies, including those mentioned in this paper. No employees at the firm hold any equity positions with any companies cited in this document.
ABOUT THE FUTURUM GROUP
The Futurum Group is an independent research, analysis, and advisory firm, focused on digital innovation and market-disrupting technologies and trends. Every day our analysts, researchers, and advisors help business leaders from around the world anticipate tectonic shifts in their industries and leverage disruptive innovation to either gain or maintain a competitive advantage in their markets.