




AI Acceleration using Red Hat OpenShift with Dell PowerEdge Servers with 4th Gen Intel® Xeon® Processors
Download PDFMon, 13 May 2024 19:46:21 -0000
|Read Time: 0 minutes
Summary
Intel® Xeon® Scalable processors feature built-in accelerators for more performance-per-core and accelerated AI performance for a CPU, with advanced security technologies for the most in-demand workload requirements - all while offering cloud choice and application portability[1]. Red Hat OpenShift (RHOS)[2] provides a robust platform for running Large Language Model (LLM) inference and fine-tuning experiments. Red Hat OpenShift Container Platform (RHOCP) leverages Kubernetes containerization technology, allowing us to package the LLM model and its dependencies in a container for ease of deployment and portability. This ensures consistent and isolated execution across different environments. To demonstrate the combined benefits of both the advanced hardware and software products, including full end to end orchestration, Dell and Intel recently conducted Large Language Model (LLM) Artificial Intelligence (AI) performance testing. This document summaries the key features incorporated at a system level along with performance results for both LLM fine-tuning and inference use cases.
Solution overview
OpenShift is a family of containerization software products developed by Red Hat. Its flagship product is the OpenShift Container Platform - a hybrid cloud platform as a service built around Linux containers orchestrated and managed by Kubernetes on a foundation of Red Hat Enterprise Linux[3].
Some of the key changes incorporated into 4th generation Intel Xeon Scalable processors that we used for this test included:
- New Advanced Matrix Extension (AMX) capabilities[4]
- Improved Advanced Vector Extension (AVX) performance
- The new Intel Extension for PyTorch® open-source solution[5]
System configurations tested
To conduct the testing, we first deployed a 16th generation Dell PowerEdge R760 with Red Hat Enterprise Linux 8.8 as an “Administration node”. Next, we deployed a cluster of three 16th generation Dell PowerEdge R660s with Red Hat Enterprise Linux CoreOS 4.13.92 as the “Control Plane” nodes providing the Kubernetes services. These systems were chosen simply for hardware availability reasons to provided administration and orchestration of the OpenShift cluster. Table 1 shows the hardware configuration used; Table 2 shows the associated software configuration.
Hardware configuration
Table 1. Hardware configuration
| Admin Node | Control Plane Node |
System | Dell Inc. PowerEdge R760 | Dell Inc. PowerEdge R660 |
CPU Model | Intel Xeon Platinum 8452Y | Intel Xeon Platinum 8452Y |
Sockets | 2 | 2 |
Core per Socket | 36 | 36 |
All Core Turbo Freq | 2.8GHz | 2.8GHz |
TDP | 300W | 300W |
Memory | 1024GB (16x64GB DDR5 4800 MT/s) | 1024GB (16x64GB DDR5 4800 MT/s) |
Microcode | 0x2b0001b0 | 0x2b0001b0 |
Test Date | Tested by Intel as of 11/30/23 | Tested by Intel as of 11/30/23 |
Software configuration
Table 2. Software configuration
Component | Version |
Kernel | 5.14.0-284.18.1.el9_2.x86_64 |
OS | RHEL CoreOS 4.13.92 |
RHOCP | v1.26.5 |
Framework | PyTorch 2.1.0+cpu |
Other Software | Python: 3.9, IPEX: 2.1.0+cpu, transformers: 4.31.0 |
Workload configuration
Table 3. Workload configuration
Component | Version |
Model | Llama2-7B-hf |
Dataset | Finance-Alpaca |
Fine-tuning | 1,2 and 3-node cluster |
Inference | Single node |
Precision | Bfloat16 and INT8 |
Batch Size | 1,2,4,6, and 8 |
Inference SLA | 100ms for second token latency |
Performance results
All the figures in this section demonstrate the performance results of LLAMA-2-7B. Figure 1 shows the training (fine-tuning) efficiency of LLAMA-2-7B from 1 to 3 nodes in terms of time to train (hours) as Key Performance Indicator (KPI). Figure 2 shows the single node inference performance for both INT8 and BFloat16 datatypes accelerated via 4th Gen Xeon built-in AI Acceleration with AMX. Figure 3 shows the performance with multi-instance scenarios. Figures 4-11 show the performance sweeps across various batch sizes.
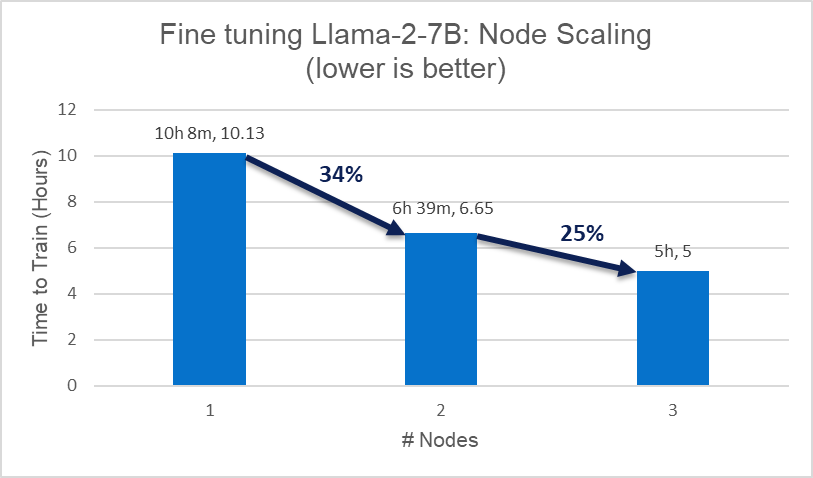
Figure 1. Fine-tuning scaling efficiency
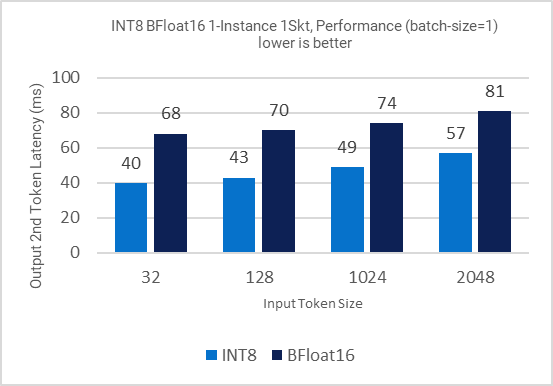
Figure 2. Inference performance for different input token sizes
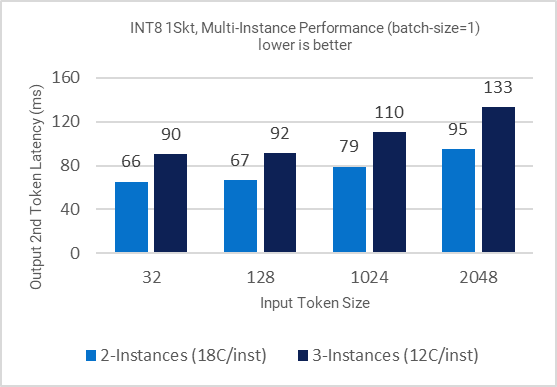
Figure 3: Multi-Instance Inference performance for different input token sizes
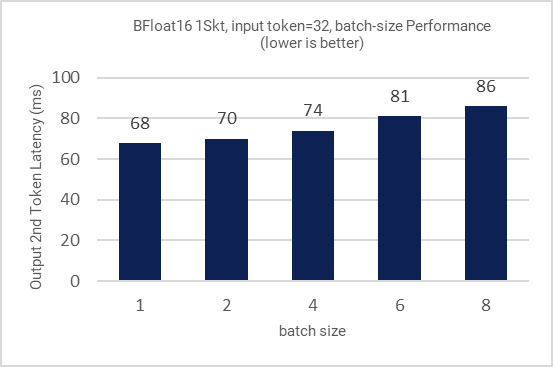
Figure 4: Inference performance for different batch sizes
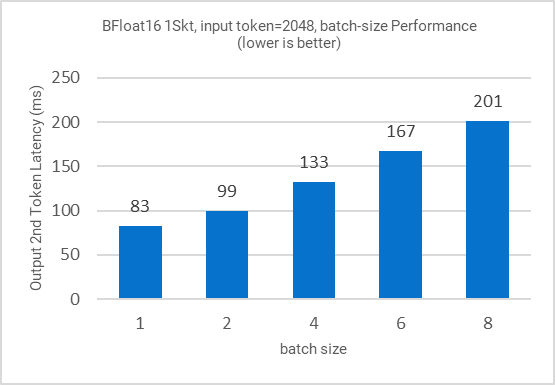
Figure 5: Inference performance for different batch sizes
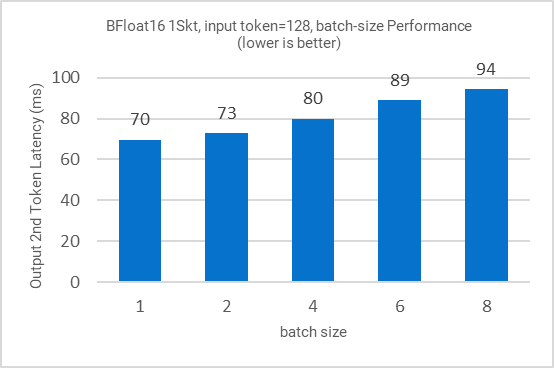
Figure 6: Inference performance for different batch sizes
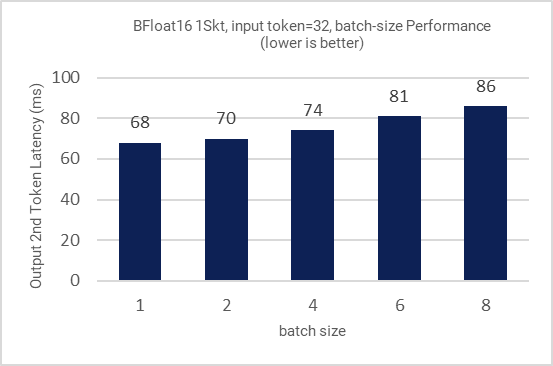
Figure 7: Inference performance for different batch sizes
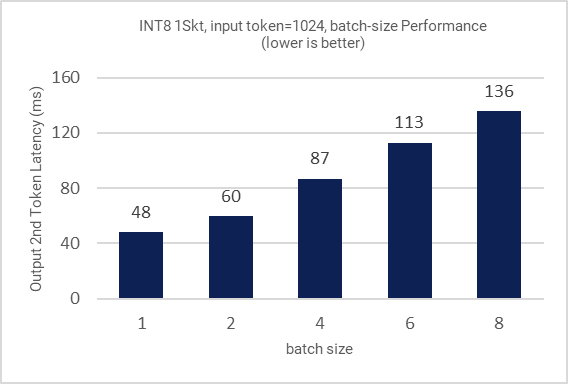
Figure 8: Inference performance for different batch sizes
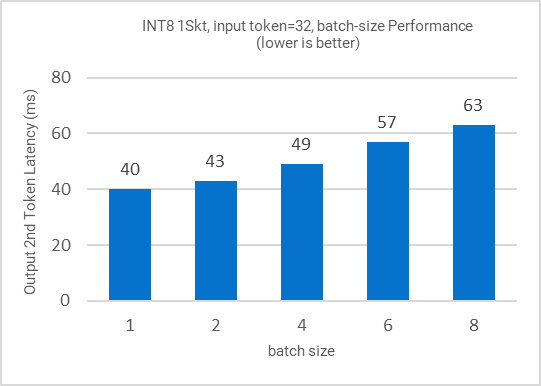
Figure 9: Inference performance for different batch sizes
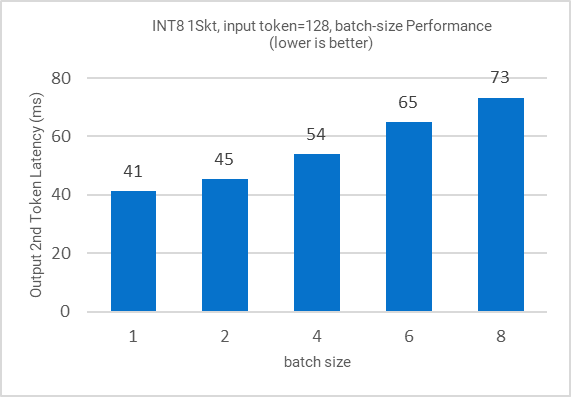
Figure 10: Inference performance for different batch sizes
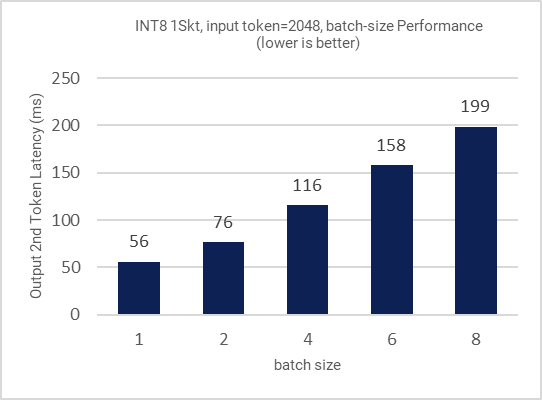
Figure 11: Inference performance for different batch sizes
Key takeaways
- Fine-tuning node scaling from 1 to 3 nodes can be easily orchestrated with Kubernetes + RHOS with 25%-35% scaling efficiency.
- Across input tokens (32, 128, 1K, 2K), INT8 1 instance/socket can deliver inference with avg. latency under 50ms.
- Across input tokens (32, 128, 1K, 2K), INT8 2 instances/socket can deliver inference with avg. latency under 100ms.
- Across input tokens (32, 128), INT8 3 instances/socket can deliver inference with avg. latency under 100ms.
- Across input tokens (32, 128, 1K, 2K), BF16 1 instance 1 socket can deliver inference with avg. latency under 100ms.
- Across input tokens (32, 128, 1K, 2K), INT8 speed up is up to 1.7x of BF16 model.
Conclusion and future work
This work demonstrated the performance effectiveness of 4th Gen Xeon on Dell PowerEdge servers for AI Large Language Model (LLM) with RHOS, the Meta LLAMA 2 Large Language Model (LLM) fine-tuning and inference. Additionally, this work demonstrates that choosing the right combination of server, processor, and software products can help provide scale out with increased performance. We would like to extend the scope of this study for larger LLMs with a variety of network topologies of varying speeds and feeds to identify optimal compute vs. communication tradeoffs for best performance.
Notices and disclaimers
Performance varies by use, configuration and other factors. Learn more at www.intel.com/PerformanceIndex.
Performance results are based on testing as of dates shown in configurations and may not reflect all publicly available updates. See backup for configuration details. No product or component can be absolutely secure.
Your costs and results may vary. Intel technologies may require enabled hardware, software or service activation.
© Intel Corporation. Intel, the Intel logo, and other Intel marks are trademarks of Intel Corporation or its subsidiaries. Other names and brands may be claimed as the property of others.
Learn more
Contact your Dell or Intel account team for a customized quote.
_____________
Related Documents

Accelerating High-Performance Computing with Dell PowerEdge XE9680: A Look at HPL Performance
Tue, 28 Mar 2023 23:05:16 -0000
|Read Time: 0 minutes
Executive Summary
The Dell PowerEdge XE9680 is a high-performance server designed and optimized to enable uncompromising performance for artificial intelligence, machine learning, and high-performance computing workloads. Dell PowerEdge is launching our innovative 8-way GPU platform with advanced features and capabilities.
- 8x NVIDIA H100 80GB 700W SXM GPUs or 8x NVIDIA A100 80GB 500W SXM GPUs
- 2x Fourth Generation Intel® Xeon® Scalable Processors
- 32x DDR5 DIMMs at 4800MT/s
- 10x PCIe Gen 5 x16 FH Slots
- 8x SAS/NVMe SSD Slots (U.2) and BOSS-N1 with NVMe RAID
This Direct from Development (DfD) tech note offers valuable performance insights for High-Performance Linpack (HPL), a widely accepted benchmark for measuring HPC system performance.
Testing
The TOP500 list frequently relies on HPL to assess and rank supercomputer performance. Utilizing the Linpack library, HPL measures FLOPS (floating-point operations per second) by creating and solving linear equations, making it a reliable benchmark for evaluating HPC system efficiency.
The Dell HPC & AI Innovation Lab used HPL to compare the performance of the PowerEdge XE9680 to our last generation PowerEdge XE8545. There are two key differentiators between the servers that affect HPL performance here: the quantity and model of GPUs supported by each platform.
Regarding GPU configuration, the PowerEdge XE9680 was equipped with 8x H100 80GB SXM GPUs, while the PowerEdge XE9680 was outfitted with 4x A100 80GB SXM GPUs.
Performance
In the HPL benchmark, the PowerEdge XE9680 equipped with NVIDIA's latest H100 80GB SXM GPU outperforms the PowerEdge XE8545 by an impressive 543% more TeraFLOPS!1

The PowerEdge XE9680, with the latest NVIDIA H100 SXM GPU, advances HPC performance. With exceptional HPL performance, the PowerEdge XE9680 sets a high benchmark for today’s and tomorrow's HPC demands. Contact your account executive or visit www.dell.com to learn more.
Table 1. Server configuration

- Testing conducted by Dell in March of 2023. Performed on PowerEdge XE9680 with 8x NVIDIA H100 SXM5-80GB and PowerEdge XE8545 with 4x NVIDIA A100-SXM-80GB. Actual results will vary.

Accelerating AI Inferencing with Dell PowerEdge XE9680: A Performance Analysis
Tue, 28 Mar 2023 23:05:16 -0000
|Read Time: 0 minutes
Executive Summary
The Dell PowerEdge XE9680 is a high-performance server designed and optimized to enable uncompromising performance for artificial intelligence, machine learning, and high-performance computing workloads. Dell PowerEdge is launching our innovative 8-way GPU platform with advanced features and capabilities.

- 8x NVIDIA H100 80GB 700W SXM GPUs or 8x NVIDIA A100 80GB 500W SXM GPUs
- 2x Fourth Generation Intel® Xeon® Scalable Processors
- 32x DDR5 DIMMs at 4800MT/s
- 10x PCIe Gen 5 x16 FH Slots
- 8x SAS/NVMe SSD Slots (U.2) and BOSS-N1 with NVMe RAID
This Direct from Development (DfD) tech note provides valuable insights on AI inferencing performance for the recently launched PowerEdge XE9680 server by Dell Technologies.
Testing
To evaluate the inferencing performance of each GPU option available on the new PowerEdge XE9680, the Dell CET AI Performance Lab, and the Dell HPC & AI Innovation Lab selected several popular AI models for benchmarking. Additionally, to provide a basis for comparison, they also ran benchmarks on our last-generation PowerEdge XE8545. The following workloads were chosen for the evaluation:
- BERT-large (Bidirectional Encoder Representations from Transformers) – Natural language processing like text classification, sentiment analysis, question answering, and language translation
- XE8545 Batch Size 512
- XE9680-A100 Batch Size 512
- XE9680-H100 Batch Size 1024
- ResNet (Residual Network) – Image recognition. Classify, object detection, and segmentation
- XE8545 Batch Size 2048
- XE9680-A100 Batch Size 2048
- XE9680-H100 Batch Size 2048
- RNNT (Recurrent Neural Network Transducer) – Speech recognition. Converts audio signal to words
- XE8545 Batch Size 2048
- XE9680-A100 Batch Size 2048
- XE9680-H100 Batch Size 2048
- RetinaNET – Object detection in images
- XE8545 Batch Size 16
- XE9680-A100 Batch Size 32
- XE9680-H100 Batch Size 16
Performance
The results are remarkable! The PowerEdge XE9680 demonstrates exceptional inferencing performance!

+300%: PowerEdge XE9680 NVIDIA A100 to H100 performance(1)
+700%: When compared to PowerEdge XE8545(2)
Comparing the NVIDIA A100 SXM configuration with the NVIDIA H100 SXM configuration on the same PowerEdge XE9680 reveals up to a 300% improvement in inferencing performance! (1)
Even more impressive is the comparison between the PowerEdge XE9680 NVIDIA H100 SXM server and the XE8545 NVIDIA A100 SXM server, which shows up to a 700% improvement in inferencing performance! (2)
Here are the results of each benchmark. In all cases, higher is better.
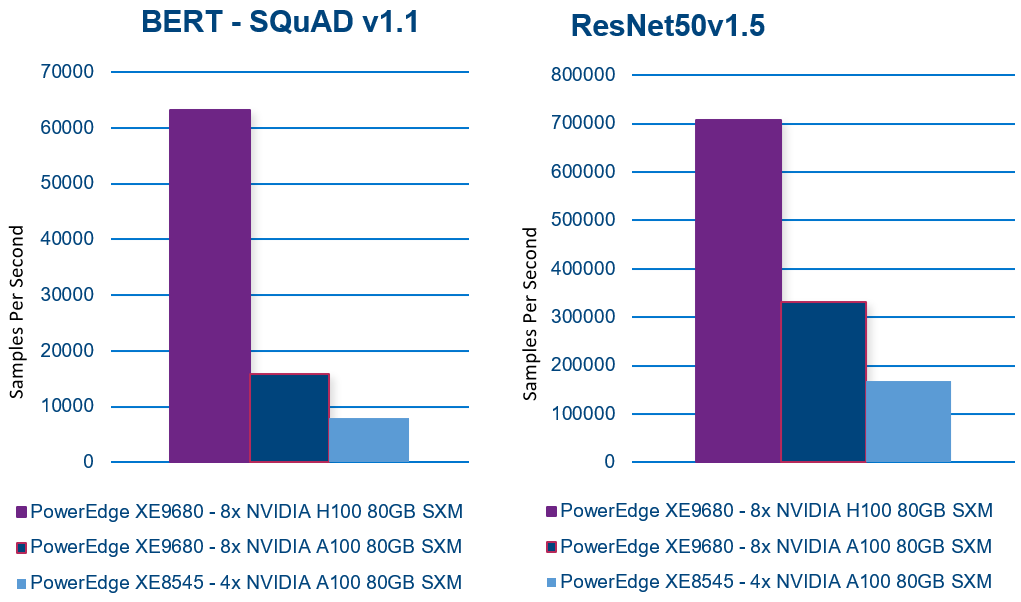
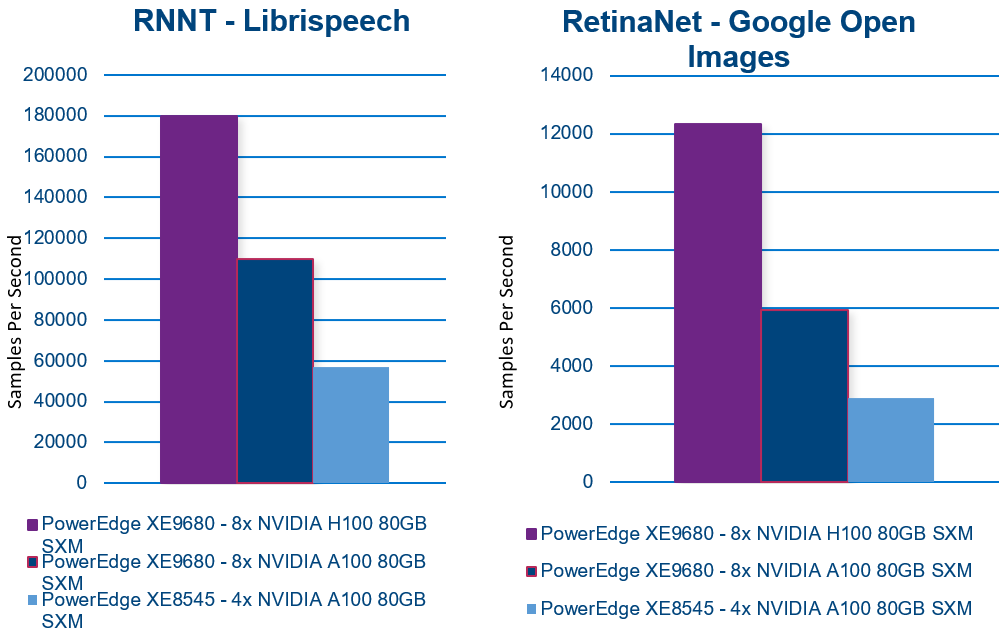
With exceptional AI inferencing performance, the PowerEdge XE9680 sets a high benchmark for today’s and tomorrow's AI demands. Its advanced features and capabilities provide a solid foundation for businesses and organizations to take advantage of AI and unlock new opportunities.
Contact your account executive or visit www.dell.com to learn more.
Table 1. Server configuration

(1) Testing conducted by Dell in March of 2023. Performed on PowerEdge XE9680 with 8x NVIDIA H100 SXM5-80GB and PowerEdge XE9680 with 8x NVIDIA A100 SXM4-80G. Actual results will vary.
(2) Testing conducted by Dell in March of 2023. Performed on PowerEdge XE9680 with 8x NVIDIA H100 SXM5-80GB and PowerEdge XE8545 with 4x NVIDIA A100-SXM-80GB. Actual results will vary.