




Spark Machine Learning on Dell HS5610 Platform with Cloudera
Download PDFMon, 29 Jan 2024 22:49:51 -0000
|Read Time: 0 minutes
Executive Summary
To establish a thorough solution collateral for the Dell PowerEdge HS5610 platform integrated with Cloudera software, we are commencing benchmarking initiatives this year. These benchmarks will form the foundational baseline for our future testing endeavors, and it's essential to emphasize that we will not be making comparisons with previous generations.
This initiative holds great significance, prompted directly by Dell's explicit request to craft this reference solution. Intel has taken charge of executing the benchmark tests and generously shared their Best-Known Methods (BKMs), providing invaluable guidance for this critical undertaking.
What are the key takeaways?
Cloudera Data Platform built on Dell’s 16G PowerEdge servers with Intel® 4th Generation Xeon processor architecture can accommodate growing enterprise data workloads and efficiently manage increasing demands for analytics and machine learning in a smaller footprint. Cloudera Data Platform delivers easier data management and scalability for data anywhere with optimal performance, scalability, and security.
As organizations create more diverse and more user-focused data products and services, there is a growing need for machine learning, which can be used to develop personalization, recommendations, and predictive insights. But as organizations amass greater volumes and greater varieties of data, data scientists are spending most of their time supporting their infrastructure instead of building the models to solve their data problems. To help solve this problem, as an integrated part of Cloudera’s platform, Spark provides a general machine learning library that is designed for simplicity, scalability, and easy integration with other tools. With the scalability, language compatibility, simple administration and compliance-ready security and governance provided through cloudera, data scientists can solve and iterate through their data problems faster.
Spark MLlib
Spark MLlib is a distributed machine learning framework built on top of Spark Core. The key benefit of MLlib is that it allows data scientists to focus on their data problems and models instead of solving the complexities surrounding distributed data. MLlib leverages the advantages of in-memory computation and is optimized for matrix and vector operations, aligning its capabilities with specific algorithmic requirements for the given use case.
K-means Overview
Clustering stands as a fundamental exploratory data analysis technique, providing valuable insights into the inherent structure of data. One prominent algorithm for this purpose is K-means, widely recognized for partitioning data points into a predefined number of clusters. This technique finds extensive applications in diverse domains including market segmentation, document clustering, image segmentation, search engines, real estate, anomaly detection and image compression, highlighting it’s versatility and importance in data analysis.
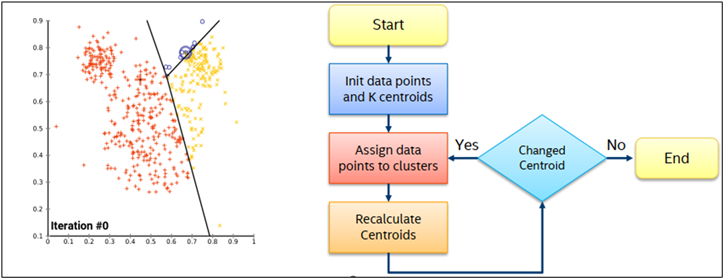
- K-Means Overview
K-means clustering performance
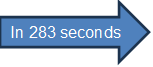
We achieved remarkable results by clustering 10 million samples with 1,000 dimensions in just 283 seconds. This accomplishment was made possible through the application of the K-Means algorithm from Spark's ML library, which was provided by Cloudera 7.1.8 and deployed on Dell PowerEdge HS5610 platform.
We conducted a performance evaluation of Spark's MLlib K-Means algorithm using the HiBench Benchmark.
For detailed information on our benchmarking process, you can refer to Intel GitHub repository: https://github.com/Intel-bigdata/HiBench
Note - This result is not compared against any other platform hardware or software. We will use this as baseline for future products.

Configuration Details
Workload Configuration | |
Platform | Dell PowerEdge HS5610 |
CPU | 6448Y |
Memory | 512 GB (16 x 32GB DDR5-4800) |
Boot Device | Dell EMC™ Boot Optimized Server Storage (BOSS-N1) with 2 x 480 GB M.2 NVMe SSDs (RAID1) |
HDFS Data Disk | 2 x Dell Ent NVMe P5500 RI U.2 3.84TB |
HDFS Namenode Disk | 1 x Dell Ent NVMe P5500 RI U.2 3.84TB |
Yarn Cache Disk | 1 x Dell Ent NVMe P5500 RI U.2 3.84TB |
Network Interface Controller | NetXtreme BCM5720 Gigabit Ethernet PCIe |
Cluster size | 1 |
Cloudera Distribution | Cloudera Data Platform 7.1.8 |
Compute Engine | Spark 3.2.0 |
Workload | Hibench 7.1.1 – Kmeans Algorithm |
Iterations and result choice | 3 iterations, average |
Spark Configuration | |
spark.deploy.mode | yarn |
Executor Numbers | 16 |
Executor cores | 8 |
spark.executor.memory | 24g |
spark.executor.memoryOverhead | 4g |
spark.driver.memory | 20g |
spark default parallelism | 128 |
spark.driver.maxResultSize | 20g |
spark.serializer | org.apache.spark.serializer.KryoSerializer |
spark.kryoserializer.buffer.max | 1g |
spark.network.timeout | 1200s |
K-means Configuration | |
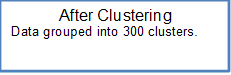
Number of clusters | 5 |
Dimensions | 1,000 |
Number of Samples | 10,000,000 |
Samples per inputfile | 10,000 |
Number of Iterations | 40 |
k | 300 |