




Optimizing Throughput in Large Language Models and Understanding Token Dynamics
Mon, 09 Sep 2024 16:19:52 -0000
|Read Time: 0 minutes
Ever wonder why chatbots respond at different rates? Or what happens behind the scenes when you prompt a question and get exactly what you need from a chatbot? The efficiency and speed of AI-powered interactions significantly influence user satisfaction, the secret to which lies in understanding and optimizing throughput in large language models (LLMs).
As the demand for seamless real-time interactions grows, so too does the need to efficiently manage the tokens that make up every conversation. From the initial user prompt to the final output, every token counts. This blog will explore the importance of understanding throughput and how to properly manage tokens by diving into the dynamics of:
- Throughput and Tokens
- Token Management
- Context Windows
Defining throughput and tokens
Throughput refers to a machine learning model’s ability to process or generate a certain number of tokens per second. A token can be thought of as a piece of a sentence, such as a word or a part of a word and is the basic unit of processing for these models.
Throughput is a critical performance metric for these models, as it directly impacts the speed at which the model can process and generate responses. Higher throughput means the model can process more tokens in less time, leading to faster results.
For example, in a customer service chatbot powered by an LLM, throughput determines how quickly the chatbot can analyze customer queries and generate relevant responses. A higher throughput means the chatbot can handle more words per second, leading to faster and more fluid conversations with users. If an LLM has a throughput of 1,000 tokens per second, it can effectively process or generate the equivalent of approximately 200 typical English sentences in just one minute, significantly enhancing the efficiency of applications like automated content creation or real-time translation services.
Tokens are not limited to text. They can also be broken down into video, audio, and image segments based on the implementation and usage of the machine learning model. The concept of a token is fundamental to how these models learn from data. By breaking down complex data into smaller, more manageable pieces (tokens), the model can learn and make predictions based off patterns.
Note that the number of tokens a model can handle at once is often limited by the model’s architecture and available computational resources, such as computational memory. This is why managing and optimizing token throughput is a key consideration when working with LLMs.
Addressing a misconception with throughput
A common misconception about throughput is that it is only considered in the context of the output rate of an LLM. In reality, it is the combination of input and output tokens that make up a model’s overall throughput. Here is a further breakdown of this concept:
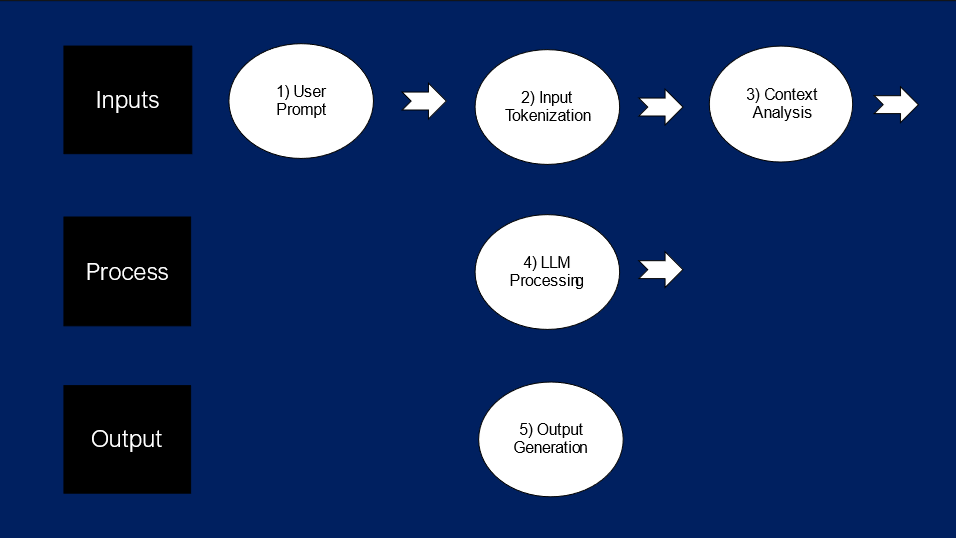
1) User Prompt
- Description: The user prompt can vary significantly in complexity and size. It may include plain text but can also involve complex data structures like images or extensive text documents. This length and variability affect the number of tokens the model must process.
- Token Usage: Larger or more complex prompts require more tokens to accurately parse and understand the input, potentially consuming a significant portion of the model's token capacity.
2) Input Tokenization
- Description: This stage converts the user's input into a format that the model can process (tokens). The process involves breaking down the input into manageable pieces for the LLM to properly parse through the inputs being fed into the model.
- Token Usage: Depends on the input length and complexity. Longer or more complex inputs naturally lead to higher token counts.
3) Context Analysis
- Description: Context analysis involves the model using its understanding from previous interactions or predefined knowledge to interpret the current prompt. This is crucial for maintaining continuity in conversations and for understanding complex queries.
- Token Usage: Depends on how much information the model needs to recall or relate to extensive prior conversations or data.
4) LLM Processing
- Description: In this core processing phase, the model processes all the accumulated tokens, considering both the new input and the relevant context, to generate a suitable output.
- Token Allocation: The model must efficiently manage its token usage to balance between understanding the input and generating a detailed and accurate output.
5) Output Generation
- Description: Here, the model formulates its response based on the processed information. The complexity of the output often mirrors the input and the required detail level.
- Token Usage: Generating detailed and contextually rich responses requires a significant number of tokens, especially for complex queries or extensive data output needs.
The tokenization process involves converting the user's input into manageable tokens that the LLM can process, which is critical as both input and output tokens significantly influence the model's throughput and overall performance. Let’s now apply the tokenization process to a real-world scenario.

Applying the tokenization process to a real-world scenario
Scenario: Telecommunications Company Customer Service Chatbot
Context Window: 500 tokens
The context window represents the total token budget per user interaction, defining the maximum number of tokens an LLM can process in a single interaction. This includes tokens allocated for both input and output. Properly managing this token budget is essential to ensure each stage of the process from understanding the user's prompt to generating a relevant response operates smoothly.
As interactions become more complex, either by requiring more context or by generating more detailed outputs, the required number of tokens increases. This necessitates careful computational scaling to maintain performance. Efficient token allocation within the context window is crucial for optimizing throughput and ensuring the model can effectively handle detailed and context-rich interactions.
Here is a scenario that exemplifies the tokenization process by breaking each step down into something more digestible:
1) User Prompt
- Scenario: A customer asks about their billing cycle and ways to reduce their monthly charges.
- Token Usage: This initial prompt might use up to 20 tokens, depending on complexity and length of the query.
- Example: "Can you explain my billing cycle and suggest ways I could reduce my monthly charges?"
- Implementation: The model first receives the raw input (user prompt) and allocates tokens to understand and break down the customer's question fully.
2) Input Tokenization
- Scenario: The prompt is converted into a structured format that the model can understand.
- Token Usage: Assuming detailed customer queries, around 100 tokens are allocated for tokenizing the full extent of the question.
- Implementation: The tokenizer processes the input text into tokens, focusing on keywords like 'billing cycle' and 'reduce monthly charges'.
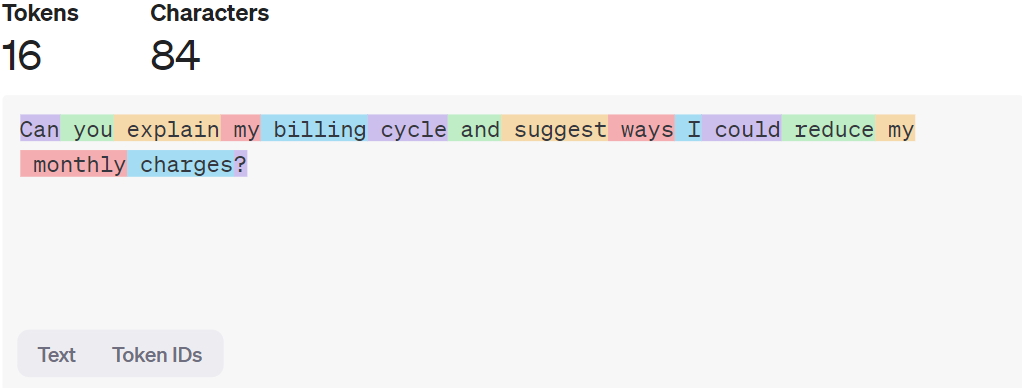
Figure 1. OpenAI Tokenizer Platform – text is broken into tokens with random colors for visual distinction
Figure 1 illustrates how the tokens are broken down within the text on ChatGPT-3.5. Since all the words in the example input have either one or two syllables, each word can be parsed as a single token. That said, with larger words, the word is usually broken down into two or three tokens.
Try the word “treacherous” on the OpenAI Tokenizer Platform, and check out the number of tokens allocated to it. Now, let’s move onto the next step.
3) Context Analysis
- Scenario: The system accesses the customer’s past interaction history and billing details to provide a personalized response.
- Token Usage: 100 tokens are dedicated to retrieving and understanding relevant customer history and previous interactions.
- Implementation: Tokens are used to pull up historical data and contextual information to ensure the response is accurate and tailored to the customer’s specific situation.
- Example: The system might retrieve past interactions where the customer inquired about billing issues or requested changes to their plan. This could include past questions like "What are my billing dates?" and "How can I lower my bill?"
4) LLM Processing
- Scenario: The model integrates the tokenized input with the contextual data to formulate an appropriate answer.
- Token Usage: 150 tokens are reserved for processing and integrating the input with the context, aggregating all the inputs into one centralized process.
- Implementation: This step involves synthesizing the data into a coherent output plan and deciding on the best way to explain the billing cycle and potential savings to the user.
5) Output Generation
- Scenario: The chatbot generates a clear, comprehensive response explaining the billing cycle and offering tips to reduce costs.
- Token Usage: The remaining 130 tokens are used to generate a detailed and helpful response.
- Implementation: The chatbot crafts a response that explains the billing details and provides customized advice based on the customer’s usage patterns.
Example Output: "Your billing cycle starts on the 15th of each month and ends on the 14th of the following month. To reduce your monthly charges, consider the following tips:
- Opt-in for electronic billing to save on paper statement fees.
- Review your plan to ensure it matches your usage needs. You may benefit from a lower-tier plan based on your average monthly usage.
- Utilize any available discounts or promotions by checking our latest offers on the website."
This interaction between the chatbot and the user takes less than a second! The process from the user asking a question to the chatbot responding is super intricate, and that’s why it’s super important to understand where your computational power is allocated throughout the process.
Key-Takeaways
 Optimize Token Allocation: Efficiently distribute tokens across user prompt, tokenization, context analysis, LLM processing, and output generation to maintain high performance for each specific use case
Optimize Token Allocation: Efficiently distribute tokens across user prompt, tokenization, context analysis, LLM processing, and output generation to maintain high performance for each specific use case
 Manage Context Window: Understand and utilize the context window to handle complex interactions without exceeding the token budget
Manage Context Window: Understand and utilize the context window to handle complex interactions without exceeding the token budget
 Balance Input and Output: Ensure a balanced allocation of tokens, limited by the context window, between understanding input and generating detailed responses
Balance Input and Output: Ensure a balanced allocation of tokens, limited by the context window, between understanding input and generating detailed responses
Author: Jaydeep Golla