




Expanding GPU Choice with Intel Data Center GPU Max Series
Fri, 12 Jan 2024 18:03:05 -0000
|Read Time: 0 minutes
This is part two, read part one here: https://infohub.delltechnologies.com/p/llama-2-on-dell-poweredge-xe9640-with-intel-data-center-gpu-max-1550/
 |  |  |  |
 |  |  |
| MORE CHOICE IN THE GPU MARKET
We are delighted to showcase our collaboration with Intel® to introduce expanded options within the GPU market with the Intel® Data Center GPU Max Series, now accessible via Dell™ PowerEdge™ XE9640 & 760xa. The Intel® Data Center GPU Max Series is Intel® highest performing GPU, with more than 100 billion transistors, up to 128 Xe cores, and up to 128 GB of high bandwidth memory. Intel® Data Center GPU Max Series pairs seamlessly with both Dell™ PowerEdge™ XE9640, the first liquid-cooled 4-way GPU platform in a 2U server from Dell™, and Dell™ PowerEdge™ 760xa, offering a wide range of choice and scalability in performance.
Dell™ recently announced partnerships with both Meta and Hugging Face to enable seamless support for enterprises to select, deploy, and fine-tune AI models for industry specific use cases, anchored by Llama-2 from Meta. We paired Dell™ PowerEdge™ XE9640 & 760xa with the Intel® Data Center GPU Max Series and tested the performance of the Llama-2 7B Chat model by measuring both the rate of token generation and the number of concurrent users that can be supported while scaling up to four GPUs.
Dell™ PowerEdge™ Servers and Intel® Data Center GPU Max Series showcased a strong scalability and met target end user latency goals.
“Scalers AI™ ran Llama-2 7B Chat with Dell™ PowerEdge™Servers, powered by the Intel® Data Center GPU Max Series with optimizations from Intel® that enabled us to meet the end user latency requirements for our enterprise AI chatbot”
 Chetan Gadgil, CTO at Scalers AI
Chetan Gadgil, CTO at Scalers AI
| LLAMA-2 7B CHAT MODEL
Large Language Models (LLMs), such as OpenAI GPT-4 and Google PaLM, are powerful deep learning architectures that have been pre-trained on large datasets and can perform a variety of natural language processing (NLP) tasks including text classification, translation, and text generation. In this demonstration, we have chosen to test Llama-2 7B Chat because it is an open source model that can be leveraged for various commercial use cases.
For inference testing in LLMs such as Llama-2 7B Chat, powerful GPUs such as the Intel® Data Center GPU Max Series are incredibly useful due to their parallel processing architecture which can support massive parameter sets and efficiently handle expanding datasets.
| PART II
In part I of our blog series on Intel® Data Center GPU Max Series, we put Intel® Data Center GPU Max 1550 to the test by running Llama-2 7B Chat and optimizing using Hugging Face Optimum with an Intel® OpenVINO™ backend in an FP32 format.
In part II of our blog series, we will focus on both the Intel® Data Center GPU Max 1550 and 1100 and leverage the lower precision INT8 format for enhanced performance using Intel® OpenVINO™. We will also use a new toolkit, Intel® BigDL, through which we will be able to run Llama-2 7B Chat on Intel® Data Center Max GPUs in the INT4 format.
| ARCHITECTURES
We initialized our testing environment with Dell™ PowerEdge™ XE9640 Server with four Intel® Data Center GPUs Max 1550 running on Ubuntu 22.04. We paired the Intel® Data Center Max GPUs 1100 with Dell™ PowerEdge™ 760xa Rack Server.
To ensure maximum efficiency, we used Hugging Face Optimum, an extension of Hugging Face Transformers that provides a set of performance optimization tools to train and run models on targeted hardware. For the Intel® Data Center Max GPU, we selected the Optimum-Intel package, which integrates libraries provided by Intel® to accelerate end-to-end pipelines on Intel® hardware. Optimum-Intel allows you to optimize your model to the Intel® OpenVINO™ IR format and attain enhanced performance using the Intel® OpenVINO™ runtime.
We also tested bigdl-llm, a library for running LLMs on Intel® hardware with support for Pytorch and lower precision formats. By using bigdl-llm, we are able to leverage INT4 precision on Llama-2 7B Chat.
The following architectures depict both scenarios:
1) Hugging Face Optimum
2) bigdl-llm
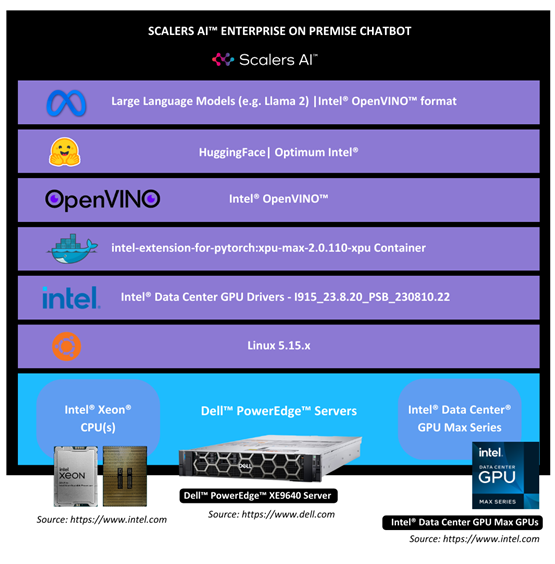

| SYSTEM SET-UP SETUP
1. Installation of Drivers
To install drivers for the Intel® Data Center GPU Max Series, we followed the steps here.
2. Verification of Installation
To verify the installation of the drivers, we followed the steps here.
3. Installation of Docker
To install Docker on Ubuntu 22.04.3, we followed the steps here.
| RUNNING THE LLAMA-2 7B CHAT MODEL WITH OPTIMUM-INTEL
4. Set up a Docker container for all our dependencies to ensure seamless deployment and straightforward replication:
sudo docker run --rm -it --privileged --device=/dev/dri --ipc=host intel/intel-extension-for-pytorch:xpu-max-2.0.110-xpu bash
5. To install the Python dependencies, our Llama-2 7B Chat model requires:
pip install openvino==2023.2.0
pip install transformers==4.33.1
pip install optimum-intel==1.11.0
pip install onnx==1.15.0
6. Access the Llama-2 7B Chat model through HuggingFace:
huggingface-cli login
7. Convert the Llama-2 7B Chat HuggingFace model into Intel® OpenVINO™ IR with INT8 precision format using Intel® Optimum to export it:
from optimum.intel import OVModelForCausalLM
from transformers import AutoTokenizer
model_id = "meta-llama/Llama-2-7b-chat-hf"
tokenizer = AutoTokenizer.from_pretrained(model_id)
model = OVModelForCausalLM.from_pretrained(model_id, export=True, load_in_8bit=True)
model.save_pretrained("llama-2-7b-chat-ov")
tokenizer.save_pretrained("llama-2-7b-chat-ov")
8. Run the code snippet below to generate the text with the Llama-2 7B Chat model:
import time
from optimum.intel import OVModelForCausalLM
from transformers import AutoTokenizer, pipeline
model_name = "llama-2-7b-chat-ov"
input_text = "What are the key features of Intel's data center GPUs?"
max_new_tokens = 100
# Initialize and load tokenizer, model
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = OVModelForCausalLM.from_pretrained(model_name, ov_config= {"INFERENCE_PRECISION_HINT":"f32"}, compile=False)
model.to("GPU")
model.compile()
# Initialize HF pipeline
text_generator = pipeline( "text-generation", model=model, tokenizer=tokenizer, return_tensors=True, )
# Inference
start_time = time.time()
output = text_generator( input_text, max_new_tokens=max_new_tokens ) _ = tokenizer.decode(output[0]["generated_token_ids"])
end_time = time.time()
# Calculate number of tokens generated
num_tokens = len(output[0]["generated_token_ids"])
inference_time = end_time - start_time
token_per_sec = num_tokens / inference_time
print(f"Inference time: {inference_time} sec")
print(f"Token per sec: {token_per_sec}")
| RUNNING THE LLAMA-2 7B CHAT MODEL WITH BIGDL-LLM
1. Set up a Docker container for all our dependencies to ensure seamless deployment and straightforward replication:
sudo docker run --rm -it --privileged -u 0:0 --device=/dev/dri --ipc=host intelanalytics/bigdl-llm-xpu:2.5.0-SNAPSHOT bash
2. Access the Llama-2 7B Chat model through HuggingFace:
huggingface-cli login
3. Run the code snippet below to generate the text with the Llama-2 7B Chat model in INT4 precision:
import torch
import intel_extension_for_pytorch as ipex
import time
import argparse
from bigdl.llm.transformers import AutoModelForCausalLM
from transformers import LlamaTokenizer
model = AutoModelForCausalLM.from_pretrained("meta-llama/Llama-2-7b-chat-hf",
load_in_4bit=True,
optimize_model=True,
trust_remote_code=True,
use_cache=True)
model = model.to('xpu')
tokenizer = LlamaTokenizer.from_pretrained("meta-llama/Llama-2-7b-chat-hf", trust_remote_code=True)
with torch.inference_mode():
input_ids = tokenizer.encode("What are the key features of Intel's data center GPUs?", return_tensors="pt").to(self.device)
# ipex model needs a warmup, then inference time can be accurate
output = model.generate(input_ids,
temperature=0.1,
max_new_tokens=100)
# start inference
start_time = time.time()
output = model.generate(input_ids, max_new_tokens=100)
end_time = time.time()
num_tokens = len(output[0].detach().numpy().flatten())
inference_time = end_time - start_time
token_per_sec = num_tokens / inference_time
print(f"Inference time: {inference_time} sec")
print(f"Token per sec: {token_per_sec}")
| ENTER PROMPT
What are the key features of Intel® Data Center GPUs?
Output for Llama-2 OpenVINO INT8
Intel® Data Center GPUs are designed to provide high levels of performance and power efficiency for a wide range of applications, including machine learning, artificial intelligence, and high-performance computing. Some of the key features of Intel's data center GPUs include:
1. Many Cores: Intel's data center GPUs are designed with many cores, which allows them to handle large workloads and perform complex tasks quickly and efficiently.
2. High Memory Band
Output for Llama-2 BigDL INT4
Intel's data center GPUs are designed to provide high levels of performance, power efficiency, and scalability for demanding workloads such as artificial intelligence, machine learning, and high-performance computing. Some of the key features of Intel's data center GPUs include:
1. Architecture: Intel's data center GPUs are based on the company's own architecture, which is optimized for high-per
| PERFORMANCE RESULTS & ANALYSIS
Llama-2 Intel® OpenVINO™ INT8 (Hugging Face Backend Intel® OpenVINO™)
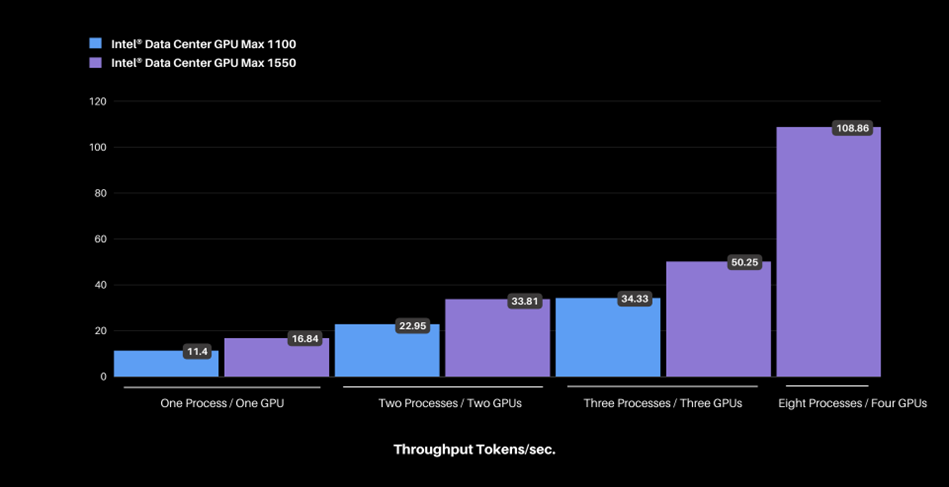 Figure: Scaling Intel® Data Center GPU Max 1100 & 1550 and increasing concurrent processes measured in total throughput in tokens per second.
Figure: Scaling Intel® Data Center GPU Max 1100 & 1550 and increasing concurrent processes measured in total throughput in tokens per second.
Using a machine with a single GPU and a single process, we achieved a throughput of ~11 tokens per second on the Intel® Data Center GPU Max 1100, which increased to ~109 tokens per second when scaling up to four Intel® Data Center Max GPUs 1550 and eight processes. The latency per process remains well below the Scalers AI™ target of 100 milliseconds despite an increase in the number of concurrent processes.
Llama-2 BigDL INT4 on Intel® Data Center GPU Max 1100
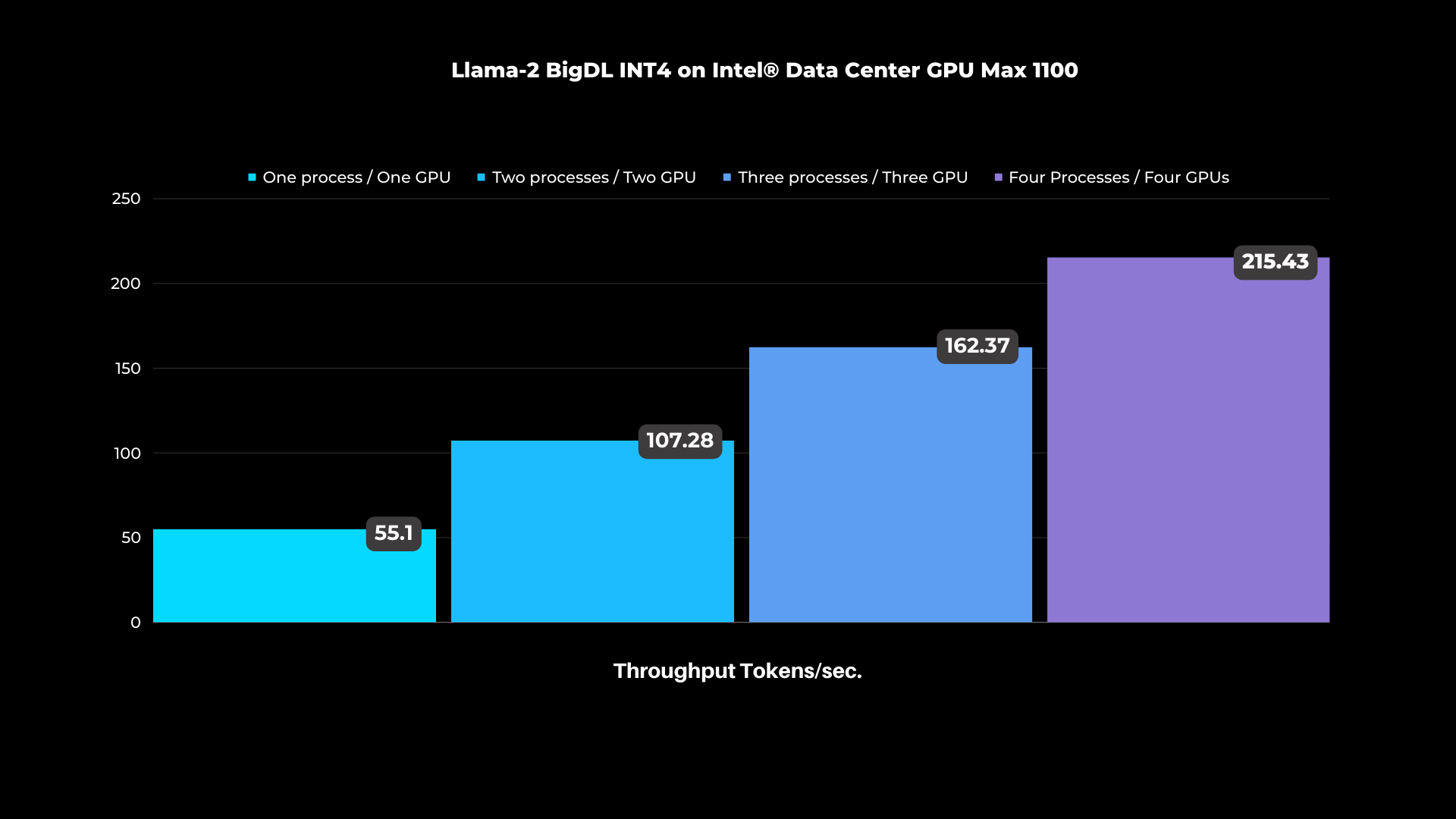
Figure: Scaling Intel® Data Center Max GPUs from one to four GPUs and increasing concurrent processes measured in total throughput in tokens per second.
Using a machine with a single GPU and a single process, we achieved a throughput of ~55 tokens per second on the Intel® Data Center GPU Max 1100, which increased to ~215 tokens per second when scaling up to four Intel® data Center GPUs Max 1100 and four processes.
Our results demonstrate that Dell™ PowerEdge™ Servers with Intel® Data Center GPU Max Series are up to the task of running Llama-2 7B Chat and meeting end user experience targets.
*Performance varies by use case, model, application, hardware & software configurations, the quality of the resolution of the input data, and other factors. This performance testing is intended for informational purposes and not intended to be a guarantee of actual performance of an AI application.
| ABOUT SCALERS AI™
Scalers AI™ specializes in creating end-to-end artificial intelligence (AI) solutions to fast track industry transformation across a wide range of industries, including retail, smart cities, manufacturing, insurance, finance, legal and healthcare. Scalers AI™ industry offerings include custom large language models and multimodal platforms supporting voice, image, and text. As a full stack AI solutions company with solutions ranging from the cloud to the edge, our customers often need versatile common off the shelf (COTS) hardware that works well across a range of workloads.
| Dell™ PowerEdge™ XE9640 & 760xa Servers Key Specifications
MACHINE | Dell™ PowerEdge™ XE9640 Server |
Operating system | Ubuntu 22.04.3 LTS |
CPU | Intel® Xeon® Platinum 8468 |
MEMORY | 512Gi |
GPU | Intel® Data Center GPU Max 1550 |
GPU COUNT | 4 |
MACHINE | Dell™ PowerEdge™ 760xa Server |
Operating system | Ubuntu 22.04.3 LTS |
CPU | Intel® Xeon® Platinum 8480+ |
MEMORY | 1024Gi |
GPU | Intel® Data Center GPU Max 1100 |
GPU COUNT | 4 |
| HUGGING FACE OPTIMUM & INTEL® BIGDL
Learn more: https://huggingface.co, https://github.com/intel-analytics/BigDL
| TEST METHODOLOGY
The Llama-2 7B Chat INT8 model is exported into the Intel® OpenVINO™ format and then tested for text generation (inference) using Hugging Face Optimum. Hugging Face Optimum is an extension of Hugging Face transformers and Diffusers that provides tools to export and run optimized models on various ecosystems including Intel® OpenVINO™. We also tested bigdl-llm, a library for running large language models on Intel® supporting PyTorch and offering lower precision formats. Using bigdl-llm, we are able to leverage INT4 precision on llama-2 chat 7B.
For performance tests, 20 iterations were executed for each inference scenario out of which initial five iterations were considered as warm-up and were discarded for calculating Inference time (in seconds) and tokens per second. The time collected includes encode-decode time using tokenizer and LLM inference time.