




Comparing NVIDIA H100 PCIe on R760xa vs. NVIDIA H100 SXM on XE9680
Mon, 09 Sep 2024 16:58:26 -0000
|Read Time: 0 minutes
Introduction
 H100 PCIe on R760xa
H100 PCIe on R760xa
 H100 SXM on XE9680
H100 SXM on XE9680
As Artificial Intelligence (AI) and High-Performance Computing (HPC) applications continue to push the boundaries of computational demands, the choice of GPU form factors—PCIe or SXM—can significantly influence the success of deploying various types of AI workloads on a server. Selecting the right GPU form factor is not merely a technical decision but a strategic one that impacts overall system performance, scalability, and cost-effectiveness.
In this article, we will benchmark various critical metrics to provide a comprehensive comparison between one PCIe GPU and one SXM GPU form factor, focusing on throughput and latency.
We will explore the general differences between these form factors and illustrate their impact through practical business use case examples. Our hypothesis is that the SXM form factor, with its superior interconnects and advanced design, should outperform the PCIe form factor in key performance areas.
Before we get into the data, it’s essential to highlight the general differences and strengths between the two form factors.
As seen in Table 1, the SXM form factor offers significantly higher GPU memory bandwidth and BFLOAT16 Tensor Core performance, making it ideal for heavy AI and HPC workloads. Additionally, SXM GPUs benefit from higher interconnect bandwidth, although they come with higher power consumption and require more sophisticated cooling solutions. On the other hand, PCIe GPUs provide moderate usage compatibility with standard AI servers, lower power consumption, and greater flexibility in deployment.
Table 1. Hardware comparison: PCIe vs. SXM
| PCIe | SXM |
GPU Memory Bandwidth | 2 TB/s | 3.35 TB/s |
GPU Memory | 80GB | 80GB |
BFLOAT16 Tensor Core | 1513 teraFLOPS | 1979 teraFLOPS |
Compatibility | Moderate usage for standard, AI servers | Heavy usage for HPC with heavy AI workloads |
Power Consumption (Max TDP) | 300-350 W | 700 W |
Transistors | 80 billion | 80 billion |
Motherboard Connection | PCIe slots | Direct socket on motherboard |
Interconnect | NVLink: 600 GB/s PCIe Gen5 128 GB/s | NVLINK: 900 GB/s PCIe Gen 5 128 GB/s |
Cooling Solutions | Air-Cooling/Simple Liquid Cooling | Advanced liquid cooling systems |
NVIDIA Enterprise | Included | Add-On |
By examining both tables, it’s clear that SXM GPUs offer superior performance and future scalability whereas PCIe GPUs provide greater flexibility, lower power consumption, and cost efficiency.
Now, let’s examine the benchmark data *1 to accurately compare the two GPU models' throughput, latency, and GPU utilization.
To ensure a fair comparison, each test was conducted under identical conditions using the same version of vLLM, parameters, and precision types—specifically the BFloat16, Llama2 7b with vLLM serving one concurrent request. This approach ensures that any differences observed are solely attributable to the intrinsic capabilities of each GPU form factor.
PCIe vs. SXM comparisons in throughput, latency, and performance/watt
Throughput
LLMs deal in a form of data currency called tokens. Throughput is the metric that shows how many tokens per second a model can utilize in a given scenario, and it is the preferred AI metric for assessing an AI compute solution's ability to process and generate information efficiently on a quantitative scale. To gain a deeper understanding of how token dynamics influence throughput and overall performance, check out this blog that portrays the intricacies of token management and its impact on choosing the proper GPU.
As you can see in the following graph, the single NVIDIA H100 SXM GPU boasts a 30% higher throughput than the single NVIDIA H100 PCIe GPU. This throughput difference means the SXM form factor can handle more tokens, translating to a higher throughput performance when it comes to AI workloads.
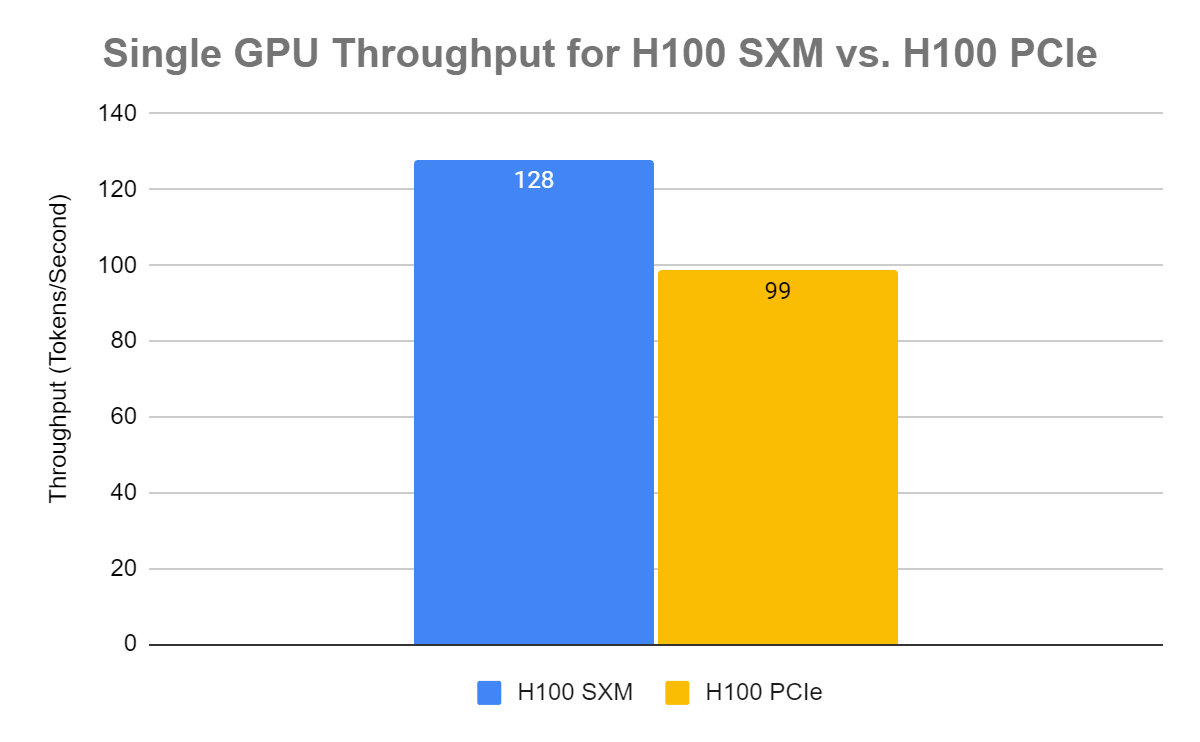
Figure 1. H100 PCIe vs. H100 SXM throughput comparison for BFloat16 Llama2 7B parameter model with one concurrent request
The NVIDIA H100 SXM has a throughput of 128 tokens/second whereas the Nvidia H100 PCIe has a throughput of 98.8 tokens/second. Not only does this indicate a higher raw throughput for the SXM GPU but also a greater performance in token processing under identical testing conditions. This reinforces why SXM can handle intensive AI workloads with higher rates of performance.
Now, let’s look at latency and see how the two form factors differ.
Latency
Have you ever felt frustrated while endlessly waiting for a chatbot to respond? That is because the model is processing the input, generating tokens within the model, and preparing the output - all in an instant.
When comparing the GPU latency between the two form factors using the Llama2 7B Parameter Model and BFloat16 precision, it is apparent that the latency is negligible. Both GPUs have a latency of ~12 milliseconds, but the NVIDIA H100 SXM has a slightly lower latency in our testing.
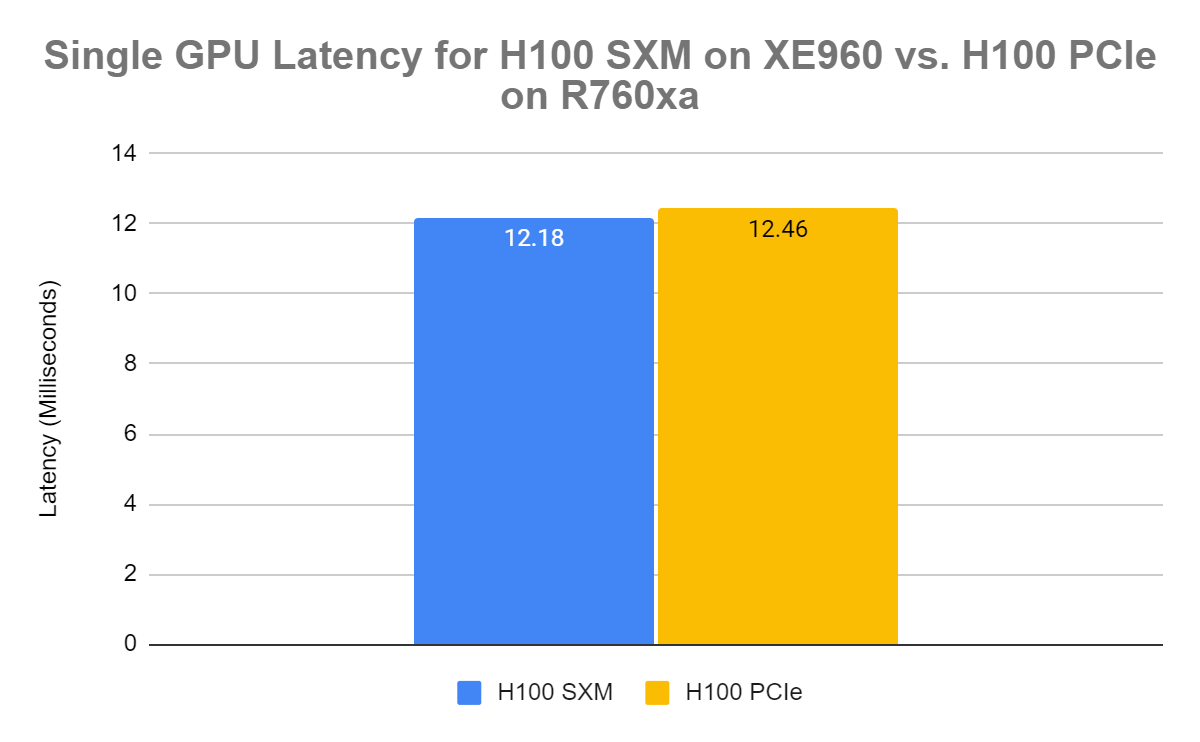
Figure 2. H100 PCIe vs. H100 SXM latency comparison for BFloat16 Llama2 7B parameter model with one concurrent request
Note: The metric used to determine latency represents the average time the model takes to start generating the first token across all measured requests.
In our latency comparison, both the NVIDIA H100 SXM and H100 PCIe have impressive responsiveness at 0.012 seconds. However, as you scale up, there is potential for the SXM GPUs to have a significantly lower latency time in comparison.
Now that we compared throughput and latency for the SXM and PCIe, the real question everyone is asking is: “PCIe or SXM?”
“PCIe or SXM?”
In conclusion, when selecting between the NVIDIA H100 PCIe and SXM GPUs, the decision hinges significantly on the specific deployment scenarios and priorities. The PCIe form factor, notably utilized in the PowerEdge R760XA, provides a highly compatible solution per GPU unit for a wide range of applications. However, as the usage of GPUs scales up, consolidating more SXM GPUs on a single server may offer superior energy efficiency compared to expanding the number of servers with PCIe GPUs. PCIe GPUs excel particularly in environments where the availability of standard server infrastructure is a critical consideration, such as in small- to medium-sized data centers or in enterprise settings where space and power are at a premium.
Conversely, the SXM form factor, showcased in the PowerEdge XE9680, delivers a marked performance advantage for intense AI and HPC workloads, largely due to its better bandwidth. This makes it particularly suitable for scenarios demanding high throughput, such as real-time AI applications or large-scale scientific computations. Moreover, the SXM's scalability features enhance vertical expansion capabilities within data centers, allowing for a denser and more powerful computing environment without disproportionately increasing operational costs.
Ultimately, the choice between PCIe and SXM mainly depends on the objective of deploying AI workloads. When balancing immediate performance and long-term operational efficiency, customers should focus on evaluating their specific needs, including but not limited to –
- Workload Intensity
- Required Scalability
- Energy Consumption
- Budget Constraints
Key Takeaways
 NVIDIA H100 SXM has a 30% higher throughput compared to the NVIDIA H100 PCIe GPU
NVIDIA H100 SXM has a 30% higher throughput compared to the NVIDIA H100 PCIe GPU
 Latency is approximately the same at approximately 12 milliseconds for a single concurrent request.
Latency is approximately the same at approximately 12 milliseconds for a single concurrent request.
To delve deeper into the differences in throughput between various GPUs, check out this research paper which meticulously evaluates how NIVIDIA GPUs, like the NVIDIA H100 PCIe and SXM, handle different levels of concurrent requests. The paper includes a detailed comparative analysis, showcasing real-world examples that illustrate how throughput capabilities can significantly impact the performance and efficiency of AI applications. These insights help businesses tailor their infrastructure choices to the specific demands of their AI workloads, emphasizing the importance of choosing the right GPU form factor based on throughput needs and concurrent processing capabilities.
References
Author: Jaydeep Golla