




Cloud Vs On Premise: Putting Leading AI Voice, Vision & Language Models to the Test in the Cloud & On Premise
Read the ReportThu, 14 Mar 2024 16:49:21 -0000
|Read Time: 0 minutes
| DEPLOYING LEADING AI MODELS ON PREMISE OR IN THE CLOUD
The decision to deploy workloads either on premise or in the cloud, hinges on four pivotal factors: economics, latency, regulatory requirements, and fault tolerance. Some might distill these considerations into a more colloquial framework: the laws of economics, the laws of the land, the laws of physics, and Murphy's Law. In this multi-part paper, we won't merely discuss these principles in theory. Instead, we'll delve deeper, testing and comparing leading AI models across voice, computer vision, and large language models both on premise and in the cloud.
In part one we’ll put leading CPUs to the test, with 4th Generation Intel® Xeon® Scalable Processor both in the cloud and on premise.
| LEVERAGING INTEL® DISTRIBUTION OF OPENVINO™ TOOLKIT & CORE PINNING FOR ENHANCED PERFORMANCE
To ensure enhanced performance across the cloud and on premise, we are using the Intel® Distribution of OpenVINO™ Toolkit because it offers enhanced optimizations of AI models runs and across a broad range of platforms and leading AI frameworks.
To further enhance performance, we conducted core pinning, a process used in computing to assign specific CPU cores to specific tasks or processes.

| AWS INSTANCE SELECTION
We have selected the AWS EC2 M7i Instance, specifically the m7i.48xlarge model, part of Amazon general-purpose instances that offers a substantial amount of computing resources making it comparable to Dell™ PowerEdge™ 760xa, the on-premise solution we selected.
- Processing Power and Memory: The m7i.48xlarge Instance is equipped with 192 virtual CPUs (vCPUs) and 768 GiB of memory. This high level of processing power and memory capacity is ideal for CPU-based machine learning.
- Networking and Bandwidth: This instance provides a bandwidth of 50 Gbps, facilitating efficient data processing and transfer, essential for high-transaction and latency-sensitive workloads.
- Performance Enhancement: The M7i Instances, including the m7i.48xlarge, are powered by custom 4th Generation Intel® Xeon® Scalable Processors, also known as Sapphire Rapids.
As of November 2023, the pricing for the AWS EC2 M7i Instance, specifically the m7i.48xlarge model, starts at US$9.6768 per hour.
| HARDWARE SELECTION CONSIDERATIONS
For the cloud instance, we selected the top AWS EC2 M7i Instance with 192 virtual cores. For on premise, Dell™ PowerEdge™ portfolio offered more choice and we selected 112 physical core processor with 224 hyper threaded cores. While cloud offerings offer significant choice, Dell™ PowerEdge™ portfolio offered great choice of processors, memory, and networking.
In our analysis, we are providing performance insights as well as cost of compute comparisons. For deployment you will also want to consider the following factors:
- Operational expenditures including power and maintenance costs,
- Network costs including data transfer to cloud and local connectivity,
- Data storage costs including cloud cost versus local storage,
- Network latency requirements including lower latency as data is processed locally,
- Security and compliance costs.
| AI MODELS SELECTION
- LLama-2 7B Chat • OpenAI Whisper Base • YOLOv8n Instance Segmentation
To ensure we have a broad range of AI workloads tested on premise and in the cloud we opted for three of the leading models in their domains:
- VISION | YOLOv8n-seg
YOLOv8n-seg is model variant of YOLOv8 that is designed for instance segmentation and has 3.2 million parameters for the nano version. Unlike basic object detection instance segmentation identifies the objects in an image as well as the segments of each object and provides outlines and confidence scores.
- LANGUAGE | Llama 2 7B Chat
Llama-2 7B-chat is a member of the Llama family of large language models offered by Meta, trained on 2 trillion tokens and well suited for chat applications.
- VOICE | OpenAI Whisper base 74M
OpenAI Whisper is a deep learning model developed by OpenAI for speech recognition and transcription, capable of transcribing speech in English and multiple other languages and translating several non-English languages into English.
EDGE HARDWARE | DELL™ POWEREDGE™ R760XA RACK SERVER

The system we selected is Dell™ PowerEdge™ R760xa hardware powered by 4th Generation Intel® Xeon® Scalable Processors.
The Air-cooled design with front-facing accelerators enables better cooling Cyber Resilient Architecture for Zero Trust IT environment.
Operations Security is integrated into every phase of Dell™ PowerEdge™ lifecycle, including protected supply chain and factory-to-site integrity assurance.
Silicon-based root of trust anchors provide end-to-end boot resilience complemented by Multi-Factor Authentication (MFA) and role-based access controls to ensure secure operations. iDRAC delivers seamless automation and centralize one-to-many management.

 *Performance varies by use case, model, application, hardware & software configurations, the quality of the resolution of the input data, and other factors. This performance testing is intended for informational purposes and not intended to be a guarantee of actual performance of an AI application.
*Performance varies by use case, model, application, hardware & software configurations, the quality of the resolution of the input data, and other factors. This performance testing is intended for informational purposes and not intended to be a guarantee of actual performance of an AI application.
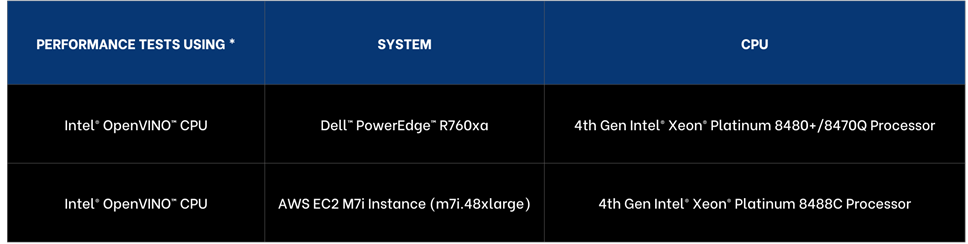
| PERFORMANCE INSIGHTS
The results selected for YOLOv8n Instance Segmentation running 12 processes as that threshold achieved targeted performance of >30 images per second. Llama-2 7B Chat was selected running 2 processes as it achieved targeted sub 100 ms per token user latency. OpenAI Whisper selected running 64 processes targeting user reading speed. Across vision, language, and voice, the on premise offering exceeded the cloud instance, including offering lower latency AI performance. From a computational cost comparison the on premise solution offered a payback period of nearly a year based on dell.com pricing indicating a TCO win for on premise as well.
| RETAIL USE CASE
- Drive-thru Pharmacy Pick-up
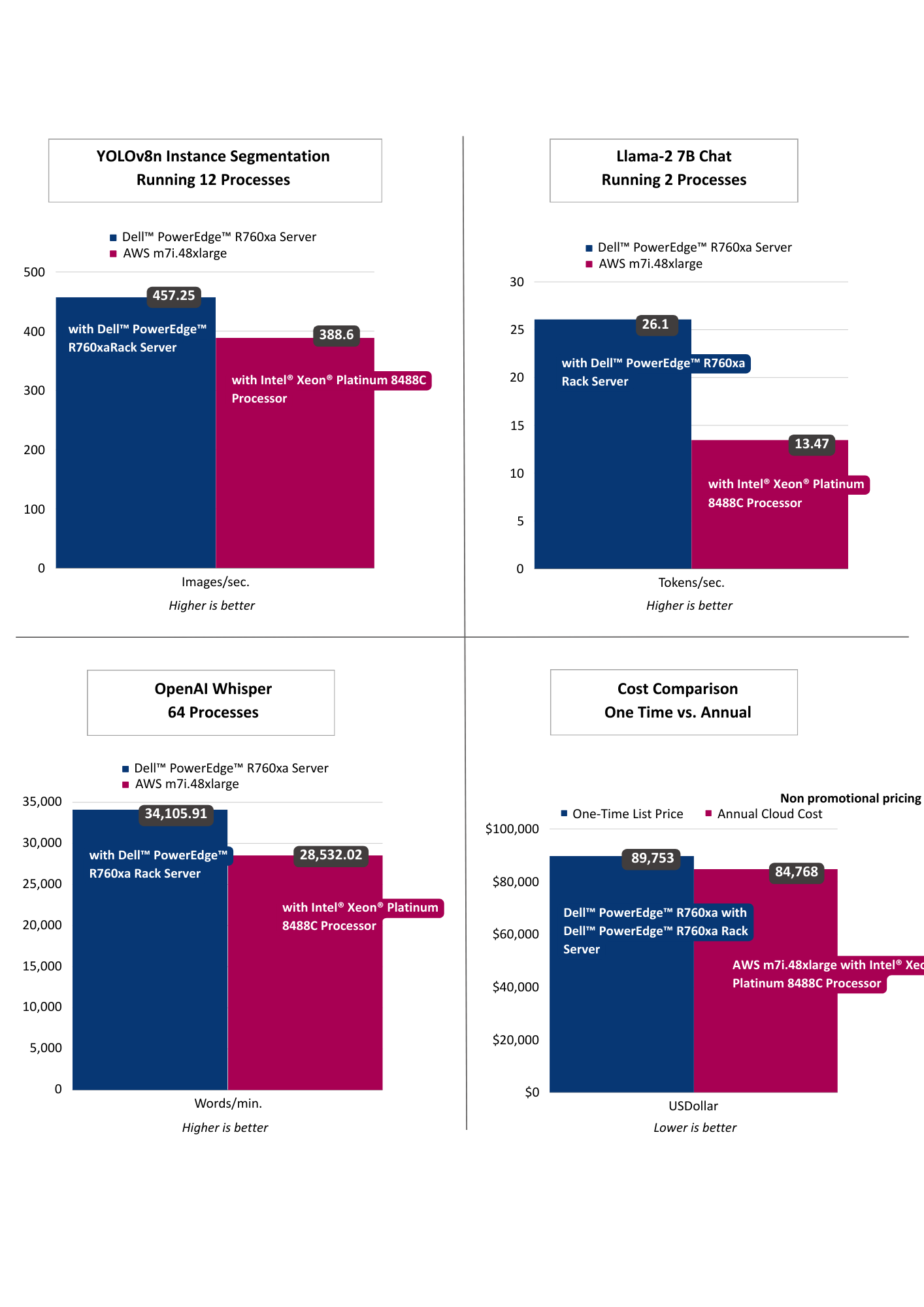
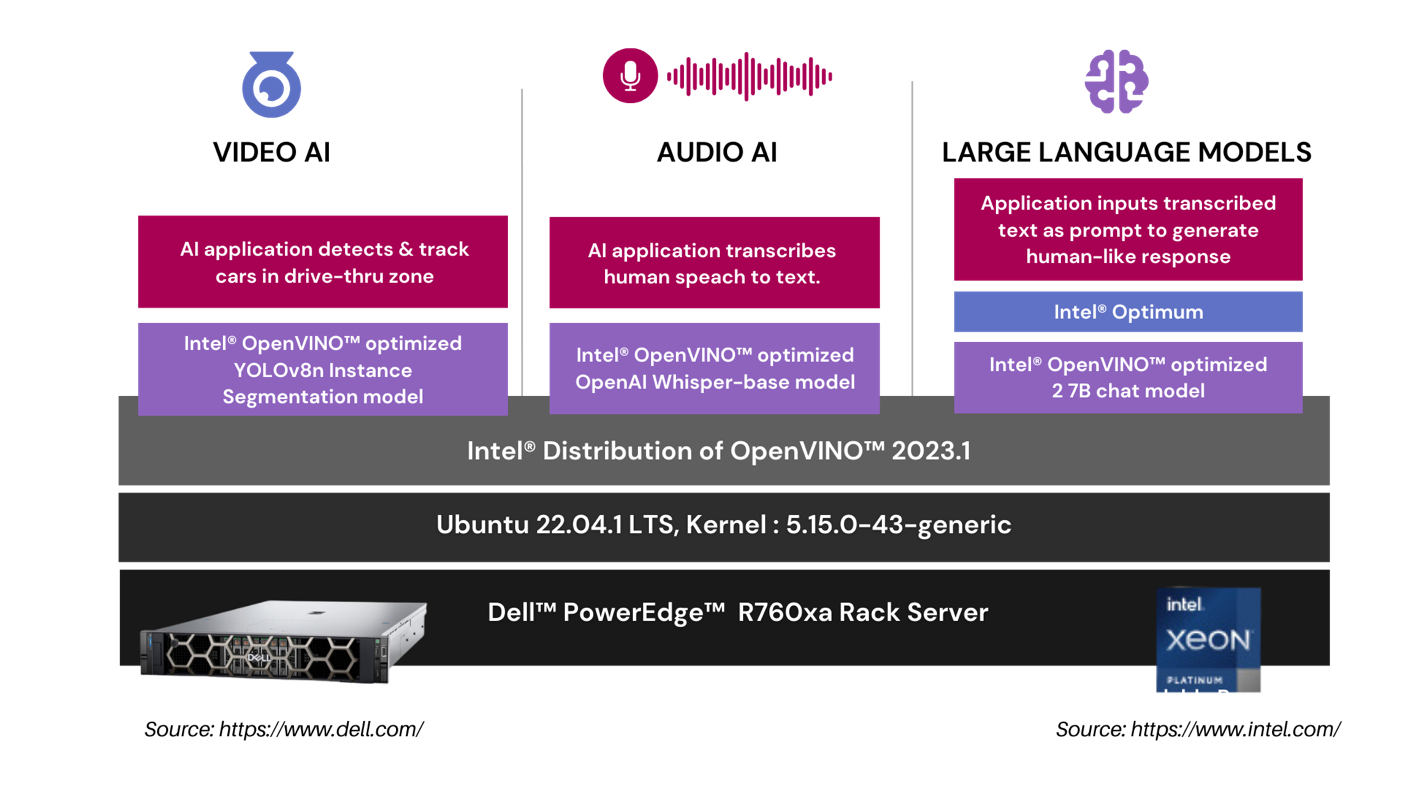
To demonstrate the practical application of these models, we designed a solution architecture accompanied by a demo that simulates a drive-through pharmacy scenario. In this use case, the vision model identifies the car upon its arrival, the language model gathers the client's information, and communication is facilitated via the voice model. As you can discern, factors such as latency, privacy, security, and cost play crucial roles in this scenario, emphasizing the importance of the decision to deploy either in the cloud or on premise.

In our drive-thru pharmacy pick-up scenario, we utilize a comprehensive architecture to optimize the customer experience. The Video AI module employs an Intel® OpenVINO™ optimized YOLOv8n Instance Segmentation model to accurately detect and track cars in the drive-thru zone. The Audio AI segment captures and transcribes human speech into text using an Intel® OpenVINO™ optimized OpenAI whisper-base model. This transcribed text is then processed by our Large Language Models segment, where an application leverages the Intel® OpenVINO™ optimized LLama 2 7B Chat model to generate intuitive, human-like responses.
| RETAIL USE CASE ARCHITECTURE
| SUMMARY
In this analysis, we put the leading voice, language, and vision models to the test on Dell™ PowerEdge™ and AWS on CPUs. Dell™ PowerEdge™ R760xa Rack Server exceeded the cloud instances on all performance tests and offers a payback period of nearly one year based on Dell™ public pricing. The drive-through pharmacy use case showcased the advantages of an on premise deployment to maintain customer privacy, HIPPA compliance, and ensure fault tolerance and low latency. Finally, in both instances we showcased enhanced CPU performance with Intel® OpenVINO™ and core pinning. In part II, we’ll compare GPU workloads in the cloud versus on premise.
APPENDIX | PERFORMANCE TESTING DETAILS
Performance Insights | 4th Generation Intel® Xeon® Scalable Processors
- Yolov8n Instance Segmentation with Intel® OpenVINO™ & Core Pinning
| Test Methodology
YOLOv8n Instance Segmentation FP32 model is exported into the Intel® OpenVINO™ format using ultralytics 8.0.43 library and then tested for object segmentation (inference) using Intel® OpenVINO™ 2023.1.0 runtime.
For performance tests, we used a source video of 53 sec duration with resolution of 1080p and a bitrate of 1906 kb/s. The initial 30 inference samples were treated as warm-up and excluded from calculating the average inference metrics. The time collected includes H264 encode-decode using PyAV 10.0.0 and model inference time.
Output | Video file with h264 encoding (without segmentation post processing)
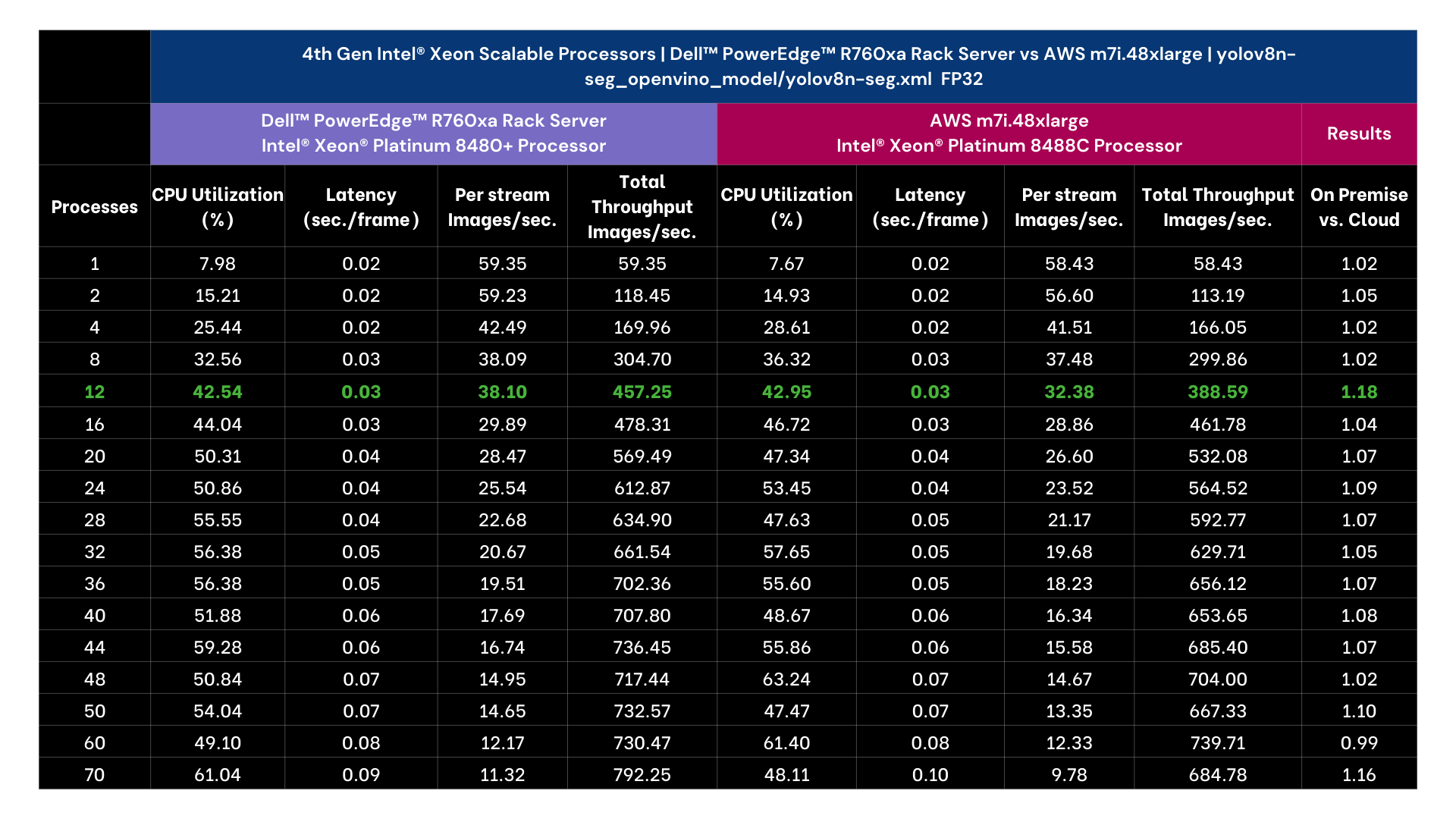
*Performance varies by use case, model, application, hardware & software configurations, the quality of the resolution of the input data, and other factors. This performance testing is intended for informational purposes and not intended to be a guarantee of actual performance of an AI application.
Performance Insights | 4th Gen Intel® Xeon® Scalable Processors
- Llama 2 7B Chat with Intel® OpenVINO™ & Core Pinning
| Test methodology
The Llama-2 7B Chat FP32 model is exported into the Intel® OpenVINO™ format and then tested for text generation (inference) using Hugging Face Optimum 1.13.1. Hugging Face Optimum is an extension of Hugging Face transformers and Diffusers and provides tools to export and run optimized models on various ecosystems including Intel® OpenVINO™. For performance tests, 25 iterations were executed for each inference scenario out of which initial 5 iterations were considered as warm-up and were discarded for calculating Inference time (in seconds) and tokens per second. The time collected includes encode-decode time using tokenizer and LLM inference time.
Input | Discuss the history and evolution of artificial intelligence in 80 words.
Output | Discuss the history and evolution of artificial intelligence in 80 words or less.
Artificial intelligence (AI) has a long history dating back to the 1950s when computer scientist Alan Turing proposed the Turing Test to measure machine intelligence. Since then, AI has evolved through various stages, including rule-based systems, machine learning, and deep learning, leading to the development of intelligent systems capable of performing tasks that typically require human intelligence, such as visual recognition, natural language processing, and decision-making.
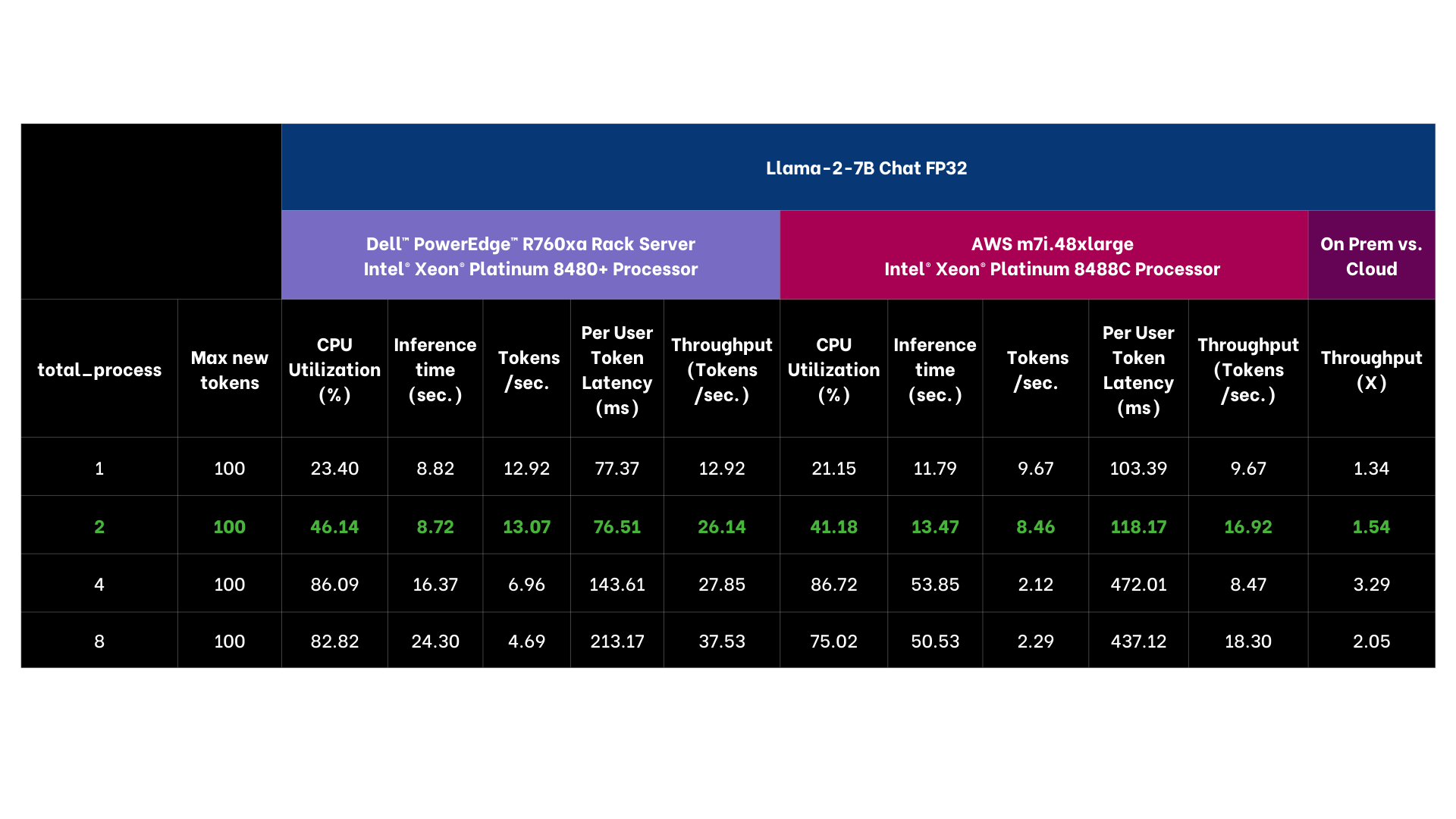
Base Model | https://huggingface.co/meta-llama/Llama-2-7b-chat-hf
*Performance varies by use case, model, application, hardware & software configurations, the quality of the resolution of the input data, and other factors. This performance testing is intended for informational purposes and not intended to be a guarantee of actual performance of an AI application.
PERFORMANCE INSIGHTS | 4TH GEN INTEL® XEON® SCALABLE PROCESSORS
- OpenAI Whisper-base model with Intel® OpenVINO™ & Core Pinning
| Test methodology
The OpenAI Whisper base 74M FP32 model is exported into the Intel® OpenVINO™ format and then tested for inference using Intel® OpenVINO™. For performance tests, 25 iterations were executed for each inference scenario out of which initial 5 iterations were considered as warm-up and were discarded for calculating Inference time (in seconds) and tokens per second. The time collected includes encode-decode time using tokenizer and LLM inference time.
Input | MP3 file with 28.2 sec audio
Output | Generative AI has revolutionized the retail industry by offering a wide array of innovative use cases that enhance customer experiences and streamline operations. One prominent application of Generative AI is personalized product recommendations. Retailers can utilize advanced recommendation algorithms to analyze customer data and generate tailored product suggestions in real time. This not only drives sales but also enhances customer satisfaction by presenting them with items that align with their preferences and purchase history.
| 74 words transcribed.
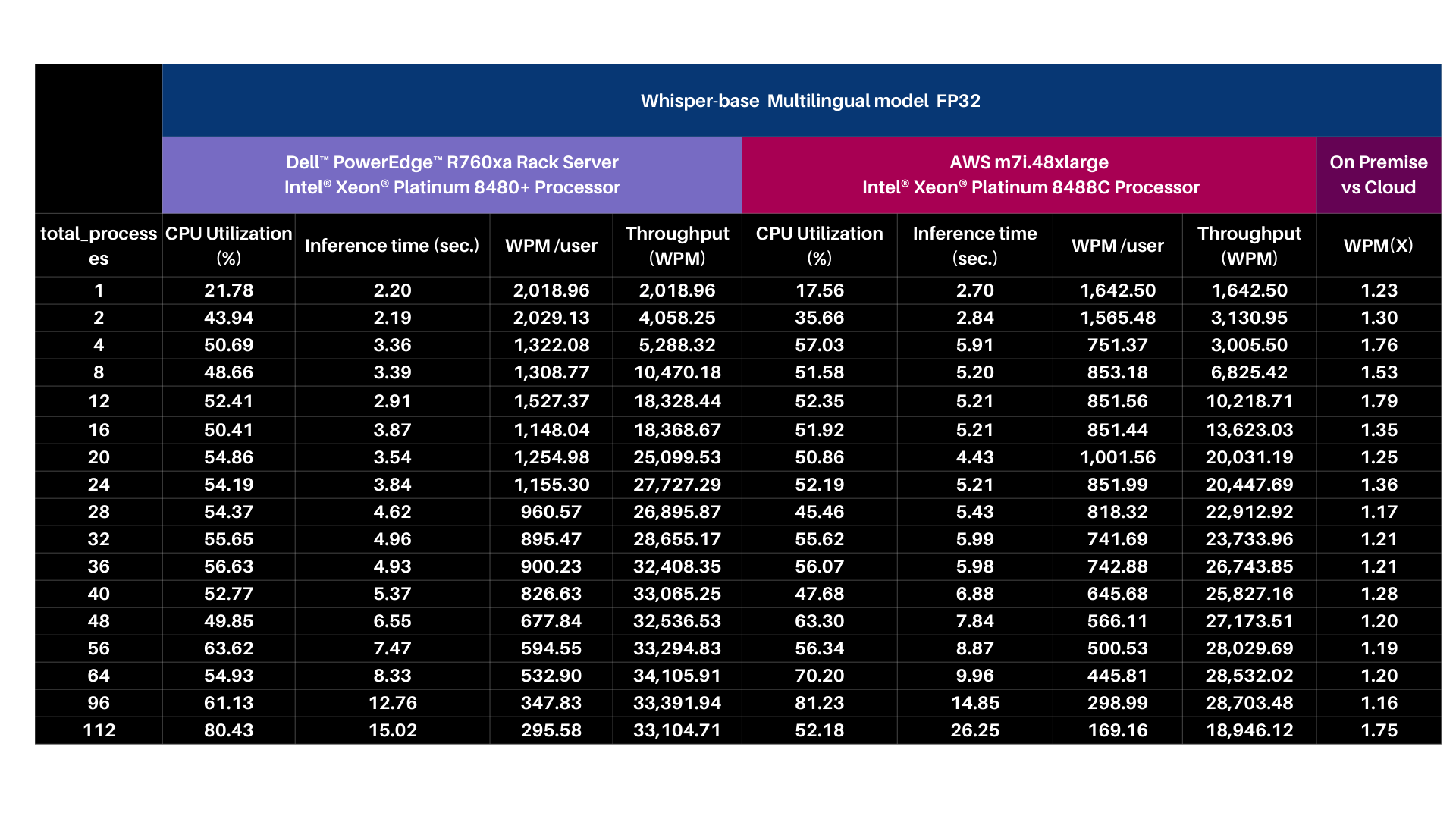
Base Model | https://github.com/openai/whisper#available-models-and-languages
***Performance varies by use case, model, application, hardware & software configurations, the quality of the resolution of the input data, and other factors. This performance testing is intended for informational purposes and not intended to be a guarantee of actual performance of an AI application.
| About Scalers AI™
Scalers AI™ specializes in creating end-to-end artificial intelligence (AI) solutions to fast-track industry transformation across a wide range of industries, including retail, smart cities, manufacturing, insurance, finance, legal and healthcare. Scalers AI™ industry offering include predictive analytics, generative AI chatbots, stable diffusion, image and speech recognition, and natural language processing. As a full stack AI solutions company with solutions ranging from the cloud to the edge, our customers often need versatile common off the shelf (COTS) hardware that works well across a range of workloads.
- Fast track development & save hundreds of hours in development with access to the solution code.
As part of this effort, Scalers AI™ is making the solution code available. Reach out to your Dell™ representative or contact Scalers AI™ at contact@scalers.ai for access to GitHub repo.
