




Benchmarking NVIDIA GPU Throughput for LLMs and Understanding GPU Configuration Choices in the AI Space
Download PDFMon, 09 Sep 2024 15:23:12 -0000
|Read Time: 0 minutes
Executive summary
This document presents a detailed comparative analysis of GPU throughput for LLMs, highlighting key performance metrics across a range of GPUs at varying levels of user concurrency. It introduces essential AI and GPU terminology, providing readers with the foundational understanding necessary for making informed decisions about GPU configurations in the AI space. This paper explores three specific use cases for Single GPUs—internal employee chatbots, code generation for developers, and real-time customer support—to demonstrate how to effectively gauge GPU throughput requirements for distinct AI applications.
Organizations beginning to deploy Large Language Models (LLMs) face crucial decisions regarding hardware selection. The challenge extends beyond merely balancing performance with cost; it involves choosing the right infrastructure to support complex AI applications without compromising efficiency and scalability.
The following table details the hardware configurations utilized in the testing and evaluation of LLM performance. It includes a range of GPUs from NVIDIA's lineup, notably the H100 SXM, H100 PCIe, and A100 SXM, which are pivotal in assessing the computational efficacy for AI tasks. Each GPU is paired with the latest robust server platforms from Dell Technologies, such as the Dell PowerEdge XE9680 and R760XA, equipped with high-performance Intel® Xeon® Platinum CPUs.
Table 1. Hardware configurations tested for LLM deployment
GPU SKU | Hardware Model Name | CPU Used | Memory | GPU Memory Bandwidth | Power Consumption (TDP) |
Dell PowerEdge XE9680 | Intel® Xeon® Platinum 8480+ | 80 GB HBM3 |
3.35TB/s | 700 W | |
Dell PowerEdge R760XA | Intel® Xeon® Platinum 8480+ | 80 GB HBM2e |
2TB/s | 700 W | |
NVIDIA A100 SXM | Dell PowerEdge R760XA | Intel® Xeon® Platinum 8480+ | 40 GB HBM2 | 1.6 TB/s | 72 W |
NVIDIA L40s PCIe | Dell PowerEdge R760XA | Intel® Xeon® PLATINUM 8592+ | 48 GB GDDR6 | 864G/s | 350 W |
NVIDIA L40 PCIe | Dell PowerEdge R760XA | Intel® Xeon® PLATINUM 8580 | 48 GB GDDR6 | 864GB/s | 350 W |
NVIDIA L4 PCIe | Dell Power Edge R760XA | Intel® Xeon® Platinum 8480+ | 24 GB GDDR6 | 300 GB/s | 72 W |
Testing methodology
Single-GPU testing conditions
The testing and analysis included four distinct LLM configurations for the single GPU dataset:
- Llama2 - 13 Billion Parameters
- Llama2 - 7 Billion Parameters
- Mistral – 7 Billion Parameters
- Falcon – 7 Billion Parameters
Each of these models has three types of model precision settings:
- BFloat16
- Float16
- Float32
This rigorous evaluation spanned a wide range of scenarios on the GPUs listed in the previous table with VD Bench, simulating environments with 1 to 1000 concurrent users to mimic real-world usage. Overall, the dataset, compiled in collaboration with ScalarsAI, includes 132 detailed test cases for each GPU configuration, providing a strong base for our subsequent performance analysis and recommendations.
Multi-GPU testing conditions
Table 2. Multi-GPU testing conditions
| 1 GPU, 1 Replica | 2 GPUs, 2 Replicas | 1 GPU, 4 Replicas | 2 GPU, 1 Replica | 2 GPU, 2 Replicas | 4 GPU, 1 Replica |
Llama2 – 7B |
|
|
|
|
|
|
Llama2 – 13B |
|
|
|
|
|
|
Llama2 – 70B |
|
|
|
|
|
|
Llama3 – 8B |
|
|
|
|
|
|
Llama3 – 70B |
|
|
|
|
|
|
Mistral – 7B |
|
|
|
|
|
|
Mistral – 8x7B |
|
|
|
|
|
|
Falcon – 7B |
|
|
|
|
|
|
Falcon – 70B |
|
|
|
|
|
|























For the Multi-GPU dataset, the testing and analysis included nine distinct LLM configurations:
- Llama2 – 7 Billion Parameters
- Llama2 - 13 Billion Parameters
- Llama 2- 70 Billion Parameters
- Llama3 – 8 Billion Parameters
- Llama3 – 70 Billion Parameters
- Mistral – 7 Billion Parameters
- Mixtral 8x7 - 46.7 Billion Parameters (8x7B Models)
- Falcon - 7 Billion Parameters
- Falcon - 40 Billion Parameters
Note: In this table, "replicas" refer to the number of parallel instances of a task or model running simultaneously, enhancing fault tolerance and load distribution across the computational resources.
Note: Multi-GPU dataset does not contain the H100 SXM.
Comparing and contrasting single-GPUs throughput
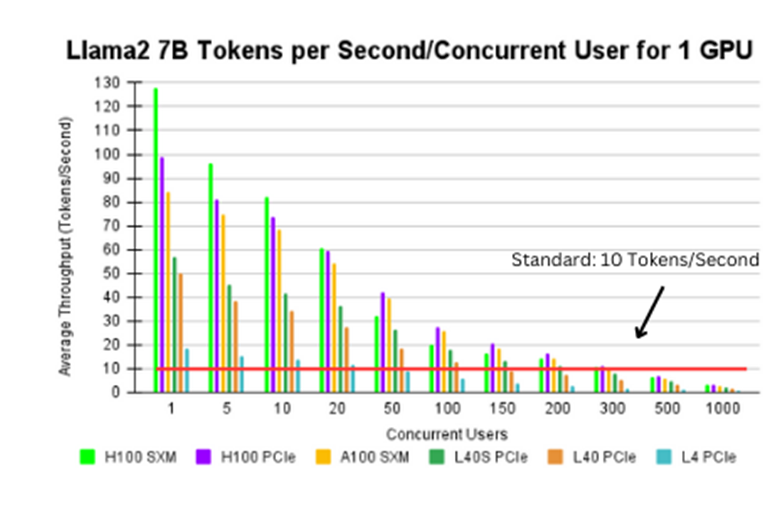
Figure 1. Llama2 7B tokens per second/concurrent user for 1 GPU
Figure 1[1] shows the average throughput for various GPU configurations, while holding parameter size, model type, and data type (bfloat16) constant. The red line represents an established throughput standard of 10 tokens/second, translating to ~450 words/minute outputted by the LLM. Based on each specific use case, this number may vary. We found:
- Across all configurations, as the number of concurrent users increase, the average throughput decreases.
- Every GPU configuration, except for the L4, meets or surpasses the standard throughput threshold for up to 100 concurrent users.
- When scaling the number of concurrent users, the H100 PCIe, H100 SXM, and A100 SXM GPUs maximize performance. That said, if less concurrent users are required, the L40S GPU delivers similar performance at a much lower cost.
Real-world examples
AI-driven employee onboarding and FAQ chatbot
Scenario: A company is enhancing its internal operations with a chatbot that assists employees with departmental queries, FAQs, and onboarding processes.
Established throughput baseline: 10 tokens/second - This is sufficient for the chatbot to respond without frustrating delays, balancing responsiveness with resource usage. The rate 10 tokens/second was chosen because most questions are straightforward and repetitive, such as queries about company policies, benefits, or procedural steps, which typically require minimal context analysis and token consumption. Moreover, the stored data necessary for responding to these queries is relatively limited, reducing the need for extensive token allocation to process complex inputs.
Recommended GPUs (Meeting or Exceeding 10 Tokens/Second):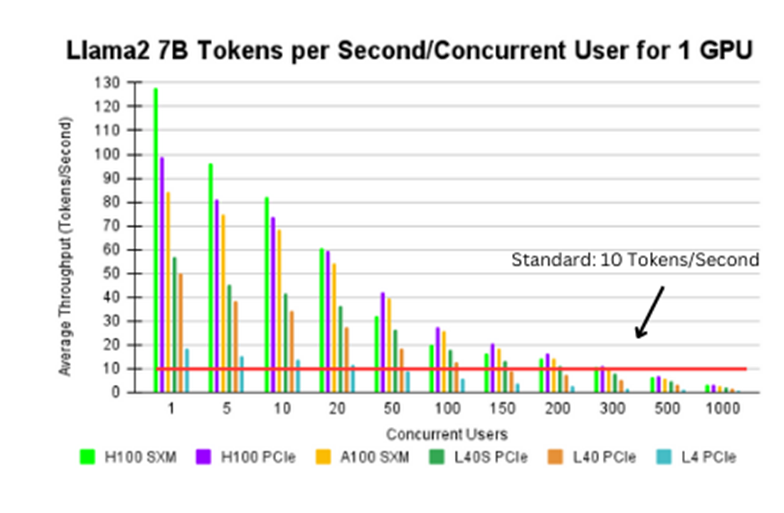
Figure 2. Llama2 7B tokens per second/concurrent user for 1 GPU
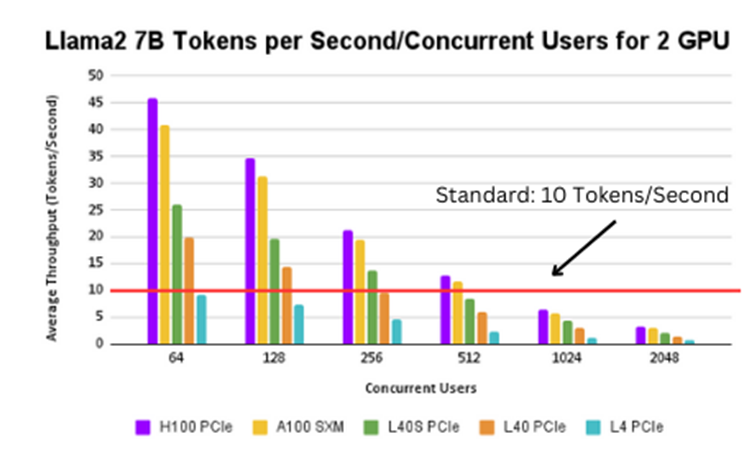
Figure 3. Llama2 7B tokens per second/concurrent user for 2 GPUs
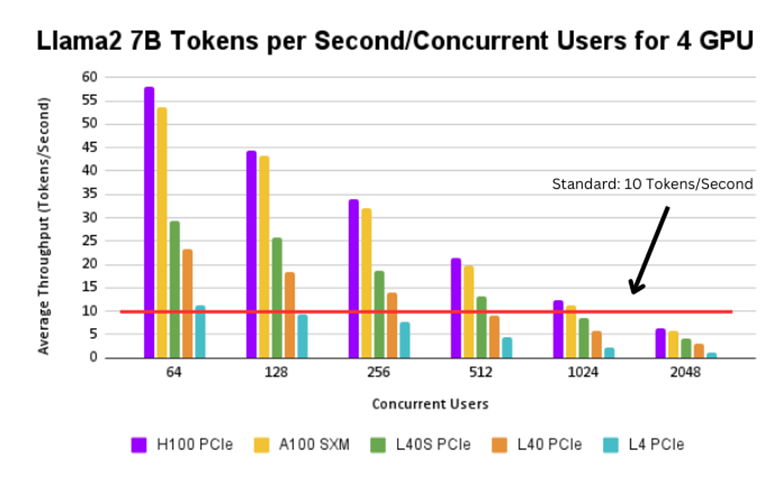
Figure 4. Llama2 7B tokens per second/concurrent user for 4 GPUs
The H100 SXM, H100 PCIe, A100 SXM, and L40s PCIe GPUs can support up to 200 users, whereas the L40 PCIe and L4 PCIe can support up to 100 and 50 users respectively.
Real-time customer support AI for sales and IT
Scenario: A large enterprise employs an AI system to manage customer inquiries through calls or text, supporting hundreds of concurrent interactions by sales and IT support staff. The LLM is finetuned to swiftly process a wide array of customer queries, ranging from comparative questions about competitive products to detailed explanations of features that distinguish the company's offerings.The system requires good throughput to process customer inputs and generate responses swiftly within a moment.
Established throughput baseline: 25 tokens/second - This throughput ensures quick responses to customer inquiries, which is essential for maintaining conversation flow and customer satisfaction without needing deep contextual analysis. Compared to previous examples, user satisfaction is extremely vital, since customers are being directly impacted in real time. A throughput of 30 tokens per second is not just about speed; it's about the capability to deliver timely, context-aware, and effective customer service that aligns with the expectations of modern consumers.
Recommended GPUs (Meeting or Exceeding 25 Tokens/Second):
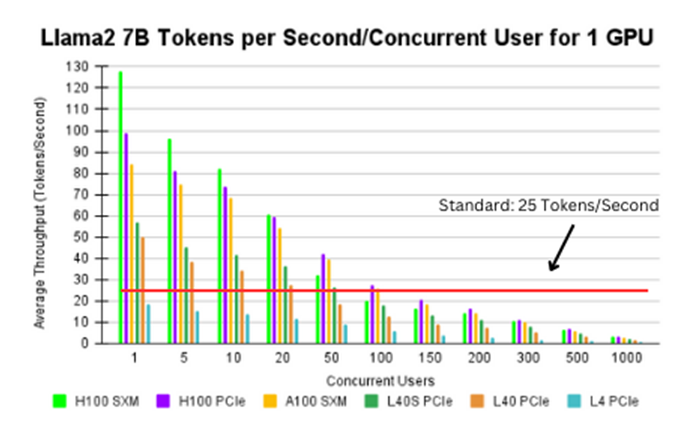
Figure 5. Llama2 7B tokens per second/concurrent user for 1 GPU
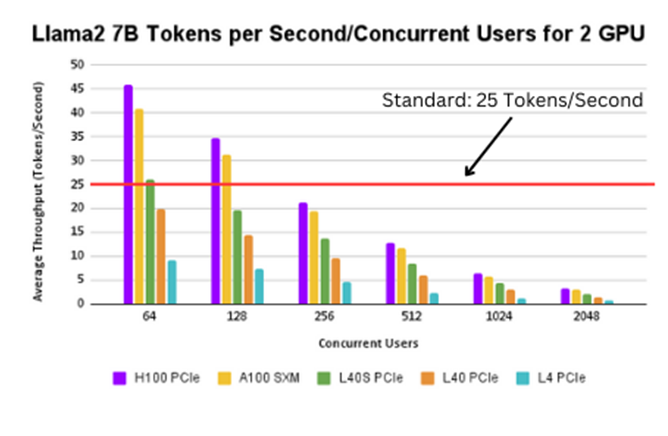
Figure 6. Llama2 7B tokens per second/concurrent user for 2 GPUs
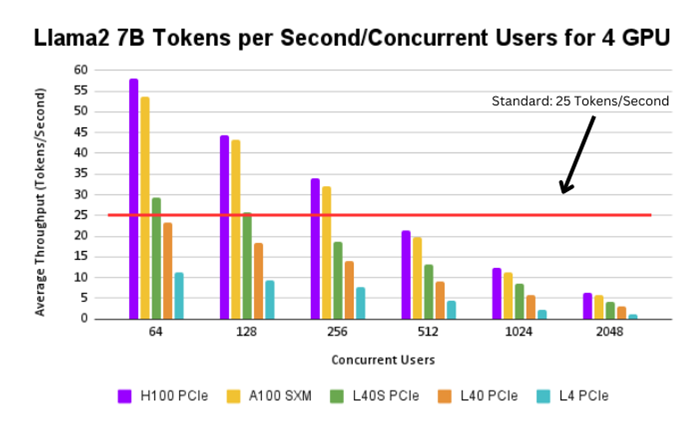
Figure 7. Llama2 7B tokens per second/concurrent user for 4 GPUs
Up to a 100 users, the H100 PCIe and A100 SXM support a throughput of 25 tokens/second. The H100 SXM and the L40s PCIe can support up to 50 users at the same throughput. The L40 PCIe can support up to 20 users at a time, however the L4 PCIe again cannot support this use case.
Code generation for software development teams
Scenario: A development firm employs an AI-driven tool that aids developers by suggesting code blocks and facilitating debugging in real-time. This tool is versatile, supporting a variety of coding tasks—from autocomplete of code snippets to generating entire code blocks based on minimal inputs. It is also integral in real-time peer review systems, offering on-the-fly optimizations and corrections, and serves as an educational aid that dynamically generates coding examples tailored to the user's current learning topic. This multi-functional capability ensures that developers can enhance productivity and accuracy in their coding projects, making the tool essential for modern software development environments.
Established throughput baseline: 40 tokens/second - This higher rate is necessary to manage the heavy data processing and output demands in code generation, ensuring developers experience minimal lag time. This substantial rate accommodates the dense token requirements typical of coding environments, where both input queries and output suggestions are often complex and lengthy. Code generation processes not only necessitate parsing extensive programming syntax but also generating accurate, contextually appropriate code responses. This ensures that developers can iterate and test code rapidly without delays, significantly enhancing productivity.
Recommended GPUs (Meeting or Exceeding 40 Tokens):
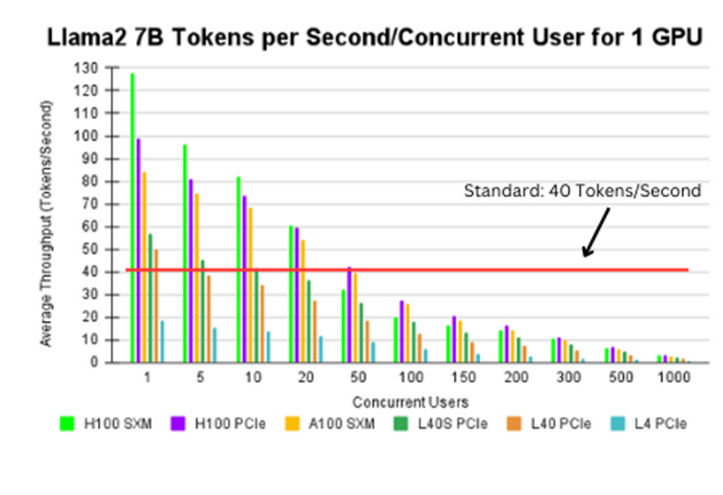
Figure 8. Llama2 7B tokens per second/concurrent user for 1 GPU
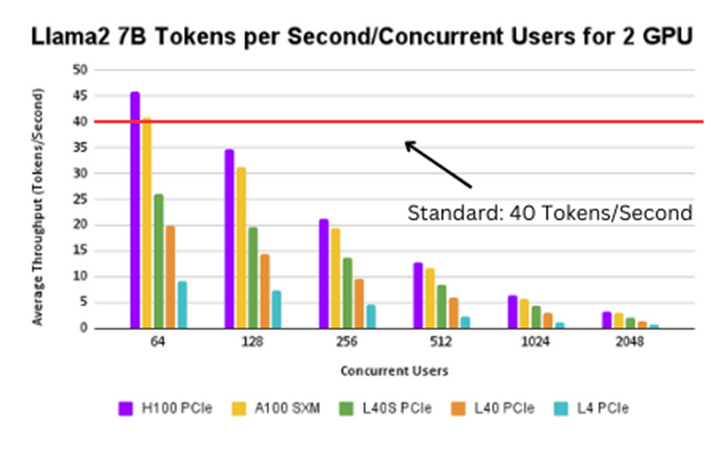
Figure 9. Llama2 7B tokens per second/concurrent user for 2 GPUs
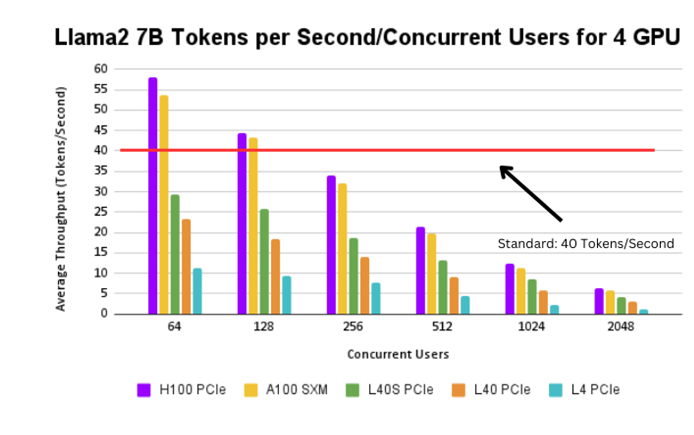
Figure 10. Llama2 7B tokens per second/concurrent user for 4 GPUs
The H100 PCIe and A100 SXM can support up to 50 users at a 40 tokens/second throughput. The H100 SXM can support up to 40 users at the same throughput. The L40s PCIe and L40 PCIe can support between 5-10 users at a time. The L4 PCIe cannot be employed with this example because of the lack of computational power to support such a high throughput.
Importance of scaling GPUs: Two use cases utilizing 8 A100-SXM GPUs
High-resolution climate modeling
Objective: To perform high-resolution climate modeling that simulates and predicts weather patterns over decades at a much higher spatial resolution than traditional models.
Description: Climate research demands the handling of vast datasets and the execution of complex simulations that model the earth's atmosphere, oceans, and land surfaces over extensive periods. Utilizing a server equipped with 8 NVIDIA A100-SXM GPUs, researchers can significantly reduce the time required for these simulations. The A100’s ability to perform faster matrix operations and handle large volumes of data concurrently allows for more detailed and accurate modeling.
Implementation:
- Data: Utilize historical weather data, satellite imagery, and oceanographic data spanning over 50 years.
- Process: Implement parallel processing algorithms that divide the global map into grids that are processed simultaneously. Each GPU handles a specific segment of the grid, performing computations related to weather patterns, temperature fluctuations, and ocean currents.
- Outcome: The use of 8 GPUs enables the processing of larger grids with higher precision, reducing the simulation time from several months to a few weeks and thus providing quicker insights for climate policy-making and scientific research.
Real-time genetic sequencing and analysis
Objective: To accelerate the process of genetic sequencing and analysis for real-time medical diagnostics and research in genomics.
Description: Genetic sequencing generates enormous volumes of data that require substantial computational resources to analyze. Using an 8 GPU configuration with NVIDIA A100-SXM GPUs enhances the ability to process multiple genome sequences simultaneously, applying complex bioinformatics algorithms at an unprecedented speed. This setup is particularly beneficial in epidemiological studies where rapid genome sequencing is necessary to track virus mutations and spread.
Implementation:
- Data: Multiple human genome sequences obtained from global databases and during outbreaks or clinical trials.
- Process: Deploy parallel genome sequencing tools and machine learning models that analyze genetic data across multiple GPUs to identify genetic variants and link them to specific diseases or health conditions.
- Outcome: Dramatically reduces the time needed for genome processing from days to hours, enabling immediate clinical responses and facilitating advanced research in personalized medicine.
Advantages of using 8 GPUs with NVIDIA A100-SXM:
- Increased throughput: Multiple GPUs working in concert can handle more tasks simultaneously, greatly increasing computational throughput.
- Reduced latency: Essential for real-time applications, where delays in data processing can lead to outdated results or missed opportunities in time-sensitive scenarios.
- Energy efficiency: Despite the high power requirements, A100 GPUs are designed to maximize computation per watt, making them more energy-efficient for large-scale computations compared to other setups with lower performance GPUs.
By implementing these use cases, organizations can leverage the advanced capabilities of NVIDIA A100 GPUs to tackle complex, data-intensive problems more efficiently and effectively, demonstrating the critical importance of GPU scaling in high-performance computing environments.
[1] Based on July 2024 Dell labs testing and analysis, subjecting the PowerEdge XE9680 and R760xa to various GPU configurations
Author: Jaydeep Golla