




Are you ready for GenAI? You will be when you harness the power of Dell and Intel
Mon, 24 Jun 2024 14:33:53 -0000
|Read Time: 0 minutes
Generative Artificial Intelligence, or GenAI, has moved into mainstream computing at lightning speed and is already causing a significant impact on society at large. Consumer-friendly AI engines like ChatGPT have quickly grabbed our collective cultural attention…and for good reason. However, the real power of GenAI is in its promise at the organizational level. Higher productivity, lower costs, and a tangible shift in how we work are very real opportunities with and almost limitless horizon.
If you’re new to GenAI or even a veteran in the AI space, it’s clear that two words key to driving your IT hardware decisions are “performance and versatility.” It takes a lot of compute power to train and fine-tune Large Language Models (LLMs). These models are pre-trained on vast amounts of data and then fine-tuned using a smaller dataset to adapt the larger models to more specific tasks and improve their performance.
A Winning GenAI Combination
Dell recently conducted testing by Dell Technologies Engineers in Dell Labs by Intel® in November and December 2023. LLM performance testing was done using the Dell PowerEdge R760 server running on 5th Gen Intel® Xeon® Scalable Processors. The Dell PowerEdge R760 server helps “accelerate transformation anywhere” with technology and solutions that help you innovate, adapt, and grow AI-driven innovation. There were two valuable use cases tested: 1) What are the next-token latency requirements of real-time chatbots, and 2) Fine-tuning LLM models to showcase if customers could benefit from this platform.
Some of the optimizations powering these LLM use cases include:
- Intel® Advanced Matrix Extensions (Intel® AMX), an AI accelerator built into each core
- BFloat 16 and INT8 precision support with Intel AMX
- Improved Advanced Vector Extension (AVX) performance
- Larger last-level cache for better data locality
- Intel® Extensions for Pytorch (IPEX) optimizations for LLMs
- DeepSpeed for model parallelism
What did we find?
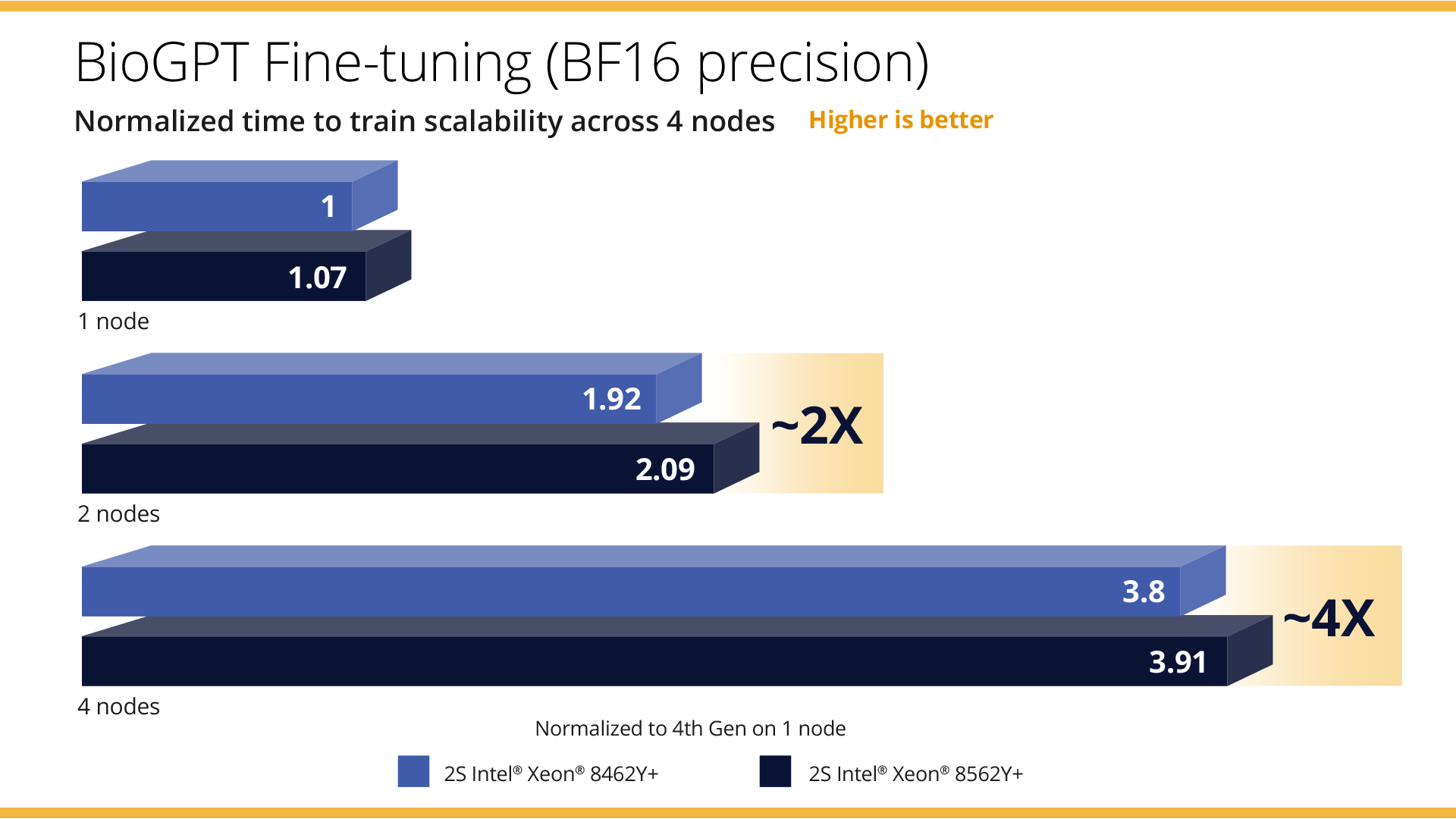
In a nutshell,
- We showed that distributed inference met market-level latency requirements of <100ms*
- We demonstrated that by scaling from 1 to 2 nodes, we achieved 2x time to train, and by moving to 4 nodes, we achieved near linear 4x scaling across both 4th Gen Intel Xeon processors and 5th Gen Intel Xeon processors, with the 5th Gen Intel Xeon processors demonstrating an additional 9% performance improvement. *
- We were able to fine-tune a model like BioGPT in ~16.23 minutes across 4 nodes with 5th Gen Intel Xeon Scalable processors. *

Investing in solutions to support your GenAI workloads is an important decision not only because it involves significant new IT investment. The lightning speed with which this technology is growing and changing reinforces the need to buy hardware and software solutions that will grow along with your GenAI requirements. Dell PowerEdge servers and Intel Xeon processors are a great place to start.
Want more information? Read the report here: https://infohub.delltechnologies.com/en-us/t/driving-genai-advancements-dell-poweredge-r760-with-the-latest-5th-gen-intel-r-xeon-r-scalable-processors/