
NVIDIA
NVIDIA
-
NVIDIA AI Enterprise
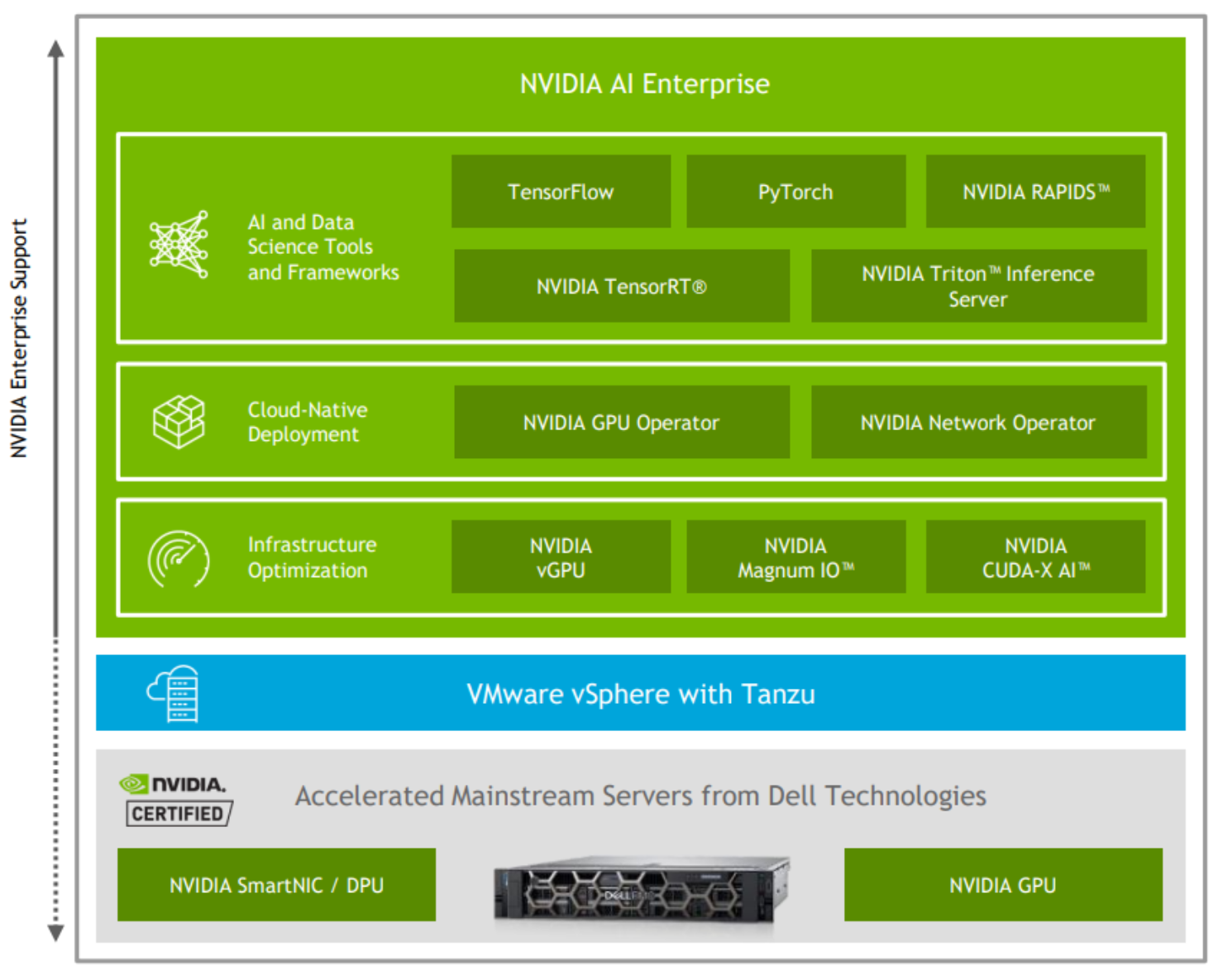
Figure 2. NVIDIA AI Enterprise—a comprehensive AI suite
NVIDIA AI Enterprise includes key enabling technologies and software from NVIDIA for rapid deployment, management, and scaling of AI workloads in the modern hybrid cloud. NVIDIA licenses and supports NVIDIA AI Enterprise.
The software in the NVIDIA AI Enterprise suite is organized into the following layers:
- Infrastructure optimization software:
- NVIDIA vGPU—NVIDIA vGPU software creates virtual GPUs that can be shared across multiple VMs enabling IT to use the management and security benefits of virtualization and the performance of NVIDIA GPUs.
- NVIDIA CUDA Toolkit—CUDA Toolkit includes GPU-accelerated libraries, debugging and optimization tools, a C/C++ compiler, and a runtime library to build and deploy your AI application.
- NVIDIA Magnum IO—Magnum IO stack contains the libraries that developers need to create and optimize applications IO across the entire stack, including:
- Networking across NVIDIA NVLink
- Ethernet
- InfinBand
- Storage APIs
- In-networking compute to accelerate multinode operations
- IO management of networking hardware
- Cloud-Native Deployment software, which is required for VMware Tanzu support:
- NVIDIA GPU Operator uses the operator framework in Kubernetes to automate the management of all NVIDIA software components needed to provision the GPU. These components include the NVIDIA drivers (to enable CUDA), the Kubernetes device plug-in for GPUs, the NVIDIA Container Runtime, automatic node labeling, DCGM-based monitoring, and others.
- NVIDIA Network Operator uses the operator framework in Kubernetes to manage networking-related components to enable fast networking, RDMA, and GPUDirect for workloads in a Kubernetes cluster. Network Operator works with GPU Operator to enable GPU-Direct RDMA on compatible systems.
- AI and data science frameworks that include the following validated containers on VMware vSphere:
- NVIDIA RAPIDS is an open-source machine learning framework. RAPIDS brings GPU optimization to problems traditionally solved by using tools such as Hadoop or Scikit-learn and pandas. RAPIDS is a useful tool for working with tabular and other data formats; it is also an essential tool for data preparation, data formatting, and data labeling. RAPIDS is a critical component to start any AI pipeline that requires data preprocessing.
- TensorFlow is an open-source framework for machine learning implemented in a combination of C++ and NVIDIA CUDA tools. First developed by Google, it has been a mainstream tool for deep learning since its debut in 2015. The provided TensorFlow container has full support for GPUs, as well as multi-GPU and multinode capabilities along with NVIDIA-tested GPU optimizations.
- PyTorch is an open-source Python Deep Learning Framework. Facebook created PyTorch, which like Tensorflow, is a leading AI framework. The PyTorch containers published through NVIDIA AI Enterprise include the software needed to run single GPU, multi-GPU, or multinode workloads.
- NVIDIA TensorRT converts models developed in frameworks such as TensorFlow and PyTorch by compiling them into a format optimized for inferencing on a specific runtime platform. When compiling a model with TensorRT, features including bit-precision optimizations, neural network graph optimizations, and automatic tuning result in a more performant model for inference. The performance benefits can be significant depending on the type of model being developed. Generally, models compiled with TensorRT take up less memory and perform inference tasks faster than the original format.
- NVIDIA Triton Inference Server is an open-source model serving software that simplifies the deployment of production AI models at scale. It lets teams deploy trained AI models from any framework, including optimized TensorRT models on any single GPU, multi-GPU, or CPU-based infrastructure. When models are retrained, IT staff can easily deploy the updates without restarting the inference server or disrupting the calling application. Triton supports multiple inferencing types including real-time, batch, and streaming. It also supports efficient model ensembles if your pipeline has multiple models that share inputs and outputs, such as in conversational AI.
Licensing and enterprise support
NVIDIA AI Enterprise is licensed per CPU socket and can be purchased through Dell Software & Peripherals. You can purchase NVIDIA AI Enterprise products either as a perpetual license with support services or as an annual or multiyear subscription. The perpetual license provides the right to use the NVIDIA AI Enterprise software indefinitely, with no expiration. You must purchase NVIDIA AI Enterprise with perpetual licenses with one-year, three-year, or five-year support services. A one-year support service is also available for renewals. For more information, see the NVIDIA AI Enterprise Packaging, Pricing, and Licensing Guide.
NVIDIA Support Services for the NVIDIA AI Enterprise software suite provides seamless access to comprehensive software patches, updates, upgrades, and technical support.
NVIDIA Ampere GPU
The Tensor Core technology in the Ampere architecture has brought dramatic performance gains to AI workloads. Large-scale testing and customer case studies prove that Ampere GPUs that are based on Tensor Core can decrease training times significantly. Two types of Ampere GPUs are available for compute workloads:
- NVIDIA A100 GPU—This Tensor Core GPU can achieve massive acceleration for training workloads. IT professionals benefit from reduced operational complexity by using a single technology that is easy to onboard and manage for these use cases. The A100 GPU is a dual-slot 10.5-inch PCI Express (PCIe) Gen4 card that is based on the NVIDIA Ampere A100 GPU. It uses a passive heat sink for cooling. The A100 PCIe supports double precision (FP64), single precision (FP32), and half precision (FP16) compute tasks. It also supports unified virtual memory and a page migration engine.
- NVIDIA A30 GPU—This Tensor Core GPU is the most versatile mainstream compute GPU for AI inference and mainstream enterprise workloads. It supports a broad range of math precisions, providing a single accelerator to expedite every workload. Built for AI inference at scale, the same compute resource can rapidly retrain AI models with TF32, as well as accelerate high-performance computing (HPC) applications using FP64 Tensor Cores. MIG and FP64 Tensor Cores combine with fast 933 GB/s of memory bandwidth in a low 165 W power envelope, all running on a PCIe card that is optimal for mainstream servers.
A100 and A30 GPUs support the MIG feature, which allows administrators to partition a single GPU into multiple instances, each fully isolated with its own high-bandwidth memory, cache, and compute. The A100 PCIe card supports MIG configurations with up to seven GPU instances per A100 GPU, while the A30 GPU supports up to four GPU instances. For more information, see the section about virtual GPUs in the Virtualizing GPUs for AI with VMware and NVIDIA design guide.
ConnectX SmartNICs
The ConnectX-6 Dx SmartNIC is a secure and advanced cloud network interface card that accelerates mission-critical, data center applications, such as virtualization, SDN/NFV, big data, machine learning, network security, and storage. ConnectX-6 supports Remote Direct Memory Access (RDMA) over Converged Ethernet (RoCE), the network protocol required for multinode training with GPUDirect RDMA. In this validated design, we use ConnectX-6 Lx for 25 Gb/s Ethernet connectivity and optionally ConnectX-6 Dx for 100 Gb/s Ethernet connectivity.
NVIDIA-Certified Systems
To be successful with machine learning and AI initiatives, enterprises need a modern coherent computing infrastructure that provides functionality, performance, security, and scalability. Organizations also benefit when they can run both development and production workloads with common technology. With NVIDIA-Certified Systems from Dell Technologies, enterprises can confidently choose performance-optimized hardware that runs VMware and NVIDIA software solutions—all backed by enterprise-grade support.
Dell Technologies produces a range of PowerEdge servers that are qualified as NVIDIA-Certified Systems. NVIDIA-Certified Systems are shipped with NVIDIA Ampere architecture A100 and A30 Tensor Core GPUs and the latest NVIDIA Mellanox ConnectX-6 network adapters.
A subset of NVIDIA-Certified Systems goes through additional certification, including VMware GPU certification, to ensure compatibility with NVIDIA AI Enterprise. An NVIDIA-Certified System that is compatible with NVIDIA AI Enterprise conforms to NVIDIA design best practices and has passed certification tests that address a range of use cases on VMware vSphere infrastructure. These use cases include deep learning training, AI inference, data science algorithms, intelligent video analytics, security, and network and storage offload for both single-node and multinode clusters.