
Summary
Summary
-
With VMware vSphere support for virtualized GPUs, IT administrators can run AI workloads such as neural network training, inference, or model development along with their standard data center applications. The following figure shows the high-level architecture for this validated design with PowerEdge R760 servers, each with two NVIDIA A100 GPUs and a ConnectX network adapter, as part of a VMware vSphere cluster. The VMs with vGPU run containers from NVIDIA AI Enterprise. This validated design allows AI workloads to run either as VM or Kubernetes pods in Tanzu Kubernetes clusters.
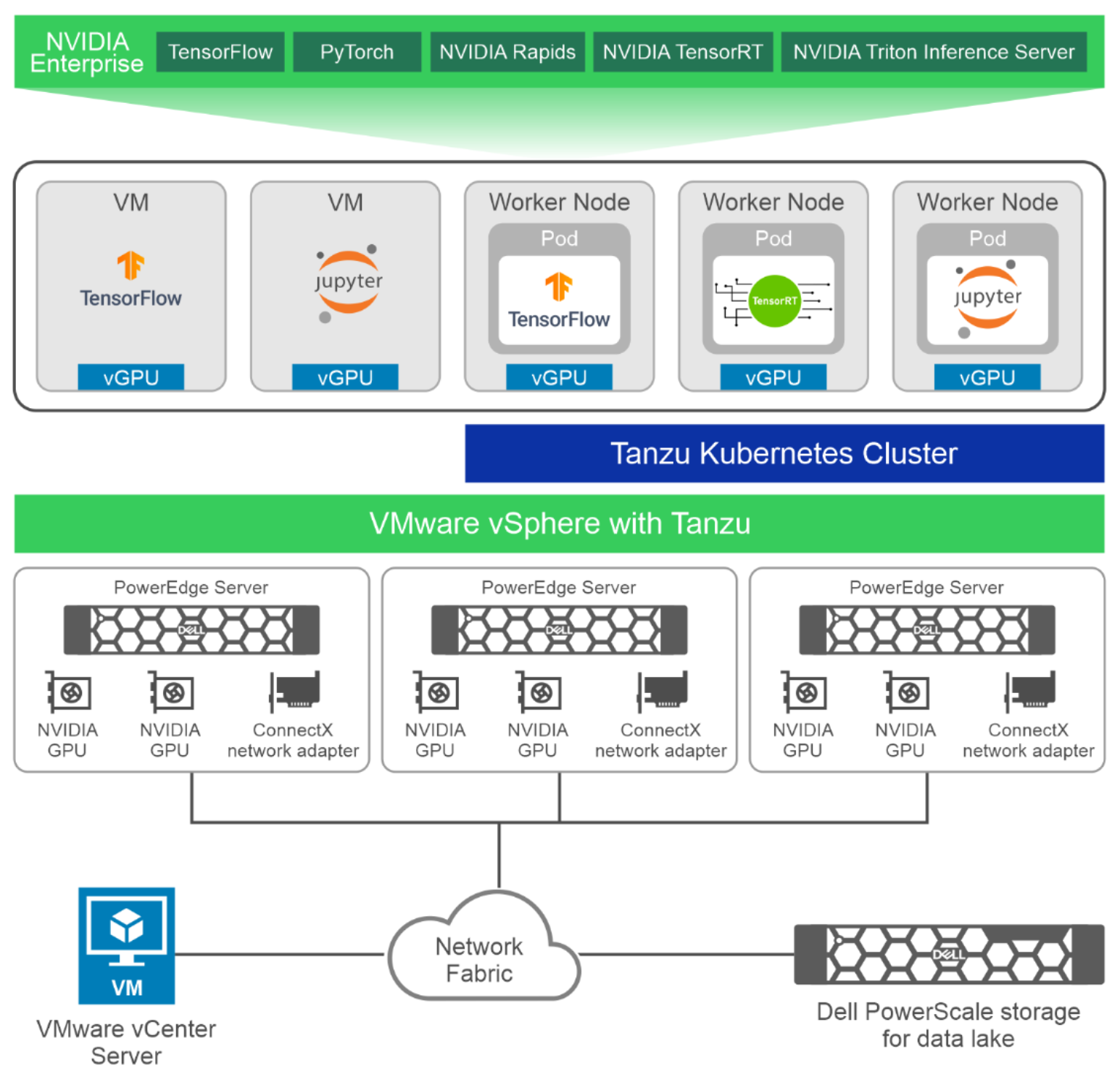
Figure 3. High-level architecture with PowerEdge R760 servers and PowerScale storage
Key aspects of this validated design include:
- Compute server—The PowerEdge R760 and R7625 servers are part of this validated design.
- GPUs—NVIDIA A100 and A30 GPUs can be used for AI and machine learning. We recommend the A100 GPU for large neural network training models that require high performance and the A30 GPU for AI inference and mainstream enterprise workloads. The number of GPUs supported in a server depends on the server model as shown in Table 2.
- Storage—vSAN is the recommended storage for VMs. We recommend PowerStore storage for data lake storage, that is, storing data that are required for neural network training. PowerScale storage can also be used both for storing data for AI workloads in an NFS partition.
- Network infrastructure—Customers can have either a 25 Gb Ethernet network infrastructure or a 100 Gb Ethernet network infrastructure. We recommend 25 GbE for workloads that can use existing network infrastructure without needing to invest in 100 Gb network infrastructure. This design is suited for neural network training jobs that can run on a single node (using at most two GPUs), and for model development and inference jobs that take advantage of GPU partitioning.
We recommend 100 GbE for workloads that require large-scale model training using large datasets (typically high-resolution video or image-based datasets).
- Virtualization and container orchestration—GPUs can be virtualized and made available to VMs running on VMware ESXi servers deployed on PowerEdge servers. For containerized workloads, Tanzu Kubernetes Grid service is enabled on vSphere cluster. Kubernetes worker nodes can be created with virtual GPU resources. AI workloads can be deployed as pods on deployment services running on Tanzu Kubernetes clusters.
- Management with VMware vCenter—VMware vCenter Server can be deployed as a VM in your data center. vCenter is critical to the deployment, operation, and maintenance of a vSAN environment. For this reason, Dell Technologies recommends that vCenter be deployed on a highly available management cluster, which exists outside of the compute cluster.
For more information about the validated design, including detailed recommended configurations, design considerations, and deployment overview, see the Virtualizing GPUs for AI with VMware and NVIDIA design guide.