A Linux Foundation project since 2019, Delta Lake by the Linux Foundation is an independent project controlled by a development community rather than any single technology vendor. The Dell Validated Design for Analytics — Modern Data Stack enables reliable deployment and operation of Delta Lake in the solution. More than 150 developers from over 50 different organizations associated with Delta Lake working on multiple storage repositories are all engaged daily to help push the program goals forward. Key Delta Lake capabilities include:
- ACID transactions—Ensure data consistency and reliability and isolating it at the strongest isolation level, the serializable level.
- Time travel and data versioning—Each data write to a Delta table creates a version number. This feature enables users to query a Delta Lake table as of a specific time. Users can view and revert to previous versions of the data using a timestamp or a version number.
- Scalable metadata—Leverages Spark’s distributed processing power to easily handle all the metadata for petabyte-scale tables with billions of files.
- Schema evolution and enforcement—Perform automatic schema validation by checking against a set of rules to determine the compatibility of a write from a DataFrame to a table.
- DML operations—Support Data Manipulation Language (DML) operations like updates, deletes, and merges by using transaction logs. They enable easy handling of complex use cases like change-data-capture, slowly changing dimension (SCD) operations and streaming upserts.
Delta Lake 3.0 is the latest major release of the Linux Foundation open-source Delta Lake project, announced on June 28, 2023. This release introduces powerful features such as:
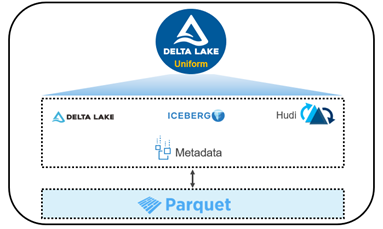
- Delta Universal Format (UniForm)—Enables reading Delta in the format needed by the application, improving compatibility and expanding the ecosystem. Delta will automatically generate metadata needed for Apache Iceberg or Apache Hudi, so users do not have to choose or do manual conversions between formats. With UniForm, Delta is the universal format that works across ecosystems.
- Delta Kernel—Simplifies building Delta connectors by providing simple, narrow programmatic APIs that hide all the complex details of the Delta protocol specification.
- Delta Liquid Clustering—Simplifies getting the best query performance with cost-efficient clustering as the data grows.
Delta UniForm automatically unifies table formats without creating additional copies of data by incrementally generating a layer of metadata to spec for Hudi, Iceberg, and Delta. Data users who use query engines designed to work with Iceberg or Hudi data can read Delta tables without copying or converting it. Delta Lake 3.0 shows the concept of Delta Lake with UniForm.