Apache Iceberg is a new open-source, high-performance data table format designed for large-scale data platforms. Its primary goal is to bring the reliability and simplicity of SQL tables to big data while providing a scalable and efficient way to store and manage data. This performance is especially important in the context of big data workloads. Iceberg makes it possible for engines such as Spark, Trino, Flink, Presto, Hive, and Impala to safely work with the same tables, simultaneously. It addresses some of the limitations of traditional data storage formats such as Apache Parquet and ORC.
Some key Apache Iceberg features and concepts include:
- ACID transactions—Iceberg tables guarantee atomic, consistent, isolated, and durable (ACID) transactions for write operations, ensuring data integrity.
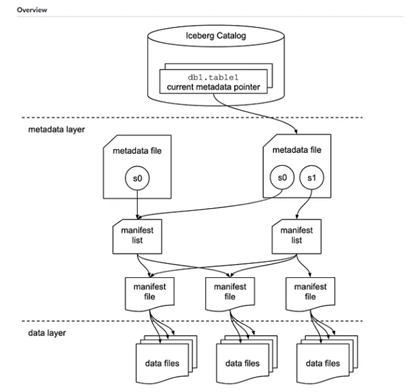
- Catalog—A mechanism that houses metadata pointers for Iceberg tables.
- Table metadata—Maintains comprehensive metadata information about tables, including schema details, partitioning information, and datafile locations. The metadata layer consists of three categories:
- Metadata files that define the table
- Manifest lists that define a snapshot of the table
- Manifests that define groups of datafiles that may be part of one or more snapshots
- Time travel—Supports the ability to query data at different points in time, enabling historical analysis and data rollback to specific versions.
- Schema evolution—Enables schema evolution by adding, renaming, or deleting columns without requiring expensive and time-consuming data migrations.
- Partitioning—Enables data to be partitioned into logical segments based on specific columns, such as date or region. Partitioning helps improve query performance by enabling efficient data pruning and reducing the amount of data scanned during queries.
Apache Iceberg table architecture depicts the Iceberg table architecture.