
SQL Server Big Data Clusters
SQL Server Big Data Clusters
-
SQL Server and similar databases were designed primarily for online transaction processing (OLTP) and are scale-up systems. In a scale-up system, performance benefits come from adding more compute and memory resources in the host server or migrating to a larger server. In contrast, a scale-out database system is designed to use multiple networked servers with storage to distribute data and data processing across a cluster. Scale-out systems are designed to manage big data challenges that do not work well through the traditional scale-up systems approach.
With SQL Server 2019, Microsoft now offers an option for hosting scale-out database services. SQL Server 2019 Big Data Clusters is a new scale-out big data solution that combines SQL Server, Spark, and HDFS across a cluster of servers. The SQL Server master instance coordinates connectivity, scale-out query management, metadata, and machine learning. The master instance is a fully functional SQL Server instance and a Tabular Data Stream (TDS) endpoint that provides application-level protocol that is used by tools such as Azure Data Studio and SQL Server Management Studio.
The master instance contains the scale-out query engine that pushes computations to the compute pool. In Big Data Clusters, the compute pool processes the query across the SQL Server instances. This parallelization enables faster reading of large datasets, thus saving time in returning the results. Management of scale-out queries and other metadata is maintained in the master instance.
Metadata in the master instance includes:
- A metadata database with HDFS-table metadata
- A data plan shard map
- Details of external tables that provide access to the cluster data plane
- PolyBase external data sources and external tables defined in user databases
Beyond the SQL engine and Big Data Cluster management, SQL Server 2019 integrates additional services such as machine learning. Machine learning is the capability to use data in developing models. For example, using machine learning, a model can be created to define the difference between legitimate email and spam. Such a model can then be used to improve email services by removing most spam from a user’s inbox.
Machine Learning Services is an add-on feature to the master instance. The feature is installed by default and enables developers to use Java, R, and Python code in SQL Server. This capability provides a pathway for data scientists to use Spark and HDFS tools with the SQL Server master instance, as shown in the following figure:
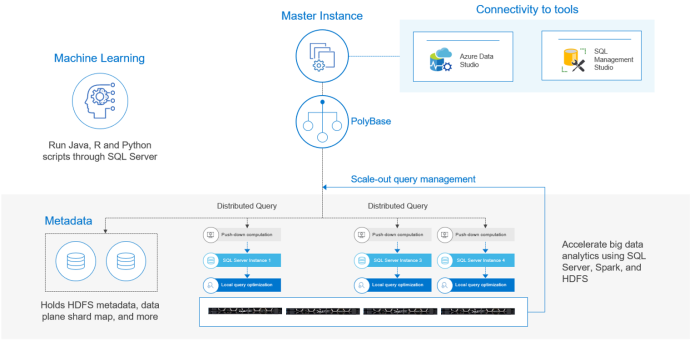
Figure 3. Machine Learning Services installed on SQL Server master instance
Apache Spark services are also available in SQL Server 2019. Spark is a general-purpose cluster computing system that is designed for performance. Through APIs, Spark supports a broad set of programming languages such as Java, Scala, Python, and R. Spark uses Hadoop’s client libraries for accessing HDFS data nodes, meaning Spark was designed to use HDFS storage. Spark provides the ability within Big Data Clusters to perform machine learning (MLib), graph processing (GraphX), and Spark Streaming. As an option, customers can separate the Spark services to create a dedicated Spark pool. A dedicated Spark pool can be beneficial if customers plan to extensively use Spark services.
In addition to the master instance, SQL Server 2019 Big Data Clusters include several scale-out services. For example, compute pools enable offloading distributed query processing to a dedicated scale-out service. In our lab setup, the Big Data Cluster compute pool has one or more SQL Server compute instances running in containers across each of the PowerFlex rack nodes. Other examples of how the compute pool accelerates data processing include:
- Query joins combine data from two objects in the database or from external data sources. With query joins, you can:
- Join HDFS directories with thousands of files.
- Join tables in different data resources.
- Join tables with different partitioning or data distribution schemes.
- Data exports move data out of an application in parallel to HDFS or Azure Blob storage.
The following figure shows the compute pool configuration:
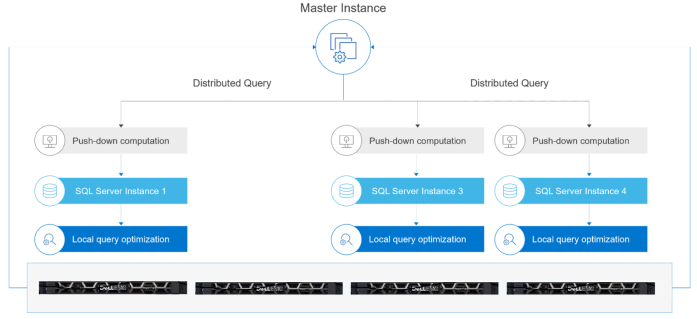
Figure 4. Compute pool configuration
A SQL 2019 Big Data Cluster storage pool is a group of pods hosting the following services: SQL Server engine, HDFS data node, and Spark. The HDFS data node stores and replicates data across all nodes in the storage pool. Because HDFS replicates data in most architectures, RAID is not needed. The HDFS storage node manages all read and write operations to the node.
The SQL Server engine can natively access the HDFS data nodes, providing the capability to use T-SQL with Big Data Clusters. Thus, the organization can use existing T‑SQL reports and fully benefit from developer experience with T-SQL; developers do not have to learn a new programming language. The following figure shows the storage pool architecture as provisioned by Kubernetes in pods:
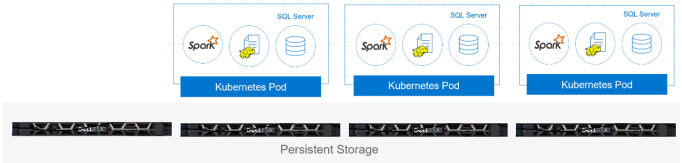
Figure 5. Storage pool architecture
A SQL Server 2019 Big Data Cluster data pool has one or more SQL Server instances and is used to ingest data from external sources. The data pool is managed from the SQL Server master instance using Data Definition Language (DDL) to manage the database and its objects and Data Manipulation Language (DML) for data management. The primary use of the data pool is to offload data processing activities from the SQL Server master instance. The data pool can accelerate data processing because it uses data sharding (partitioning) across the SQL Server instances in the pool. Database shards are data that is distributed in separate containers across multiple database instances residing on separate servers. Most of the data is not duplicated or replicated, meaning that each shard holds a single source of data. Sharding improves performance by enabling multiple data reads in parallel across multiple database instances, thus reducing the time that is required to complete a query.