
Microsoft SQL Server 2019 Big Data Clusters: A Big Data Solution Using Dell EMC Infrastructure
SQL Server Big Data Cluster components
SQL Server Big Data Cluster components
-
SQL Server Big Data Clusters consist of the following planes for component aggregation:
- Control plane—This plane consists of SQL master instances along with monitoring and logging components. It also hosts other shared components such as Hive, SQL Proxy, and so on.
- Compute plane—This plane consists of SQL Server instances to offload compute workload from a SQL master instance. This plane does not store any user data.
- Data plane—This plane consists of a SQL Server instance that hosts user data so that the master instance can offload any data (tables with full data or intermediate data) to this plane. This plane also hosts semi-structured and nonstructured data.
Our design distributes the SQL Server Big Data Cluster components across dedicated worker nodes in the Kubernetes cluster, as shown in the following figure. This distribution enables better performance and improved workload segregation:
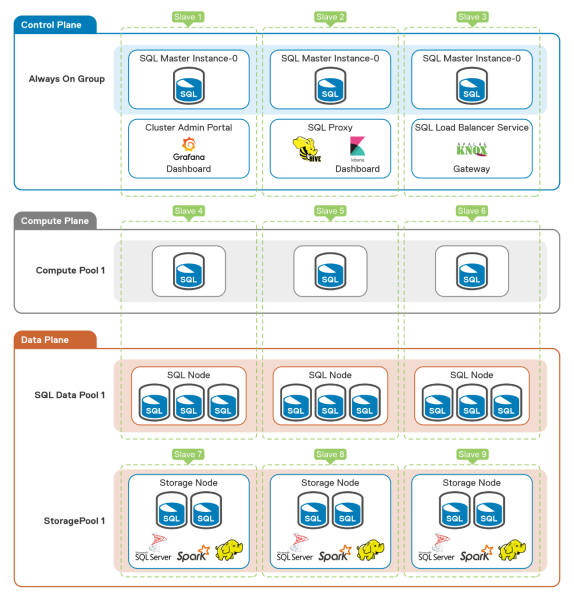
Figure 19. Distribution of Big Data Cluster components
Apart from component-aggregating planes, the SQL Server Big Data Cluster also has multiple pools:
- Compute pool—SQL Server instances to offload compute workloads from master instances.
- Data pool—SQL Server instances to offload data from master instances.
- Storage pool—SQL server instance, Spark components, and HDFS components to store and process structured, nonstructured, or semi-structured data.
The following separate pools also are part of SQL Server Big Data Cluster deployments; however, they are not in Figure 19 because we are not using them exclusively in our validation scenarios:
- App pool—Any application container that is directly inside SQL Server Big Data Cluster
- Spark pool—Spark components (segregated from the storage pool)