
Virtual GPU
Virtual GPU
-
Resource requirements for AI workloads can vary widely depending on the nature of the workload. A neural network training job might require the allocation of many GPU resources to converge in a reasonable time, while inference and model experimentation might not be able to use the resources of a single modern GPU. New technologies from NVIDIA and VMware enable IT administrators to partition a GPU into multiple virtual GPUs while securely allocating the correctly sized partition to different VMs. For more flexibility when dealing with large training jobs, IT administrators can also aggregate multiple GPU resources into a single VM.
GPU partitioning using MIG technology
The new Multi-Instance GPU (MIG) feature for GPUs was designed to support robust hardware partitioning for the latest NVIDIA A100 and A30 GPUs. NVIDIA MIG-enabled GPUs plus NVIDIA vGPU software allow enterprises to use the management, monitoring, and operational benefits of VMware virtualization for all resources including AI acceleration.
VMware VMs using MIG-enabled vGPUs provide the flexibility to have a heterogenous mix of GPU partition sizes available on a single host or cluster. MIG-partitioned vGPU instances are fully isolated with an exclusive allocation of high-bandwidth memory, cache, and compute. The A100 PCIe card supports MIG configurations with up to seven GPU partitions per GPU card, while the A30 GPU supports up to four GPU instances per card.
MIG allows multiple vGPU-powered VMs to run in parallel on a single A100 or A30 GPU. One common use case is for administrators to partition available GPUs into multiple units for allocation to individual data scientists. Each data scientist can be assured of predictable performance due to the isolation and Quality of Service guarantees of the vGPU partitioning technology.
The following table lists the options for MIG-supported GPU partitions:
Table 2. GPU profiles for the A100 and A30 GPU
GPU
GPU profile name
Profile name on VMs
Fraction of GPU memory
Fraction of GPU computes
Maximum number of instances available
A100 80GB
MIG 1g.10gb
grid_a100-1-10c
1/8
1/7
7
MIG 2g.20gb
grid_a100-2-20c
2/8
2/7
3
MIG 3g.40gb
grid_a100-3-40c
4/8
3/7
2
MIG 4g.40gb
grid_a100-4-40c
4/8
4/7
1
MIG 7g.80gb
grid_a100-7-80c
8/8
7/7
1
A30 24GB
MIG 1g.6gb
grid_a30-1-6c
1/4
1/4
4
MIG 2g.12gb
grid_a30-2-12c
2/4
2/4
2
MIG 4g.24gb
grid_a30-4-24c
4/4
4/4
1
You can create and assign a combination of the preceding profiles to VMs. Only certain combinations of MIG partitions are supported for a single card instance. For more information about MIG and the supported partition details, see the NVIDIA Multi-Instance GPU User Guide.
When a VM is created, an administrator can assign one of the partitions in the preceding table before powering on the VM. A GPU resource is then exclusively allocated to a single VM, guaranteeing isolation of GPU resources. MIG only supports assigning one partition profile type per VM. The GPU resources are deallocated when the VM is powered off or migrated to another server.
The following figure shows an example of how MIG partitions are allocated to VMs:
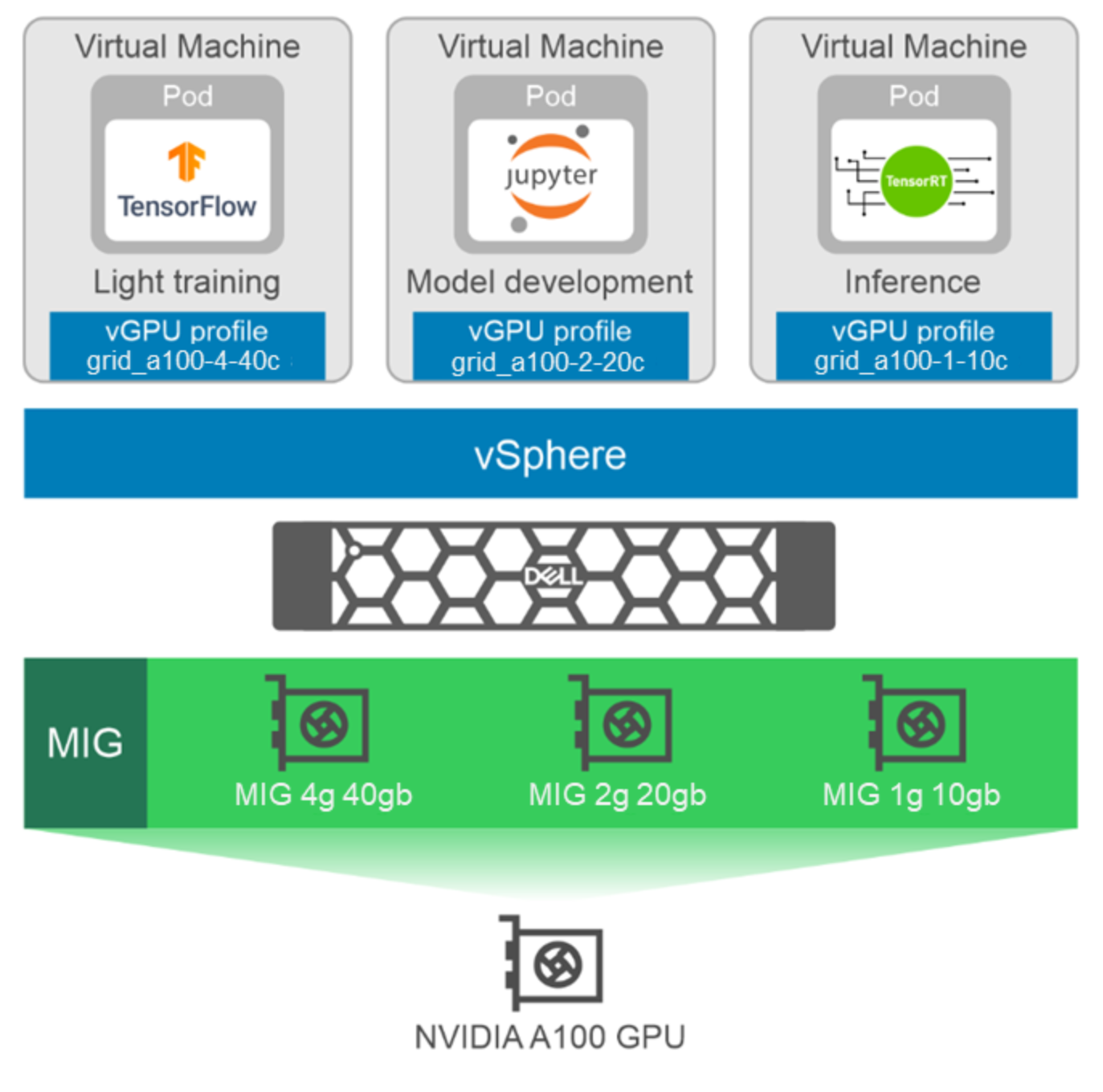
Figure 1. MIG partitioning and virtualization
The preceding figure shows an A100 GPU partitioned into three compatible MIG profiles: MIG 4g.40gb, MIG 2g.20gb, and MIG 1g.10gb. These profiles are typically assigned to run light training using TensorFlow, model development using Jupyter notebooks, and inference using TensorRT.
Non-MIG mode partitioning using software temporal partitioning
When the NVIDIA GPUs are in non-MIG mode, NVIDIA vGPU software uses temporal partitioning and GPU time slice scheduling. With temporal partitioning, VMs have shared access to compute resources that can be beneficial for certain workloads. The workloads running on time-sliced vGPUs on a common GPU share access to all GPU engines including the engines for graphics (3D), video decode, and video encode.
Time-sliced vGPU processes are scheduled to run periodically depending on the number of currently running workloads. Each workload running on a vGPU waits in a queue while other processes have access to the GPU resources in the same way that multiuser operating systems share CPU resources. While a process is running on a vGPU, it has exclusive use of the GPU's engines.
The following table compares MIG and temporal partitioning:
Table 3. MIG and temporal partitioning comparison
Component
GPU partitioning through MIG
GPU partitioning using software temporal partitioning
GPU partitioning
Spatial (hardware)
Temporal (software)
Compute resources
Dedicated
Shared
Compute instance partitioning
Yes
No
Address space isolation
Yes
Yes
Fault tolerance
Yes (highest quality)
Yes
Low latency response
Yes (highest quality)
Yes
NVLink support
No
Yes
Multitenant
Yes
Yes
GPUDirect RDMA
Yes (GPU instances)
Yes
Heterogeneous profiles
Yes
No
For more information about the differences between the two modes of partitioning, see the NVIDIA Multi-Instance GPU and NVIDIA Virtual Compute Server GPU Partitioning technical brief.