




Dell PowerProtect Hadoop Data Protection – a Modern and Cost-effective Solution for Big Data Apache Hadoop
Thu, 27 Jan 2022 19:10:36 -0000
|Read Time: 0 minutes
Big Data is no longer a buzzword. Over the past decade, big data and analytics have become the most reliable source of insight for businesses as they harness collective data to align strategy, help teams collaborate, uncover new opportunities, and compete in the global marketplace. The market size for business data analytics (BDA) was USD 206.95 billion in 2020 and USD 231.43 billion in 2021, according to Fortune Business Insights™ in its report, titled, “Big Data Analytics Market, 2021-2028”.
With big data analytics on the course to become the most mission critical enterprise application, enterprises are demanding a robust level of backup, recovery, and disaster recovery solutions for their big data environment, in particular Apache Hadoop®. Apache Hadoop is a clustered distributed system that is used to process massive amounts of data. It provides software and a framework for distributed storage and processing of big data, using various distributed processing models.
Some common mistakes that make data protection challenging in Apache Hadoop:
- Because Apache Hadoop has 3X replication by default, many administrators do not plan to back up the data again.
- A very common misconception is that Apache Hadoop is just a repository for data that resides in existing data warehouses or transactional systems, so the data can be reloaded.
- Data is unstructured and often huge in size and it takes a very long time for backups to complete.
- Administrators mistakenly believe that Apache Hadoop is missing built-in technologies such as replication and mirroring with Apache Falcon, distcp, HBase, and Hive Replication.
Why do we need a dedicated Data Protection solution in Apache Hadoop aside from replication and in-built snapshots?
- Apache Hadoop infrastructure with 3x replication is a costly solution and long-time retention is not possible for huge volumes of data, so we need a cost-effective solution that can save multiple copies of important data.
- Social media data, ML models, logs, third-party feeds, open APIs, IoT data, banking transactions, and other sources of data may not be reloadable, easily available, or in the enterprise at all. So, this is critical single-source data that must be backed up and stored forever for meeting internal or legal compliance requirements for RPO and RTO.
- Synchronously replicating data will negatively impact application performance. Synchronous replication will also intercept all writes to the file system. This can destabilize the production system and requires extensive testing prior to putting it into production.
- Some natural disaster that takes out an entire data center, an extended power outage that makes the Apache Hadoop platform unavailable, a DBA accidentally dropping an entire database, an application bug corrupting data stored on HDFS, or worse: a cyberattack such as ransomware.
Overview of Dell PowerProtect Hadoop Data Protection
Dell Technologies has developed a Hadoop File System driver for PowerProtect DD series appliances that allows Hadoop data management functions to transparently use DD series appliances for the efficient storage and retrieval of data. This driver is called DD Hadoop Compatible File System (DDHCFS).
DDHCFS is the Hadoop-compatible file system that is used by DD series appliances. It provides versioned backups and recoveries of the Hadoop Distributed File System (HDFS) by using DD snapshots. It provides source-level deduplication and direct backups to DD series appliances. DDHCFS can also distribute backup-and-restore streams across all HDFS DataNodes, making backups and restores faster. It can also be integrated with Kerberos and Hadoop local credentials.
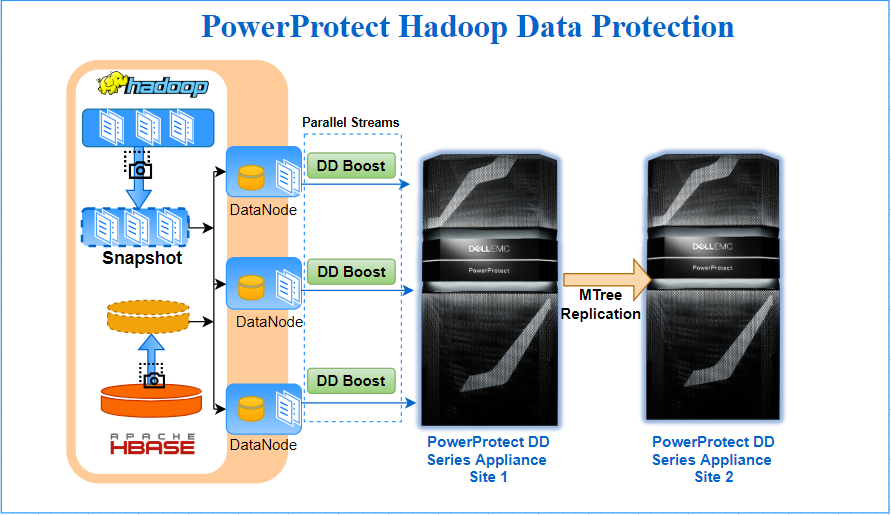
PowerProtect Hadoop Data Protection requires minimal configuration and installs only on the one node of the Hadoop Cluster. It is tightly integrated into the Hadoop file system, and leverages Hadoop’s scale-out distributed processing architecture to parallelize data transfer from Hadoop to the PowerProtect DD series appliance. DD Boost provides a network-efficient data transfer with client-side deduplication, while PowerProtect DD provides storage efficiency through deduplication and compression. Together this makes it the most efficient method of moving large amounts of data from a Hadoop cluster to a PowerProtect DD series appliance. Internally standard Hadoop constructs like Distributed File Copy & HDFS/HBase snapshots are leveraged to accomplish backup tasks.
Some highlights of the PowerProtect Hadoop Data protection solution for Hadoop environments are:
- True point-in-time backup and recovery of HDFS data to the PowerProtect DD series appliance
- Full backups at the low cost of incremental (synthetic full) – incremental forever
- Flexible Licensing (included in the PowerProtect and DP Suite license)
- Bandwidth efficiency of DD Boost sends only unique data over the network
- Capacity savings of up to 70% by means of global deduplication and compression on DD series appliances
- Source level deduplication and load balancing via DDBoost interface group
- HDFS integration transparently works through the three way storage redundancy to back up one consistent copy of the data
- Uses standard Hadoop constructs (such as MapReduce and distcp) to spawn distributed DD Boost agents to parallelize data transfer to PowerProtect DD series appliances
- Self-service, script-based backup, restores, and listing. Every Hadoop administrator can readily use these commands and incorporate them into other workflows
- Backup operations can be further scheduled and automated by Oozie
- Audit log of configuration changes and backup monitoring
Conclusion
PowerProtect Hadoop Data Protection, which is part of the Dell Data Protection Suite Family, provides complete Hadoop data protection. Apache Hadoop customers further benefit from PowerProtect DD series appliances when using the power of DD Boost, with strong backup performance, reduced bandwidth requirements, and improved load balancing and reliability.
The PowerProtect DD series appliances’s Data Invulnerability Architecture provides outstanding data protection, ensuring that data from your Hadoop cluster can be recovered when needed and the data can be trusted. It provides storage efficiency through variable-length deduplication and compression, typically reducing storage requirements by 10-30x[1].
Throughput with DD Boost technology can scale from 7TB/hr on the DD3300 to 94TB/hr on the DD9900. What makes DD Boost special is the deduplication taking place at the source client: only unique data is sent through the network to the PowerProtect DD systems. According to IDC, PowerProtect DD is the #1 product in the Purpose Built Backup Appliance (PBBA) market[2].
If you are already using PowerProtect DD series appliances for other data protection needs, you can leverage the same processes and expertise to protect your big data Hadoop environment.
Author: Sonali Dwivedi LinkedIn
[1] Based on Dell internal testing, January 2020. https://www.delltechnologies.com/en-ca/data-protection/powerprotect-backup-appliances.htm#overlay=//www.dellemc.com/en-ca/collaterals/unauth/analyst-reports/products/data-protection/esg-techreview-next-generation-performance-with-powerprotect.pdf.
[2] Based on IDC WW Purpose-Built Backup Appliance Systems Tracker, 1Q21 (revenue), June 2021.