




Running LLMs on Dell PowerEdge Servers with Intel® 4th Generation Xeon® CPUs


Introduction
Large-language Models (LLMs) have gained great industrial and academic interests in recent years. Different LLMs have been adopted in various applications, such as content generation, text summarization, sentiment analysis, and healthcare. The list goes on.
When we think about LLMs and what methodologies we can use for inferencing and fine-tuning, the question always comes up as to which compute device we should use. For inferencing, we wanted to explore what the performance metrics are when running on an Intel 4th Generation CPU, and what are some of the variables we should explore?
This blog focuses on LLM inference results on Dell PowerEdge Servers with the 4th Generation Intel® Xeon® Scalable Processors. Specifically, we demonstrated their performance and power while running the stable diffusion and Llama2 chat models on R760 and HS5610 servers. We also explored the performance and power impacts with different quantization bits and CPU/socket numbers through experiments and will present the inference results of stable diffusion and Llama2 models obtained on a Dell PowerEdge R760 and HS5610 with the 4th Generation Intel® Xeon® Scalable Processors.
We selected the aforementioned Dell platforms because we wanted to explore how our CSP-focused platforms like HS5610 perform when it comes to inferencing and whether they can meet the requirements for LLM models. These new Intel® Xeon® processors use an Intel AMX® matrix multiplication engine in each core to boost overall inferencing performance. By combining with the quantization techniques, we further improved the inference performance with the CPU-only system. Moreover, we also show how the CPU core and socket numbers affect the performance results.
Background
Transformer is regarded as the 4th fundamental model after Multilayer Perceptron (MLP), Recurrent Neural Networks (RNN), and Convolutional Neural Networks (CNN). Known for its parallelization and scalability, transformer has greatly boosted the performance and capability of LLMs since it was introduced in 2017 [1].
Today, LLMs have been rapidly adopted in various applications like content generation, text summarization, sentiment analysis, code generation, healthcare, and so on, as shown in Figure 1 [2]. This trend is continuing. More open-source LLMs are popping up almost on a monthly basis. Moreover, the transformer-based techniques are being used alongside with other methods, greatly improving the accuracy and performance of the original tasks. For example, the stable diffusion model uses the LLM at the input as the neural language understanding engine. Combined with the diffusion model, it has greatly improved the quality and throughput of the text-to-image generation task [3]. Note that for simplicity in this blog, we use the term “LLMs” to represent both those transformer-based models shown in Figure 1 and the derivative models like stable diffusion models.
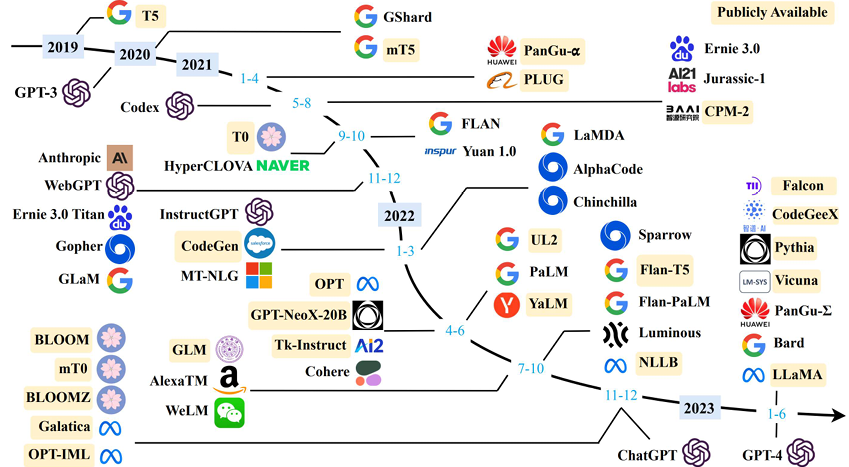
Figure 1. LLM Timeline [2] Image credit: Wayne Xin Zhao, et.al, “A Survey of Large Language Models”]
While training and fine-tuning those LLMs is normally time- and cost-consuming, deploying the LLMs at the edge has its own challenges. Considering both performance and power, deploying the LLMs can be, in a sense, more cost-sensitive given the volumes of the systems required to cover various applications. GPUs are widely used to deploy LLMs. In this blog, we demonstrate the feasibility of deploying those LLMs with Intel 4th generation Intel® Xeon® CPUs with Dell PowerEdge servers and illustrate that good performance can be achieved with a proper hardware configuration – like CPU core numbers and quantization method for popular LLMs.
Test Setup
The hardware platforms we used for the experiments are PowerEdge R760 and HS5610, which are the latest mainstream and cloud-optimized servers respectively from Dell product portfolio. Figure 2 shows the rack-level interface for the HS5610 server. As a cloud-optimized solution, the HS5610 server has been designed with CSP features that allow the same benefits with full PowerEdge features and management like the mainstream server R760, as well as open management (OpenBMC), cold aisle service, channel firmware, and services. Both servers have two sockets with an Intel 4th generation Xeon CPU on each socket. R760 features a 56-core CPU – Intel® Xeon® Platinum 8480+ (TDP: 350W) in each socket, and HS5610 has a 32-core CPU – Intel® Xeon® Gold 6430 (TDP: 250W) in each socket. Tables 1-4 show the details of the server configurations and CPU specifications. During tests, we use the numactl command to set the numbers of the sockets or CPU cores to execute the LLM inference tasks.
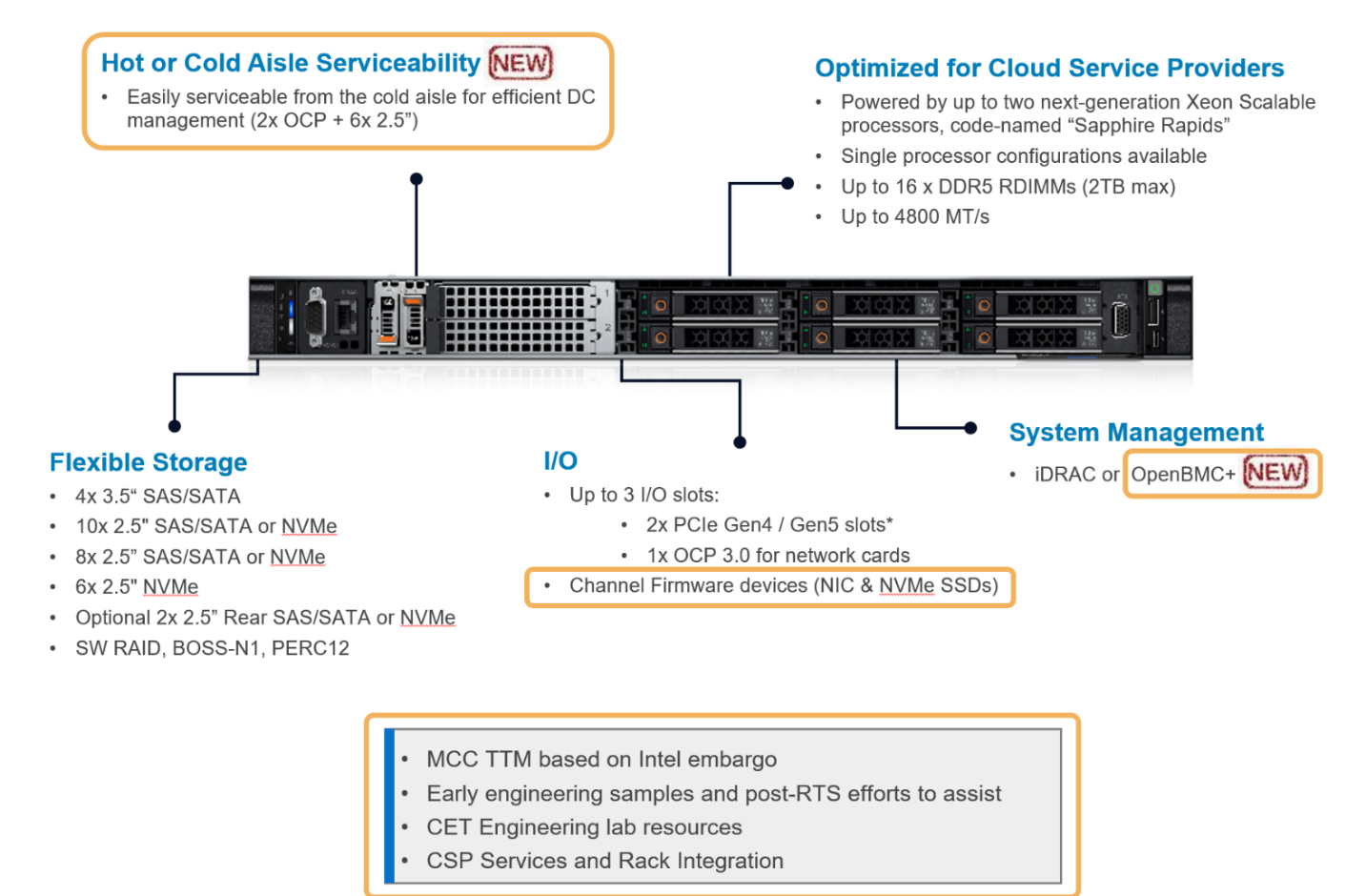
Figure 2. PowerEdge HS5610 [4]
System Name | PowerEdge R760 |
Status | Available |
System Type | Data Center |
Number of Nodes | 1 |
Host Processor Model | 4th Generation Intel® Xeon® Scalable Processors |
Host Processors per Node | 2 |
Host Processor Core Count | 56 |
Host Processor Frequency | 2.0 GHz, 3.8 GHz Turbo Boost |
Host Memory Capacity | 1TB, 16 x 64GB DIMM 4800 MHz |
Host Storage Capacity | 4.8 TB, NVME |
Table 1. R760 Server Configuration
Product Collection | 4th Generation Intel® Xeon® Scalable Processors |
Processor Name | Platinum 8480+ |
Status | Launched |
# of CPU Cores | 56 |
# of Threads | 112 |
Base Frequency | 2.0 GHz |
Max Turbo Speed | 3.8 GHz |
Cache L3 | 108 MB |
Memory Type | DDR5 4800 MT/s |
ECC Memory Supported | Yes |
Table 2. 4th Generation 56-core Intel® Xeon® Scalable Processor Technical Specifications
System Name | PowerEdge HS5610 |
Status | Available |
System Type | Data Center |
Number of Nodes | 1 |
Host Processor Model | 4th Generation Intel® Xeon® Scalable Processors |
Host Processors per Node | 2 |
Host Processor Core Count | 32 |
Host Processor Frequency | 2.0 GHz, 3.8 GHz Turbo Boost |
Host Memory Capacity | 1TB, 16 x 64GB DIMM 4800 MHz |
Host Storage Capacity | 4.8 TB, NVME |
Table 3. HS5610 Server Configuration
Product Collection | 4th Generation Intel® Xeon® Scalable Processors |
Processor Name | Gold 6430 |
Status | Launched |
# of CPU Cores | 32 |
# of Threads | 64 |
Base Frequency | 2.0 GHz |
Max Turbo Speed | 3.8 GHz |
Cache L3 | 64 MB |
Memory Type | DDR5 4800 MT/s |
ECC Memory Supported | Yes |
Table 4. 4th Generation 32-core Intel® Xeon® Scalable Processor Technical Specifications
Software stack and system configuration
The software stack and system configuration used for this submission is summarized in Table 5. Optimizations have been done for the PyTorch framework and Transformers library to unleash the Xeon CPU machine learning capabilities. Moreover, a low-level tool -- Intel® Neural Compressor -- has been used for high-accuracy quantization.
OS | CentOS Stream 8 (GNU/Linux x86_64) |
Intel® Optimized Inference SW | OneDNN™ Deep Learning, ONNX, Intel® Extension for PyTorch (IPEX), Intel® Extension for Transformers (ITREX), Intel® Neural Compressor |
ECC memory mode | ON |
Host memory configuration | 1TiB |
Turbo mode | ON |
CPU frequency governor | Performance |
Table 5. Software stack and system configuration
The models under testing are stable diffusion model version 1.4 (~1 billion parameters) and Llama2-chat-HF models with 7 billion, 13 billion, and 70 billion parameters. We purposely choose those models because they are open-sourced, representative, and cover a wide parameter range. Different quantization bits are tested to characterize the corresponding performance and power consumption.
All the experiments are based on batch-size equal to 1. Performance is characterized by latency or throughput. To reduce the measurement errors, the inference is executed 10 times to get the averaged value. A warm-up process is executed by loading the parameter and running a sample test before running the defined inference.
Results
We show some typical results in this section alongside brief discussions for each result. The conclusions are summarized in the next section.
HS5610 Results
Latency vs Quantization vs Cores – Stable Diffusion Model:
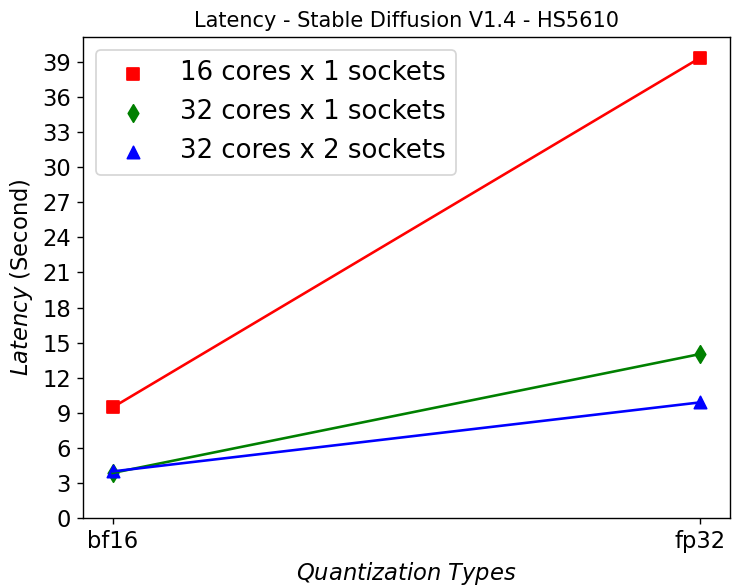
Figure 3. Latency in HS5610 server running Stable Diffusion
Figure 3 shows that HS5610 can generate a new image in approximately 3 seconds when running at bf16 Stable Diffusion V1.4 model. Quantizing to 16 bits greatly reduces the latency compared to using fp32 model. Scaling up the core numbers from 16 to 32 cores greatly reduces the latency, however scaling up across the sockets does not help. This is mainly due to the NUMA remote memory bottleneck.
Power Consumption – Stable Diffusion Model:
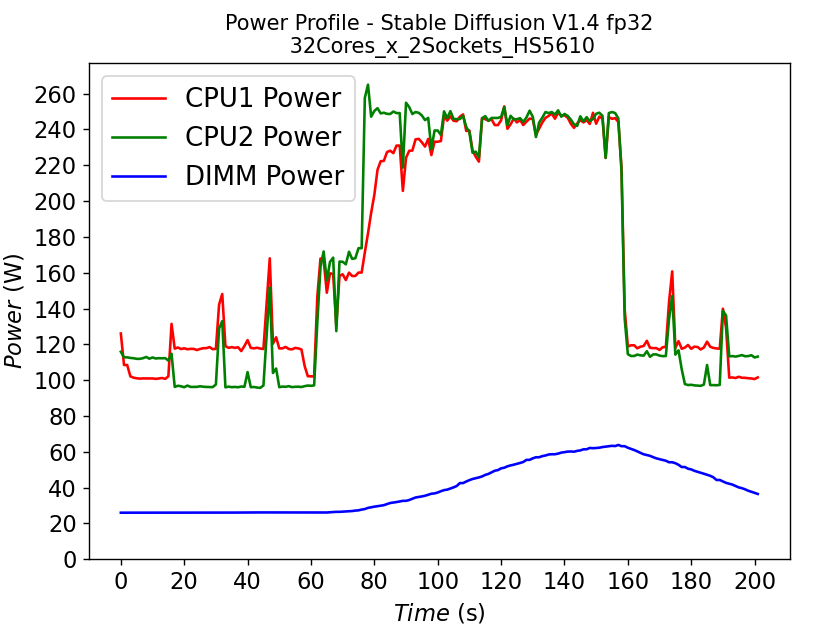 (a)
(a) 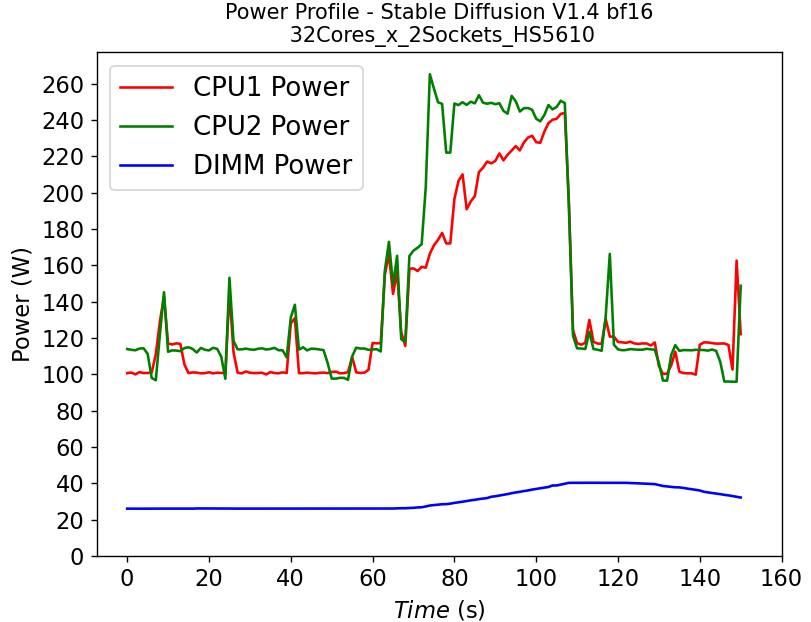 (b)
(b)
Figure 4. Power consumption of CPU and DIMM in HS5610 server running stable diffusion: (a) fp32 model (b) bf16 model
Figure 4 shows the power profile comparison of HS5610 when running the stable diffusion model with (a) fp32 weights and (b) bf16 weights. To finish the same tasks (warm up and inferencing), the bf16 model takes significantly less time (shorter power profile duration) compared to fp32 scenario. The plot also shows that much larger DIMM power is required to run fp32 compared to bf16. Executing the task pushes the CPU working close to the TDP limit, with the exception of the CPU1 in Figure 4b, indicating that further improvement is possible to further reduce the latency for the bf16 model.
Throughput vs Quantization vs Cores – Llama2 Chat Models:
 (a)
(a)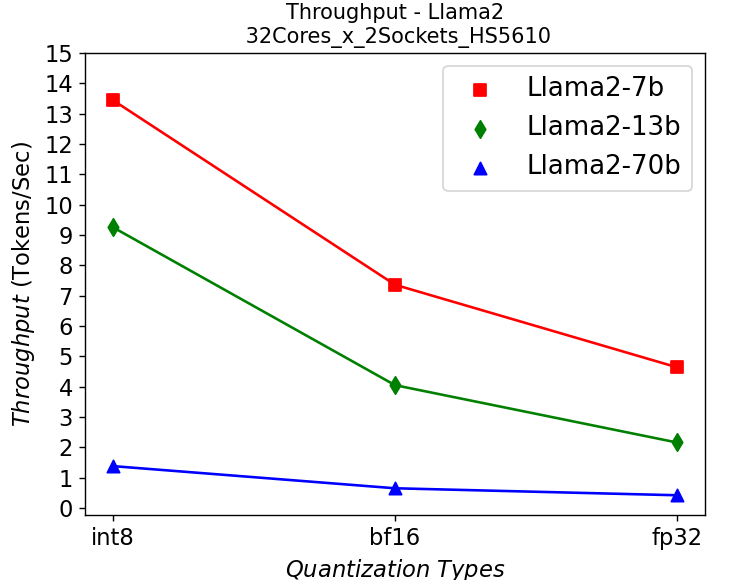 (b)
(b)
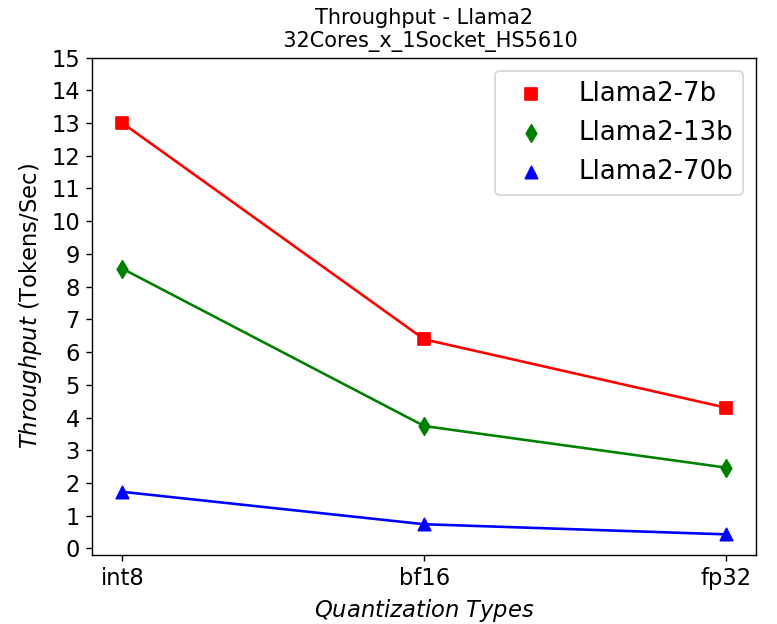
Figure 5. Throughput in HS5610 server running Llama2: (a) 1-socket (b) 2-socket
Figure 5 shows the throughput numbers when running Llama2 chat models with different parameter sizes and quantization bits in HS5610 server. Figure 5a shows the single socket scenario and 5b shows the dual-socket scenario. Smaller models with lower quantization bits give higher throughputs which is to be expected. Like the stable diffusion model, quantization greatly improves the throughput. However, scaling up with more CPU cores across the socket has negligible results in boosting the performance.
R760 Results
Throughput vs Quantization vs Cores – Llama2 Chat Models:
 (a)
(a)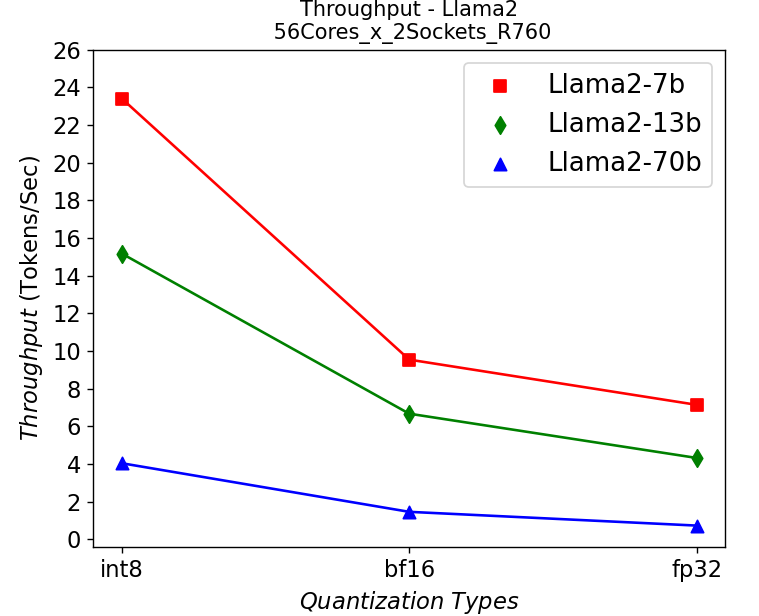 (b)
(b)
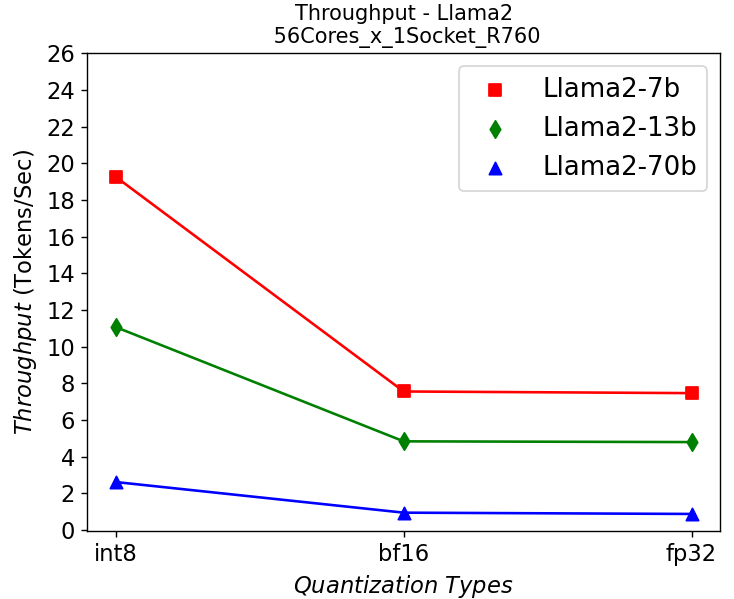
Figure 6. Throughput in R760 server running Llama2: (a) 1-socket (b) 2-socket
Figure 6 shows the throughput numbers when running Llama2 chat models with different parameter sizes and quantization bits in R760 server. We get similar observations as the results shown in HS5610 server. A smaller model gives a higher throughput, and quantization greatly improves the throughput. One difference is that we get a 10-30% performance improvement depending on models when scaling up across sockets, showing a benefit from larger core numbers. The performance across the models is good enough for most real-time chatbot applications.
Performance Per Watt – Llama2 Chat Models:
 (a)
(a)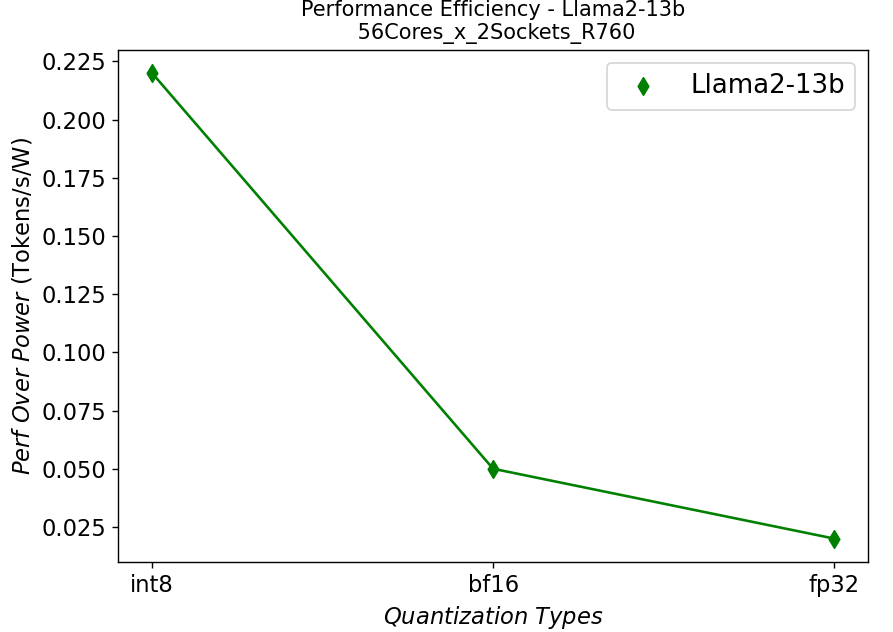 (b)
(b)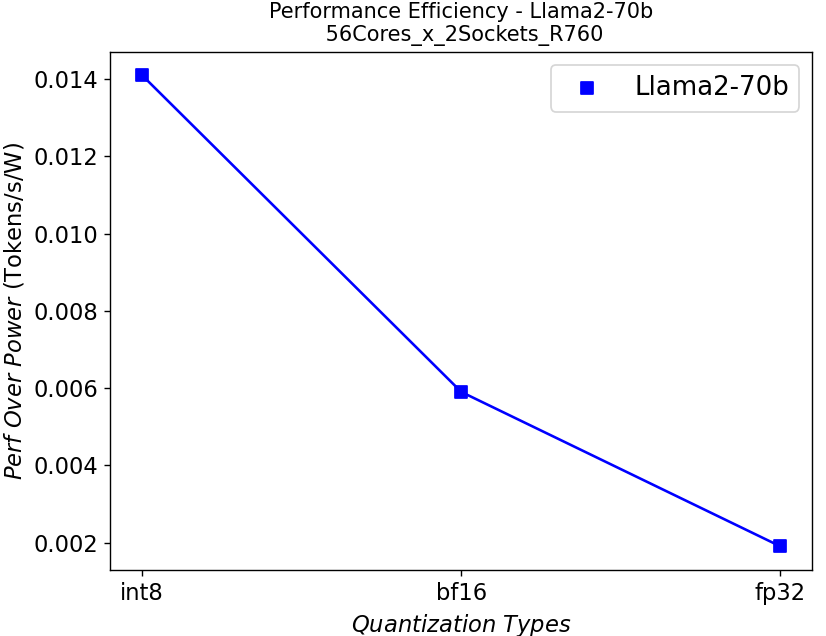 (c)
(c)
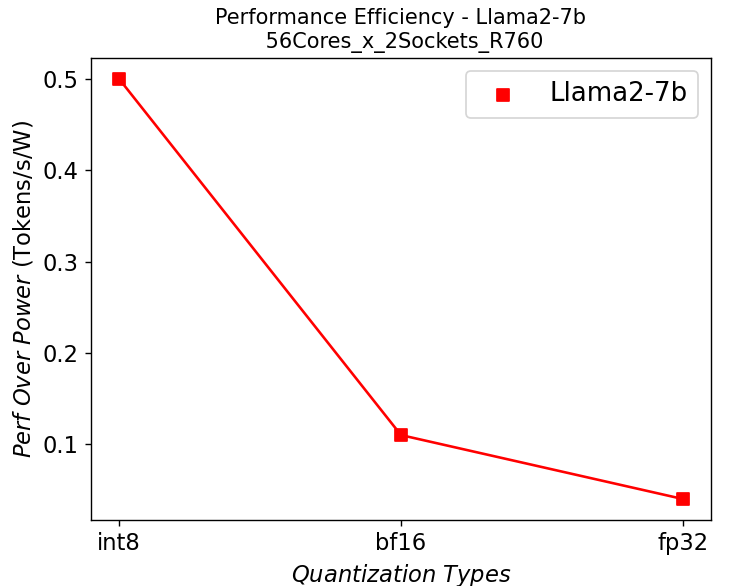
Figure 7. Performance per watt in R760 server running Llama2: (a) 7b (b)13b (c) 70b
We further plot the performance per watt curve which is strongly related to the total cost of ownership (TCO) of the system in Figure 7. From the plots, the quantization can greatly help with the performance efficiency, especially for the models with large parameters.
Conclusion
- We have shown that the Intel 4th generation Intel® Xeon® CPUs on Dell PowerEdge mainstream and HS class platforms can easily meet performance requirements when it comes to Inferencing with Llama2 models.
- We also demonstrate the benefits of quantization or using lower precision for inferencing quantitively, which can give a better TCO in terms of performance per watt and memory footprint as well as enable better user experience by improving the throughput.
- These studies also show that we need to right-size the infrastructure based on the application and model size.
References
[1]. A. Vaswani et. al, “Attention Is All You Need”, https://arxiv.org/abs/1706.03762
[2]. W. Zhao et. al, “A Survey of Large Language Models”, https://doi.org/10.48550/arXiv.2303.18223
[3]. R. Rombach et. al, “High-Resolution Image Synthesis with Latent Diffusion Models”, https://arxiv.org/abs/2112.10752
[4]. https://www.dell.com/en-us/shop/ipovw/poweredge-hs5610
Authors: Tao Zhang (tao.zhang9@dell.com); Bhavesh Patel (bhavesh_a_patel@dell.com)