




OpenShift Virtualization with NVIDIA virtual GPU - Part 2

OpenShift Virtualization with NVIDIA virtual GPU
This blog describes how to set up OpenShift Virtualization on OpenShift Container Platform clusters using nodes that are equipped with different NVIDIA GPU (Graphics Processing Unit) cards. The tables at the end of this blog show component versions and combinations of GPU workloads that the Dell OpenShift team validated across nodes in OpenShift cluster versions 4.14 and 4.12. NVIDIA and CUDA (Compute Unified Device Architecture) drivers are installed on RHEL8 operating system VMs, and a sample Spark application is created to consume the GPU/vGPU resource.
For a comprehensive overview of NVIDIA vGPU, GPU Operator, and OpenShift Virtualization, as well as the architecture of our validated environment, see OpenShift Virtualization with NVIDIA virtual GPU - Part 1.
Before you start
- Install Dell PowerStore drivers on the cluster to provision NFS volumes. For more information about deploying Dell CSI drivers on OpenShift, see the Red Hat OpenShift Container Platform 4.12 on Dell Infrastructure Implementation Guide.
- Enable SR-IOV on the OpenShift nodes to give the VMs direct hardware access to network resources.
- Install OpenShift Virtualization operator and create HyperConverged CR on the cluster.
- Optionally, configure a dedicated network for virtual machines using Kubernetes NMState.
- Install the Node Feature Discovery operator and create a NodeFeatureDiscovery CR.
- Install the NVIDIA GPU operator from Operator Hub.
- Create a MachineConfig resource to enable Input-Output Memory Management Unit (IOMMU) driver on the nodes, before configuring mediated devices.
Steps
- Add the GPU workload configuration label to the node:
oc label node <node-name> --overwrite nvidia.com/gpu.workload.config=vm-vgpu
You can assign the following values to the label: container, vm-passthrough, and vm-vgpu. The GPU operator uses the value of this label when determining which operands to deploy to support the workload type.
2. Annotate the HyperConverged CR to enable mediated devices:
oc annotate --overwrite -n openshift-cnv hco kubevirt-hyperconverged kubevirt.kubevirt.io/jsonpatch='[{"op": "add", "path": "/spec/configuration/developerConfiguration/featureGates/-", "value": "DisableMDEVConfiguration" }]'
3. Build the vGPU manager image:
a. Download the vGPU Software from Software Downloads in the NVIDIA Licensing Portal for the platform, platform version, and vGPU product version you want.
The vGPU software bundle is packaged as NVIDIA-GRID-Linux-KVM-<version>.zip.
b. Extract the bundle to obtain the NVIDIA vGPU Manager for Linux (NVIDIA-Linux-x86_64-<version>-vgpu-kvm.run file) in the Host_Drivers folder.
4. On your administration node, clone the driver container image repository, and change to the vgpu-manager/rhel8 directory:
git clone https://gitlab.com/nvidia/container-images/driver
cd driver/vgpu-manager/rhel8
5. Export the variables with the name of your private registry, where the driver image is pushed into the NVIDIA vGPU manager version, Red Hat CoreOS version (in the format rhcos4.x, where x is the supported minor OCP version), and the CUDA base image version for building the driver image. Build the image using Docker or Podman and push the image to the private registry:
export PRIVATE_REGISTRY=docker.io/indira0408 VERSION=525.125.06 OS_TAG=rhcos4.14 CUDA_VERSION=12.0
docker build --build-arg DRIVER_VERSION=${VERSION} --build-arg CUDA_VERSION=${CUDA_VERSION} -t ${PRIVATE_REGISTRY}/vgpu-manager:${VERSION}-${OS_TAG} .
podman push docker.io/indira0408/vgpu-manager:525.125.06-rhcos4.14
6. Create an imagePullSecret with user credentials for authenticating to the private registry in the nvidia-gpu-operator namespace. Create a clusterPolicy CR with the following custom configuration, and pass the vGPU manager image you created in the previous step in the clusterPolicy:
sandboxWorloads.enabled=true
vgpuManager.enabled=true
vgpuManager.repository=docker.io/indira0408
vgpuManager.image=vgpu-manager
vgpuManager.version=525.125.06
vgpuManager.imagePullSecrets=private-registry-secret
7. After the ClusterPolicy status changes to “Ready,” edit the HyperConverged CR to allow PCI/mediated devices. For examples of HyperConverged CRs for different PCI and mediated devices, see the Dell ISG OpenShift-bare-metal git page.
8. Create a RHEL 8.6 VM and assign the vGPU device. For instructions on how to create a VM on OpenShift, see Creating virtual machines.
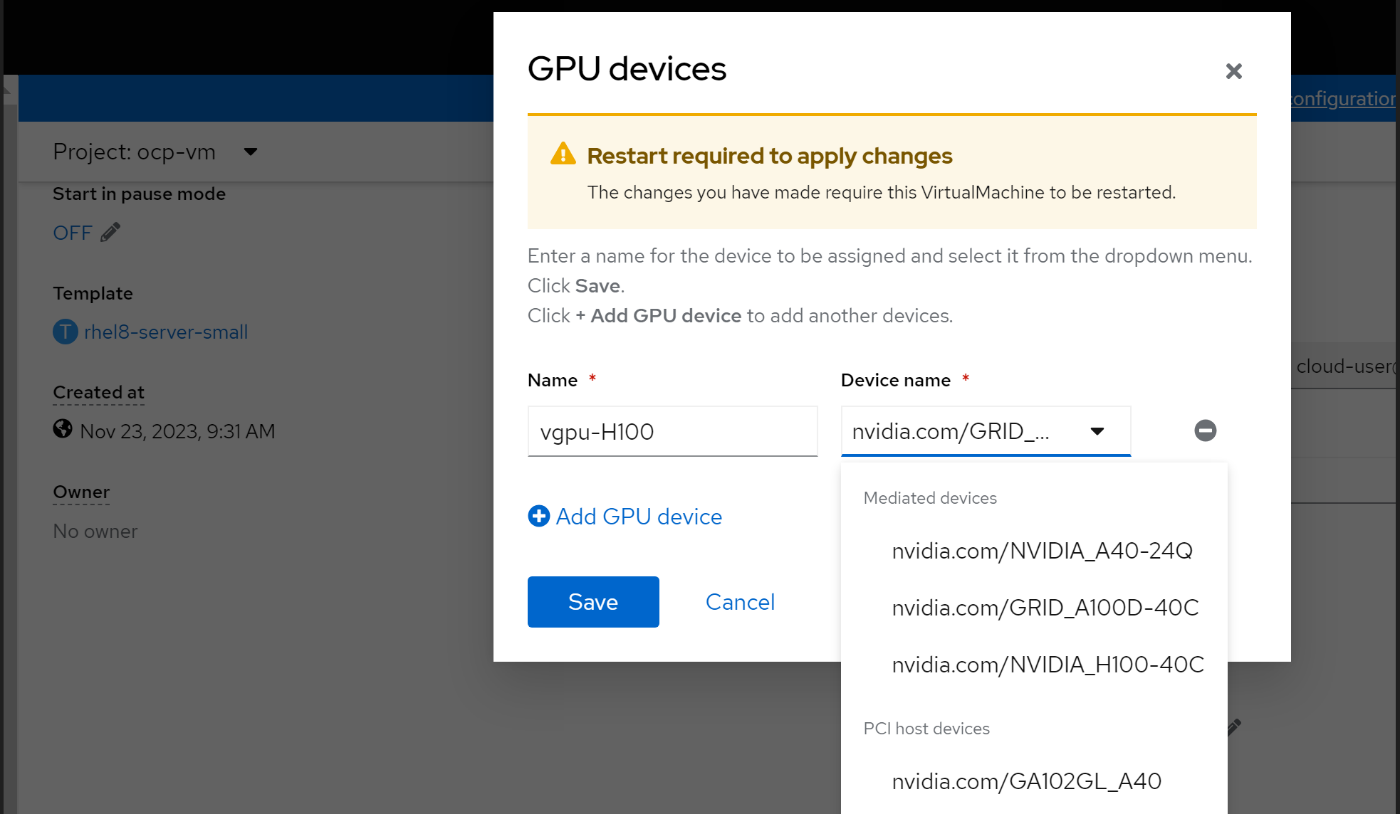
9. Optionally, you can change the vGPU profile by labeling the node with a vGPU profile name.
The GPU operator re-creates the vGPU manager drivers. Update the PCI Devices and mediated devices in the HyperConverged CR:
oc label node cnv-vgpu1 nvidia.com/vgpu.config=A40-8Q
Installing NVIDIA drivers on an RHEL 8.6 VM
Note: A vGPU-assigned VM must have the vGPU driver installed. The vGPU software's "Guest_Drivers" folder contains the package and runfile installers for drivers. You can install either the data center driver or the vGPU driver on a VM that has been assigned a single physical GPU through GPU Passthrough mode. Get the data center drivers for the operating system, architecture, and version that you want from NVIDIA Unix Drivers.
- Register the VM to the Red Hat subscription server using subscription-manager:
sudo subscription-manager register –username <username> --password <password>
2. Install make and compilation tools on the VM:
yum install -y make
yum group install ”Development Tools” -y
3. Disable the Nouveau kernel:
echo ’blacklist nouveau’ | sudo tee -a /etc/modprobe.d/blacklist.conf
4. Reboot the VM to apply the change:
reboot
5. Install Kernel headers:
yum install -y kernel-devel-$(uname -r) kernel-headers-$(uname -r)
The NVIDIA driver requires that the kernel headers and development packages for the running version of the kernel be installed at the time of the driver installation.
6. Install the NVIDIA drivers using the runfile installer. Copy the NVIDIA-Linux-x86_64-525.125.06-grid.run file in Guest drivers folder in the downloaded vGPU software to the VM.
chmod +x NVIDIA-Linux-x86_64-525.125.06-grid.run
sh NVIDIA-Linux-x86_64-525.125.06-grid.run
7. Select the options you require and install the drivers.
8. Run the nvidia-smi command to view the GPU device, NVIDIA, and CUDA drivers.
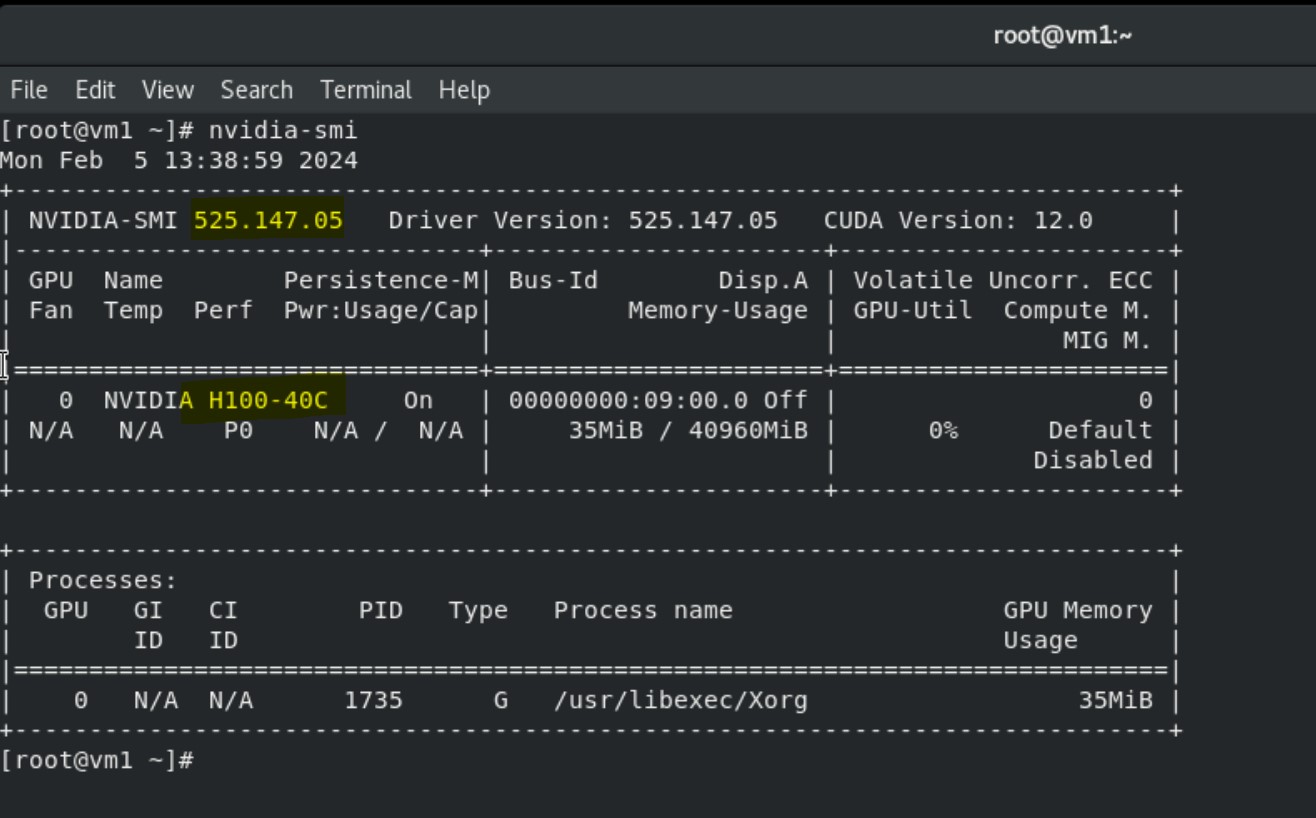
Installing Spark application on VMs to consume vGPU
Prerequisites
NVIDIA and CUDA drivers are installed on the VM.
Steps
1. Install the Open-JDK package on the VM:
yum install java-1.8.0-openjdk -y
2. Choose the required version of Spark tarball from Downloads | Apache Spark.
3. Unpack the tar file into the /opt directory:
tar -xvf spark-3.5.0-bin-hadoop3.tgz
mv spark-3.5.0-bin-hadoop3 /opt/
mv /opt/spark-3.5.0-bin-hadoop3/ /opt/spark
4. Choose the Spark release you want, and then download the NVIDIA RAPIDS Accelerator for Apache Spark plug-in jar file into the /opt/spark/jars directory from Spark Rapids Download:
wget https://repo1.maven.org/maven2/com/nvidia/rapids-4-spark_2.12/23.10.0/rapids-4-spark_2.12-23.10.0.jar
5. Export variables for the Spark home and Java home directories inside bash_profile and reload the bash_profile:
export SPARK_HOME=/opt/spark
export PATH=$SPARK_HOME/bin:$PATH
export JAVA_HOME="/usr/lib/jvm/java-1.8.0-openjdk-1.8.0.392.b08-4.el8.x86_64/jre/"
export PATH=$JAVA_HOME/bin:$PATH
source .bash_profile
6. Download the GPU discovery script from the following GitHub link and save the script locally (/root/getGpusResources.sh):
wget https://github.com/apache/spark/blob/master/examples/src/main/scripts/getGpusResources.sh
7. Launch the spark shell with the following configuration settings and run a small compute program to use the vGPU device:
/opt/spark/bin/spark-shell --jars /opt/spark/jars/rapids-4-spark_2.12-23.10.0.jar --conf spark.plugins=com.nvidia.spark.SQLPlugin --conf spark.executor.resource.gpu.discoveryScript=/root/getGpusResources.sh --conf spark.executor.resource.gpu.vendor=nvidia.com --conf spark.rapids.sql.enabled=true --conf spark.executor.resource.gpu.amount=1
scala> val df = sc.makeRDD(1 to 1000000000, 6).toDF
scala> val df2 = sc.makeRDD(1 to 1000000000, 6).toDF
scala> df.select( $"value" as "a").join(df2.select($"value" as "b"), $"a" === $"b").count
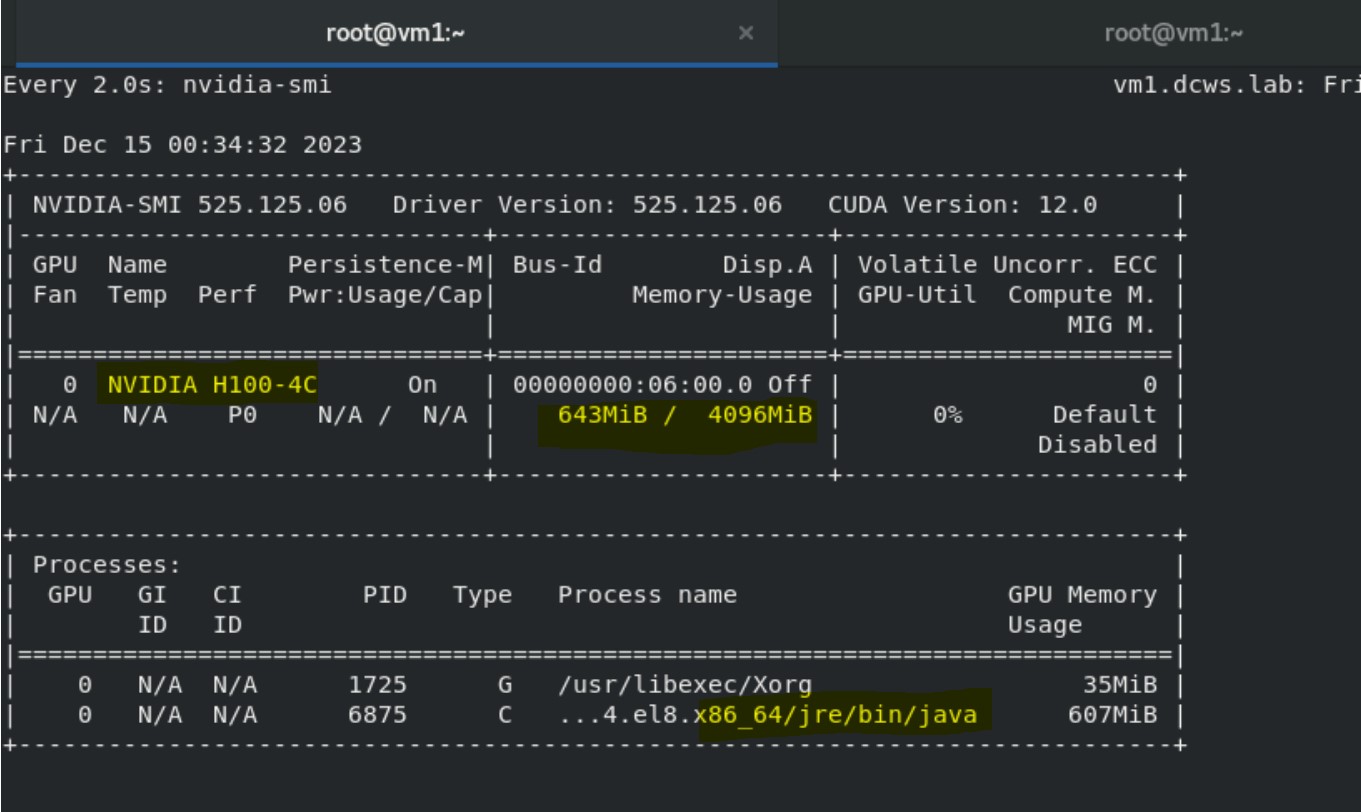
8. Run nvidia-smi in the other terminal to monitor vGPU utilization:
watch nvidia-smi
The output shows the Java process and Volatile GPU-utilization percentage.
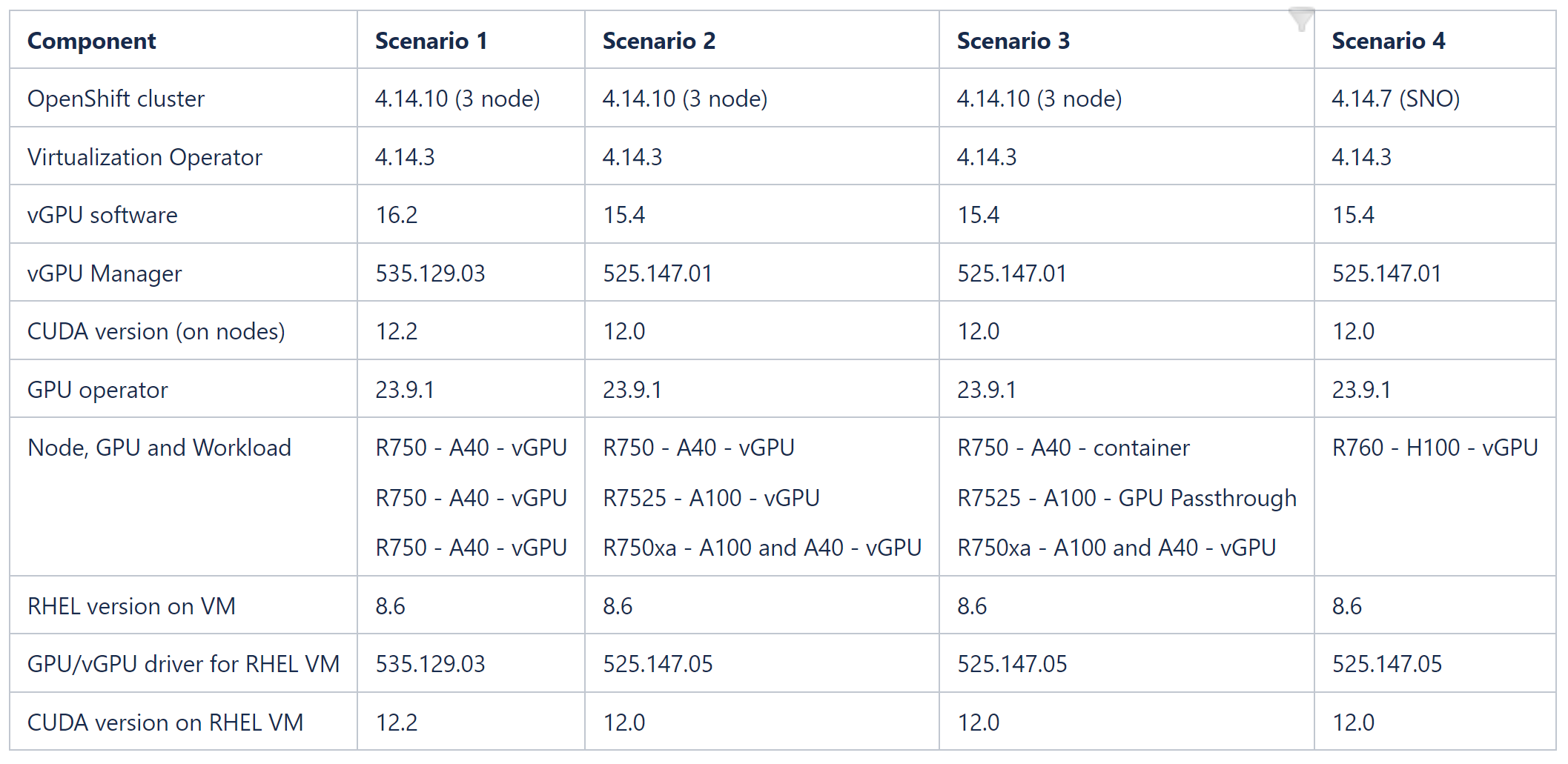
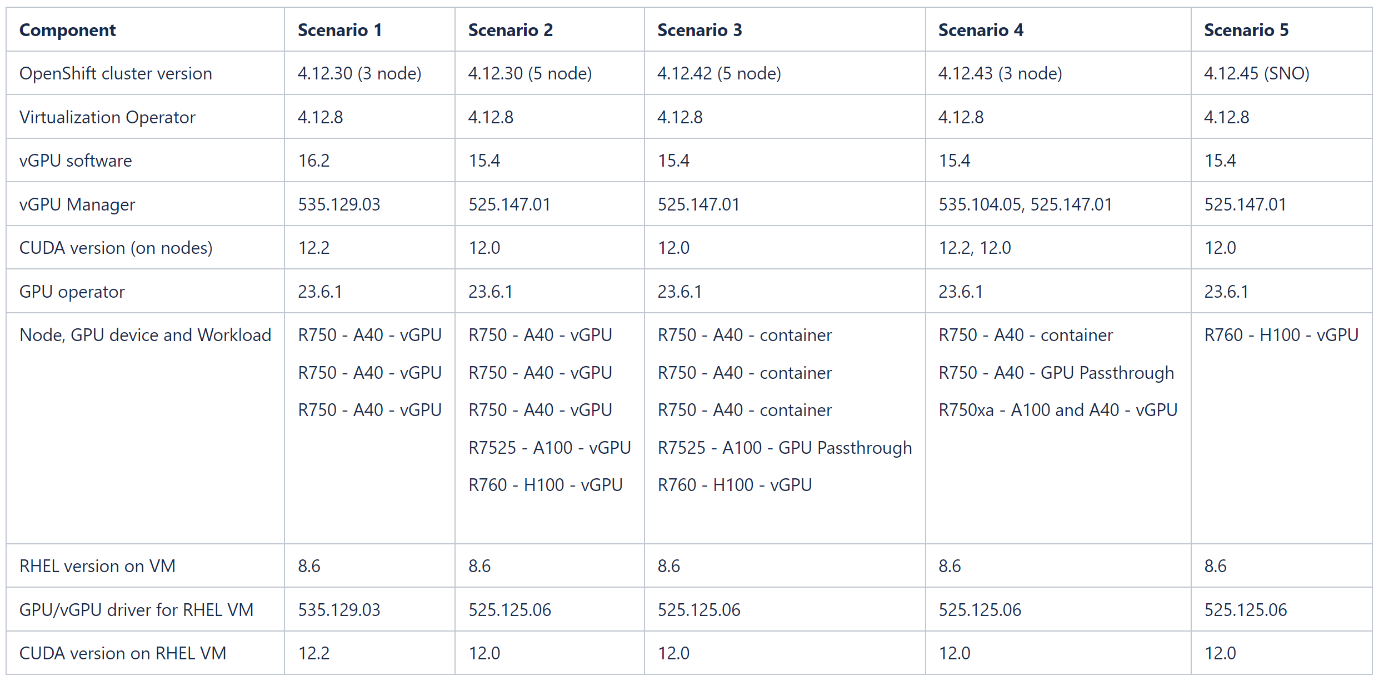
Validated scenarios and versions
References
- NVIDIA GPU Operator with OpenShift Virtualization
- NVIDIA Virtual GPU (vGPU) Software Documentation
- Configuring virtual GPUs - Virtual machines | Virtualization | OpenShift Container Platform 4.14
- GPU Operator Component Matrix
- NVIDIA Virtual GPU Software Documentation
- NVIDIA® Virtual GPU Software Supported GPUs