




New Frontiers—Dell EMC PowerEdge R750xa Server with NVIDIA A100 GPUs
Dell Technologies has released the new PowerEdge R750xa server, a GPU workload-based platform that is designed to support artificial intelligence, machine learning, and high-performance computing solutions. The dual socket/2U platform supports 3rd Gen Intel Xeon processors (code named Ice Lake). It supports up to 40 cores per processor, has eight memory channels per CPU, and up to 32 DDR4 DIMMs at 3200 MT/s DIMM speed. This server can accommodate up to four double-width PCIe GPUs that are located in the front left and the front right of the server.
Compared with the previous generation PowerEdge C4140 and PowerEdge R740 GPU platform options, the new PowerEdge R750xa server supports larger storage capacity, provides more flexible GPU offerings, and improves the thermal requirement

Figure 1 PowerEdge R750xa server
The NVIDIA A100 GPUs are built on the NVIDIA Ampere architecture to enable double precision workloads. This blog evaluates the new PowerEdge R750xa server and compares its performance with the previous generation PowerEdge C4140 server.
The following table shows the specifications for the NVIDIA GPU that is discussed in this blog and compares the performance improvement from the previous generation.
Table 1 NVIDIA GPU specifications
PCIe | Improvement | ||
GPU name | A100 | V100 |
|
GPU architecture | Ampere | Volta | - |
GPU memory | 40 GB | 32 GB | 60% |
GPU memory bandwidth | 1555 GB/s | 900 GB/s | 73% |
Peak FP64 | 9.7 TFLOPS | 7 TFLOPS | 39% |
Peak FP64 Tensor Core | 19.5 TFLOPS | N/A | - |
Peak FP32 | 19.5 TFLOPS | 14 TFLOPS | 39% |
Peak FP32 Tensor Core | 156 TFLOPS 312 TFLOPS* | N/A | - |
Peak Mixed Precision FP16 ops/ FP32 Accumulate | 312 TFLOPS 624 TFLOPS* | 125 TFLOPS | 5x |
GPU base clock | 765 MHz | 1230 MHz | - |
Peak INT8 | 624 TOPS 1,248 TOPS* | N/A | - |
GPU Boost clock | 1410 MHz | 1380 MHz | 2.1% |
NVLink speed | 600 GB/s | N/A | - |
Maximum power consumption | 250 W | 250 W | No change |
Test bed and applications
This blog quantifies the performance improvement of the GPUs with the new PowerEdge GPU platform.
Using a single node PowerEdge R750xa server in the Dell HPC & AI Innovation Lab, we derived all results presented in this blog from this test bed. This section describes the test bed and the applications that were evaluated as part of the study. The following table provides test environment details:
Table 2 Server configuration
Component | Test Bed 1 | Test Bed 2 |
Server | Dell PowerEdge R750xa
| Dell PowerEdge C4140 configuration M |
Processor | Intel Xeon 8380 | Intel Xeon 6248 |
Memory | 32 x 16 GB @ 3200MT/s | 16 x 16 GB @ 2933MT/s |
Operating system | Red Hat Enterprise Linux 8.3 | Red Hat Enterprise Linux 8.3 |
GPU | 4 x NVIDIA A100-PCIe-40 GB GPU | 4 x NVIDIA V100-PCIe-32 GB GPU |
The following table provides information about the applications and benchmarks used:
Table 3 Benchmark and application details
Application | Domain | Version | Benchmark dataset |
High-Performance Linpack | Floating point compute-intensive system benchmark | xhpl_cuda-11.0-dyn_mkl-static_ompi-4.0.4_gcc4.8.5_7-23-20 | Problem size is more than 95% of GPU memory |
HPCG | Sparse matrix calculations | xhpcg-3.1_cuda_11_ompi-3.1 | 512 * 512 * 288
|
GROMACS | Molecular dynamics application | 2020 | Ligno Cellulose Water 1536 Water 3072 |
LAMMPS | Molecular dynamics application | 29 October 2020 release | Lennard Jones |
LAMMPS
Large-Scale Atomic/Molecular Massively Parallel simulator (LAMMPS) is distributed by Sandia National Labs and the US Department of Energy. LAMMPS is open-source code that has different accelerated models for performance on CPUs and GPUs. For our test, we compiled the binary using the KOKKOS package, which runs efficiently on GPUs.
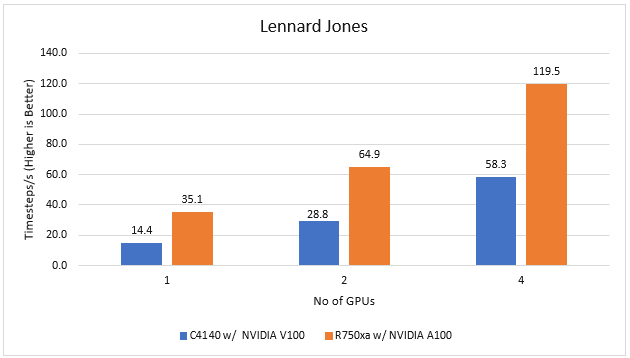
Figure 2 LAMMPS Performance on PowerEdge R750xa and PowerEdge C4140 servers
With the newer generation GPUs, this application improves 2.4 times compared to single GPU performance. The overall performance from a single server improved twice with the PowerEdge R750xa server and NVIDIA A100 GPUs.
GROMACS
GROMACS is a free and open-source parallel molecular dynamics package designed for simulations of biochemical molecules such as proteins, lipids, and nucleic acids. It is used by a wide variety of researchers, particularly for biomolecular and chemistry simulations. GROMACS supports all the usual algorithms expected from modern molecular dynamics implementation. It is open-source software with the latest versions available under the GNU Lesser General Public License (LGPL).
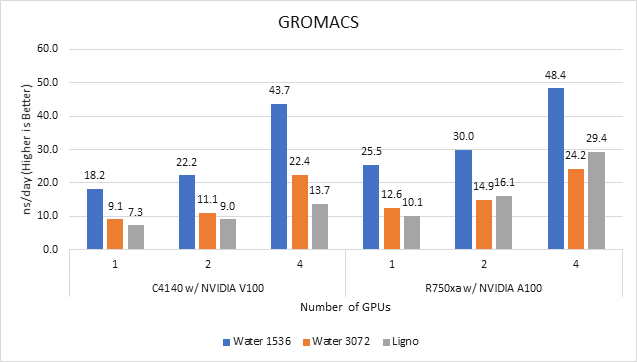
Figure 3 GROMACS performance on PowerEdge C4140 and r750xa servers
With the newer generation GPUs, this application improved approximately 1.5 times across the dataset compared to single GPU performance. The overall performance from a single server improved 1.5 times with a PowerEdge R750xa server and NVIDIA A100 GPUs.
High-Performance Linpack
High-Performance Linpack (HPL) needs no introduction in the HPC arena. It is a widely used standard benchmark tests in the industry.
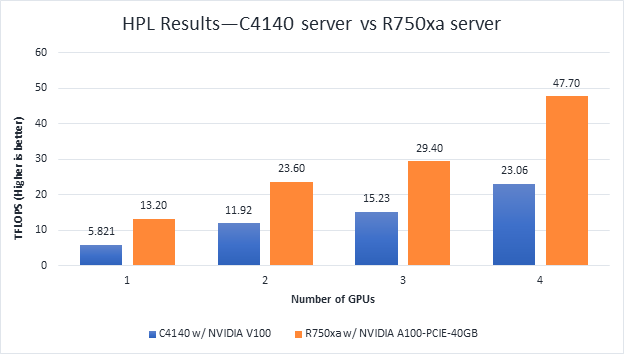
Figure 4 HPL Performance on the PowerEdge R750xa server with A100 GPU and PowerEdge C4140 server with V100 GPU
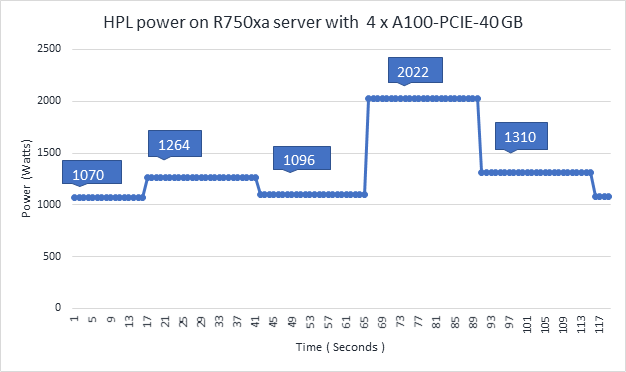
Figure 5 Power use of the HPL running on NVIDIA GPUs
From Figure 4 and Figure 5, the following results were observed:
- Performance—For GPU count, the NVIDIA A100 GPU demonstrates twice the performance of the NVIDIA V100 GPU. Higher memory size, double precision FLOPS, and a newer architecture contribute to the improvement for the NVIDIA A100 GPU.
- Scalability—The PowerEdge R750xa server with four NVIDIA A100-PCIe-40 GB GPUs delivers 3.6 times higher HPL performance compared to one NVIDIA A100-PCIE-40 GB GPU. The NVIDIA A100 GPUs scale well inside the PowerEdge R750xa server for the HPL benchmark.
- Higher Rpeak—The HPL code on NVIDIA A100 GPUs uses the new double-precision Tensor cores. The theoretical peak for each GPU is 19.5 TFlops, as opposed to 9.7 TFlops.
- Power—Figure 5 shows power consumption of a complete HPL run with the PowerEdge R750xa server using four A100-PCIe GPUs. This result was measured with iDRAC commands, and the peak power consumption was observed as 2022 Watts. Based on our previous observations, we know that the PowerEdge C4140 server consumes approximately 1800 W of power.
HPCG
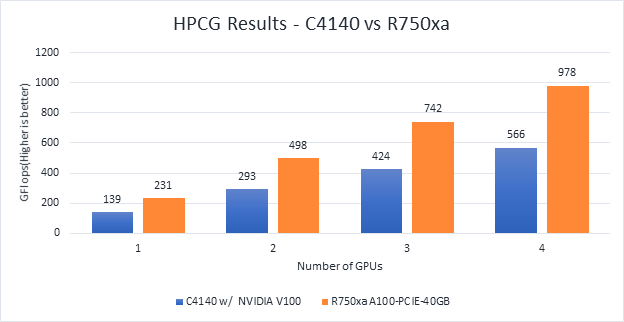
Figure 6 Scaling GPU performance data for HPCG Benchmark
As discussed in other blogs, high performance conjugate gradient (HPCG) is another standard benchmark to test data access patterns of sparse matrix calculations. From the graph, we see that the HPCG benchmark scales well with this benchmark resulting in 1.6 times performance improvement over the previous generation PowerEdge C4140 server with an NVIDIA V100 GPU.
The 72 percent improvement in memory bandwidth of the NVIDIA A100 GPU over the NVIDIA V100 GPU contributes to the performance improvement.
Conclusion
In this blog, we introduced the latest generation PowerEdge R750xa platform and discussed the performance improvement over the previous generation PowerEdge C4140 server. The PowerEdge R750xa server is a good option for customers looking for an Intel Xeon scalable CPU-based platform powered with NVIDIA GPUs.
With the newer generation PowerEdge R750xa server and NVIDIA A100 GPUs, the applications discussed in this blog show significant performance improvement.
Next steps
In future blogs, we plan to evaluate NVLINK bridge support, which is another important feature of the PowerEdge R750xa server and NVIDIA A100 GPUs.