




Is GPU integration critical for Predictive Analytics?
GPUs are getting widespread attention in the Predictive Analytics (PredAn) space. This is due to their ability to perform parallel computation on large volumes of data. GPUs leverage complex models that are tightly integrated to the simulation required to do control synthesis for real-time response in Industry 4.0 (I4) solutions. Consider the predictive maintenance use-case, where telemetry from servers in the datacenter are captured for failure analysis in the analytics cluster and control sequences generated to avoid downtime. Clearly, to be on track, the machine needs to project current data into the future and simulate fault partitions in the monitorable list to negotiate a fix, all in a tight time-window. However, prediction and simulation are inherently slow, particularly when this needs to be done on many fault partitions over multiple servers.
We argue that two things can help:
- Linearizing prediction with Koopman filters
- Leveraging generative models for control synthesis in the simulation space
We use Koopman filter to project data into a skinnier latent basis space for Dimension Reduction (DR) and embed this transformation inside an autoencoder. A probe to convert eigen-vector sections to an Eigen Value Sequence (EVS) that correlates to survival probabilities can then be transformed to Time2Failure (T2F) estimates. This failure detection can then be tagged with a reference to a pre-calibrated auto-fix script derived using Anomaly Fingerprinting (AF) while simulating the projected fault partition. Generative models (GAN) allow performance and footprint optimization, resulting in faster inferencing. In that sense, this improves inferencing throughput. We train generative models for Data, DR, T2F and AF and use them for fast inferencing. Figure 1(a) shows the inferencing flow, 1(b) shows Koopman linearization, and 1(c) shows the underlying GAN footprint.
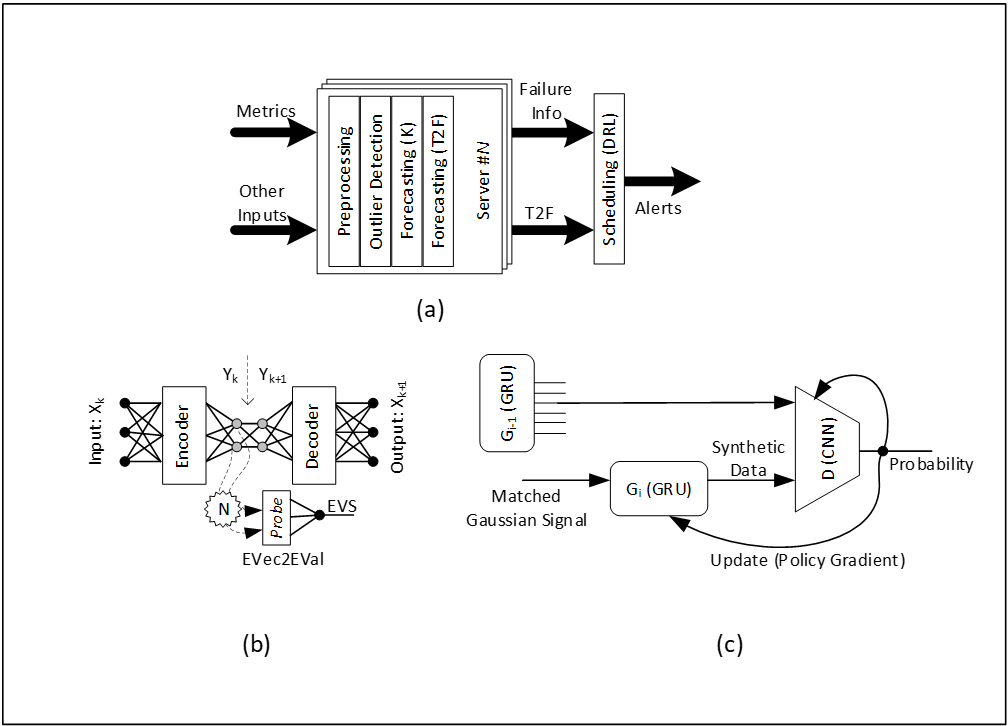
Figure 1. Inferencing flow, Koopman linearization, and the underlying GAN footprint
In figure 1(a), T2F estimates for all faults on all servers are triaged by the scheduler using DRL in the inferencing phase. In figure 1(b), each fault-group, eigen-vector dimension is searched in the autoencoder frame by resizing the encoder depth for failure clarity in EVS. In figure 1(b), G2 is derived from G1, and G1 from G0 for each fault group. Generative model synthesis enables the mapping of complex computation to high-performance low-footprint analogues that can be leveraged at inference time.
The GPU Argument
A GPU is typically used for both training and inferencing. In the predictive maintenance testbed, we stream live telemetry from iDRACs to the analytics cluster built using Splunk services like streaming, indexing, search, tiering and data-science tools on Robin.io k8s platform. The cluster has access to Nvidia GPU resources for both training and inferencing. The plot in figure 2(a) shows that the use of asynchronous access to Multi-Instance GPU (MIG) inferencing provides performance gain over blocking alternative, measured using wall-clock estimates. The GPU scheduler manages asynchronous T2F workloads better, and blocking calls would require timeout reconfiguration in production. The plot in figure 2(b) shows that inferencing performance of generative models improved by 15% (for 12+ episodes) when selective optimization (DRL-on-CPU and T2F-Calculation-on-GPU) was opted. The direction of this trend makes sense because DRL-in-GPU requires frequent memory-to-memory transfers and so is an ideal candidate for CPU pinning, whereas T2F estimates are dense but relatively less frequent computations that do well when mapped to GPU with MIG enabled. As the gap between the plots widens, this indicates that the CPU only computation cannot keep up with data pile-up, so input sections need to be shortened. The plot in figure 2(c) shows that fewer batches (assuming fixed dataset size) shortened epochs needed to achieve the desired training accuracy in GAN. However, larger batch size requires more GPU memory implying MIG disablement for improved throughput and energy consumption. Based on this data, we argue that dedicating a GPU for training (single kernel) as opposed to switching kernels (between training and inferencing) improves throughput. This tells us that the training GPU (without MIG enablement) and the inferencing GPU (with MIG enablement) should be kept separate in I4 for optimal utilization and performance. Based on current configuration choices, this points to dual Nvidia A30 GPU preference as opposed to a single Nvidia A100 GPU attached to the Power Edge server worker node. The plot in figure 2(d) shows that single layer generative models improve inferencing performance and scales more predictively. The expectation is that multilayering would do better. The plot indicates performance improvement as the section size increases, although more work is needed to understand the impact of multilayering.
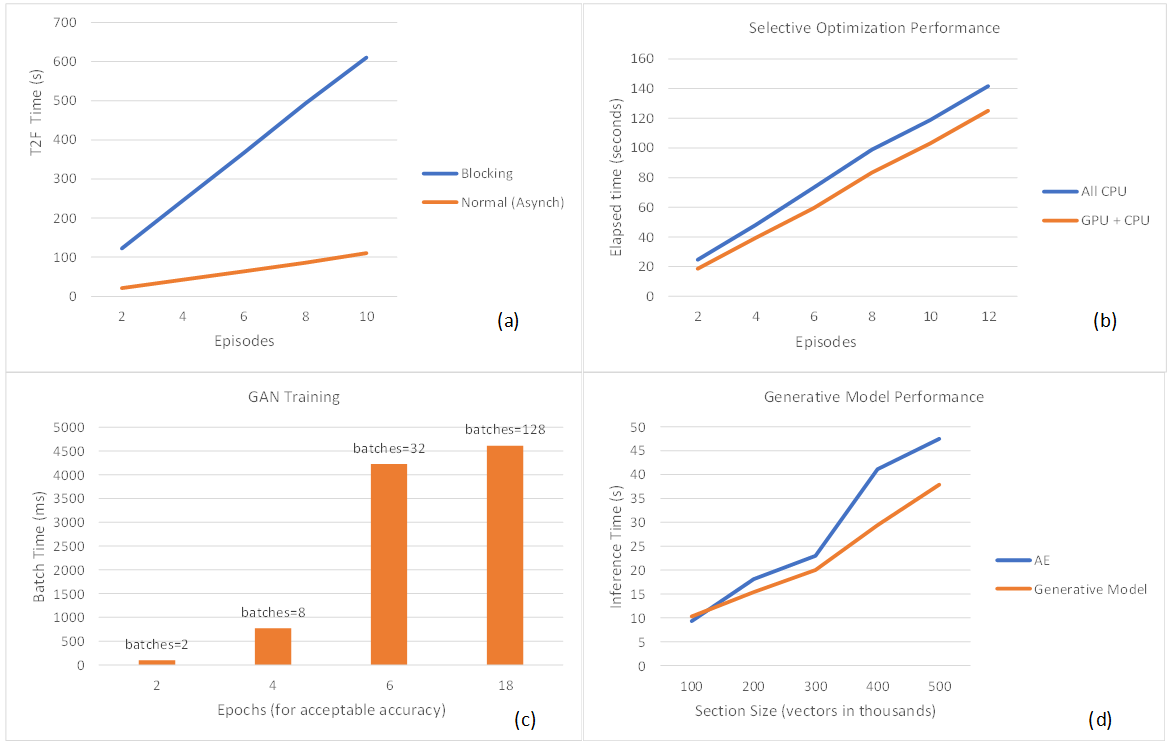
Figure 2. (a) Asynchronous calls for MIG inferencing provide performance gain over blocking calls. (b) Selective optimization provides better inferencing performance. (c) Larger training batch size (fewer batches) shortens the epochs needed to achieve acceptable accuracy. (d) Generative models improve inferencing performance.
In conclusion, predictive analytics is essential for maintenance in the era of digital transformation. We present a solution that scales with Dell server telemetry specification. It is widely accepted that for iterative error correction, linear feedback control systems perform better than their non-linear counterparts. We shaped predictions to behave linearly. By using generative models, one can achieve faster inferencing. We proposed a new way to couple generative models with Digital Twins (DT) simulation models for scheduling shaped by DRL. Our experiments indicate that GPU in analytics cluster accelerates response performance in I4 feedback loops (e.g., MIG enablement at inferencing, leveraging generative models to fast-track control synthesis).
References
- Brunton, S. L.; Budišić, M; Kaiser, E; Kutz, N. Modern Koopman Theory for Dynamical Systems. arXiv 2102.12086 2021.
- Brophy, E; Wang, Z; She, Q; Ward, T. Generative Adversarial Networks in Time Series: A Systematic Literature Survey. ACM Computing Surveys 2023, 55(10), Article 199.
- Matsuo, Y; LeCun, Y; Sahani, M; Precup, D; Silver, D; Sugiyama; M; Uchibe, E; Morimoto, J. Deep learning, reinforcement learning, and world models. Neural Networks Elsevier Press 2022, 152(2022), pp 267-275.
- Gara, S et al. Telemetry Streaming with iDRAC9. Dell White Paper May 2021.