




Inverse Design Meets Big Data: A Spark-Based Solution for Real-Time Anomaly Detection
Inverse design is a process in which you start with a wanted outcome and performance goals. It works backward to find the system configuration and design parameters to achieve goals instead of the more traditional forward design, in which known parameters shape the design.
For accurate and timely identification of anomalies in big data streams from servers, it is important to configure an optimal combination of technologies. We first pick the autoencoder technique that shapes the multivariate analytics, then configure Kafka-Spark-Delta integration for dataflow, and finally select the data grouping at the source for the analytics to fire.
The iDRAC module in Dell PowerEdge servers gathers critical sideband data in its sensor bank. This data can be programmed for real-time streaming, but not every signal (data-chain) is relevant to online models that consume them. For example, if the goal is to find servers in the data center that are overheating, the internal residual battery charge in servers is not useful. Composable iDRAC data from PowerEdge servers is pooled in networked PowerScale storage. The most recent chunks of data are loaded onto memory for anomaly detection over random samples. Computed temporal fluctuations in anomaly strength complete the information synthesis from raw data. This disaggregated journey from logically grouped raw data to information using the Dell Data Lakehouse (DLH) network infrastructure specification (not shown here) triggers action in real-time. The following figure captures the architecture:
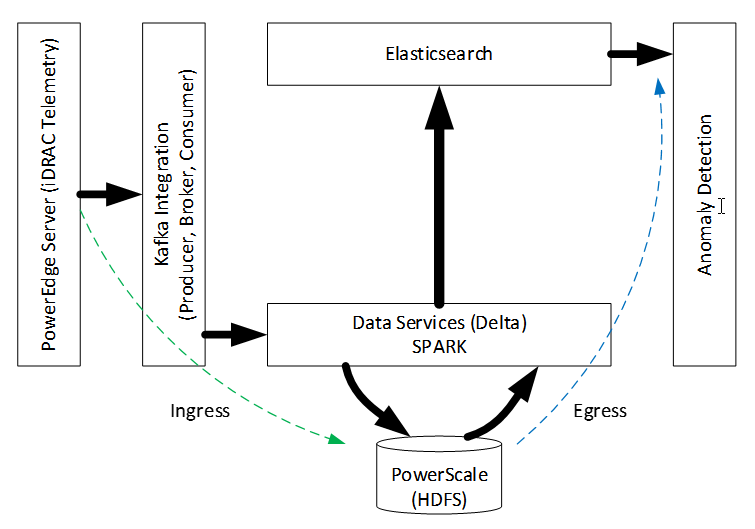
Figure 1. End-to-end architecture for streaming analytics
The pipeline has two in-order stages─ingress and egress. In the ingress stage, target model (for example, overheating) features influence data enablement, capture frequency, and streamer parameterization. Server iDRACs [1] write to the Kafka Pump (KP), which interprets native semantics for consumption by the multithreaded Kafka Consumer, as shown in the following figure:
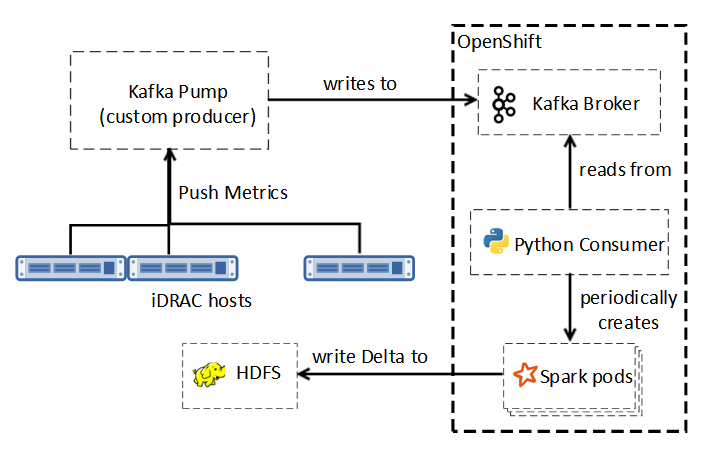
Figure 2. Kafka to Delta
The reader thread collects data from the configured input buffer while the writer thread periodically flushes this data by concatenating to the HDFS storage in Delta format, using Spark services for in-memory computing, scalability, and fault tolerance. Storage and data-management reliability, scalability, efficiency of HDFS and Delta Lake, coupled with the Spark and Kafka performance considerations influenced our choices.
In the egress stage of the pipeline, we apply anomaly strength analytics to the pretrained autoencoder [2] model. The use of NVIDIA A100 GPUs accelerated autoencoder training. Elasticsearch helped sift through random samples of the most recent server data bundle for anomaly identification. Aggregated Z-score error deviations over these samples helped characterize the precise multivariate anomaly strength (as shown in the following figure), extrapolation of which over a temporal window captured undesirable fluctuations. 
Figure 3. Anomaly analytics
We used Matplotlib to render, but you can alternatively manufacture on-demand events to drive corrections in the substrate. If generalized, this approach can continuously identify machine anomalies.
Conclusion
In this PoC, we combined several emerging technologies. We used Kafka for real-time data ingestion with Spark for reliable high-performance processing, HDFS with Delta Lake for storage, and advanced analytics for anomaly detection. We designed a Spark solution for real-time anomaly detection. By using autoencoders, supplemented with a strategy to quantify anomaly strength without requiring periodic drift compensation, we proved that modern data analytics integrates well on Dell DLH infrastructure. This infrastructure includes Red Hat OpenShift, Dell PowerScale storage, PowerEdge compute, and PowerSwitch network elements.
References:
[1] Telemetry Streaming with iDRAC9— Custom Reports Get Started
[2] D. Bank, N. Koenigstein, R. Giryes, “Autoencoders”, arXiv:2003.05991v2, April 2021.