




Deploying Llama 8B Model with Advanced Quantization Techniques on Dell Server
Download PDF
Introduction
Large language models (LLMs) have shown excellent performance on various tasks, but the large model size makes it difficult to deploy in resource constrained environments. The LLM evolution diagram in Figure 1 shows the popular pre-trained models since 2017, most of which are based on the transformer architecture [1] [2]. It is not hard to find the trend of larger and more open-source models following the timeline. Open-source models boosted the popularity of LLMs by eliminating the training cost associated with the large-scale infrastructure and the long training time required to create them. Another portion of the cost of LLM applications comes from the deployment where an efficient inference platform is required.
Meta Llama models have become one of the most powerful open-source Large Language Model (LLM) series. Notably, the recently released Llama 3 models achieved impressive performance across various benchmarks due, in part, to the highly curated 15T tokens of pre-training data [3]. Despite their impressive performance, deploying Llama 3 models with high throughput may still pose significant challenges in resource constrained environments due to the large model size and limited hardware resources in many scenarios. Fortunately, low-bit quantization has emerged as one of the most popular techniques for compressing LLMs. This technique reduces the memory and computational requirements of LLMs during inference, enabling them to run on resource-limited devices and potentially boost the performance.
This blog focuses on how to deploy LLMs efficiently on Dell Servers with different quantization techniques. To better understand the impact of quantization, we first benchmarked the model accuracy under different quantization techniques. Then we demonstrated the throughput and memory requirements of running LLMs under different quantization techniques through experiments. Specifically, we chose the open-source model Meta-Llama-3-8B-Instruct [4] for its popularity. Given that the Llama-2-7B and Llama-3.1-8B models have a similar model architecture and comparable size, the conclusions based on the experiments for Llama-3-8B in the blog also apply for those models as well. The server used was Dell PowerEdge XE9680 with NVIDIA H100s GPUs [5] [6]. The deployment framework in the experiments is TensorRT-LLM, which enables different quantization techniques including advanced 4bit quantization as demonstrated in the blog [7].
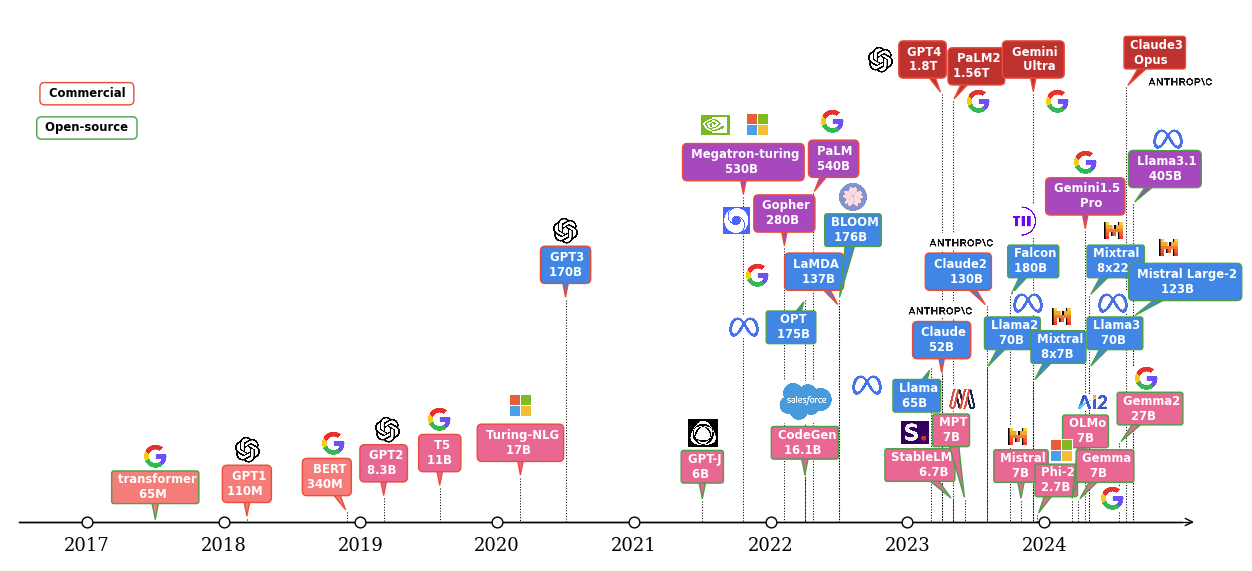
Figure 1. LLM evolution
Background
One key approach in model compression is quantization which changes full or half precision floating point numbers into simpler forms like integers. This conversion cuts down on the memory footprint that the model needs. Quantization intrinsically introduces some accuracy loss. Most of the quantization techniques implement algorithms to minimize the accuracy loss so the model quality has a negligible degradation after quantization.
In this blog, we focused on post training quantization (PTQ) under the inferencing framework TensorRT-LLM. PTQ entails quantizing the parameters of a Large Language Model (LLM) after it has completed the training phase. The primary objective of PTQ is to reduce the memory requirements of the LLM, without necessitating modifications to the LLM architecture or requiring a re-training process.
Test setup
Meta-Llama-3-8B-Instruct [4] is an instruction-tuned version of the base 8b model meta-llama/Meta-Llama-3-8B [10]. It has been optimized for dialogue applications and was fine-tuned on over 10 million human-annotated data samples with a combination of rejection sampling, proximal policy optimization (PPO), and direct policy optimization (DPO) [18]. We downloaded the bfloat16 model from Hugging Face and used the format bfloat16 as the baseline model for comparison with the quantized models.
We investigated four main advanced quantization techniques along with KV cache quantization options to compare with the baseline bfloat16 model. As shown in Table 1, for weight-only quantization, we explored AWQ (activation-aware weight quantization) W4A16 [11], GPTQ (Accurate Post-Training Quantization for Generative Pre-trained Transformers) W4A16 [12]. For weight-activation quantization, we explored FP8 W8A8 [13], AWQ W4A8 [17] and SmoothQuant W8A8 [14]. We run the experiments under the TensorRT-LLM framework which integrates the toolkit that allows quantization and deployment for the main-stream LLM models.
Table 1. List of quantization techniques under investigation
Quantization Techniques | Precision of weights | Precision of activations | Precision of KV Cache |
AWQ W4A16 | INT 4
| FP16 | FP16 |
AWQ W4A16 with INT8 KV Cache | INT4 | FP16 | INT8 |
AWQ W4A8
| INT4 | FP8 | FP16 |
GPTQ W4A16 | INT4 | FP16 | FP16 |
FP8 W8A8 | FP8 | FP8 | FP16 |
SmoothQuant W8A8 | INT8 | INT8 | FP16 |
We also investigated the SmoothQuant by different quantization granularities - per-tensor and per-token + per-channel quantization. Per-tensor quantization applies a single quantization step size to the entire matrix. For better precision, fine-grained quantization can be enabled by using different quantization step sizes for each token's activations (per-token quantization) or for each output channel of weights (per-channel quantization) [14].
For the accuracy evaluation across models with different quantization techniques, we choose the Massive Multitask Language Understanding (MMLU) datasets. The benchmark covers 57 different subjects and ranges across different difficulty levels for both world knowledge and problem-solving ability tests [8]. The granularity and breadth of the subjects in MMLU dataset allow us to evaluate the model accuracy across different applications. To summarize the results in a more precise form, the 57 subjects in the MMLU dataset can be further grouped into 21 categories or even 4 main categories as STEM, humanities, social sciences, and others (business, health, misc.) [9].
Performance is evaluated in terms of throughput (tokens/sec) across different batch sizes on Dell XE9680 server. In this blog, we do not investigate the GPU parallelism impact, but focus on the quantization itself, so we use only one of the 8 available H100 GPUs for the experiments. The XE9680 server configuration and high-level specification of H100 are shown in Table 1 and 2 [5] [6]. We tested four different combinations of input sequence length and output length: 128/128; 128/2048; 2048/128; 2048/2048, to represent different use cases.
Table 2. XE9680 server configuration
System Name | PowerEdge XE9680 |
Status | Available |
System Type | Data Center |
Number of Nodes | 1 |
Host Processor Model | 4th Generation Intel® Xeon® Scalable Processors |
Host Process Name | Intel® Xeon® Platinum 8470 |
Host Processors per Node | 2 |
Host Processor Core Count | 52 |
Host Processor Frequency | 2.0 GHz, 3.8 GHz Turbo Boost |
Host Memory Capacity and Type | 2TB, 32x 64 GB DIMM, 4800 MT/s DDR5 |
Host Storage Capacity | 1.8 TB, NVME |
Table 3. H100 High-level specification
GPU Architecture | NVIDIA Hopper |
GPU Number, Memory, and name | 1 x 80GB H100 |
GPU Memory Bandwidth and Type | 2TB/s HBM3 |
Max Power Consumption | Up to 700W (configurable) |
Form Factor | SXM |
The inference framework that includes different quantization tools is NVIDIA TensorRT-LLM release version 0.11.0. The operating system for the experiments is Ubuntu 22.04 LTS.
To achieve an optimized performance, a TensorRT engine needs to be built with the different options for the H100 GPU under the TensorRT-LLM framework. A brief introduction for those options and recommendations can be found in [15] [16].
Results
We first show the model accuracy results based on the MMLU dataset tests, then the performance results when running those models on PowerEdge XE9680. Lastly, we show the actual peak memory usage for different scenarios. Brief discussions are given for each result. The conclusions are summarized in the next section.
Accuracy
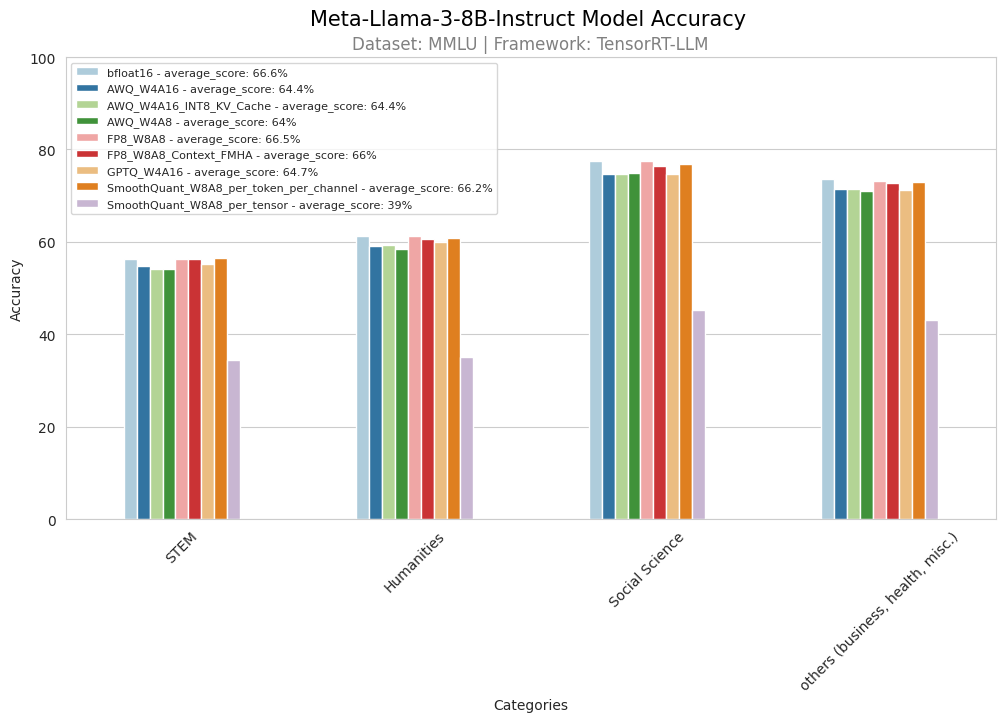
Figure 2. MMLU 4-category accuracy test result
Figure 2 shows the accuracy test results of 4 main MMLU categories for the Meta-Llama-3-8B-Instruct model. Compared to the baseline bfloat16 model, all int4 quantized models (AWQ W4A16, GPTQ W4A16, AWQ W4A8) exhibit an overall accuracy drop of approximately 2%. In contrast, the accuracy of the FP8 quantized model is much closer to that of the bfloat16 model. Additionally, the SmoothQuant (W8A8) model with per token + per channel quantization achieves accuracy levels close to the bfloat16 model, while the SmoothQuant model with per tensor quantization shows the worst performance among all. Notably, the AWQ W4A16 model with a quantized KV cache (int8) does not experience any accuracy degradation from the test, maintaining accuracy comparable to the native AWQ W4A16 model.
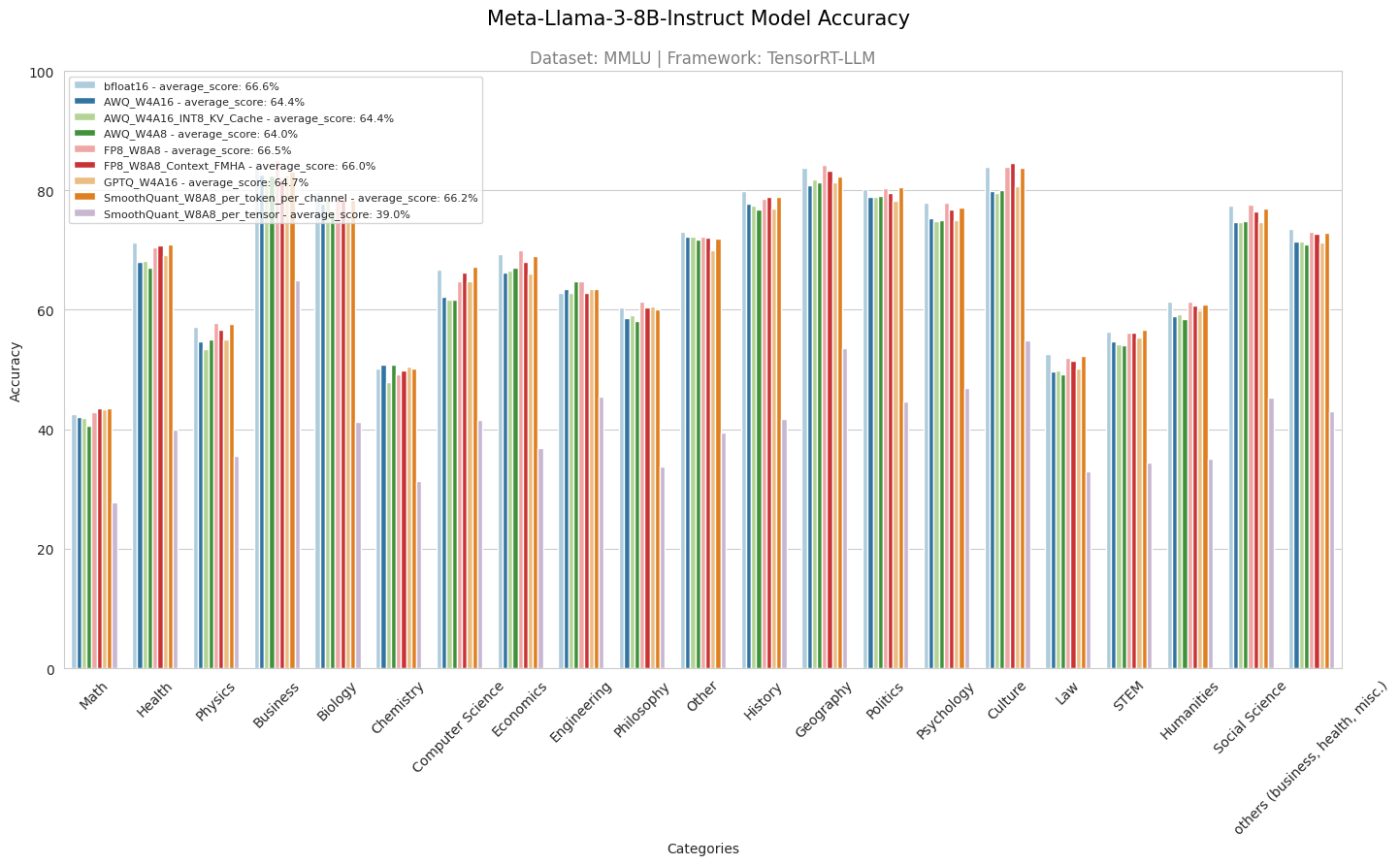
Figure 3. MMLU 21-category accuracy test result
Figure 3 further shows the accuracy test results of 21 MMLU sub-categories for the Meta-Llama-3-8B-Instruct model. Similar conclusions can be drawn that AWQ quantized models performed worse than bfloat16 across all subjects, except for chemistry and engineering, where AWQ W4A16 and AWQ W4A8 outperformed bfloat16. GPTQ did not surpass bfloat16 in general, except in math, chemistry, engineering, and philosophy, where it shows similar accuracy. GPTQ outperformed or matched AWQ in most subjects, except for economics, other, history, and politics. The FP8 model performed on par with bfloat16 in most areas, except health, chemistry, computer science, and history, while exceeding bfloat16 in economics and philosophy. SmoothQuant with per-tensor quantization had the worst performance among all, whereas SmoothQuant with per-token and per-channel quantization performed comparably to bfloat16 in all subjects except biology, history, and geography. Overall, AWQ and GPTQ experienced an approximate 2% accuracy drop compared to bfloat16, while FP8 and SmoothQuant with per-token and per-channel quantization techniques maintained the accuracy close to bfloat16.
Performance
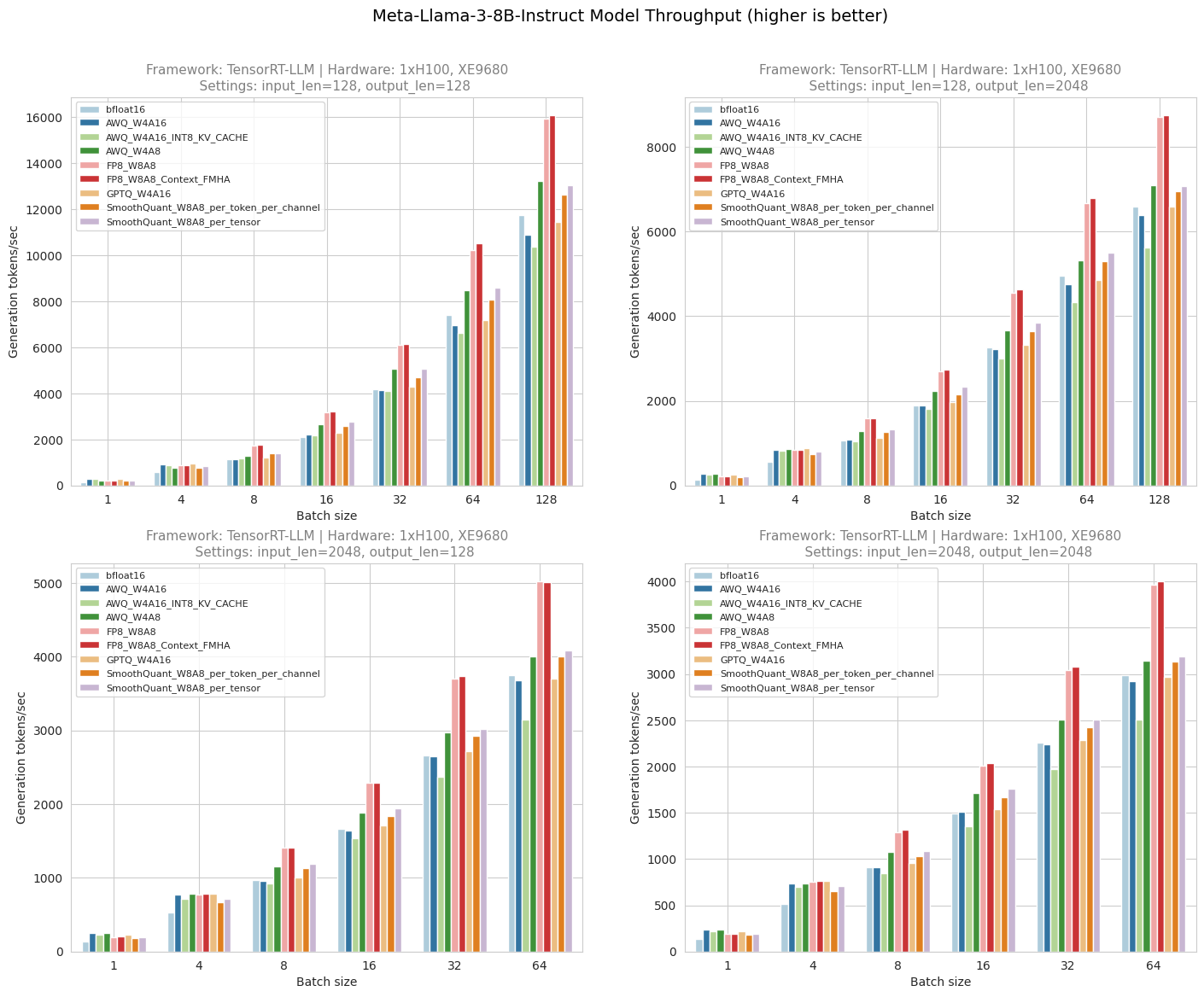
Figure 4. Throughput test result

Figure 5. Throughput at small batch sizes
Figure 4 shows the throughput numbers when running Meta-Llama-3-8B-Instruct with different batch size, input length, output length and quantization methods on XE9680 server. Figure 5 shows throughput benefits on a smaller batch size. From the diagrams, we can observe AWQ W4A16 achieves ~ 1.4x to 1.9x higher throughput for smaller batch sizes (<=4). Similarly, AWQ W4A16 with quantized KV Cache (INT8) achieves a throughput increase of about 1.3x to 1.8x for smaller batch sizes (<=4). However, its overall throughput across all batch sizes is lower compared to AWQ W4A16 without quantized KV Cache. This is due to TensorRT-LLM maintaining one KV cache per Transformer layer, necessitating as many KV caches as layers in the model. When INT8 or FP8 KV caches are enabled, input values must be quantized to 8 bits using a scaling factor, and during generation, these values are dequantized on-the-fly in the MHA/MQA kernel, making this dequantization step compute-bound for every layer [16].
AWQ W4A8 achieves ~ 1.3x to 1.9x higher throughput than bfloat16 across all batch sizes but has lower throughput than AWQ W4A16 for smaller batch sizes (<=4). FP8 outperforms bfloat16 across all batch sizes, achieving throughput gains of about 1.3x to 1.5x, but does not outperform AWQ and GPTQ for smaller batch sizes (<=4). GPTQ outperforms bfloat16 for smaller batch sizes (<=4), achieving throughput gains of approximately 1.4x to 1.7x, and performs slightly better than AWQ W4A16 across all batch sizes except when batch size is 1.
SmoothQuant (W8A8) outperforms bfloat16 across all batch sizes, achieving throughput gains of approximately 1.1x to 1.3x, but does not outperform AWQ or GPTQ for smaller batch sizes (<=4), and does not surpass FP8 at any batch size. SmoothQuant with per-tensor quantization performs slightly better than SmoothQuant with per-token and per-channel quantization, but it has the worst accuracy among all techniques, as illustrated in the MMLU accuracy test result figures.
GPU memory usage
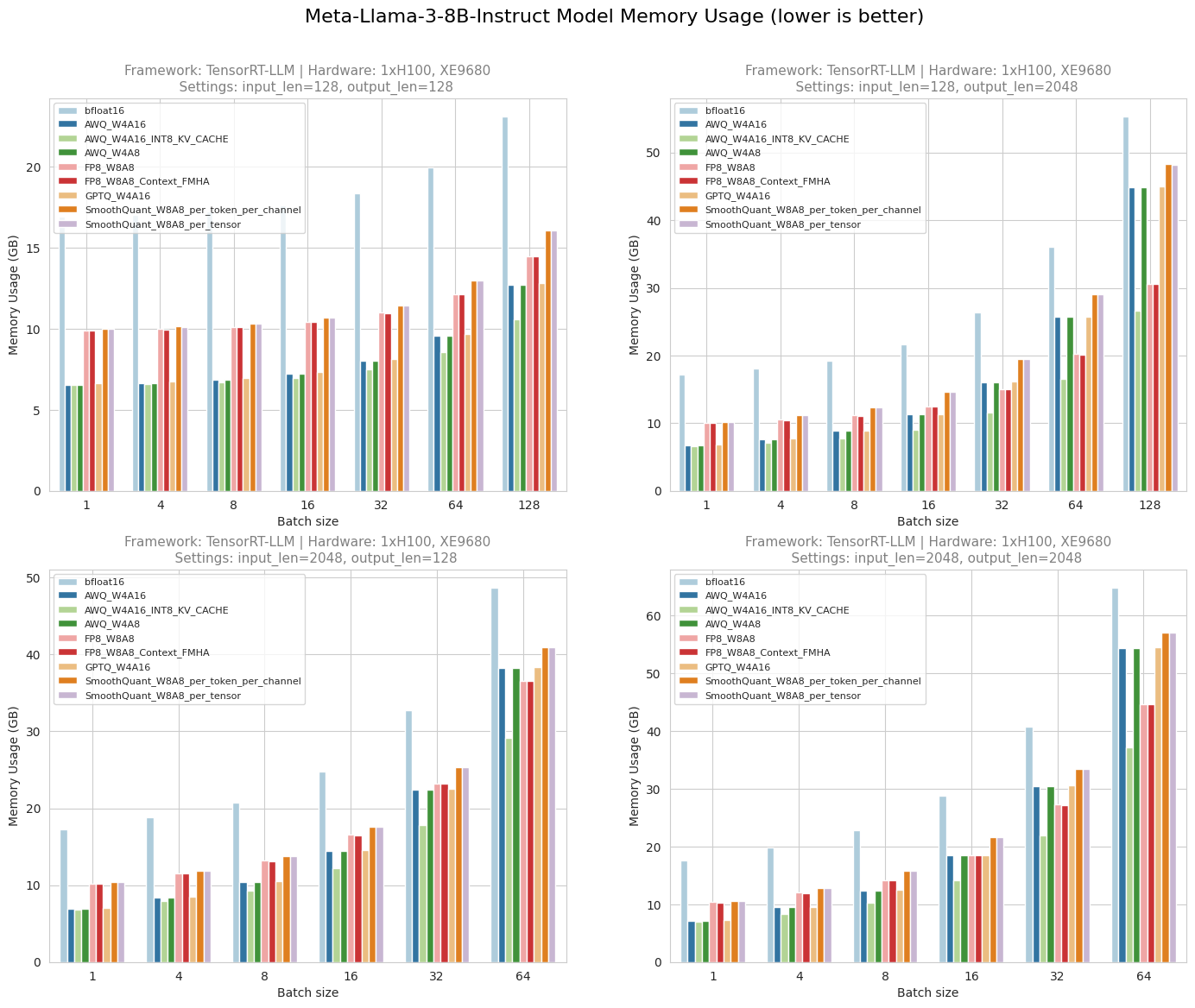
Figure 6. Peak GPU memory usage
Figure 6 shows the peak GPU memory usage when running Meta-Llama-3-8B-Instruct with different batch size, input length, output length and quantization methods on XE9680 server. The results indicate that 4-bit quantization techniques significantly reduce the memory required to run the model. Compared to the memory needed for the baseline FP16 model, quantized models using AWQ or GPTQ require half or even less memory, depending on the batch size. The AWQ model with a quantized KV cache shows lower memory consumption compared to the native AWQ model due to the reduced precision of cache values. SmoothQuant has less memory consumption than bfloat16, but its memory footprint is greater than INT4 and FP8 quantization. FP8 also consumes significantly less memory than bfloat16 but uses less memory than AWQ and GPTQ on higher batch-size >=32.
Conclusions
Table 4. Summary of different quantization techniques
Quantization Techniques | Accuracy comparison with bfloat16 | Throughput comparison with bfloat16
| Memory comparison with bfloat16
|
AWQ W4A16 | 2.2% down | ~ 1.4x to 1.9x higher throughput for smaller batch size (<=4) | ~ 1.2x to 2.5x memory saving |
AWQ W4A16 with INT8 KV Cache | 2.2% down | ~ 1.3x to 1.8x higher throughput for smaller batch size (<=4) | ~ 1.6x to 2.5x memory saving
|
AWQ W4A8
| 2.6% down | ~ 1.3x to 1.9x higher throughput for smaller batch size (<=4)
| ~ 1.2x to 2.5x memory saving
|
GPTQ W4A16 | 1.9% down | ~ 1.4x to 1.7x higher throughput for all batch size | ~ 1.2x to 2.4x memory saving
|
FP8 W8A8 | 0.1% down | ~ 1.3x to 1.5x higher throughput for all batch size | ~ 1.3x to 1.7x memory saving
|
SmoothQuant W8A8 per-tensor | 27.6% down | ~ 1.1x to 1.5x higher throughput for all batch size | ~ 1.1x to 1.6x memory saving
|
SmoothQuant W8A8 per-token+per-channel | 0.4 % down | ~ 1.1x to 1.3x higher throughput for all batch size | ~ 1.1x to 1.6x memory saving
|
Table 4 summarizes the experiment results. In terms of performance, we can conclude that for smaller batch size (<=4), AWQ W4A16 and GPTQ are preferred options. AWQ W4A16 with quantized KV cache has less throughput but more memory savings than AWQ W4A16 without quantized KV cache. Whereas for large-batch inference scenarios, such as serving scenarios (batch size >=8) AWQ W4A8, FP8, SmoothQuant are the preferred options. Specifically, FP8 shows the best performance both in terms of throughput and accuracy followed by SmoothQuant and AWQ W4A8. But SmoothQuant (per_token + per_channel quantization) has better accuracy than AWQ W4A8, whereas SmoothQuant (per_token) has the worst accuracy. AWQ and GPTQ experienced an approximate 2% accuracy drop compared to bfloat16, while FP8 and SmoothQuant per-token and per-channel quantization technique maintains accuracy like bfloat16. For some subjects one quantization technique has better accuracy than the other, which indicates the model should be limited to the applications tied to some specific subjects.
Note: the results are based on the Llama-3-8B model running on XE9680 machine with the TensorRT-LLM framework. Conclusions are valid for the models with similar architecture and size under the same setup. However, it may vary with a different model architecture or size, hardware, and deployment framework. So, one should experiment to achieve an optimized model quantization and deployment techniques under the given hardware and application constraints.
References
[1]. https://infohub.delltechnologies.com/en-us/p/deploying-llama-7b-model-with-advanced-quantization-techniques-on-dell-server/
[2]. A. Vaswani et. al, “Attention Is All You Need,” https://arxiv.org/abs/1706.03762
[3]. https://ai.meta.com/blog/meta-llama-3/
[4]. https://huggingface.co/meta-llama/Meta-Llama-3-8B-Instruct
[5]. https://www.dell.com/en-us/shop/ipovw/poweredge-xe9680
[6]. https://www.nvidia.com/en-us/data-center/h100/
[7]. https://github.com/NVIDIA/TensorRT-LLM
[8]. D. Hendrycks et. all, “Measuring Massive Multitask Language Understanding,” https://arxiv.org/abs/2009.03300
[9]. https://github.com/hendrycks/test/blob/master/categories.py
[10]. https://huggingface.co/meta-llama/Meta-Llama-3-8B
[11]. J. Lin et. al, “AWQ: Activation-aware Weight Quantization for LLM Compression and Acceleration,” https://arxiv.org/abs/2306.00978
[12]. E. Frantar et. al, “GPTQ: Accurate Post-Training Quantization for Generative Pre-trained Transformers”, https://arxiv.org/abs/2210.17323
[13]. Paulius Micikevicius et. al, “FP8 FORMATS FOR DEEP LEARNING”, https://arxiv.org/pdf/2209.05433
[14]. G. Xiao et. al, “SmoothQuant: Accurate and Efficient Post-Training Quantization for Large Language Models,” https://arxiv.org/abs/2211.10438
[15]. https://nvidia.github.io/TensorRT-LLM/performance/perf-best-practices.html
[16]. https://nvidia.github.io/TensorRT-LLM/advanced/gpt-attention.html
[17]. https://nvidia.github.io/TensorRT-Model-Optimizer/guides/_choosing_quant_methods.html
[18] https://huggingface.co/blog/llama3