




AMD Milan - BIOS Characterization for HPC
With the release of the AMD EPYC 7003 Series Processors (architecture codenamed "Milan"), Dell EMC PowerEdge servers have now been upgraded to support the new features. This blog outlines the Milan Processor architecture and the recommended BIOS settings to deliver optimal HPC Synthetic benchmark performance. Upcoming blogs will focus on the application performance and characterization of the software applications from various scientific domains such as Weather Science, Molecular Dynamics, and Computational Fluid Dynamics.
AMD Milan with Zen3 cores is the successor of AMD's high-performance second generation server microprocessor (architecture codenamed "Rome"). It supports up to 64 cores at 280w TDP and 8 DDR4 memory channels at speeds up to 3200MT/s.
Architecture
As with AMD Rome, AMD Milan’s 64 core Processor model has 1 I/O die and 8 compute dies (also called CCD or Core Complex Die) – OPN 32 core models may have 4 or 8 compute dies. Milan Processors have upgrades to the Cache (including new prefetchers at both L1 and L2 caches) and Memory Bandwidth which is expected to improve performance of applications requiring higher memory bandwidth.
Unlike Naples and Rome, Milan's arrangement of its CCDs has changed. Each CCD now features up to 8 cores with a unified 32MB L3 cache which could reduce the cache access latency within compute chiplets. Milan Processors can expose each CCD as a NUMA node node by setting the “L3 cache as NUMA Domain” ( from the iDRAC GUI ) or BIOS.ProcSettings.CcxAsNumaDomain (using racadm CLI) option to “Enabled”. Therefore, Milan’s 64 core dual-socket Processors with 8 CCDs per Processor will expose 16 NUMA domains per system in this setting. Here is the logical representation of Core arrangement with NUMA Nodes per socket = 4 and CCD as NUMA = Disabled.
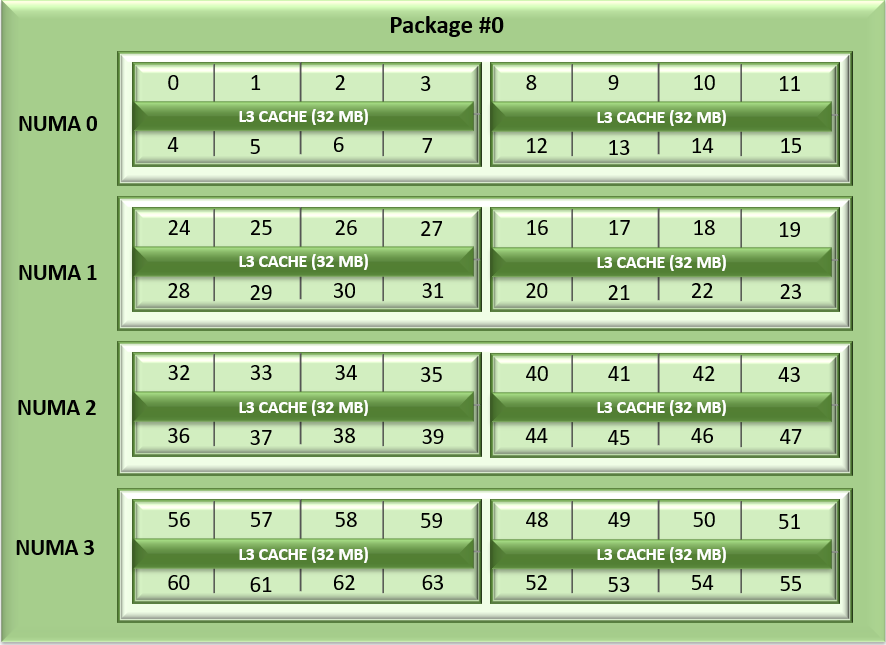
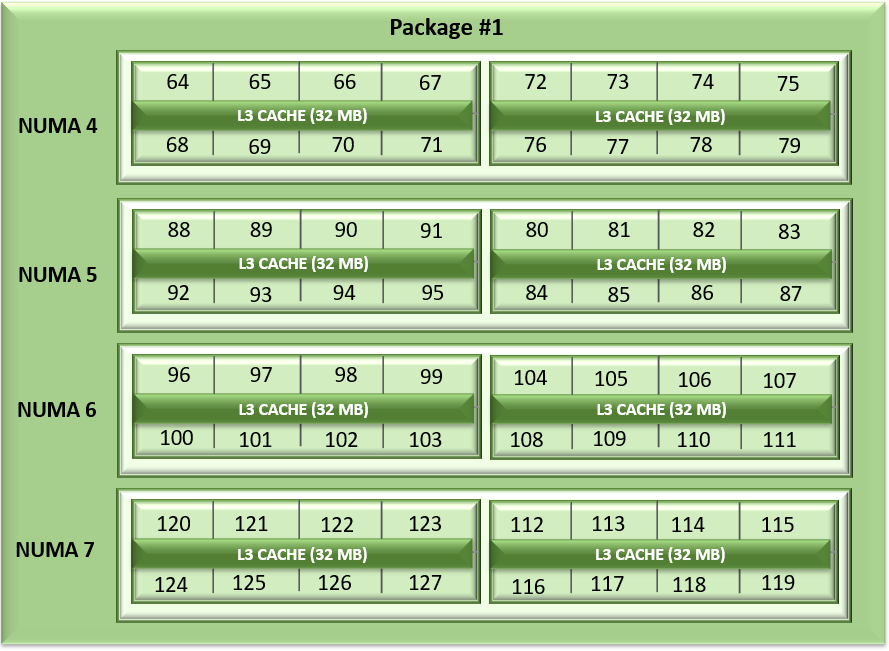
Figure1: Linear core enumeration on a dual-socket system, 64c per socket, NPS4 configuration on an 8 CCD Processor model
As with AMD Rome, AMD Milan Processors support the AVX256 instruction set allowing 16 DP FLOP/cycle.
BIOS Options Available on AMD Milan and Tuning
Processors from both Milan and Rome generations are socket compatible, so the BIOS Options are similar across these Processor generations. Server details are mentioned in Table 1 below.
Table 1: Testbed hardware and software details
Server | Dell EMC PowerEdge 2 socket servers (with AMD Milan Processors) | Dell EMC PowerEdge 2 socket servers (with AMD Rome Processors) |
OPN Cores/Socket Frequency (Base-Boost) TDP | 7763 (Milan) 64 2.45GHz – 3.5GHz 280W 256 MB | 7H12 (Rome) 64 2.6GHz – 3.3 GHz 280W 256 MB |
OPN Cores/Socket Frequency TDP | 7713 (Milan) 64 2.0GHz – 3.7GHz 225W 256 MB | 7702 (Rome) 64 2.0 GHz – 3.35 GHz 200W 256 MB |
OPN Cores/Socket Frequency TDP | 7543 (Milan) 32 2.8GHz – 3.7 GHz 225W 256 MB | 7542 (Rome) 32 2.9GHz – 3.4 GHz 225W 128 MB |
Operating System | RHEL 8.3 (4.18.0-240.el8.x86_64) | RHEL 8.2 (4.18.0-193.el8.x86_64) |
Memory | DDR4 256G (16Gb x 16) 3200 MT/s | |
BIOS / CPLD | 2.0.3 / 1.1.12 | 1.1.7 |
Interconnect | Mellanox HDR 200 (4X HDR) | Mellanox HDR 100 |
The following BIOS options were explored –
- BIOS.SysProfileSettings.SysProfile: This field sets the System Profile to Performance Per Watt (OS), Performance, or Custom mode. When set to a mode other than Custom, BIOS will set each option accordingly. When set to Custom, you can change setting of each option. Under Custom mode when C state is enabled, Monitor/Mwait should also be enabled.
- BIOS.ProcSettings.L1StridePrefetcher: When set to Enabled, the Processor provides additional fetch to the data access for an individual instruction for performance tuning by controlling the L1 stride prefetcher setting.
- BIOS.ProcSettings.L2StreamHwPrefetcher: When set to Enabled, the Processor provides advanced performance tuning by controlling the L2 stream HW prefetcher setting.
- BIOS.ProcSettings.L2UpDownPrefetcher: When set to Enabled, the Processor uses memory access to determine whether to fetch next or previous for all memory accesses for advanced performance tuning by controlling the L2 up/down prefetcher setting.
- BIOS.ProcSettings.CcxAsNumaDomain: This field specifies that each CCD within the Processor will be declared as a NUMA Domain.
- BIOS.MemSettings.MemoryInterleaving: When set to Auto, memory interleaving is supported if a symmetric memory configuration is installed. When set to Disabled, the system supports Non-Uniform Memory Access (NUMA) (asymmetric) memory configurations. Operating Systems that are NUMA-aware understand the distribution of memory in a particular system and can intelligently allocate memory in an optimal manner. Operating Systems that are not NUMA-aware could allocate memory to a Processor that is not local, resulting in a loss of performance. Die and Socket Interleaving should only be enabled for Operating Systems that are not NUMA-aware.
After setting System Profile (BIOS.SysProfileSettings.SysProfile) to PerformanceOptimized, NUMA Nodes Per Socket (NPS) to 4, and Prefetchers (L1Region,L1Stream,L1Stride,L2Stream, L2UpDown) to “Enabled” we measured the impact of CcxAsNumaDomain and MemoryInterleaving BIOS parameters on application performance. We tested the performance of the applications listed in Table 1 with following settings.
Table 2: Combinations of CCX as NUMA domain and Memory Interleaving
CCX as NUMA Domain | Memory Interleaving | |
Setting01 | Disabled | Disabled |
Setting02 | Disabled | Auto |
Setting03 | Enabled | Auto |
Setting04 | Enabled | Disabled |
With Setting01 and Setting02 (CCX as NUMA Domain = Disabled), the system will expose 8 NUMA nodes. With Setting03 and Setting04, there will be 16 NUMA nodes on a dual socket server with 64 core based Milan Processors.
Table 3: hwloc-ls and numactl -H command output on 64c server with setting01/setting02 and (listed in Table 2)
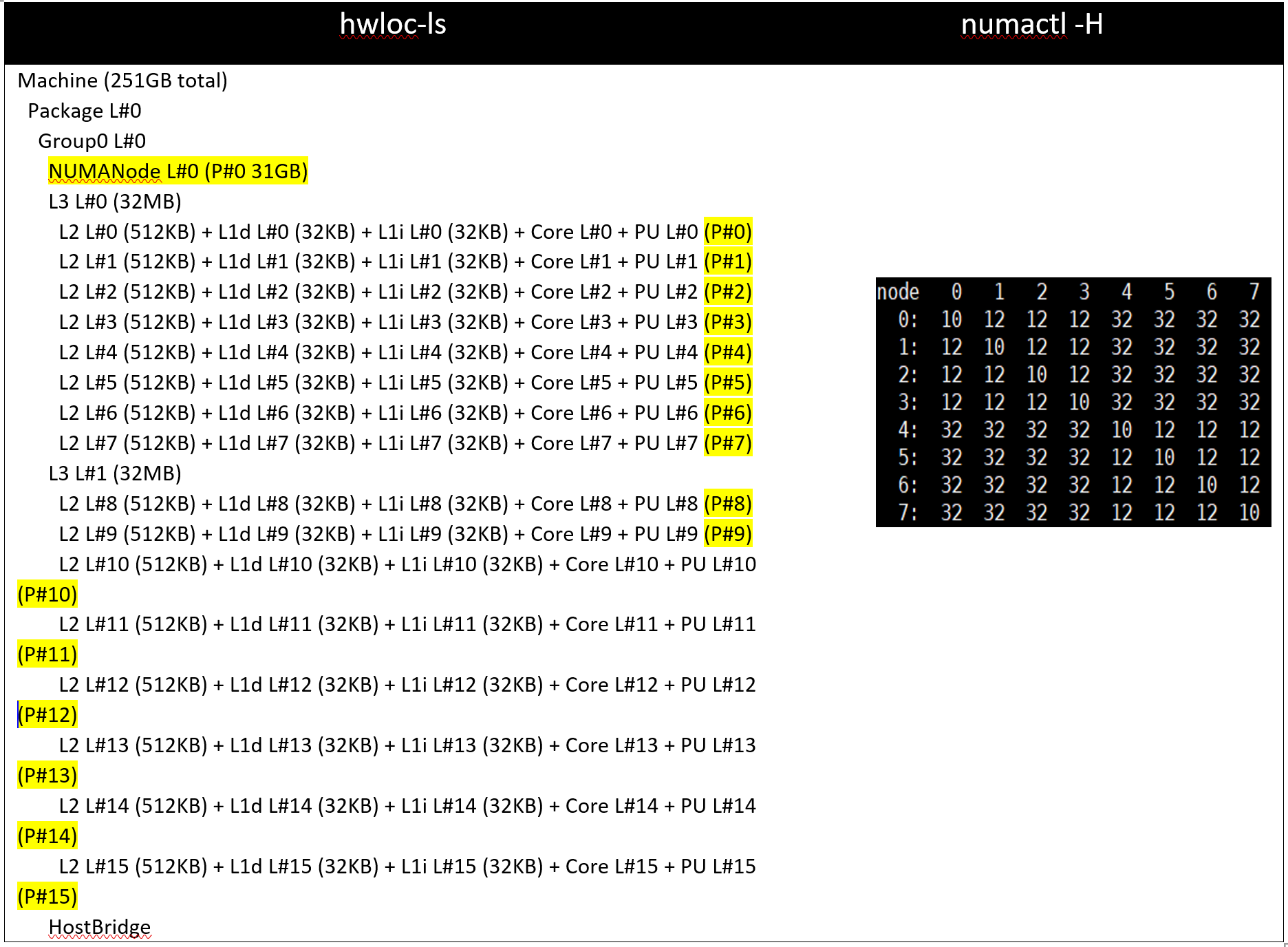
Table 4: hwloc-ls and numactl -H command output on 128 core (2x 64c) server with setting03/setting04 and (listed in Table 2)
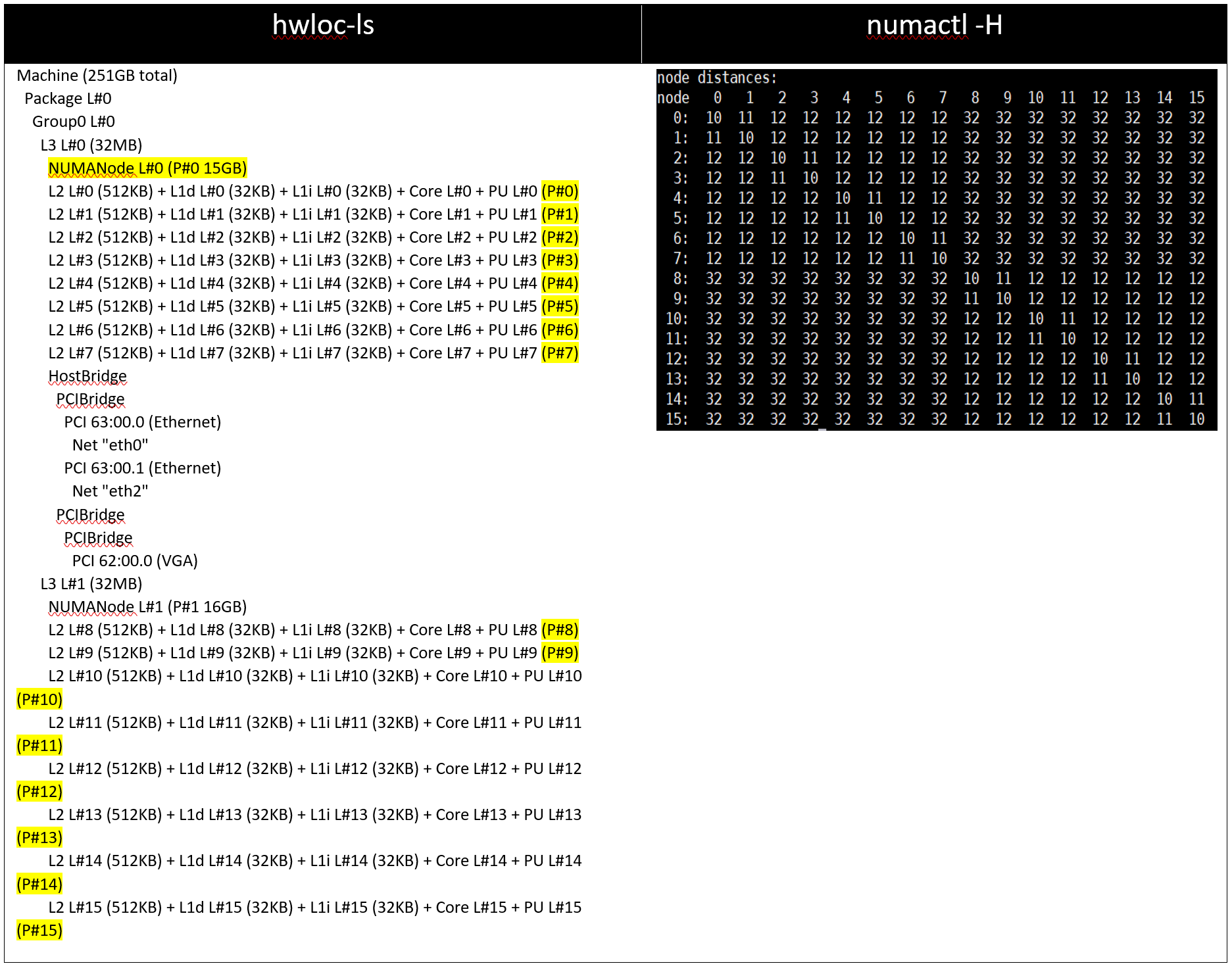
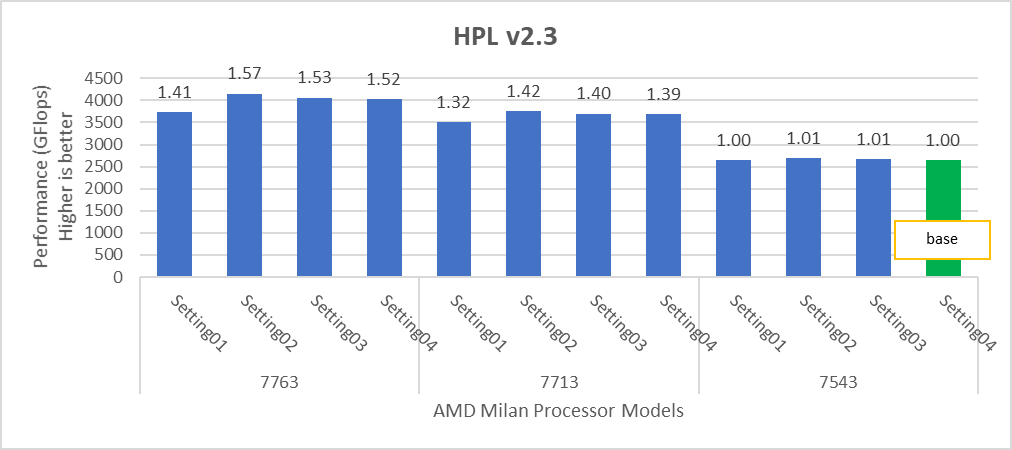
Figure 2: Relative difference in the performance of HPL by processor and BIOS settings mentioned in Table 1 and Table 2.
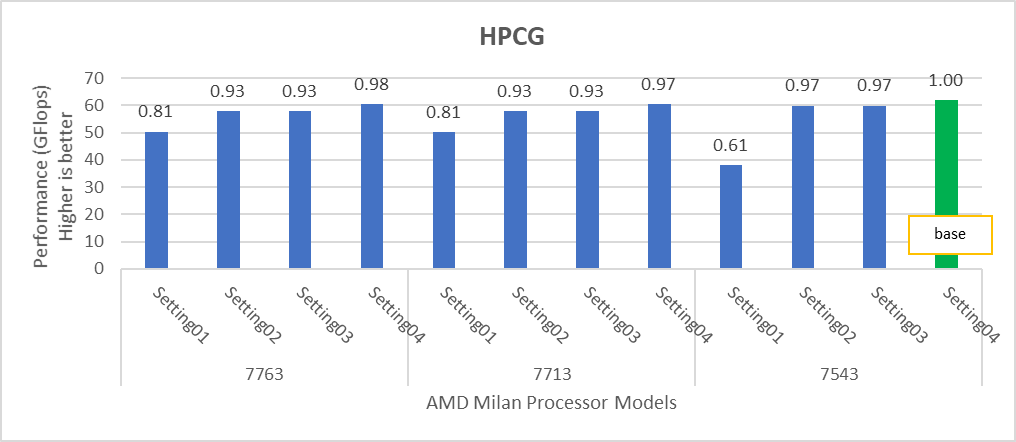
Figure 3: Relative difference in the performance of HPCG by processor and BIOS settings mentioned in Table 1 and Table 2.
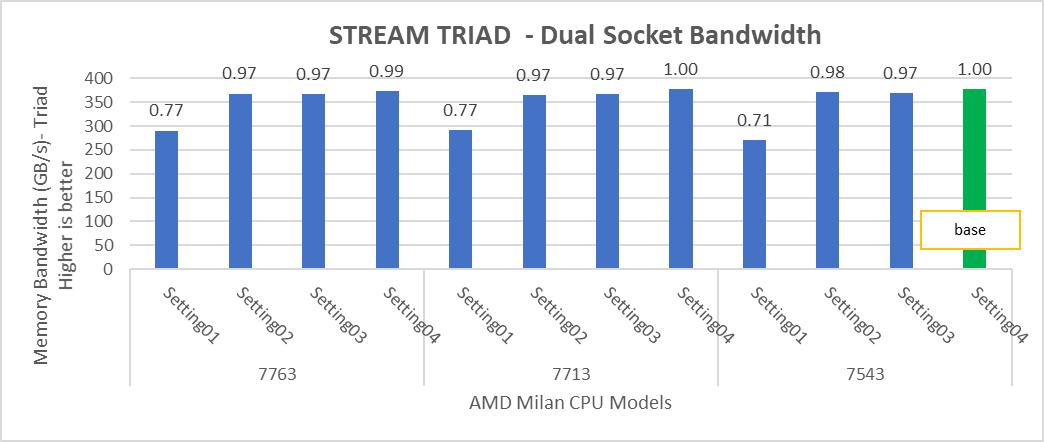
Figure 4: Relative difference in the performance of STREAM by processor and BIOS settings mentioned in Table 1 and Table 2.
HPL delivers the best performance numbers on setting02 with 82-93% efficiency depending on Processor Model, whereas STREAM and HPCG deliver better performance with setting04.
STREAM TRIAD tests generate best performance numbers at ~378 GB/s memory bandwidth across all of the 64 and 32 core Processor Models mentioned in Table 1 with efficiency up to 90%.
In Figure 4, the STREAM TRIAD performance numbers were measured by undersubscribing the server by utilizing only 16 cores on the servers. The comparison of the performance numbers by utilizing all the available cores and 16 cores per system has been shown in Figure 5. The numbers on top of the orange bars shows the relative difference.
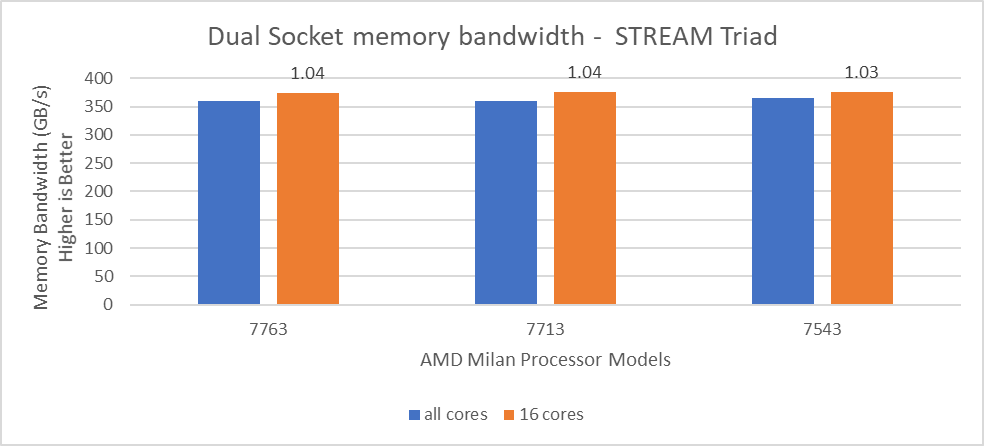
Figure 5: Relative difference in the memory bandwidth.
From Figure 5, we observed that by using 16 cores, the STREAM TRIAD test’s performance numbers were ~3-4% higher than the performance numbers measured by subscribing all available cores.
We carried out NUMA bandwidth tests using setting02 and setting04 mentioned in Table01. With setting02, system exposes a total of 8 NUMA nodes while with setting04, system exposes a total of 16 NUMA nodes with 8 cores per NUMA node In Figure 6 and 7, NUMA node presented as “c” and memory node as “m”. As an example, c0m0 represents NUMA node 0 and memory node 0. The best bandwidth numbers obtained on varying the number of threads
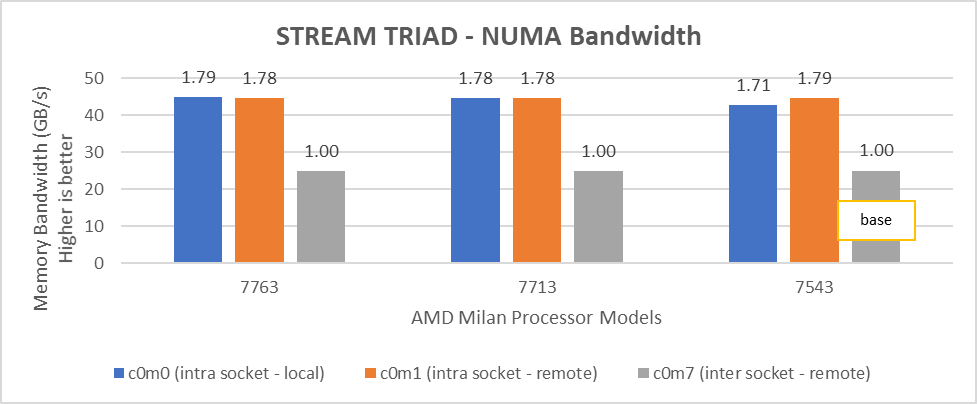
Figure 6: Local and remote NUMA memory bandwidth with CCXasNUMADomain=Disabled
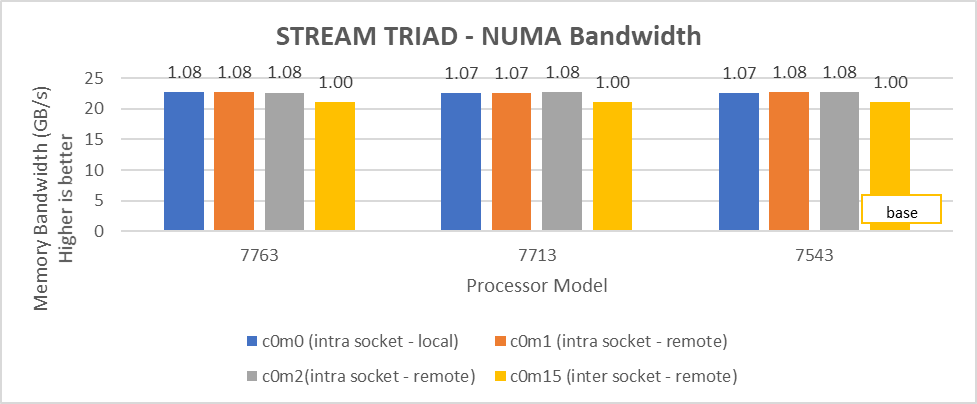
Figure 7: Local and remote NUMA memory bandwidth with CCXasNUMADomain=ENabled
We observed that the optimal intra socket local memory bandwidth numbers were obtained with 2 threads per NUMA node with setting2 on both 64 core and 32 core processor models. In Figure 6 with setting02 (Table 2) the intra socket local memory bandwidth, at 2 threads per NUMA node, can be up to 79% more than inter remote memory bandwidth. With setting02 (Figure 6) we get at least 96% higher intra socket local memory bandwidth per NUMA domain than setting04 (Figure 7).
Impact of new Prefetch options
Milan introduces two new prefetchers for L1 cache and one for L2 Cache with a total of five prefetcher options which can be configured using BIOS. We tested combinations listed in Table 5 by keeping L1 Stream and L2 Stream prefetcher as Enabled.
Table 5: Cache Prefetchers
L1StridePrefetcher | L1RegionPrefetcher | L2UpDownPrefetcher | |
setting01 | Disabled | Enabled | Enabled |
setting02 | Enabled | Disabled | Enabled |
setting03 | Enabled | Enabled | Disabled |
setting04 | Disabled | Disabled | Disabled |
We found that these new prefetchers do not have significant impact on the performance of the synthetic benchmarks covered in this blog.
InfiniBand bandwidth, message rate and scalability
For Multinode tests, the testbed was configured with Mellanox HDR interconnect running at 200 Gbps with each server having the AMD 7713 Processor Model and Preferred IO setting set to Enabled from BIOS.Along with the setting02 (Table 2) and Prefetchers (L1Region,L1Stream,L1Stride,L2Stream, L2UpDown) set to “Enabled” we were able to achieve the expected linear performance scalability for HPL and HPCG Benchmarks.
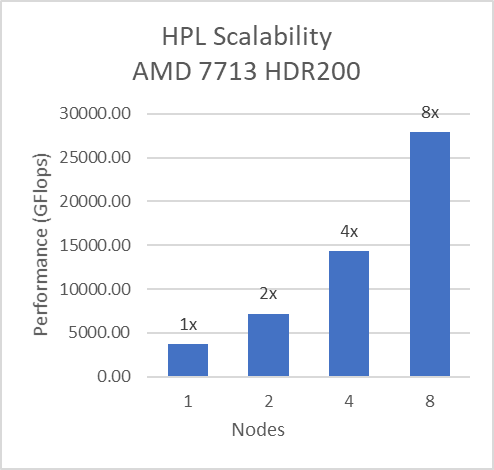
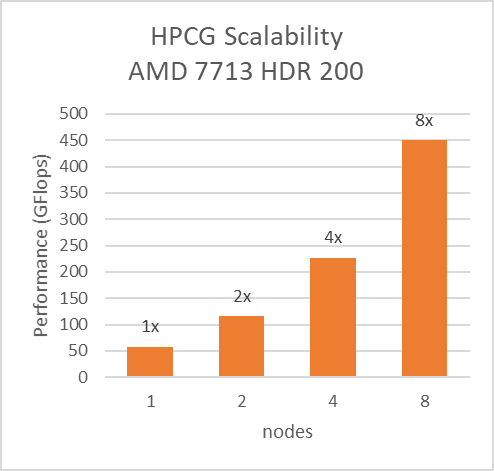
Figure 8: Multinode scalability of HPL and HPCG with setting02 (Table 2) with 7713 Processor model, HDR200 Infiniband
We tested the Message Rate, Unidirectional, and Bidirectional InfiniBand bandwidth using OSU Benchmarks and results are in Figure 9, Figure 10 and Figure 11. Except the Numa Nodes per socket setting, all other BIOS settings for these tests were same as mentioned above. The OSU Bidirectional bandwidth and OSU Unidirectional tests were carried out with Numa Nodes per socket set to 2 and the and Message rate test was carried out with Numa Nodes per socket set to 4. In Figure 9 and Figure10, the numbers on top of the orange bars represent the percentage difference between Local and Remote bandwidth performance numbers.
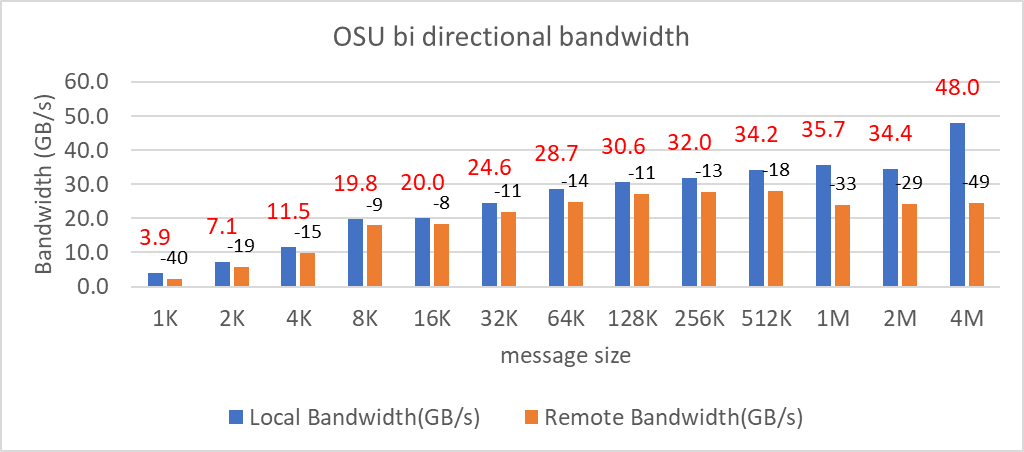
Figure 9: OSU bi-directional bandwidth test on AMD 7713, HDR 200 InfiniBand
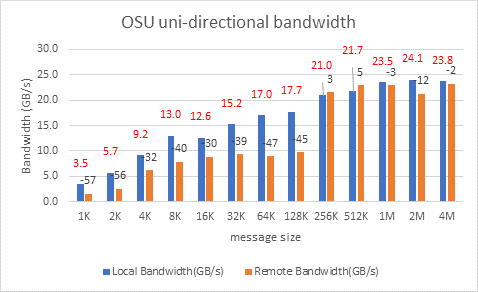 Figure 10: OSU uni-directional bandwidth test on AMD 7713, HDR 200 Infiniband
Figure 10: OSU uni-directional bandwidth test on AMD 7713, HDR 200 Infiniband
For Local Latency and Bandwidth performance numbers, the MPI process was pinned to the NUMA node 1 (closest to the HCA). For Remote Latency and Bandwidth tests, processes were pinned to NUMA node 6.
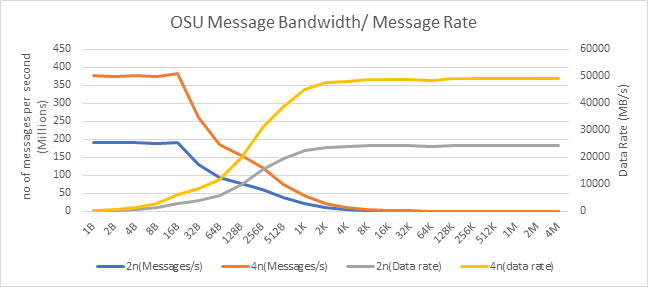
Figure 11: OSU Message rate and bandwidth performance on 2 and 4 nodes of 7713 Processor model
On 2 nodes using HDR200, we are able to achieve ~24 GB/s unidirectional bandwidth and message rate of 192 Million messages/second – almost double the performance numbers obtained on HDR100.
Comparison with Rome SKUs
In order to draw out performance improvement comparisons, we have selected Rome SKUs closest to their Milan counterparts in terms of hardware features such as Cache Size, TDP values, and Processor Base/Turbo Frequency.
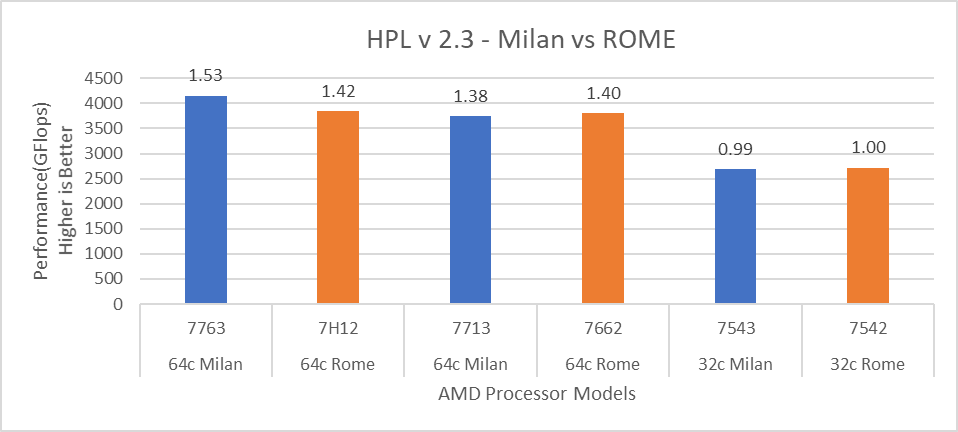
Figure 12: HPL performance comparison with Rome Processor Models
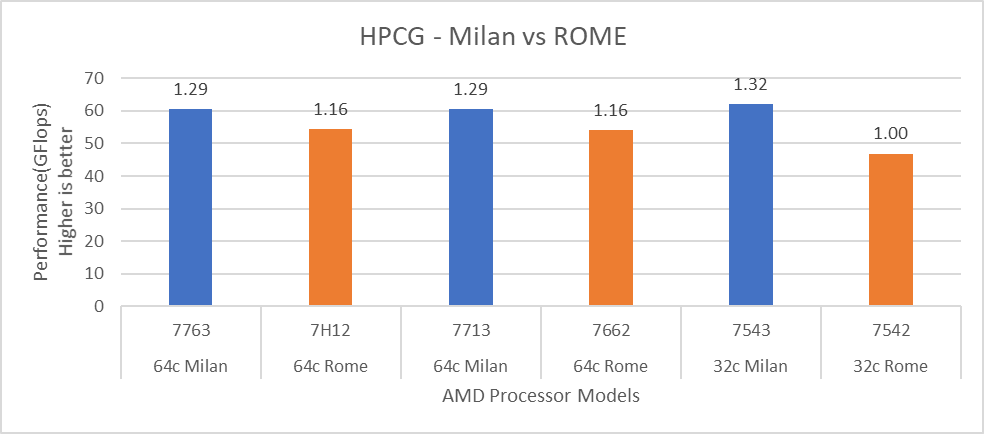
Figure 13: HPCG performance comparison with Rome Processor Models
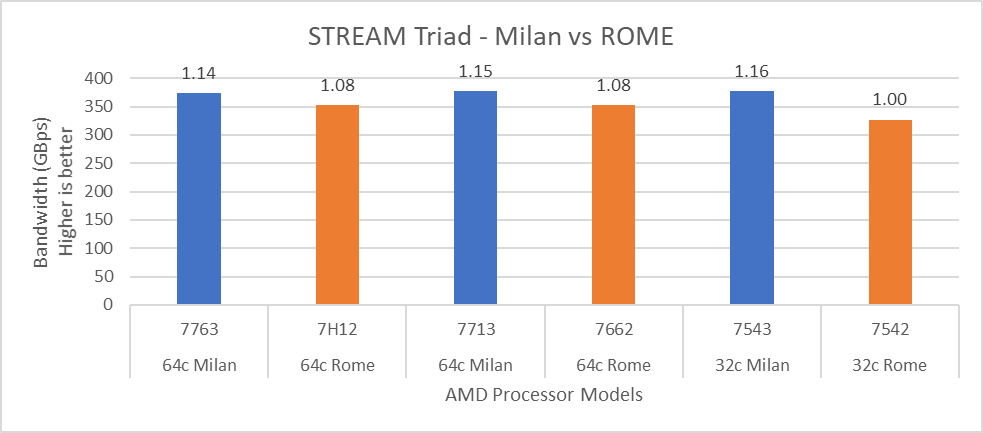
Figure 14: STREAM performance comparison with Rome Processor Models
For HPL (Figure 12) we observed that, on higher end Processor Models, Milan delivers 10% better performance than Rome. As expected, on the Milan platform, memory bandwidth bound applications like STREAM and HPCG (Figure 13 and Figure 14) gain 6-16 % and 13-32% in the performance over Rome Processor Models covered in this blog.
Summary and Future Work
Milan-based servers show expected performance upgrades, especially for the memory bandwidth bound synthetic HPC benchmarks covered in this blog. Configuring the BIOS options is important in order to get the best performance out of the system. The Hyper-Threading should be Disabled for general-purpose HPC systems, and benefits of this feature should be tested and enabled as appropriate for the synthetic benchmarks not covered in this blog.
Check back soon for subsequent blogs that describe application performance studies on our Milan Processor based cluster.