
Implementation guidance for Kubernetes
Implementation guidance for Kubernetes
-
Model Catalog
The image above shows the Model Catalog with optimized model cards that are presented to users when first opening Dell Enterprise Hub. On the top row, it is important to notice that there are several search and filter categories available that provide easy access to searching for a specific model name or author. There are also filters for model size, based on number of parameters, and license type. Another key filter to note is the platform, which filters the models that are optimized for select Dell PowerEdge Server and GPU combination. When selected, the screen shows the AI models that are designed to run on that specific grouping. This ensures that organizations are deploying the best models on top of their existing Dell infrastructure or helping the decision-making process for additional Dell Technologies hardware to matches their generative AI needs.
There are two types of Model Cards in the Model Catalog: Deploy and Train. The Deploy option, indicated by a small blue rocket icon next to the model title, enables developers to deploy the pretrained models to on-premises Dell platforms. The Train option, indicated by the small green wrench icon next to the model title, empowers users to leverage the model to train custom datasets using the on-premises Dell platforms and then deploy the fine-tuned model leveraging the trained data. Users click the model card to configure a small number of defined parameters and initiate the deployment process.
To use Kubernetes code snippets from the model card, there are several pre-requisites that must be met. Since Kubernetes allows for more utility than a container application like Docker, its installation can be challenging. For the purposes of this paper, a few key assumptions should already be met. Firstly, a proper container runtime like Docker or containerd must already be installed and configured for Kubernetes on the system. In order for the deployed containers to communicate, as well as the ability to access the API endpoint for the running model, a container networking service must also be correctly configured for the Kubernetes cluster. Finally, the correct GPU drivers and container toolkit must already be installed on the machine and Kubernetes must be configured to run on the installed GPUs.
The following components were used in this example deployment:
- Dell PowerEdge R760xa Rack Server
- 2x Intel® Xeon® Gold 6448Y Processor
- 2x NVIDIA® L40s GPU
- Local Storage (1 TB)
- Operating System: Ubuntu 22.04.4
- Kubernetes v1.28.13
- containerd 1.7.20
- NVIDIA GPU Driver Version: 535.183.01
- Container Network Interface (CNI): Flannel v0.25.5
- NVIDIA Container Toolkit Version: 1.16.1
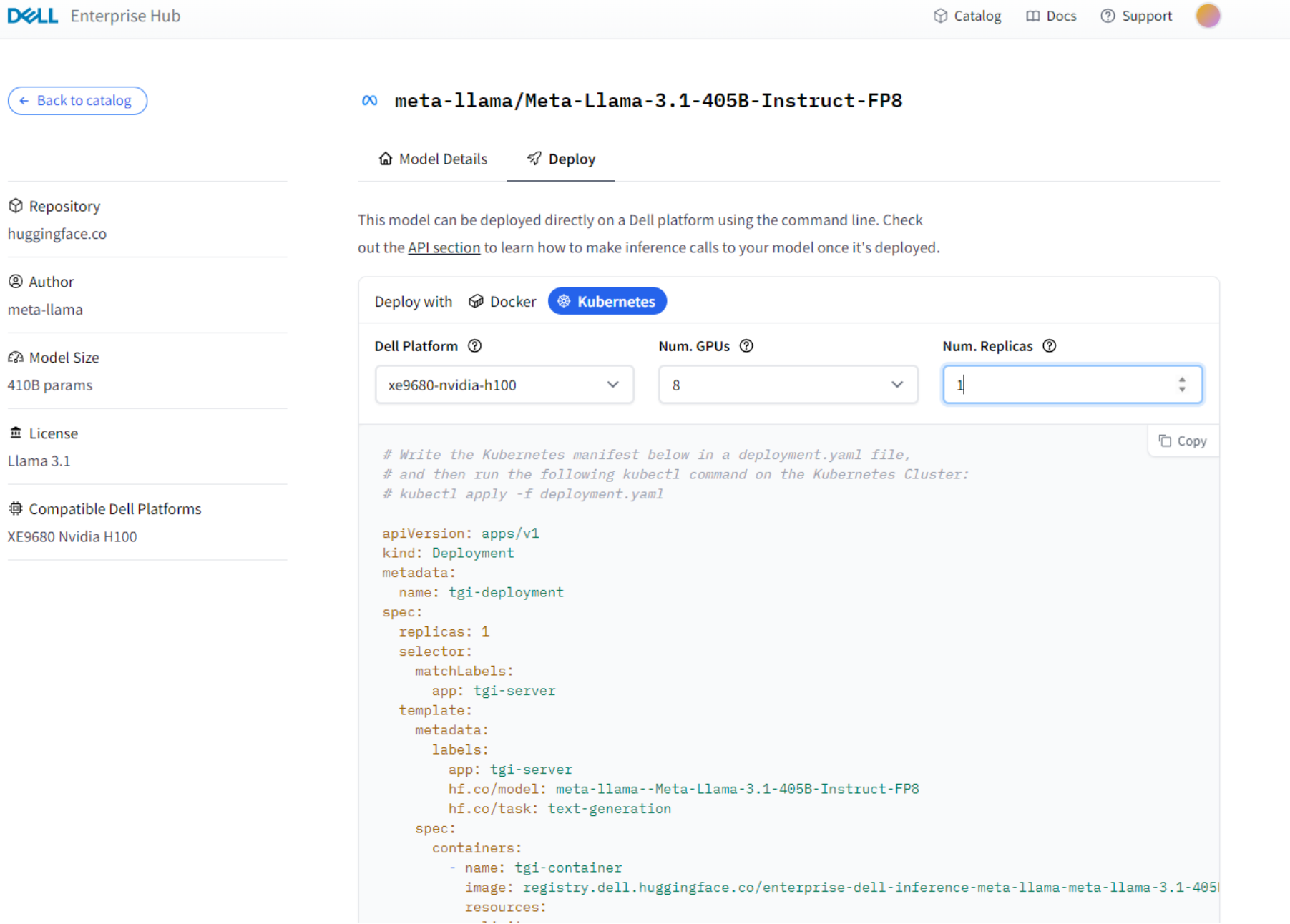
Figure 3. Sample Model Card Deploy tab, Dell Enterprise Hub on Hugging Face
In the image above, the deployment YAML for the specific model is given. The YAML code snippet specifies the components of the application so that it can be deployed to Kubernetes. Items such as the model itself, the GPU count, GPU drivers, and server ports are all defined in a YAML file to be deployed on Kubernetes. The following code snippet from Dell Enterprise Hub was used in the example for this document.
apiVersion: apps/v1
kind: Deployment
metadata:
name: tgi-deployment
spec:
replicas: 2
selector:
matchLabels:
app: tgi-server
template:
metadata:
labels:
app: tgi-server
hf.co/model: meta-llama--Meta-Llama-3-8B-Instruct
hf.co/task: text-generation
spec:
containers:
- name: tgi-container
image: registry.dell.huggingface.co/enterprise-dell-inference-meta-llama-meta-llama-3-8b-instruct
resources:
limits:
nvidia.com/gpu: 2
env:
- name: MODEL_ID
value: meta-llama/Meta-Llama-3-8B-Instruct
- name: NUM_SHARD
value: "1"
- name: PORT
value: "80"
- name: MAX_BATCH_PREFILL_TOKENS
value: "16182"
- name: MAX_INPUT_TOKENS
value: "8000"
- name: MAX_TOTAL_TOKENS
value: "8192"
- name: HF_TOKEN
value: "hf_xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx"
volumeMounts:
- mountPath: /dev/shm
name: dshm
volumes:
- name: dshm
emptyDir:
medium: Memory
nodeSelector:
nvidia.com/gpu.product: NVIDIA-L40S
---
apiVersion: v1
kind: Service
metadata:
name: tgi-service
spec:
type: LoadBalancer
ports:
- protocol: TCP
port: 80
targetPort: 80
selector:
app: tgi-server
---
apiVersion: networking.k8s.io/v1
kind: Ingress
metadata:
name: tgi-ingress
annotations:
nginx.ingress.kubernetes.io/rewrite-target: /
spec:
ingressClassName: nginx-ingress
rules:
- http:
paths:
- path: /
pathType: Prefix
backend:
service:
name: tgi-service
port:
number: 80
The YAML code above has a few portions that are important to understand for a successful deployment of a generative AI model. The top spec variables describe a few components of the physical infrastructure, such as the replicas and the GPU count. The GPU count refers to the quantity of GPUs in the system, and the replicas describe how many copies of the machine with the same GPU model and count will use the model. The env variables describe the model used, the port for connections, and the token capacity. These variables will change depending on the model and GPUs used. The node selector variable is particularly important, as it describes the location that Kubernetes will use in order to run pods on. The naming of tgi-service at the bottom of the YAML file describes the app service that the model is running on, and tgi-service contains the container, service, and ingress components that exist in the Kubernetes model. The container holds the model image, the service provides endpoints and accessibility to pods, and the ingress allows external management of the cluster. Together, all these components work to create the strong functionality of Kubernetes. Before applying the YAML file to the Kubernetes cluster, a namespace with the name hugging face was created for organization purposes.
kubectl create namespace huggingface
Once the YAML file is properly configured, the user should run an apply command to the YAML file in their Kubernetes environment in order to load the AI model onto their Kubernetes environment. After properly applying the YAML file, it is important to check that the deployment of the model was successful.
kubectl apply -f deploy-hf-llama3.1-8B-L40S.yaml
To check that the deployment was run properly, you must verify that the pod was properly deployed.
kubectl get pods -n huggingface -o wide
The Kubernetes function will show the details of all pods running in the Hugging Face namespace used to run the deployment YAML. The first time the model image is pulled, the pod will take some time to complete the pull operation and deploy. On subsequent image deployments on the same node, the deployment will attempt to use the cached model before pulling a new copy. Once the pods complete deployment, the use the describe services function to retrieve relevant information.
kubectl describe services tgi-service
Here, the output of the service should return the name, namespace, type, and IP among other information. This is where you can find the endpoint to test that your model will run properly. Taking the IP of your endpoint, the following command can be run to generate a sample output of the model:
curl http://<endpoint-IP>/generate -X POST -d '{"inputs":"What is a Large Language Model?","parameters":{"max_new_tokens":50}}' -H 'Content-Type: application/json'
An output will be displayed as a result from the model in JSON form, limited to 50 tokens in length. For production environments, there are a few features of deployment to consider. One important aspect is allowing an external IP to respond to requests so that you can request the model from outside of the local system. To do this, the following command should be run on your Kubernetes environment.
kubectl patch svc tgi-service -p '{"spec":{"externalIPs":["<External Host IP>"]}}'
For security purposes, it is also possible to obscure your Hugging Face token from Kubernetes. To do so, the following commands and edits must be done.
kubectl create secret generic hf-secret --from-literal=hf_token=<your Hugging Face token> --dry-run=client -o yaml | kubectl apply -f –
Afterwards, edit the env section of the deployment YAML to the following:
- name: HF_TOKEN
valueFrom:
secretKeyRef:
name: hf-secret
key: hf_token
Once the model has been verified to have been deployed, the model is ready to start being used for tasks. Additional features such as a user interface and retrieval augmented generation can also be added for further benefit. For an example on implementing a UI and RAG within your AI model, refer to Open Source RAG Made Easy by Dell Enterprise Hub on Dell Technologies Info Hub. For guidance on creating dynamic applications that call API endpoints to create custom interactions, refer to Hugging Face – Messages API.