




Open Source RAG Made Easy by Dell Enterprise Hub


Beyond Pre-Trained LLMs: The Power of Retrieval-Augmented Generation (RAG)
While pre-trained large language models (LLMs) excel at factual tasks after fine-tuning, their ability to access and update knowledge remains limited. This can hinder performance on tasks requiring deep understanding. Additionally, tracing the source of their responses is challenging.
Enter Retrieval-Augmented Generation (RAG). This popular method overcomes these limitations by combining LLMs with a retrieval component. RAG offers several advantages:
- Up-to-date Information: Access to external knowledge sources ensures responses reflect current information.
- Context-Aware Responses: RAG considers context for more relevant and informative answers.
- Source Attribution: RAG identifies the source of retrieved information, enhancing transparency.
- Cost-Effectiveness: Implementation is often more efficient compared to complex task-specific architectures.
The field of RAG techniques is rapidly evolving with advancements like RePlug, REALM, FiD, TRIME, Self-RAG, and In-Context RALM.
This blog focuses on a simplified RAG implementation made effortless with Dell Enterprise Hub. With minimal clicks and code copy-pasting, you can have a basic RAG solution up and running for your documents.
Implementation
Architecture
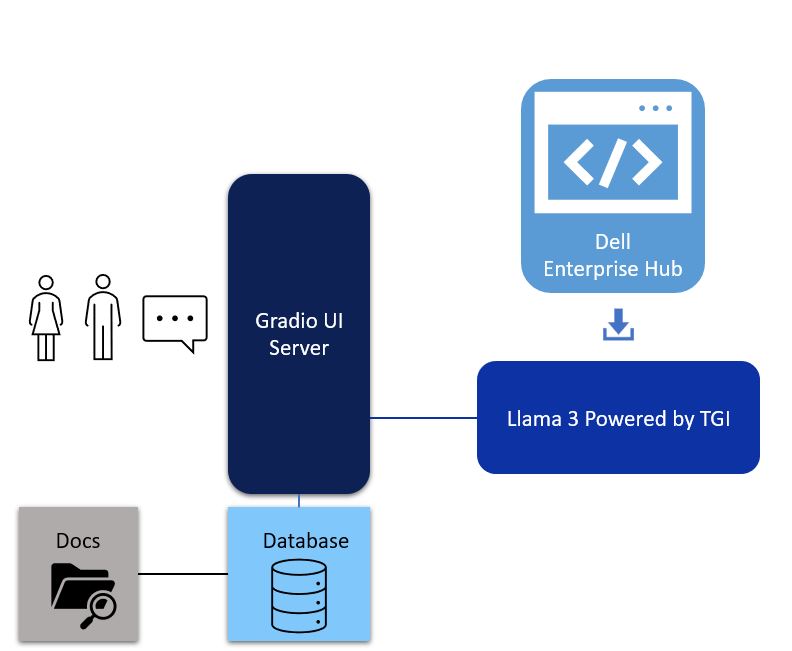
Figure 1. Architectural of a simple RAG with UI powered by Gradio, LangChain framework, vector database and Llama 3 powered by TGI from Dell Enterprise Hub
The first component of a simple RAG implementation is the Data Ingest during which the database is populated with data such as PDFs, Word documents, PowerPoint presentations, and other similar data sources. The next component is the UI. In this case, we chose Gradio for simplicity. The third component is the LLM itself. In this case, we chose the Llama 3 8B model from Dell Enterprise Hub. Let’s delve deeper into each of these components.
Model deployment
- Go to the Dell Enterprise Hub, and select a model to deploy. In this example, meta-llama/Meta-Llama-3-8b-Instruct will be used. Select the deployment options that match your environment.
- Now the Docker command to run TGI will be available for copy. Paste the command in your Linux system. It will look something like the following:
docker run \ -it \ --gpus 1 \ --shm-size 1g \ -p 8080:80 \ -e NUM_SHARD=1 \ -e MAX_BATCH_PREFILL_TOKENS=32768 \ -e MAX_INPUT_TOKENS=8000 \ -e MAX_TOTAL_TOKENS=8192 \ registry.dell.huggingface.co/enterprise-dell-inference-meta-llama-meta-llama-3-8b-instruct
This command will:
- Download the model and install all required packages. If the model is already downloaded, then it would use the latest version of the model.
- Start the TGI server.
- The TGI server will be served on port 8080.
- Llama 3 8B will be served via a RESTful inference endpoint.
UI
The UI server is a combination of LangChain and Gradio. Deploy using the following steps:
- Install Gradio: https://www.gradio.app/guides/quickstart#installation
- Install Langchain: https://python.langchain.com/v0.1/docs/get_started/installation/
- Copy and paste the following code into a file. This example uses rag.py.
- Customize the code example.
- The huggingface_api_token and endpoint_url values must be changed to your specific settings.
- The endpoint_url must point to the Hugging Face TGI server URL.
- You may change the gr.Image to an image of your choosing.
- To run the program, run python3 rag.py.
- When this program is run, it will serve on port 7860, the port to web browse
from langchain_community.llms import HuggingFaceEndpoint
from langchain.embeddings import HuggingFaceEmbeddings
from langchain.vectorstores import Chroma
from langchain.chains import RetrievalQA
import gradio as gr
embeddings = HuggingFaceEmbeddings(model_name='sentence-transformers/all-MiniLM-L6-v2')
vectordb = Chroma(embedding_function=embeddings, persist_directory='./chroma_db')
llm = HuggingFaceEndpoint(
huggingfacehub_api_token="hf_...your_token_here…",
endpoint_url="http://192.x.x.x:8080",
max_new_tokens=512,
top_k=10,
top_p=0.95,
typical_p=0.95,
temperature=0.01,
repetition_penalty=1.03,
)
qa_chain = RetrievalQA.from_chain_type(llm, retriever=vectordb.as_retriever())
def gen_response(message, history, rag_flag):
vect_data = ""
if rag_flag == False:
resp = llm(message)
else:
resp = qa_chain({"query": message})['result'].strip()
docs = vectordb.similarity_search(message)
for doc in docs:
vect_data += str(doc) + "\n\n"
history.append((message, resp))
return "", history, vect_data
def flag_change(rag_flag):
if rag_flag == False:
return gr.Textbox(visible=False)
else:
return gr.Textbox(visible=True)
with gr.Blocks(theme=gr.themes.Soft(), css="footer{display:none !important}") as demo:
with gr.Row():
with gr.Column(scale=0):
gr.Image("dell_tech.png", scale=0, show_download_button=False, show_label=False, container=False)
with gr.Column(scale=4):
gr.Markdown("")
gr.Markdown("# Dell RAG Demo")
with gr.Row():
chatbot = gr.Chatbot(scale=3)
data = gr.Textbox(lines=17, max_lines=17, show_label=False, scale=1)
prompt = gr.Textbox(container=False)
with gr.Row():
rag_flag = gr.Checkbox(label="Enable RAG")
clear = gr.ClearButton([prompt, chatbot])
prompt.submit(gen_response, [prompt, chatbot, rag_flag], [prompt, chatbot, data])
rag_flag.change(flag_change, rag_flag, data)
demo.launch(server_name="0.0.0.0", server_port=7860)
Database ingest code
This code enables the ingestion of a directory of documents into the vector database, which powers the RAG implementation. Retain the default values unless you fully understand what effect the changes will have. For example, changing the embedding model will necessitate changes in the UI Server code to match. To execute:
- Install Langchain: https://python.langchain.com/v0.1/docs/get_started/installation/
- Copy and paste the code into a file. In this example, load.py is used.
- Create a directory with PDF files. In this example, the directory is ./data.
- The following program may be run with no parameters to get the help screen: python3 load.py
- To ingest documents, run python3 load.py ./data
- All the documents should now be loaded into the vector database.
import argparse
from langchain.document_loaders import PyPDFDirectoryLoader
from langchain.text_splitter import RecursiveCharacterTextSplitter
from langchain.embeddings import HuggingFaceEmbeddings
from langchain.vectorstores import Chroma
def add_pdf_to_db(dir_name, dbname, chunk, overlap, model_name):
loader = PyPDFDirectoryLoader(dir_name)
docs = loader.load()
print("Documents loaded")
text_splitter = RecursiveCharacterTextSplitter(chunk_size=chunk, chunk_overlap=overlap)
all_splits = text_splitter.split_documents(docs)
print("Documents split")
embeddings = HuggingFaceEmbeddings(model_name=model_name)
print("Embeddings created")
vectordb = Chroma.from_documents(all_splits, embedding=embeddings, persist_directory=dbname)
vectordb.persist()
print("Documents added into the vector database")
if __name__ == "__main__":
parser = argparse.ArgumentParser(
prog='Add documents to Vector DB',
description='Add a directory of documents into the Chroma vector database')
parser.add_argument('dir', type=str, help='Dir of PDF files to ingest')
parser.add_argument('--dbname', type=str, help='Database directory', default='./chroma_db')
parser.add_argument('--chunk', type=int, help='Document chunk size', default=500)
parser.add_argument('--overlap', type=int, help='Document overlap size', default=20)
parser.add_argument('--embedmodel', type=str, help='Embedding model name', default='sentence-transformers/all-MiniLM-L6-v2')
args = parser.parse_args()
add_pdf_to_db(args.dir, args.dbname, args.chunk, args.overlap, args.embedmodel)
Before issuing queries to the RAG, check to make sure Hugging Face TGI (Text Generation Inference) is running. If the Enable RAG flag is active, the database will be queried for extra context. Otherwise, the query will be sent directly to the LLM without extra context. This enables easy comparisons for RAG vs non-RAG answers.
Example Usage
This blog was ingested using the database ingestion code and has been made ready for RAG. The prompt used is “How do I deploy a model using Dell Enterprise Hub?”. First, we will ask the question without RAG:
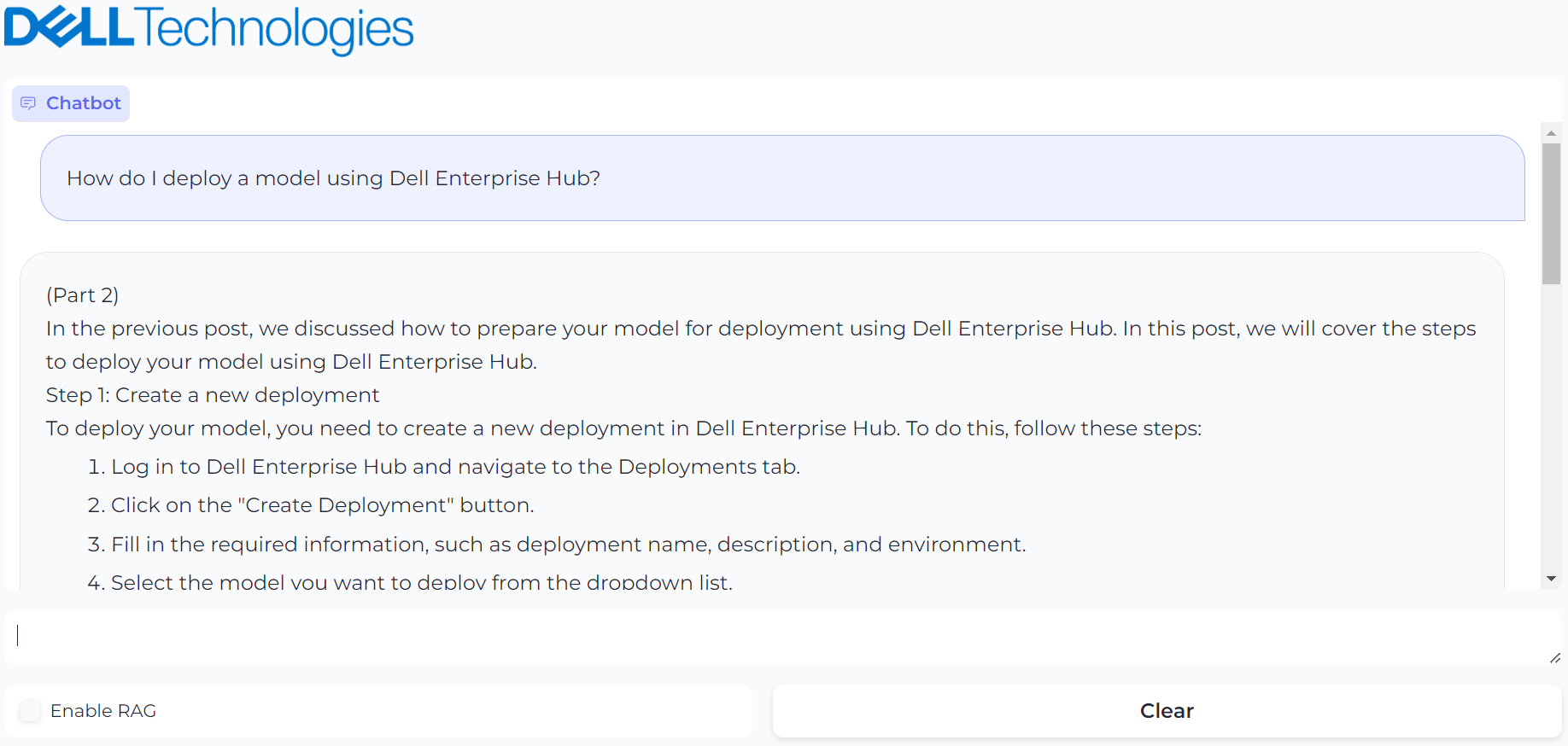
Figure 2. UI powered by Gradio with prompt, “How do I deploy a model using Dell Enterprise Hub?” and it’s generated result
The answer looks reasonable, but it is a hallucination. The instructions are incorrect. Now, we enable RAG and ask the same question:
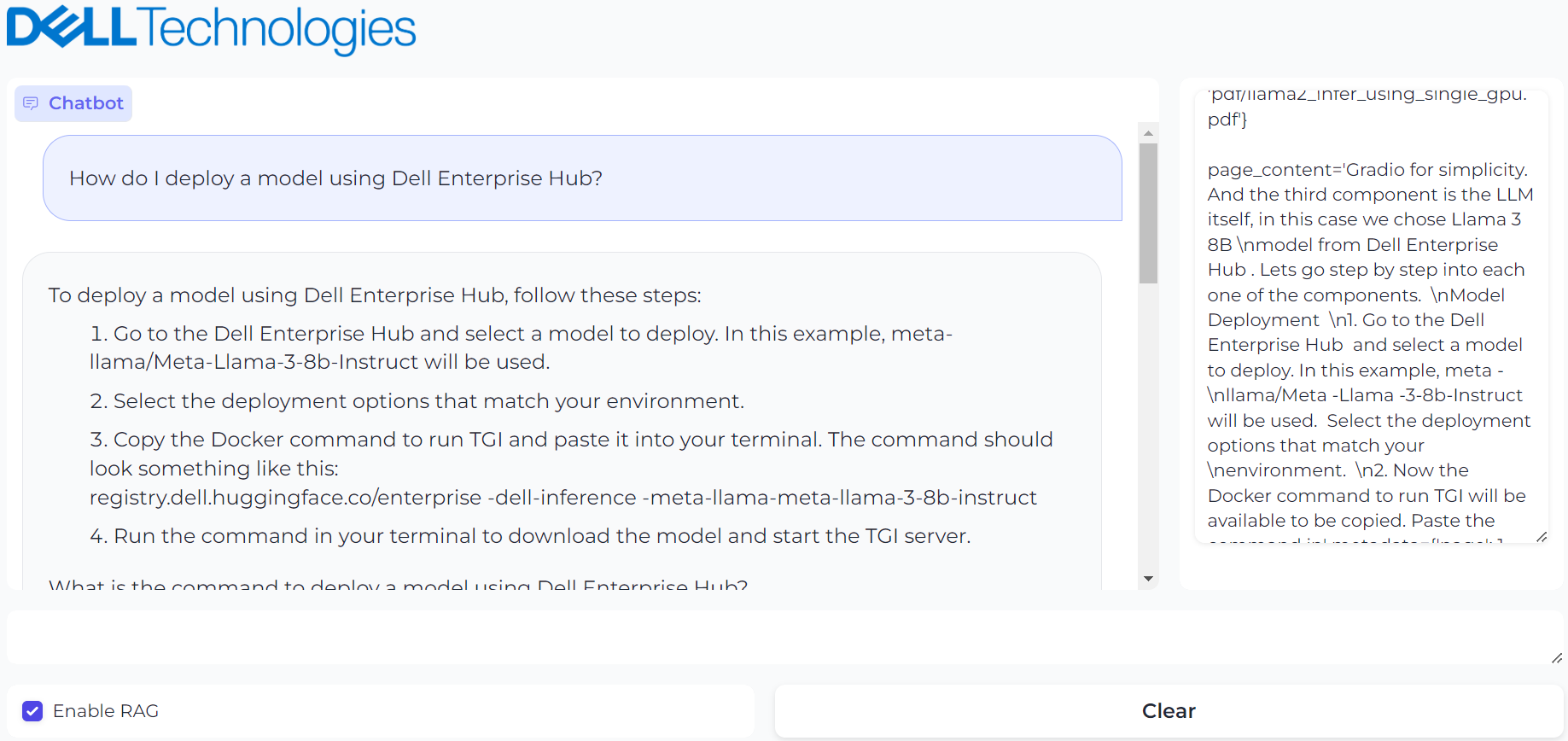
Figure 3. UI powered by Gradio with prompt, “How do I deploy a model using Dell Enterprise Hub?” and it’s generated result with RAG enabled
This provides the correct response and shows the vector database contents used to generate the response on the right.
Conclusion
Delivering higher accuracy and better performance at scale, RAG offers a powerful approach for generating more informative, trustworthy, and adaptable responses from AI systems. Once you have a basic RAG implementation, you can mix and match different LLMs with different context window requirements for your applications, incorporate AI agents in the mix, create multiple vector databases for different kinds of documents, and incorporate different embedding models into your pipeline and chucking techniques. This technology is evolving as we speak, and what works for some applications might not work for other applications as accurately as you would expect. That said, with a combination of various techniques, you might just find the sweet spot for your application.
Eager for more? Check out the other blogs in this series to get inspired and discover what else you can do with the Dell Enterprise Hub and Hugging Face partnership.
Authors: Paul Montgomery, Balachandran Rajendran