




Will More Disks Lead to Better Performance in APEX File Storage in AWS?
Mon, 08 Jan 2024 18:02:59 -0000
|Read Time: 0 minutes
Related Blog Posts

Unveiling APEX File Storage for AWS Enhancements
Wed, 13 Dec 2023 15:36:10 -0000
|Read Time: 0 minutes
We are thrilled to announce the latest version of APEX File Storage for AWS! This release brings a multitude of enhancements to elevate your AWS file storage experience, including expanded AWS regions with the support for additional EC2 instance types, a Terraform module for streamlined deployment, larger raw capacity, and additional OneFS features support.
APEX File Storage delivers Dell’s leading enterprise-class high-performance scale-out file storage as a software-defined customer-managed offer in the public cloud. Based on PowerScale OneFS, APEX File Storage for AWS brings enterprise file capabilities and performance and delivers operational consistency across multicloud environments, simplifying hybrid cloud environments by facilitating seamless data mobility between on-premises and the cloud with native replication and making it the perfect option to run AI workloads. APEX File Storage can enhance customers’ development and innovation initiatives by combining proven data services such as multi-protocol access, security features, and a proven scale-out architecture with the flexibility of public cloud infrastructure and services. APEX File Storage enables organizations to run the software they trust directly in the public cloud without retraining their staff or refactoring their storage architecture.
What's New?
1. Additional EC2 instance types support
We've expanded compatibility by adding support for a wider range of EC2 instance types. This means you have more flexibility in choosing the instance type that best suits your performance and resource requirements. We now support the following EC2 instance types:
- EC2 m5dn instances: m5dn.8xlarge, m5dn.12xlarge, m5dn.16xlarge, m5dn.24xlarge
- EC2 m6idn instances: m6idn.8xlarge, m6idn.12xlarge, m6idn.16xlarge, m6idn.24xlarge
- EC2 m5d instances: m5d.24xlarge
- EC2 i3en instances: i3en.12xlarge
Please note that it is required to run PoC if you intend to use m5d.24xlarge or i3en.12xlarge EC2 instance types. Please contact your Dell account team for the details.
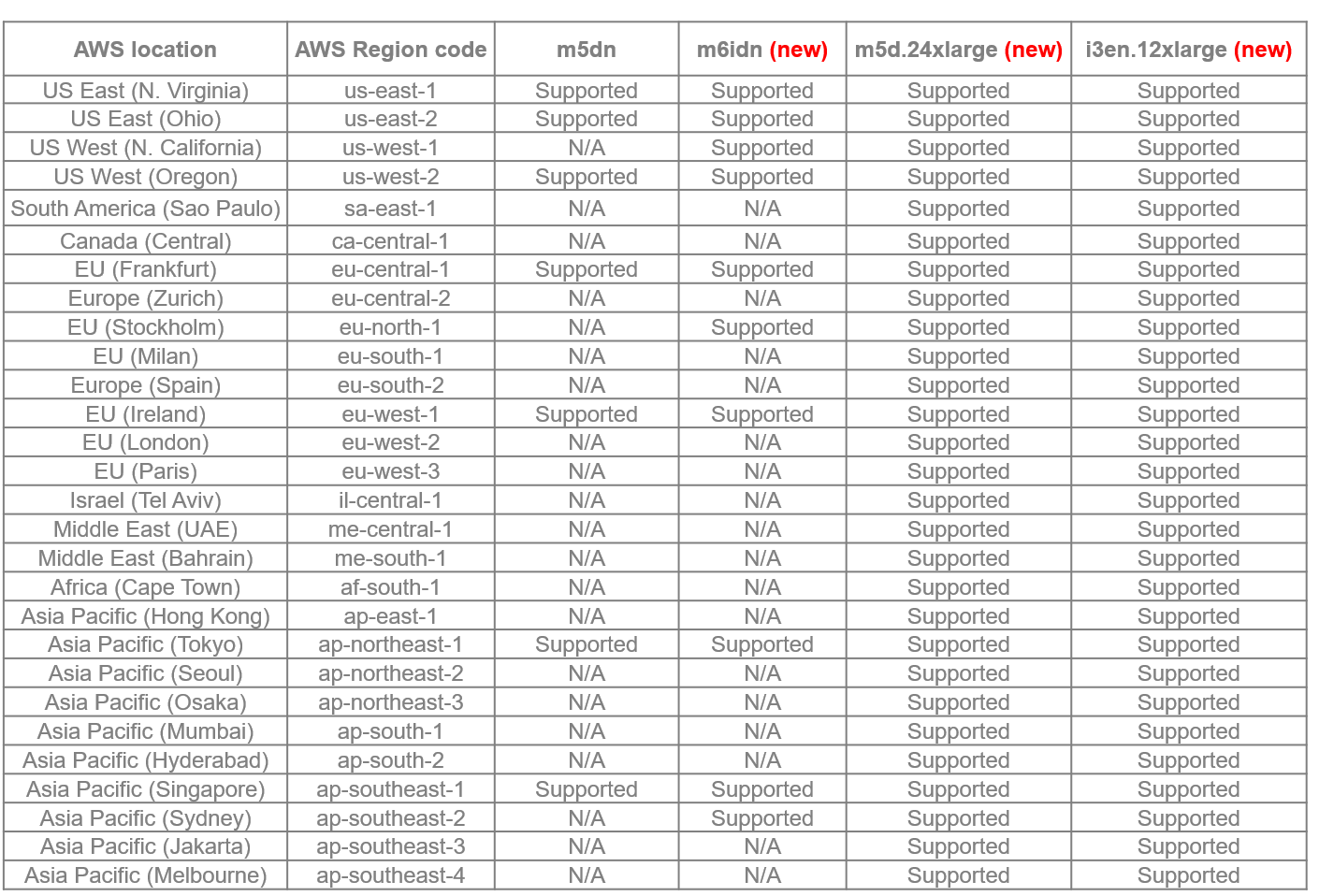
2. Extended AWS regions support
APEX File Storage is now available in more AWS regions than ever before. A total of 28 regions are available for you. We understand that our users operate globally, and this expansion ensures that you can leverage APEX File Storage wherever your AWS resources are located. The following table lists all available regions for different EC2 instance types:
3. Terraform module: auto-deployment made effortless
Simplify your deployment process with our new Terraform module, which automates the AWS resource deployment process to ensure a smooth and error-free experience.
Once you fulfill the deployment prerequisites, you can deploy a cluster with a single Terraform command. For more details, refer to documentation: APEX File Storage for AWS Deployment Guide with Terraform. Stay tuned for a blog with additional details coming soon.
4. Larger raw capacity: more room for your data
Your data is growing, and so should your storage capacity. APEX File Storage for AWS can now support up to 1.6PiB raw capacity, enabling workloads that produce a vast amount of data such as AI and ensuring that you have ample space to store, manage, and scale your data effortlessly.
5. Additional OneFS features support
The OneFS features not supported in the first release of APEX File Storage for AWS are now supported, including:
- Enhanced Protocols: With HDFS protocol support, you can seamlessly integrate HDFS into your workflows, enhancing your data processing capabilities in AWS. Enjoy expanded connectivity with support for HTTP and FTP protocols, providing more flexibility in accessing and managing your files.
- Quality of Service – SmartQoS: Ensure a consistent and reliable user experience with SmartQoS, which enables you to prioritize workloads and applications based on performance requirements.
- Immutable Data Protection - SmartLock: Enhance data protection by leveraging SmartLock to create Write Once Read Many (WORM) files, providing an added layer of security against accidental or intentional data alteration.
- Large File Support: Address the needs of large-scale data processing with improved support for large files, facilitating efficient storage and retrieval. A single file size can be up to 16TiB now.
Learn More
For deployment instructions and detailed information on these exciting new features, refer to our documentation:
- APEX File Storage for AWS
- terraform-aws-onefs Terraform Module
- Technical white paper for AI use case: APEX File Storage for AWS with Amazon SageMaker
- Technical White Paper for M&E use case: APEX File Storage for AWS for Video Edit in AWS
- APEX File Storage for AWS Manual Deployment Guide
- APEX File Storage for AWS Deployment Guide with Terraform
- APEX File Storage for AWS Interactive Demo
Author: Lieven Lin

Alert in IIQ 5.0.0 – Part I
Wed, 13 Dec 2023 17:40:06 -0000
|Read Time: 0 minutes
Alert is a new feature introduced with the release of IIQ 5.0.0. It provides the capability and flexibility to configure alerts based on the KPI threshold.
This blog will walk you through the following aspects of this feature:
- Introduction to Alert
- How to configure alerts using Alert
Let’s get started:
Introduction
IIQ 5.0.0 can send email alerts based on your defined KPI and threshold. The supported KPIs are listed in the following table:
KPI Name | Description | Scope |
Protocol Latency SMB | Average latency within last 10 minutes required for the various operations for the SMB protocol | Across all nodes and clients per cluster. |
Protocol Latency NFS | Average latency within last 10 minutes required for the various operations for the NFS protocol. | Across all nodes and clients per cluster. |
Active Clients NFS | The current number of active clients using NFS. The client is active when it is transmitting or receiving data. | Across all nodes per cluster. |
Active Clients SMB 1 | The current number of active clients using SMB 1. The client is active when it is transmitting or receiving data. | Across all nodes per cluster. |
Active Clients SMB 2 | The current number of active clients using SMB 2. The client is active when it is transmitting or receiving data. | Across all nodes per cluster. |
Connected Clients NFS | The current number of connected clients using NFS. The client is connected when it has an open TCP connection to the cluster. It can transmit or receive data or it can be in an idle state. | Across all nodes per cluster. |
Connected Clients SMB | The current number of connected clients using SMB. The client is connected when it has an open TCP connection to the cluster. It can transmit or receive data or it can be in an idle state. | Across all nodes per cluster. |
Pending Disk Operation Count | The average pending disk operation count within the last 10 minutes. It is the number of I/O operations that are pending at the file system level and waiting to be issued to an individual drive. | Across all disks per cluster. |
CPU Usage | The average usage of CPU cores including the physical cores and hyperthreaded core within last 10 minutes. | Across all nodes per cluster. |
Cluster Capacity | The current used capacity for the cluster. | N/A |
Nodepool Capacity | The current used capacity for the node pool in a cluster. | N/A |
Drive Capacity | The current used capacity for a drive in a cluster. | N/A |
Node Capacity | The current used capacity for a node in a cluster. | N/A |
Network Throughput Equivalency | Checks whether the network throughput for each node within the last 10 minutes is within the specified threshold percentage of the average network throughput of all nodes in the node pool for the same time. | Across all nodes per node pool. |
Each KPI requires a threshold and a severity level, together forming an alert rule. You can customize the alert rules to align with specific business use cases.

Here is an example of an alert rule:
If CPU usage (KPI) is greater than or equal to 96% (threshold), a critical alert (severity) will be triggered.
The supported severities are:
- Emergency
- Critical
- Warning
- Information
You can combine multiple alert rules into a single alert policy for easy management purposes.
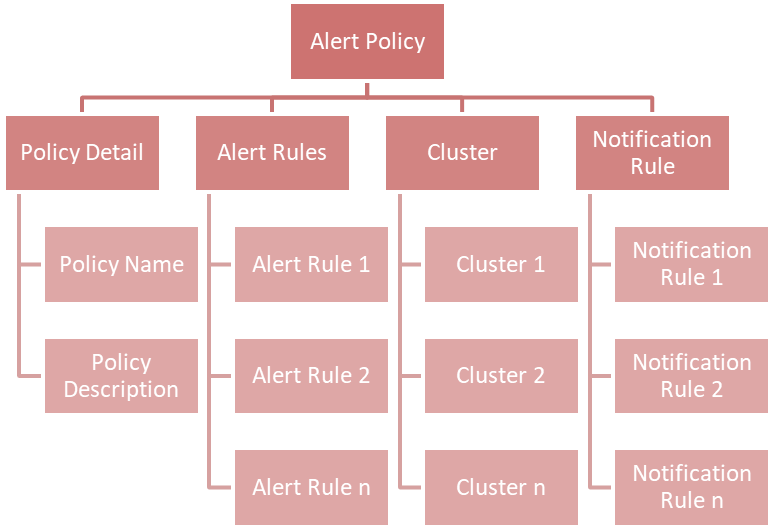
If you take a look at the chart above, you will find a new concept called Notification Rule. This is used to define the recipients' Email address and from what severity they will receive an Email:
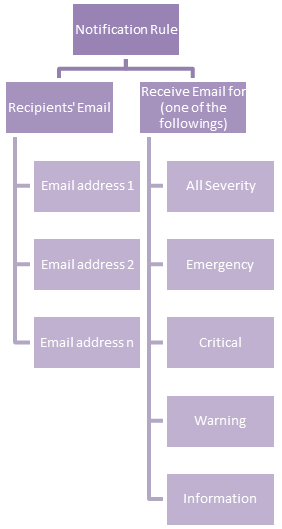
An example of a notification rule is like this: for user A (user_a@lled.com) and user B (user_b@lled.com), they both will receive Email alerts from all severity.
If you combine the above two examples and put them into the view of alert policy, you will get:
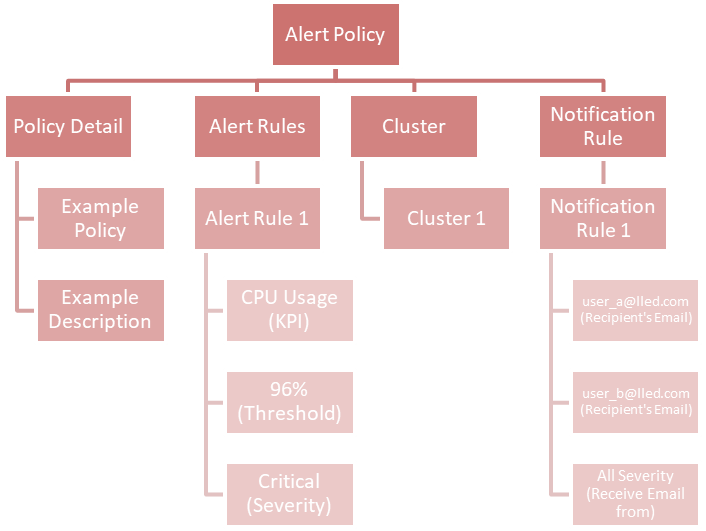
At this point, you should understand the big picture of the alert feature in IIQ 5.0.0. In my next post, I will walk you through the details of how to configure it.