




Understanding the Value of AMDs Socket to Socket Infinity Fabric
Download PDFMon, 16 Jan 2023 13:44:23 -0000
|Read Time: 0 minutes
Summary
AMD socket-to-socket Infinity Fabric increases CPU-to-CPU transactional speeds by allowing multiple sockets to communicate directly to one another through these dedicated lanes. This DfD will explain what the socket-to-socket Infinity Fabric interconnect is, how it functions and provides value, as well as how users can gain additional value by dedicating one of the x16 lanes to be used as a PCIe bus for NVMe or GPU use.
Introduction
Prior to socket-to-socket Infinity Fabric (IF) interconnect, CPU-to-CPU communications generally took place on the HyperTransport (HT) bus for AMD platforms. Using this pathway for multi-socket servers worked well during the lifespan of HT, but developing technologies pushed for the development of a solution that would increase data transfer speeds, as well as allow for combo links.
AMD released socket-to-socket Infinity Fabric (also known as xGMI) to resolve these bottlenecks. Having dedicated IF links for direct CPU-to- CPU communications allowed for greater data-transfer speeds, so multi-socket server users could do more work in the same amount of time as before.
How Socket-to-Socket Infinity Fabric Works
IF is the external socket-to-socket interface for 2-socket servers. The architecture used for IF links is a combo of serializer/deserializer (SERDES) that can be both PCIe and xGMI, allowing for sixteen lanes per link and a lot of platform flexibility. xGMI2 is the current generation available and it has speeds that reach up to 18Gbps; which is faster than the PCIe Gen4 speed of 16Gbps. Two CPUs can be supported by these IF links. Each IF lane connects from one CPU IO die to the next, and they are interwoven in a similar fashion, directly connecting the CPUs to one- another. Most dual-socket servers have three to four IF links dedicated for CPU connections. Figure 1 depicts a high- level illustration of how socket to socket IF links connect across CPUs.
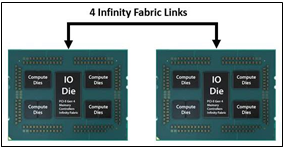
Figure 1 – 4 socket to socket IF links connect two CPUs
The Value of Infinity Fabric Interconnect
Socket to socket IF interconnect creates several advantages for PowerEdge customers:
- Dedicated IF lanes are routed directly from one CPU to the other CPU, ensuring inter-socket communications travel the shortest distance possible
- xGMI2 speeds (18Gbps) exceed the speeds of PCIe Gen4, allowing for extremely fast inter-socket data transfer speeds
Furthermore, if customers require additional PCIe lanes for peripheral components, such as NVMe or GPU drives, one of the four IF links are a cable with a connector that can be repurposed as a PCIe lane. AMD’s highly optimized and flexible link topologies enable sixteen lanes per socket of Infinity Fabric to be repurposed. This means that 2S AMD servers, such as the PowerEdge R7525, have thirty-two additional lanes giving a total of 160 PCIe lanes for peripherals. Figure 2 below illustrates what this would look like:
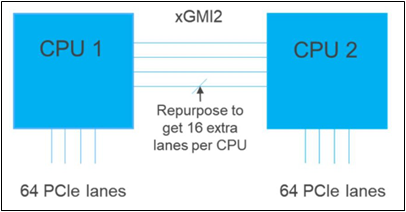
Figure 2 – Diagram showing additional PCIe lanes available in a 2S configuration
Conclusion
AMDs socket-to-socket Infinity Fabric interconnect replaced the former HyperTransport interconnect in order to allow massive amounts of data to travel fast enough to avoid speed bottlenecks. Furthermore, customers needing additional PCIe lanes can repurpose one of the four IF links for peripheral support. These advantages allow AMD PowerEdge servers, such as the R7525, to meet our server customer needs.
Related Documents

Understanding the Value of AMDs Socket to Socket Infinity Fabric
Tue, 17 Jan 2023 00:43:22 -0000
|Read Time: 0 minutes
Summary
AMD socket-to-socket Infinity Fabric increases CPU-to-CPU transactional speeds by allowing multiple sockets to communicate directly to one another through these dedicated lanes. This DfD will explain what the socket-to-socket Infinity Fabric interconnect is, how it functions and provides value, as well as how users can gain additional value by dedicating one of the x16 lanes to be used as a PCIe bus for NVMe or GPU use.
Introduction
Prior to socket-to-socket Infinity Fabric (IF) interconnect, CPU-to-CPU communications generally took place on the HyperTransport (HT) bus for AMD platforms. Using this pathway for multi-socket servers worked well during the lifespan of HT, but developing technologies pushed for the development of a solution that would increase data transfer speeds, as well as allow for combo links.
AMD released socket-to-socket Infinity Fabric (also known as xGMI) to resolve these bottlenecks. Having dedicated IF links for direct CPU-to- CPU communications allowed for greater data-transfer speeds, so multi-socket server users could do more work in the same amount of time as before.
How Socket-to-Socket Infinity Fabric Works
IF is the external socket-to-socket interface for 2-socket servers. The architecture used for IF links is a combo of serializer/deserializer (SERDES) that can be both PCIe and xGMI, allowing for sixteen lanes per link and a lot of platform flexibility. xGMI2 is the current generation available and it has speeds that reach up to 18Gbps; which is faster than the PCIe Gen4 speed of 16Gbps. Two CPUs can be supported by these IF links. Each IF lane connects from one CPU IO die to the next, and they are interwoven in a similar fashion, directly connecting the CPUs to one- another. Most dual-socket servers have three to four IF links dedicated for CPU connections. Figure 1 depicts a high- level illustration of how socket to socket IF links connect across CPUs.
Figure 1 – 4 socket to socket IF links connect two CPUs
The Value of Infinity Fabric Interconnect
Socket to socket IF interconnect creates several advantages for PowerEdge customers:
- Dedicated IF lanes are routed directly from one CPU to the other CPU, ensuring inter-socket communications travel the shortest distance possible
- xGMI2 speeds (18Gbps) exceed the speeds of PCIe Gen4, allowing for extremely fast inter-socket data transfer speeds
Furthermore, if customers require additional PCIe lanes for peripheral components, such as NVMe or GPU drives, one of the four IF links are a cable with a connector that can be repurposed as a PCIe lane. AMD’s highly optimized and flexible link topologies enable sixteen lanes per socket of Infinity Fabric to be repurposed. This means that 2S AMD servers, such as the PowerEdge R7525, have thirty-two additional lanes giving a total of 160 PCIe lanes for peripherals. Figure 2 below illustrates what this would look like:
Figure 2 – Diagram showing additional PCIe lanes available in a 2S configuration
Conclusion
AMDs socket-to-socket Infinity Fabric interconnect replaced the former HyperTransport interconnect in order to allow massive amounts of data to travel fast enough to avoid speed bottlenecks. Furthermore, customers needing additional PCIe lanes can repurpose one of the four IF links for peripheral support. These advantages allow AMD PowerEdge servers, such as the R7525, to meet our server customer needs.

The Value of Using Four-Channel Optimized AMD EPYCTM CPUs in PowerEdge Servers
Mon, 16 Jan 2023 13:44:27 -0000
|Read Time: 0 minutes
Summary
AMD recently launched their 2nd generation of AMD EPYCTM CPUs, and with this launch came the announcement of an additional set of four- channel optimized SKUs. Considering AMD CPUs have eight memory channels, there has been uncertainty as to why these SKUs were created and how they are beneficial. This DfD will educate readers on the architecture modifications made for four-channel optimized AMD EPYCTM CPUs, as well as the suggested use cases and value they bring to PowerEdge servers.
Introduction
Most 2nd generation AMD EPYCTM CPUs contain four memory controllers each with two memory channels; a total of eight memory slots that need to be populated for an optimized configuration. However, several CPU SKUs were modified to optimize performance with only four memory slots populated. These four-channel optimized SKUs require only two memory controllers to be fully populated for an optimized solution, and ultimately provide a lower cost alternative to traditional eight-channel solutions. The remaining channels can always be filled in if more memory is required.
Four-Channel Architecture and Positioning
These four-channel optimized CPUs, such as the AMD EPYCTM 7252 and the AMD EPYCTM 7282, contain a unique architecture that was designed to best support two fully populated memory controllers. Figure 1 below illustrates at a high level the architecture differentiation between four- channel optimized and eight-channel optimized CPUs.
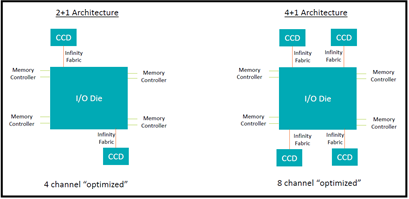
Figure 1 – Block diagram illustrating the distinctions between four-channel optimized and eight-channel optimized architectures
The Core Complex Die, or CCD, count is reduced from four to two per CPU. Both memory controllers closest to the CCD quadrant should be populated with two memory modules so the I/O die can route and distribute data packages across the smallest travel distance possible. Populating this way enables performance similar to eight-channel data transfer speeds for specific workloads. Additionally, reducing the number of CCDs lowers the total solution cost, effectively generating an increased performance per price value proposition.
Positioning
Various workloads were tested to compare performance with the eight-channel optimized SKUs. Most workloads do indeed gain an increased performance per price. Customers that prioritize pricing over everything else should find the cost-savings of four-channel optimized CPUs an attractive feature to consider.
However, there are some limitations and caveats that make this technology inadequate for specific workloads. The most obvious caveat is that by populating only four memory modules per CPU, the memory bandwidth and latency are essentially halved, and this should be considered for customers running memory- dense workloads. Additionally, the CPU base/max clock frequency have been slightly reduced and the total L3 cache has been halved. Please reference Figure 2 below for Dell EMC recommended positioning:
WORKLOAD | AVERAGE PERFORMANCE PER PRICE VARIANCE (7282 4ch vs. 7302 4ch) |
BENCHMARK(S) |
RECOMMENDED POSITIONING |
Collaboration (Conference, Web Conference, IM, Email, Enterprise Social Networks, File Sharing) |
+10% | SPECint 2017 | RECOMMENDED - Exceptional increase in performance per price, with minimal risk of negative impact |
Web Serving (HTTP, PHP, Javascript) | +7% | Apache, PHP Bench | RECOMMENDED - Exceptional increase in performance per price, with minimal risk of negative impact |
Web Based Applications (Java) | +7% | DeCapo, Renaissance | RECOMMENDED - Exceptional increase in performance per price, with minimal risk of negative impact |
Content Creation (Video Encoding, Image Processing) | +6% | Graphics-Magick, gimp, gegl | RECOMMENDED - Exceptional increase in performance per price, with minimal risk of negative impact |
Video Rendering |
+5% | Blender, C-Ray | NOT RECOMMENDED - Despite having marginal increase in performance per price, limited core count can become disadvantageous |
Databases (Excluding Enterprise class) |
+4% | Redis, RocksDB, Cassandra | NOT RECOMMENDED - Despite having averaged increase in performance per price, too much variance occurred for tested DBs, as some DB had large decrease in performance |
Compress |
+4% | 7-Zip, XZ | NOT RECOMMENDED - Despite having marginal increase in performance per price, lower core frequencies can become disadvantageous |
Compile |
+1% | Build GCC, Build LLVM, Build PHP | NOT RECOMMENDED - Despite having marginal increase in performance per price, lower core frequencies can become disadvantageous |
Memory (Bandwidth and Latency) | -1% | STREAM, RAMSPEED | NOT RECOMMENDED - There is limited-to-no increase in performance per price |
HPC | -2% | NPB, NAMD, GROMACS, DGEMM | NOT RECOMMENDED - There is limited-to-no increase in performance per price |
Conclusion
AMD four-channel optimized CPUs can provide great value for various workloads and should be considered by customers that prioritize a lower TCO as an alternative to AMD eight-channel optimized CPUs.