




SQL Server 2022 Backup Using T-SQL and Dell PowerFlex Storage Snapshots
Fri, 04 Nov 2022 04:56:21 -0000
|Read Time: 0 minutes
Introduction
Challenges with conventional database backups
Conventional SQL Server database backups read the data from the host to write it to the backup target location. Similarly, during the restore operation, the data is read back to the host and written to the database datafiles. Although this method allows both incremental and full backups, it poses significant challenges to mission-critical databases:
- Conventional backup and restore operations use host resources, such as CPU, memory, and I/O, which may end up impacting database performance.
- As database capacity grows, backing up the larger dataset takes longer time that can range from minutes to hours. This issue gets worse during restore operations when the business is waiting for the restore to finish and for the database to become online again.
Why Storage snapshots?
Many companies are using storage snapshots to overcome the above challenges. Dell PowerFlex software-defined storage snapshots provide the following advantages for SQL Server backup:
- You can create and restore storage snapshots in seconds regardless of the database size.
- Since snapshot creation or restore operation is so fast, the database host resources are not impacted.
- PowerFlex storage snapshots are consistent and writable, allowing the snapshot to serve as a point-in-time copy (for purposes such as mounting test, development, or reporting database copies).
- PowerFlex snapshots are thin and keep only the data changes that happened since the snapshot was created hence providing space efficiency better than incremental backups.
- Final and most important advantage is that together with Microsoft APIs, you can use PowerFlex snapshots for SQL Server backup and restore operations.
SQL Server storage backup APIs
It is not new for the SQL Server backup process to take advantage of storage snapshots. This has been done for many years using Virtual Device Interface (VDI) or Volume Shadow Copy Service (VSS) APIs. By using these APIs and backup software, together with PowerFlex, provides all the storage snapshot advantages that are mentioned above, and allows the snapshots to be valid backups of the database.
The new Transact-SQL snapshot backup feature
With SQL Server 2022, Microsoft introduced a new way of creating database backups using storage snapshots: Transact-SQL (T-SQL) snapshot backup. This method does not require the use of either VDI or VSS APIs and can work for both Windows and Linux.
The new T-SQL snapshot backup workflow is as follows:
- A T-SQL backup command is issued, that stops write operations to the database by acquiring a lock. The command can include one, multiple, or all databases.
- The backup administrator takes a storage-level snapshot of the database (or databases).
- A second T-SQL backup command is issued, resuming databases operations and saving the backup’s metadata to a file. This metadata file is required if the storage snapshot is used for database recovery.
Here's an example of using a T-SQL snapshot:
The following example shows how to perform backup and recovery operations on a database that is called tpcc, using the new T-SQL snapshot backup feature with PowerFlex snapshots.
Backup operation
Backup step 1: Suspend database
Suspend the database using the following T-SQL command:
ALTER DATABASE tpcc SET SUSPEND_FOR_SNAPSHOT_BACKUP = ON;
In this command, a single-user database is suspended, blocking any further operations. The following output shows successful suspension:
Database 'tpcc' acquired suspend locks in session 54.
I/O is frozen on database tpcc. No user action is required. However, if I/O is not resumed promptly, you could cancel the backup.
Database 'tpcc' successfully suspended for snapshot backup in session 54.
Note: For more information about how to suspend multiple or all user databases, see Microsoft documentation.
Backup step 2: Take a PowerFlex snapshot of database volumes
Once the database is suspended, a snapshot of the database volumes is created using PowerFlex Manager UI, REST APIs, or PowerFlex Command Line Interface (CLI).
In this example, the snapshot includes both the datafiles and transaction log volumes. This allows the snapshot to serve multiple purposes:
- To create stand-alone database instances for purposes such as reporting, testing, and development (as it contains a consistent image of both the data and log).
- To restore both the data and log if both were corrupted. In that case, both the data and log volumes are restored, and the database is recovered to the last transaction log backup.
- If the active transaction log survived the disaster, only the data volumes are restored, and the database can perform a full recovery of all committed transactions.
The following figure is an example of creating a snapshot using PowerFlex Manager UI:
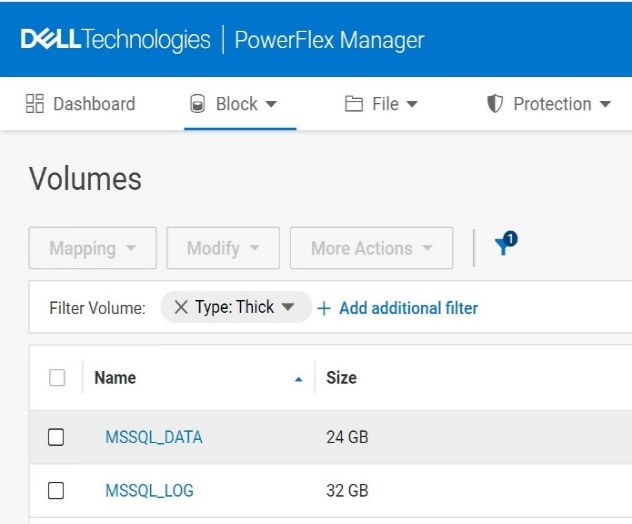
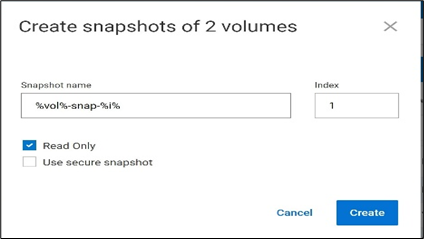
Figure1. Creating a snapshot using PowerFlex CLI
Run the following command to create a snapshot using PowerFlex CLI:
scli --snapshot_volume --volume_name MSSQL_DATA, MSSQL_LOG --snapshot_name MSSQL_DATA-snap-1,MSSQL_LOG-snap-1 --read_only
Sample output:
Snapshots on 2 volumes created successfully
Consistency group ID: b10f52c800000002
Source volume MSSQL_DATA => 20f0895f00000004 MSSQL_DATA-snap-1
Source volume MSSQL_LOG => 20f0896000000005 MSSQL_LOG-snap-1
Backup step 3: Take T-SQL metadata backup of the database
When the snapshot is created, use the following command to create the metadata file and resume database write operations:
BACKUP DATABASE tpcc TO DISK = 'C:\mssql_metadata_backup\tpcc_metadata.bkm' WITH METADATA_ONLY,MEDIANAME='PowerFlex-MSSQL_DATA-Snapshot-backup';
In this step, the metadata file of the database tpcc is stored in the specified path. This command also releases the database lock and allows the database operations to resume.
Sample output:
I/O was resumed on database tpcc. No user action is required.
Database 'tpcc' released suspend locks in session 54.
Database 'tpcc' originally suspended for snapshot backup in session 54 successfully resumed in session 54.
Processed 0 pages for database 'tpcc', file 'tpcc' on file 5.
BACKUP DATABASE successfully processed 0 pages in 0.003 seconds (0.000 MB/sec.
Simulating a database corruption
There could be different reasons for a database to require recovery, such as due to datafiles deletion, disks being formatted or overwritten, physical block corruptions, and so on. In this example, we will drop a large table and recover the database to a point in time before the drop.
To show the database recovery that includes data that is added after the snapshot creation, we create a new table after the snapshot is taken and insert a record to that table. That record is a part of the next transaction log backup. Finally, we drop the customer table and validate the database recovery.
Step 1: Create a new table after the snapshot was taken, and insert a known record to the table
Run the following command to create a table and insert a known record into the table:
create table returns ( returnID int, returnName varchar(255));
insert into returns values (1,'sampleValue');
returnID | returnName |
1 | sampleValue |
Step 2: Take a transaction log backup
The following command creates a log backup which includes the returns table data. The database recovery uses this log backup.
BACKUP LOG tpcc TO DISK = 'C:\mssql_tail_log_backup\tpcc_tail_log_before_disaster.bkm';
Note: It is a best practice to create periodic transaction log backups, as demonstrated above.
Step 3: Simulate a database corruption
For demonstration purposes, we simulate database corruption by dropping the customer table by running the following command:
drop table tpcc.dbo.customer;
Recovery operations
Database recovery happens in two steps:
- First, we restore the database data using the storage snapshot.
- Next, we recover the database using the transaction log backup.
Recovery step 1: Bring the database offline
Before we restore the database, if it is still up (depends on the type of corruption), set the database offline by running the following command:
alter database tpcc set offline;
Recovery step 2: Bring the database disks offline
Before restoring the storage snapshot of the database disks, set the disks offline to avoid any leftover locks. You can use either disk management or PowerShell commands.
Set-Disk -Number 1 -isOffline $True
Note: In this example only the data disk is set to offline, as the active transaction log remained intact and there is no reason to overwrite it with the log snapshot.
Recovery step 3: Restore the database data volume snapshot
Restore the PowerFlex database data volumes using the snapshot. This can be done from the PowerFlex UI, REST APIs, or PowerFlex CLI.
Following is an example of restoring the snapshot using PowerFlex CLI:
scli --overwrite_volume_content --source_vol_name MSSQL_DATA-snap-1 --destination_vol_name 'MSSQL_DATA'
Sample output:
Overwrite volume content can remove data and should not be called during I/O operations or on mounted volumes. Press 'y' and then Enter to confirm: y
Overwrite volume content was completed successfully
Recovery step 4: Bring the database disks online
Bring the database volumes back online either using Disk management or PowerShell commands.
Set-Disk -Number 1 -isOffline $False
Recovery step 5: Bring the database online
Bring the database tpcc back online by using following command:
alter database tpcc set online;
Recovery step 6: Restore the snapshot backup metadata
Use the metadata file captured during the snapshot backup to make the SQL Server aware of the restored snapshot.
Note: Before this can be done, SQL Server requires to perform a backup of active transaction log content. Do this first, followed by the database restore command.
Take a T-SQL backup of the active transaction log by running the following command:
BACKUP LOG tpcc TO DISK = 'C:\mssql_tail_log_backup\tpcc_tail_log_after_disaster.bkm' WITH NORECOVERY;
Restore the snapshot backup metadata by running the following command:
RESTORE DATABASE tpcc FROM DISK = 'C:\mssql_metadata_backup\tpcc_metadata.bkm' WITH METADATA_ONLY, NORECOVERY;
Note: Since the command specifies METADATA_ONLY, SQL Server knows that the database data was restored from a storage snapshot. If NORECOVERY is used, the database goes to a restoring state, as it is waiting to apply transaction log backups to make it consistent.
Recovery step 7: Apply transaction log backups
Restore the appropriate transaction log backup or backups. In the following example, we restore the log backup taken after the returns table was created, and before the customer table is dropped.
RESTORE LOG tpcc FROM DISK = C:\mssql_tail_log_backup\tpcc_tail_log_before_disaster.bkm' WITH RECOVERY;
Note: If there are multiple transaction logs to restore, use the WITH NORECOVERY option with all but the last one. The last RESTORE LOG command uses WITH RECOVERY, signifying that no more recovery is needed.
When this operation is complete, the database is operational and contains all the restored transactions (including the newly created returns table).
Conclusion
With the new SQL Server 2022 T-SQL Snapshot backup feature, it is possible to perform database backups based on the PowerFlex storage snapshots, without relying on additional backup tools. This process can be automated to achieve faster and reliable backup solutions for mission-critical SQL Server databases, for both Windows and Linux operating systems.
Also, for related information about Dell PowerStore see the blog post: SQL Server 2022 – Time to Rethink your Backup and Recovery Strategy.