




Running Meta Llama 3 Models on Dell PowerEdge XE9680


Introduction
Recently, Meta has open-sourced its Meta Llama 3 text-to-text models with 8B and 70B sizes, which are the highest scoring LLMs that have been open-sourced so far in their size ranges, in terms of quality of responses[1]. In this blog, we will run those models on the Dell PowerEdge XE9680 server to show their performance and improvement by comparing them to the Llama 2 models.
Open-sourcing the Large Language Models (LLMs) enables easy access to this state-of-the-art technology and has accelerated innovations in the field and adoption for different applications. As shown in Table 1, this round of Llama 3 release includes the following five models in total, including two pre-trained models with sizes of 8B and 70B and their instruction-tuned versions, plus a safeguard version for the 8B model[2].
Table 1: Released Llama 3 Models
Model size (Parameters) | Model names | Context | Training tokens | Vocabulary length |
8B |
| 8K |
15T |
128K |
70B |
|
Llama 3 is trained on 15T tokens which is 7.5X the number of tokens on which Llama 2 was trained. Training with large, high-quality datasets and refined post-training processes improved Llama 3 model’s capabilities, such as reasoning, code generation, and instruction following. Evaluated across main accuracy benchmarks, the Llama 3 model not only exceeds its precedent, but also leads over other main open-source models by significant margins. The Llama 3 70B instruct model shows close or even better results compared to the commercial closed-source models such as Gemini Pro[1].
The model architecture of Llama 3 8B is similar to that of Llama 2 7B with one significant difference. Besides a larger parameter size, the Llama 3 8B model uses the group query attention (GQA) mechanism instead of the multi-head attention (MHA) mechanism used in the Llama 2 7B model. Unlike MHA which has the same number of Q (query), K (key), and V (value) matrixes, GQA reduces the number of K and V matrixes required by sharing the same KV matrixes across grouped Q matrixes. This reduces the memory required and improves computing efficiency during the inferencing process[3]. In addition, the Llama 3 models improved the max context window length to 8192 compared to 4096 for the Llama 2 models. Llama 3 uses a new tokenizer called tik token that expands the vocabulary size to 128K when compared to 32K used in Llama 2. The new tokenization scheme offers improved token efficiency, yielding up to 15% fewer tokens compared to Llama 2 based on Meta’s benchmark[1].
This blog focuses on the inference performance tests of the Llama 3 models running on the Dell PowerEdge XE9680 server, especially, the comparison with Llama 2 models, to show the improvements in the new generation of models.
Test setup
The server we used to benchmark the performance is the PowerEdge XE9680 with 8x H100 GPUs[4]. The detailed server configurations are shown in Table 2.
Table 2: XE9680 server configuration
System Name | PowerEdge XE9680 |
Status | Available |
System Type | Data Center |
Number of Nodes | 1 |
Host Processor Model | 4th Generation Intel® Xeon® Scalable Processors |
Host Process Name | Intel® Xeon® Platinum 8470 |
Host Processors per Node | 2 |
Host Processor Core Count | 52 |
Host Processor Frequency | 2.0 GHz, 3.8 GHz Turbo Boost |
Host Memory Capacity and Type | 2TB, 32x 64 GB DIMM, 4800 MT/s DDR5 |
Host Storage Capacity | 1.8 TB, NVME |
GPU Number and Name | 8x H100 |
GPU Memory Capacity and Type | 80GB, HBM3 |
GPU High-speed Interface | PCIe Gen5 / NVLink Gen4 |
The XE9680 is the ideal server, optimized for AI workloads with its 8x NVSwitch interconnected H100 GPUs. The high-speed NVLink interconnect allows deployment of large models like Llama 3 70B that need to span multiple GPUs for best performance and memory capacity requirements. With its 10 PCIe slots, the XE9680 also provides a flexible PCIe architecture that enables a variety of AI fabric options.
For these tests, we deployed the Llama 3 models Meta-Llama-3-8B and Meta-Llama-3-70B, and the Llama 2 models Llama-2-7b-hf and Llama-2-70b-hf. These models are available for download from Hugging Face after permission approved by Meta. For a fair comparison between Llama 2 and Llama 3 models, we ran the models with native precision (float16 for Llama 2 models and bfloat16 for Llama 3 models) instead of any quantized precision.
Given that it has the same basic model architecture as Llama 2, Llama 3 can easily be integrated into any available software eco-system that currently supports the Llama 2 model. For the experiments in this blog, we chose NVIDIA TensorRT-LLM latest release (version 0.9.0) as the inference framework. NVIDIA CUDA version was 12.4; the driver version was 550.54.15. The operating system for the experiments was Rocky Linux 9.1.
Knowing that the Llama 3 improved accuracy significantly, we first concentrated on the inferencing speed tests. More specifically, we tested the Time-to-First-Token (TTFT) and throughput over different batch sizes for both Llama 2 and Llama 3 models, as shown in the Results section. To make the comparison between two generations of models easy, and to mimic a summarization task, we kept the input token length and output token length at 2048 and 128 respectively for most of the experiments. We also measured throughput of the Llama 3 with the long input token length (8192), as one of the most significant improvements. Because H100 GPUs support the fp8 data format for the models with negligible accuracy loss, we measured the throughput under long input token length for the Llama 3 model at fp8 precision.
Results
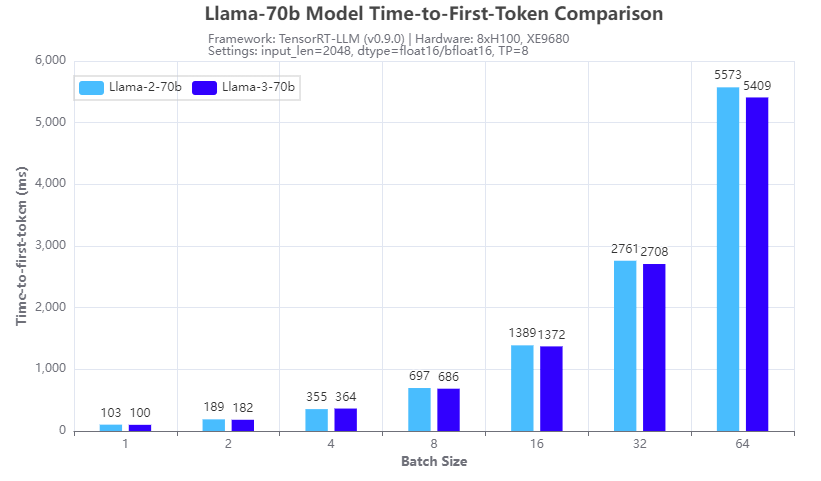
Figure 1. Inference speed comparison: Llama-3-70b vs Llama-2-70b: Time-to-First-Token
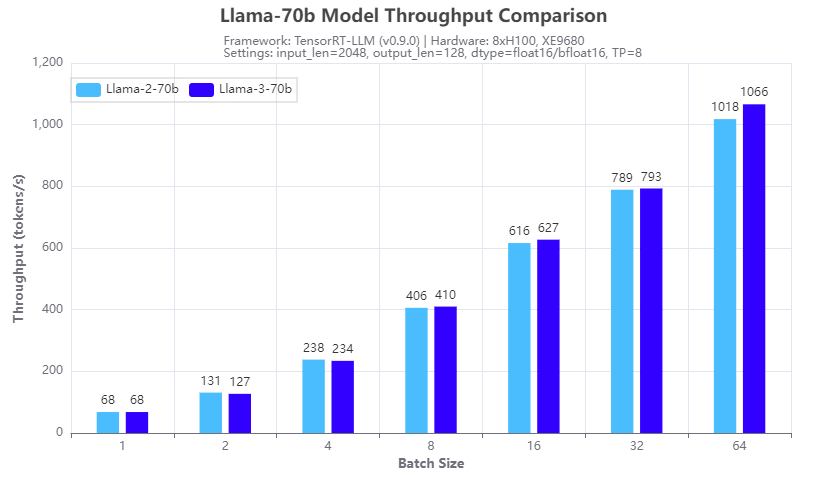
Figure 2: Inference speed comparison: Llama-3-70b vs Llama-2-70b: Throughput
Figures 1 and 2 show the inference speed comparison with the 70b Llama 2 (Llama-2-70b) and Llama 3 (Llama-3-70b) models running across eight H100 GPUs in a tensor parallel (TP=8) fashion on an XE9680 server. From the test results, we can see that for both TTFT (Figure 1) and throughput (Figure 2), the Llama 3 70B model has a similar inference speed to the Llama 2 70b model. This is expected given the same size and architecture of the two models. So, by deploying Llama 3 instead of Llama 2 on an XE9680, organizations can immediately see a big boost in accuracy and quality of responses, using the same software infrastructure, without any impact to latency or throughput of the responses.
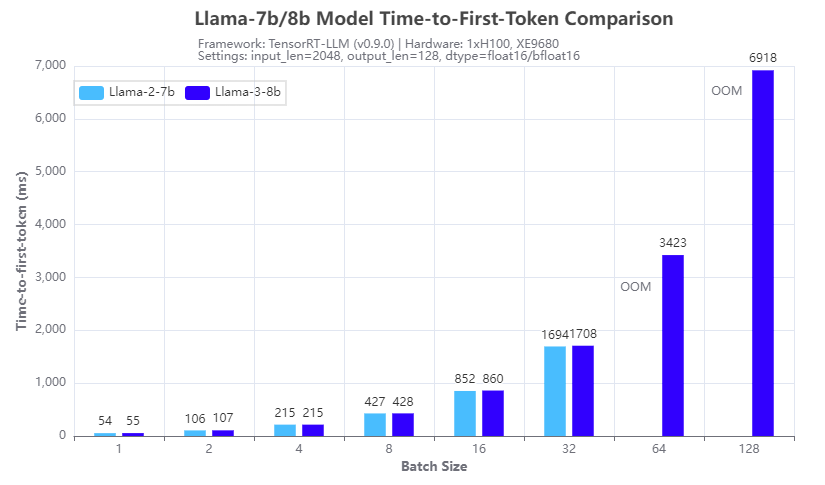
Figure 3. Inference speed comparison: Llama-3-8b vs Llama-2-7b: Time-to-First-Token
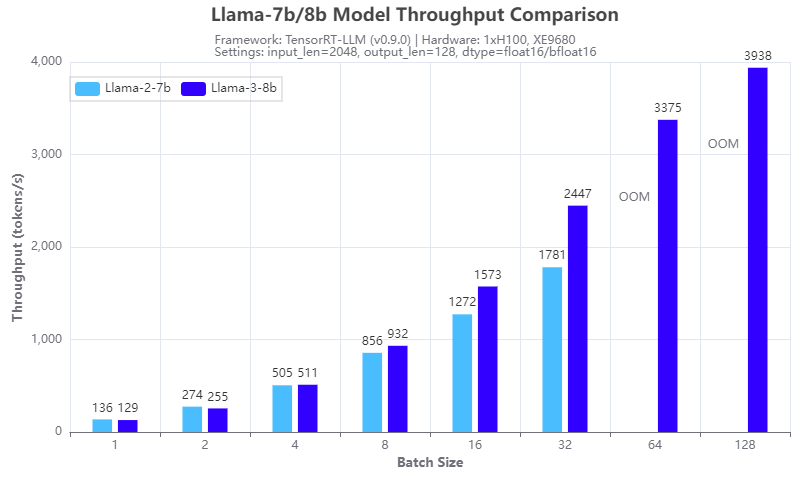
Figure 4: Inference speed comparison: Llama-3-8b vs Llama-2-7b: Throughput
Figures 3 and 4 show the inference speed comparison with the 7b Llama 2 (Llama-2-7b) and 8b Llama 3 (Llama-3-8b) models running on a single H100 GPU on an XE9680 server. From the results, we can see the benefits of using the group query attention (GQA) in the Llama 3 8B architecture, in terms of reducing the GPU memory footprint in the prefill stage and speeding up the calculation in the decoding stage of the LLM inferencing. Figure 3 shows that Llama 3 8B has a similar response time in generating the first token even though it is a 15% larger model compared to Llama-2-7b. Figure 4 shows that Llama-3-8b has higher throughput than Llama-2-7b when the batch size is 4 or larger. The benefits of GQA grow as the batch size increases. We can see from the experiments that:
- the Llama-2-7b cannot run at a batch size of 64 or larger with the 16-bit precision and given input/output token length, because of the OOM (out of memory) error
- the Llama-3-8b can run at a batch size of 128, which gives more than 2x throughput with the same hardware configuration
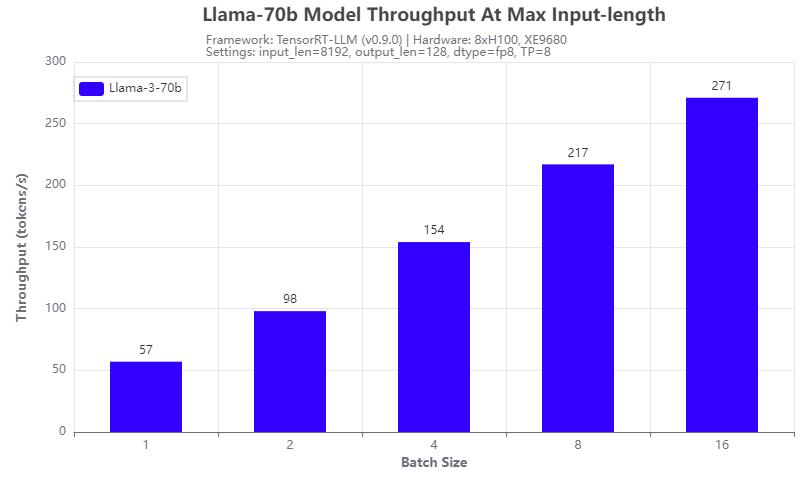
Figure 5: Llama-3-70b throughput under 8192 input token length
Another improvement of the Llama 3 model: it supports a max input token length of 8192, which is 2x of that of a Llama 2 model. We tested it with the Llama-3-70b model running on 8 H100 GPUs of the XE9680 server. The results are shown in Figure 5. The throughput increases with the batch size tested and can achieve 271 tokens/s at a batch size of 16, indicating that more aggressive quantization techniques can further improve the throughput.
Conclusion
In this blog, we investigated the Llama 3 models that were released recently, by comparing their inferencing speed with that of the Llama 2 models by running on a Dell PowerEdge XE9680 server. With the numbers collected through experiments, we showed that not only is the Llama 3 model series a big leap in terms of the quality of responses, it also has great inferencing advantages in terms of high throughput with a large achievable batch size, and long input token length. This makes Llama 3 models great candidates for those long context and offline processing applications.
Authors: Tao Zhang, Khushboo Rathi, and Onur Celebioglu
[1] Meta AI, “Introducing Meta Llama 3: The most capable openly available LLM to date”, https://ai.meta.com/blog/meta-llama-3/.
[3] J. Ainslie et. al, “GQA: Training Generalized Multi-Query Transformer Models from Multi-Head Checkpoints”, https://arxiv.org/abs/2305.13245