




Next-Generation Dell PowerEdge Servers: Designed with PCIe Gen 5 to Deliver Future-Ready Bandwidth
Download PDFFri, 03 Mar 2023 17:38:40 -0000
|Read Time: 0 minutes
Summary
This Direct from Development tech note describes PCIe Gen 5 for next-generation Dell PowerEdge servers. This document provides a high-level overview of PCIe Gen 5 and information about its performance improvement over Gen 4.
PCIe Gen 4 and Gen 5
PCIe (Peripheral Component Interconnect Express) is a high-speed bus standard interface for connecting various peripherals to the CPU. This standard is maintained and developed by the PCI Special Interest Group (PCI-SIG), a group of more than 900 companies. In today’s world of servers, PCIe is the primary interface for connecting peripherals. It has numerous advantages over the earlier standards, being faster, more robust, and very flexible. These advantages have cemented the importance of PCIe.
PCIe Gen 4, which was the fourth major iteration of this standard, can carry data at the speed of 16 gigatransfers per second (GT/s). GT/s is the rate of bits (0’s and 1’s) transferred per second from the host to the end device or endpoint. After considering the overhead of the encoding scheme, Gen 4’s 16 GT/s works out to an effective delivery of 2 GB/s per lane in each direction. A PCIe Gen 4 slot with x16 lanes can have a total bandwidth of 64 GB/s.
The fifth major iteration of the PCIe standard, PCIe Gen 5, doubles the data transfer rate to 32 GT/s. This works out to an effective throughput of 4 GB/s per lane in each direction and 128 GB/s for an x16 PCIe Gen5 slot.
PCIe generations feature forward and backward compatibility. That means that you can connect a PCIe 4.0 SSD or a PCIe 5.0 SSD to a PCIe 5.0 slot, although speed is limited to the lowest generation. There are no pinout changes to from PCIe 4.0 for x16, x8, x4 packages.
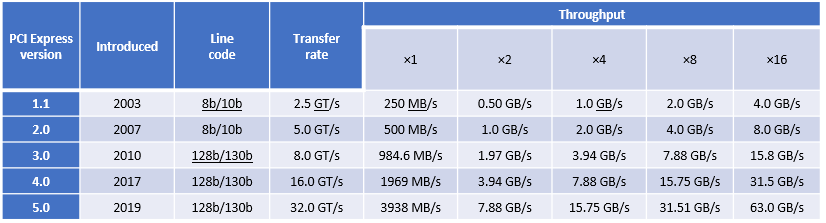
Figure 1. PCIe bandwidth over time
Advantages of increased bandwidth
With the increased bandwidth of PCIe 5.0, devices might be able to achieve the same throughput while using fewer lanes, which means freeing up more lanes. For example, a graphics card that requires x16 bandwidth to run at full speed might now run at the same speed with x8, making an additional eight lanes available. Using fewer lanes is important because CPUs only provide a limited number of lanes, which need to be distributed among devices.
PCIe bandwidth improvements bring opportunities for high-bandwidth accelerators (FPGA, for example). The number of storage-attached and server-attached SSDs using PCIe continues to grow. PCIe 5.0 provides foundational bandwidth, electricals, and CEM slots for Compute Express Link (CXL) devices such as SmartNICs and accelerators. The new standard will be much more useful for machine learning and artificial intelligence, data centers, and other high performance computing environments, thanks to the increase in speeds and bandwidth. In addition, a single 200 Gb network is expected to saturate a PCIe 4.0 link in certain conditions, creating opportunities for PCIe 5.0 connectivity adapters. This unlocks opportunities for 400 Gb networking. The Intel PCIe 5.0 test chip is heavily utilized for interoperability testing.
Next-generation PowerEdge servers and PCIe Gen 5
Next-generation Dell PowerEdge servers with 4th Gen Intel® Scalable processors are designed for PCIe Gen 5. The 4th Gen Intel® Xeon® series processors support the PCIe Gen 5 standard, allowing for the maximum utilization of this available bandwidth with the resulting advantages.
Single-socket 4th Gen Intel® Scalable processors have 80 PCIe Gen 5 lanes available for use, which allows for great flexibility in design. Eighty lanes also give plenty of bandwidth for many peripherals to take advantage of the high-core-count CPUs.
Conclusion
PowerEdge servers continue to deliver the latest technology. Support for PCIe Gen 5 provides increased bandwidth and improvements to make new applications possible.