




Investigating the Memory Access Bottlenecks of Running LLMs


Introduction
Memory access and computing are the two main functions in any computer system. In past decades, the computing capability of a processor has greatly benefited from Moore’s Law which brings smaller and faster transistors into the silicon die almost every year. On the other hand, system memory is regressing. The trend of shrinking fabrication technology for a system is making memory access much slower. This imbalance causes the computer system performance to be bottle-necked by the memory access; this is referred to as the “memory wall” issue. The issue gets worse for large language model (LLM) applications, because they require more memory and computing. Therefore, more memory access is required to be able to execute those larger models.
In this blog, we will investigate the impacts of memory access bottlenecks to the LLM inference results. For the experiments, we chose the Llama2 chat models running on a Dell PowerEdge HS5610 server with the 4th Generation Intel® Xeon® Scalable Processors. For quantitative analysis, we will be using the Intel profile tool – Intel® VTune™ Profiler to capture the memory access information while running the workload. After identifying the location of the memory access bottlenecks, we propose the possible techniques and configurations to mitigate the issues in the conclusion session.
Background
The Natural Language Processing (NLP) has greatly benefited from the transformer architecture since it was introduced in 2017 [1]. The trajectory of the NLP models has been moved to transformer-based architectures given its parallelization and scalability features over the traditional Recurrent Neural Networks (RNN) architectures. Research shows a scaling law of the transformer-based language models, in which the accuracy is strongly related to the model size, dataset size and the amount of compute [2]. This inspired the interest in using Large Language Models (LLMs) for high accuracy and complicated tasks. Figure 1 shows the evolution of the LLMs since the transformer architecture was invented. We can see the parameters of the LLMs have increased dramatically in the last 5 years. This trend is continuing. As shown in the figure, most of the LLMs today come with more than 7 billion parameters. Some models like GPT4 and PaLM2 have trillion-level parameters to support multi-mode features.
Figure 1: LLM evolution
What comes with the large models are the challenges on the hardware systems for training and inferencing those models. On the one hand, the computation required is tremendous as it is proportional to the model size. On the other hand, memory access is expensive. This mainly comes from the off-chip communication and complicated cache architectures required to support the large model parameters and computation.
Test Setup
The hardware platform we used for this study is HS5610 which is the latest 16G cloud-optimized server from Dell product portfolio. Figure 2 gives an overview of HS5610. It has been designed with CSP features that allow the same benefits with full PowerEdge features & management like mainstream Dell servers, as well as open management (OpenBMC), cold aisle service, channel firmware, and services. The server has two sockets with an Intel 4th generation 32-core Intel® Xeon® CPU on each socket. The TDP power for each CPU is 250W. Table 1 and Table 2 show the details of the server configurations and CPU specifications.
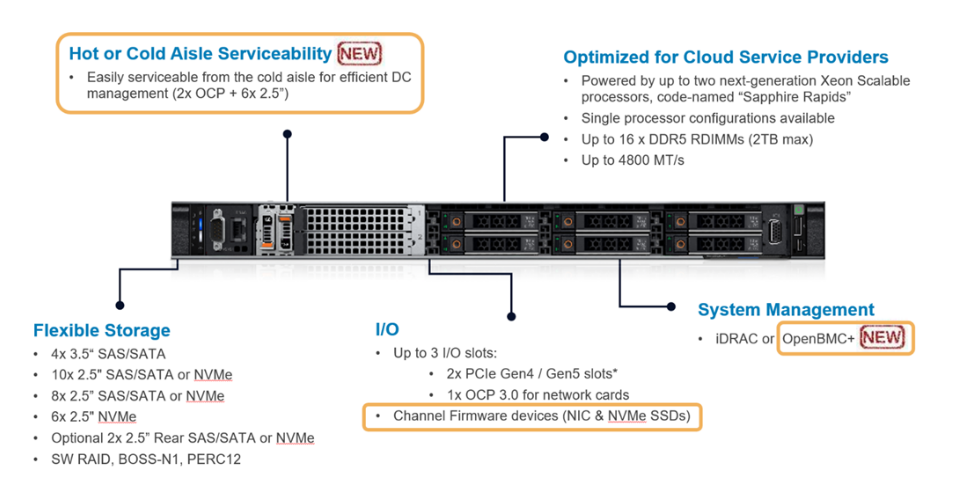
Figure 2: PowerEdge HS5610 [3]
Product Collection | 4th Generation Intel® Xeon® Scalable Processors |
Processor Name | Platinum 8480+ |
Status | Launched |
# of CPU Cores | 32 |
# of Threads | 64 |
Base Frequency | 2.0 GHz |
Max Turbo Speed | 3.8 GHz |
Cache L3 | 64 MB |
Memory Type | DDR5 4800 MT/s |
ECC Memory Supported | Yes |
Table 1: HS5610 Server Configurations
System Name | PowerEdge HS5610 |
Status | Available |
System Type | Data Center |
Number of Nodes | 1 |
Host Processor Model | 4th Generation Intel® Xeon® Scalable Processors |
Host Processors per Node | 2 |
Host Processor Core Count | 32 |
Host Processor Frequency | 2.0 GHz, 3.8 GHz Turbo Boost |
Host Memory Capacity | 1TB, 16 x 64GB DIMM 4800 MHz |
Host Storage Capacity | 4.8 TB, NVME |
Table 2: 4th Generation 32-core Intel® Xeon® Scalable Processor Technical Specifications
Software Stack and System Configuration
The software stack and system configuration used for this submission is summarized in Table 3. Optimizations have been done for the PyTorch framework and Transformers library to unleash the Xeon CPU AI instruction capabilities. Also, a low-level tool - Intel® Neural Compressor has been used for high-accuracy quantization.
OS | CentOS Stream 8 (GNU/Linux x86_64) |
Intel® Optimized Inference SW | OneDNN™ Deep Learning, ONNX, Intel® Extension for PyTorch (IPEX), Intel® Extension for Transformers (ITREX), Intel® Neural Compressor |
ECC memory mode | ON |
Host memory configuration | 1TiB |
Turbo mode | ON |
CPU frequency governor | Performance |
Table 3: Software stack and system configuration
The model under tests is Llama2-chat-hf models with 13 billion parameters (Llama2-13b-chat-hf). The model is based on the pre-trained 13 billion Llama2 model and fine-tuned with human feedback for chatbot applications. The Llama2 model has light (7b), medium (13b) and heavy (70b) size versions.
The profile tool used in the experiments is Intel® VTune™. It is a powerful low-level performance analysis tool for x86 CPUs that supports algorithms, micro-architecture, parallelism, and IO related analysis etc. For the experiments, we use the memory access analysis under micro-architecture category. Note Intel® VTune™ consumes significant hardware resources which impacts the performance results if we run the tool along with the workload. So, we use it as a profile/debug tool to investigate the bottleneck. The performance numbers we demonstrate here are running without Intel® VTune™ on.
The experiments are targeted to cover the following:
- Single-socket performance vs dual-socket performance to demonstrate the NUMA memory access impact.
- Performance under different CPU-core numbers within a single socket to demonstrate the local memory access impact.
- Performance with different quantization to demonstrate the quantization impact.
- Intel® VTune™ memory access results.
Because Intel® VTune™ has minimum capture durations and max capture size requirements, we focus on capturing the results for the medium-size model (Llama2-13b-chat-hf). This prevents short/long inference time therefore avoiding an underload or overload issue. All the experiments are based on the batch size equals to 1. Performance is characterized by latency or throughput. To reduce the measurement errors, the inference is executed 10 times to get the averaged value. A warm-up process by loading the parameter and running a sample test is executed before running the defined inference.
Results
For this section, we showcase the performance results in terms of throughput for single-socket and dual socket scenarios under different quantization types followed by the Intel® VTune™ capturing results.
Single-socket Results Under Different Quantization Types:
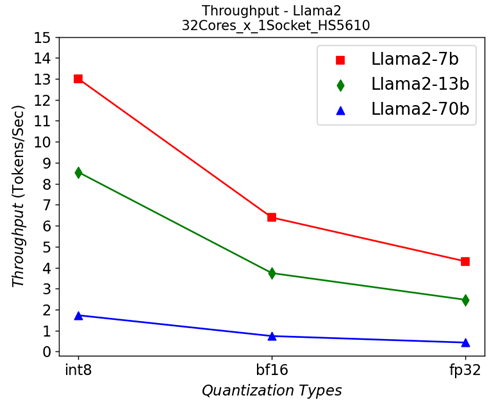
Figure 3: Single-socket throughput in HS5610 server running Llama2 models under different quantization types
Figure 3 shows the throughputs of running different Llama2 chat models with different quantization types on a single socket. The “numactl” command is used to confine the workload within one single 32-core CPU. From the results, we can see that quantization greatly helps to improve the performance across different models.
 |  |
(a) | (b) |
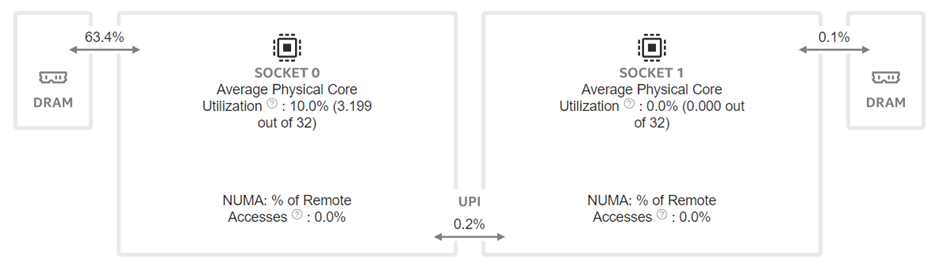
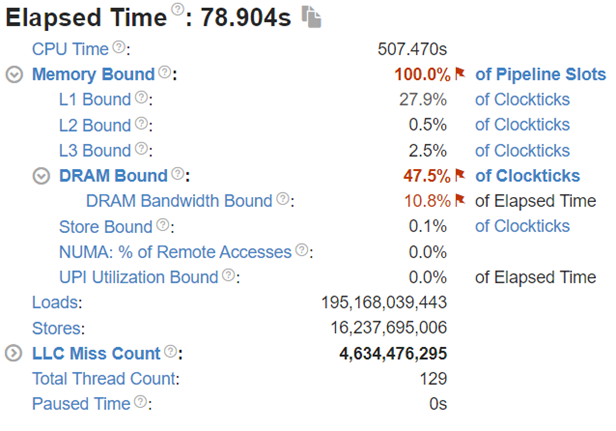
Figure 4:Intel® VTune™ memory analysis results for single-socket fp32 results:
(a). bandwidth and utilization diagram (b). elapsed time analysis
 |  |
(a) | (b) |
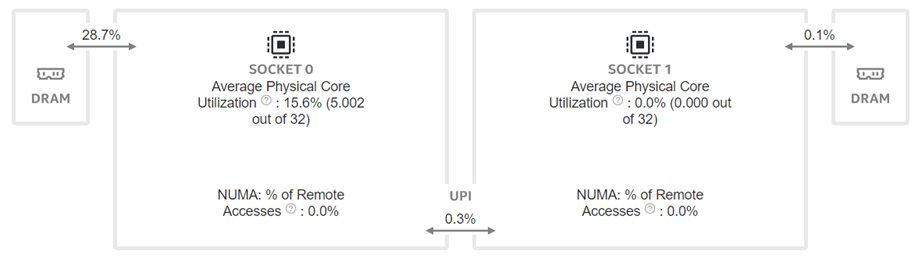
Figure 5: Intel® VTune™ memory analysis results for single-socket bf16 results:
(a). bandwidth and utilization diagram (b). elapsed time analysis
To better understand what would happen at the lower level, we will take the Llama2 13 billion model as an example. We will use Intel® VTune™ to capture the bandwidth and utilization diagram and the elapsed time analysis for the fp32 data type (shown in Figure 4) and use bf16 data type (shown in Figure 5). We can see that by reducing the representing bits, the bandwidth required for the CPU and DRAM communication is reduced. In this scenario, the DRAM utilization drops from 63.4% for fp32 (shown in Figure 4 (a)) to 28.7% (shown in Figure 4 (b)). The also indicates that the weight data can arrive quicker to the CPU chip. Now we can benefit from the quicker memory communication. The CPU utilization also increases from 10% for fp32 (shown in Figure 4 (a)) to 15.6% for bf16 (shown in Figure 4 (b)). Both faster memory access and better CPU utilization translate to better performance with a more than 50% (from 2.47 tokens/s for fp32 to 3.74 tokens/s) throughput boost as shown in Figure 3. Diving deeper with the elapsed time analysis shown in Figure 4 (b), and Figure 5 (b), L1 cache is one of the performance bottleneck locations on the chip. Quantization reduces the possibility that the task gets stalled.
Dual-socket Results Under Different Quantization Types:
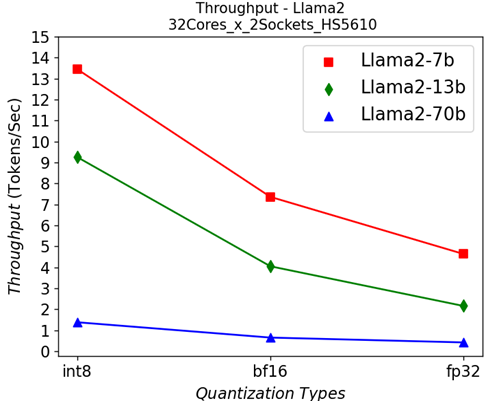
Figure 6: Dual-socket throughput in HS5610 server running Llama2 models under different quantization types
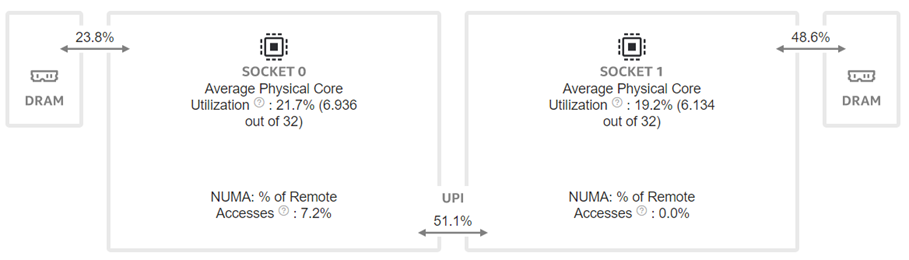 | 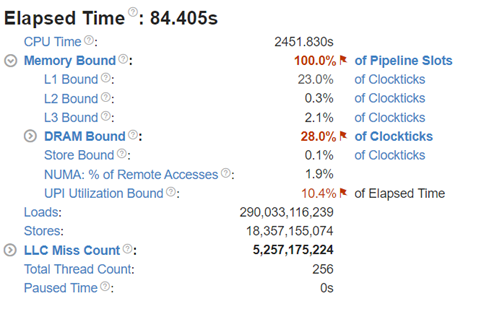 |
(a) | (b) |
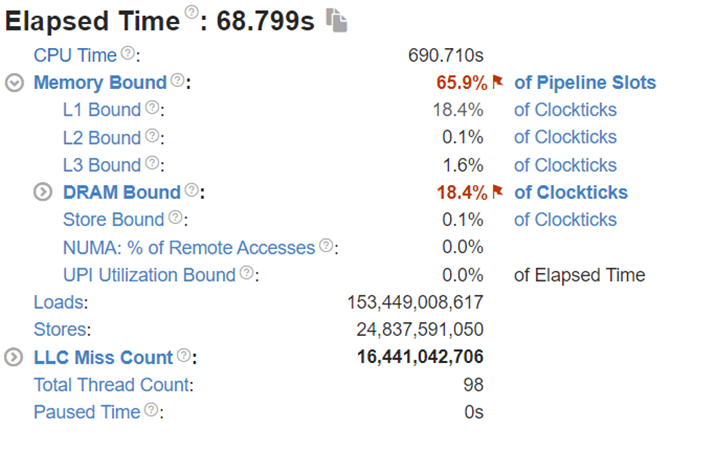
Figure 7: Intel® VTune™ memory analysis results for dual-socket fp32 results:
(a). bandwidth and utilization diagram (b). elapsed time analysis
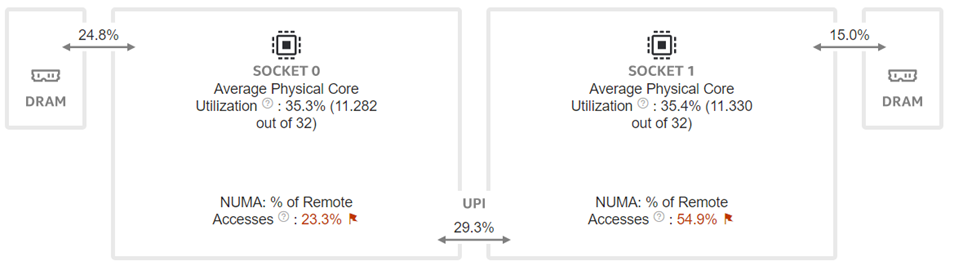 | 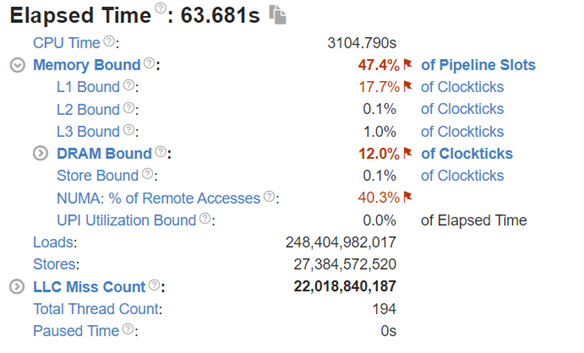 |
(a) | (b) |
Figure 8: Intel® VTune™ memory analysis results for dual-socket bf16 results:
(a). bandwidth and utilization diagram (b). elapsed time analysis
Now moving to the dual-socket scenarios shown in Figure 6-8, we have similar observations regarding the impacts of the quantization: Quantization increases CPU utilization and reduces the L1 cache bottleneck, therefore boosting the throughputs across different Llama2 models.
Comparing the performance between the single-socket (shown in Figure 3) and dual-socket (shown in Figure 6) scenarios indicates negligible performance improvement. As seen in Figure 7 and 8, even though we get better CPU utilizations, the communication between two sockets (the UPI or the NUMA memory access), becomes the main bottleneck that offsets the benefits of having more computing cores.
Conclusion
Based on the experiment results for different Llama2 models under various configurations, we have the conclusions as the following:
- Quantization improves the performance across the models with different weights by reducing the L1 cache bottleneck and increasing the CPU utilization. It also indicates that we can optimize the TCO by reducing the memory requirements (in terms of the capacity and speed) if we were able to quantize the model properly.
- Crossing-socket communication from either UPI or NUMA memory access is a significant bottleneck that may affect performance. Optimizations include the reducing of the inter-socket communication. For example better partitioning of the model is critical. Alternatively, this also indicates that executing one workload on a single dedicated CPU with enough cores is desirable for cost and performance considerations.
References
[1]. A. Vaswani et. al, “Attention Is All You Need”, https://arxiv.org/abs/1706.03762
[2]. J. Kaplan et. al, “Scaling Laws for Neural Language Models”, https://arxiv.org/abs/2001.08361
[3]. https://www.dell.com/en-us/shop/ipovw/poweredge-hs5610