




In a data-driven world, innovation changes are forcing a new paradigm
Wed, 19 Aug 2020 22:15:07 -0000
|Read Time: 0 minutes
For the last two decades, I’ve enjoyed working at Dell Technologies focusing on customer big-picture ideas. Not just focusing on hardware changes, but on a holistic solution including hardware, software, and services that achieves a business objective by addressing customer goals, problems, and needs. I’ve also partnered with my clients on their transformation journey. The concepts of digital transformation and IT transformation have been universal themes and turning these ideas into realities is where the rubber meets the road.
Now as I engage with customers and partners about Microsoft solutions, an incremental awareness of the idea of “data”, and how data is accessed and leveraged, has become evident. A foundational shift around data has occurred.
We are now living in a new era of data management, but many of us were not aware this change was developing. This has crept up on us without the fanfare you might see from a new technology launch. When you take a step back and look at these shifts in their entirety you see these changes aren’t just isolated updates, but instead are amplifying their benefits within each other. This is a fundamental transformation in the industry, similar to when virtualization was first adopted 15 years ago.
For many, this change started to become apparent with the end of support for SQL Server 2008 earlier this year (along with support for all previous versions of the product). This deadline, coupled with the large install base that still exists on this platform, is helping the conversation along but it’s not just a replace the old with the new in a point-by-point swap out. The doors opened in this new era force a completely different view and approach. We no longer need to have a SQL, Oracle, SAP, or Hadoop conversation – instead it becomes a holistic “data” point of view.
In our hybrid/multi-cloud world, there is not just one answer for managing data. Regardless of the type of data or where it resides, all the diverse data languages and methods of control, the word “data” can encompass a great deal.
Emerging technologies including IoT, 5G, AI and ML are generating greater amounts and varied types of data. How we access that data and derive insight from it becomes critical, but we have been limited by people, processes, and technology.
People have become stuck in the rut of, “I want it to be this way because it has always been this way.” Therefore, replacing dated/expired architectures becomes a swap out story verses a re-examine story and new efficiencies are completely missed. Processes within the organization become rigid with that same mindset and, dare I say politics, where access to that data becomes path- limited. Technology is influenced by both people and process as “the old way is good enough, right?”
The value/importance of “data” really points back to the insight that you drive from it. Having a bunch of ones and zeros on a hard drive is nice but what you derive from that data is critically important. The conversations I have with customers are not so much, “Where is my data and how is it stored?” The conversation is more commonly, “I have a need to get business analytics from my proprietary data so I can impact my customers in a way I never did before.”
To put my Stephen Covey hat on, we are in a paradigm change. What is occurring is incredibly impactful for how customers should view and treat data. There are three key areas that we will examine with the new paradigm today and we’ll start with data gravity.
Data Gravity
 Data gravity is the idea that data has weight. Wherever data is created, it tends to remain. Data stores are getting so big that moving data around is becoming expensive, time constrained, and database performance impacting. This in turn, results in silos of data by location and type. Versioning and lack of upgrade/migration/consolidation of databases also perpetuates these silo challenges.
Data gravity is the idea that data has weight. Wherever data is created, it tends to remain. Data stores are getting so big that moving data around is becoming expensive, time constrained, and database performance impacting. This in turn, results in silos of data by location and type. Versioning and lack of upgrade/migration/consolidation of databases also perpetuates these silo challenges.
As with physical gravity, we understand that data’s mass encourages applications and analytics to orbit that data store where it resides. Then, application dependency upon the data’s language version cements the silo requirement even further. We have witnessed the proliferation of intelligent core and edge devices, as well as bringing applications to that place where the data resides – at the customer location.
Silos of data based on language, version, and location can’t be readily accessed from a common interface. If I am a SQL user, how do I get that Oracle data I need? I cannot just pull all my data together into a huge common dataset – it’s just too big. We see these silos in almost every customer environment.
Data Virtualization
This is where data virtualization comes into the story. Please note this is not a virtual machine (a common confusion on the naming). Think instead of this being data democratization: the ability to allow all the people access to all the data – within reason, of course. Data virtualization allows you to access the data where the data is stored without a massive ETL event. You can see and control the data regardless of language, version, or location. The data remains where it is, but you have real-time source access to this data. You can access data from remote or diverse sources and perform actions on that data from one common point of view.
Data virtualization allows access into the silos that, in the past, have been very rigid, blocking the ability to effectively use that data. From a non-SQL Server point of view, having unstructured data or structured data in a different format (like Oracle), required you to hire a specialized person with a specific skill set to access that data. With data virtualization, that is no longer a barrier as these silo walls are reduced. Data virtualization becomes data democratization, meaning that all people (with appropriate permissions) can access and do things with that data.
From a Microsoft point of view, that technology came into reality with Polybase. Polybase with SQL Server allows access with T-SQL, the most commonly used database language. I started using this resource with the Analytics Platform System (APS) many years ago. After Microsoft placed this tool into SQL Server in 2016 and updated its functionality tremendously in SQL Server 2019, we now can ingest Hadoop, Oracle, and use orchestrators like Spark, to access all these disparate data sources. To visualize this, think of Polybase with SQL Server 2019 as a wrapper around these diverse silos of data. You now can access all these disparate data sources within one common interface: T-SQL using Polybase.
Holistic Solution
The final tenet of this fundamental change is the advent of containerization. This enablement technology allows abstraction beyond virtualization and runs just about anywhere. Data becomes nimble and you can move it where needed.
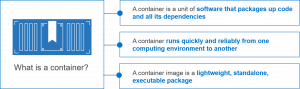
It’s amazing how pervasive containers have become. It’s no longer a science experiment, but is quickly becoming the new normal. In the past, many customers had a forklift perception that when a new technology comes into play, it requires a lift and replace. I’ve heard, “What I am doing today is no longer good, so I have to replace it with whatever your new product is, and it will be painful.”
I’ve been using the phrase that containerization enables “all the things”. Containerization has been adopted by so many architectures that it’s easier to talk about where you can’t do it verses where you can. Traditional SAN, converged, hyperconverged, hybrid cloud — you can place this just about anywhere. There is not just one right path here — do what makes sense for you. It becomes a holistic solution.
There are multiple ways to address the business need that customers have even if it’s leveraging existing designs that they’ve been using for years. Dell Technologies has published details of several architectures supporting SQL Server and has just recently published the first of many papers on SQL Server in containers.
The answer is, you can do all these things with all these architectures. By the way, this isn’t specific to Microsoft and SQL Server. We see similar architectures being created in other databases and technology formats.
These three tenets are each self-supporting to the new paradigm. Data gravity is supported by data virtualization and containerization. Data virtualization allows silos when needed (gravity) and is enabled by containerization. Containerization gives access to silos (wrapper) and is the mechanism to activate data virtualization.
From a Dell Technologies point of view, we are aggressively embracing these tenets. Our enablement technologies to support this paradigm are called out in three discrete points – accelerate, protect, and reuse. We will review these points in a separate blog.
There is much more to come as we continue this journey into the new era of data management. Dell Technologies has deeply invested in resources around this topic with several recent publications and reference designs embracing this paradigm change. Our leadership on this topic is the result of our 30+ year relationship with Microsoft and our continuing “better together” story. A detailed white paper that further expands the ideas within this blog is available here.