




Driving Innovation with the Dell Validated Platform for Red Hat OpenShift and IBM Instana
“There is no innovation and creativity without failure. Period.” – Brené Brown
In the Information Technology field today, it seems like it’s impossible to go five minutes without someone using some variation of the word innovate. We are constantly told we need to innovate to stay competitive and remain relevant. I don’t want to spend time arguing the importance of innovation, because if you’re reading this then you probably already understand its importance.
What I do want to focus on is the role that failure plays in innovation. One of the biggest barriers to innovation is the fear of failure. We have all experienced some level of failure in our lives, and the costly mistakes can be particularly memorable. To create a culture that fosters innovation, we need to create an environment that reduces the costs associated with failure – these can be financial costs, time costs, or reputation costs. This is why one of the core tenets of modern application architecture is “fail fast”. Put simply, it means to identify mistakes quickly and adjust. The idea is that a flawed process or assumption will cost more to fix the longer it is present in the system. With traditional waterfall processes, that flaw could be present and undetected for months during the development process, and in some cases, even make it through to production.
While the benefits of fail fast can be easy to see, implementing it can be a bit harder. It involves streamlining not just the development process, but also the build process, the release process, and having proper instrumentation all the way through from dev to production. This last part, instrumentation, is the focus of this article. Instrumentation means monitoring a system to allow the operators to:
- See current state
- Identify application performance
- Detect when something is not operating as expected
While the need for instrumentation has always been present, developers are often faced with difficult timelines and the first feature areas that tend to be cut are testing and instrumentation. This can help in the short term, but it often ends up costing more down the road, both financially and in the end-user experience.
IBM Instana is a tool that provides observability of complete systems, with support for over 250 different technologies. This means that you can deploy Instana into the environment and start seeing valuable information without requiring any code changes. If you are supporting web-based applications, you can also take things further by including basic script references in the code to gain insights from client statistics as well.
Announcing Support for Instana on the Dell Validated Platform for Red Hat OpenShift
Installing IBM Instana into the Dell Validated Platform for Red Hat OpenShift can be done by Operator, Helm Chart, or YAML File.
The simplest way is to use the Operator. This consists of the following steps:
- Create the instana-agent project
- Set the policy permissions for the instana-agent service account
- Install the Operator
- Apply the Operator Configuration using a custom resource YAML file
You can configure IBM Instana to point to IBM’s cloud endpoint. Or for high security environments, you can choose to connect to a private IBM Instana endpoint hosted internally.

Figure 1. Infrastructure view of the OpenShift Cluster
Once configured, the IBM Instana agent starts sending data to the endpoint for analysis. The graphical view in Figure 1 shows the overall health of the Kubernetes cluster, and the node on which each resource is located. The resources in a normal state are gray: any resource requiring attention would appear in a different color.
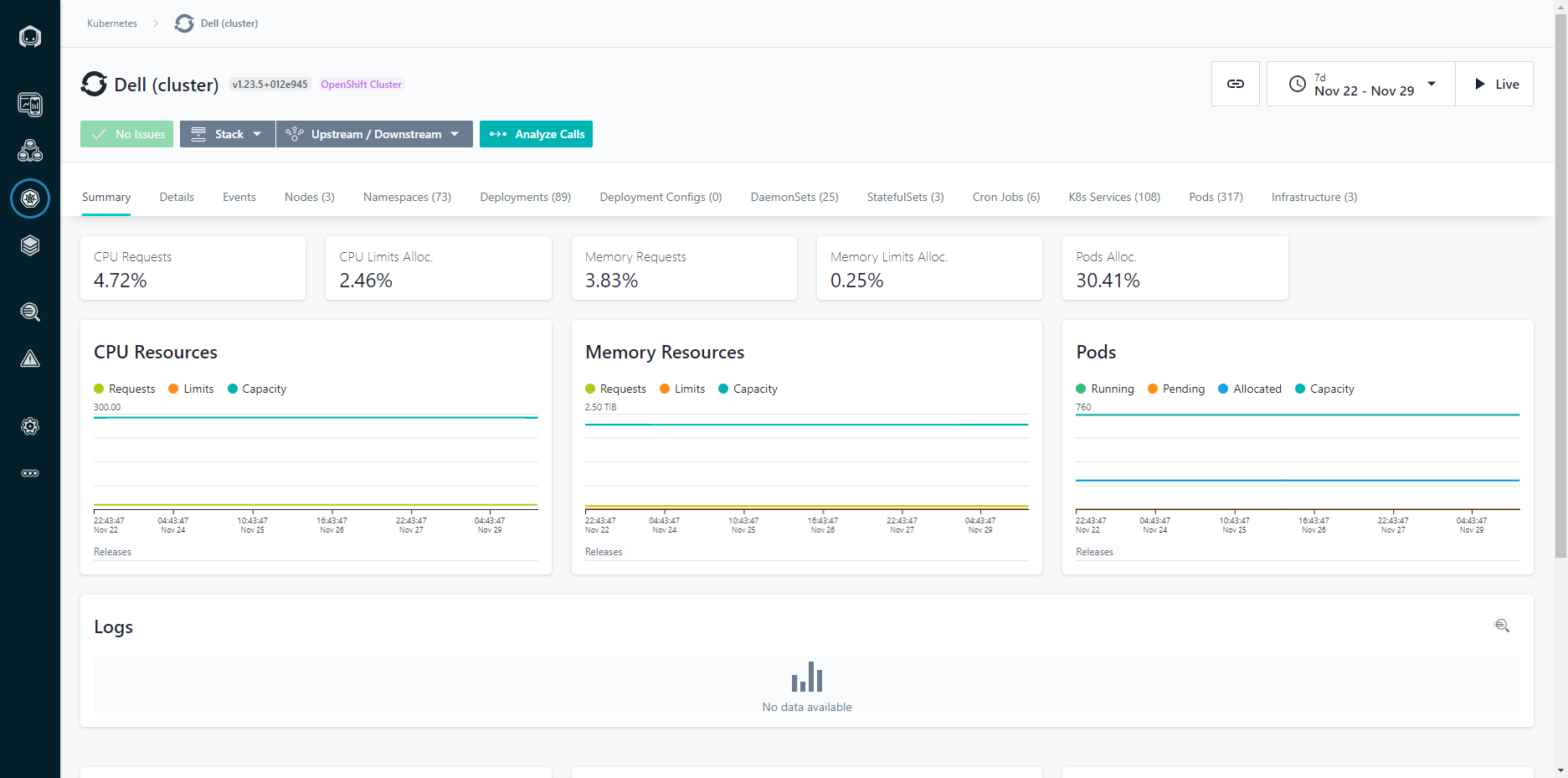
Figure 2: Cluster View
We can also see the metrics across the cluster, including CPU and Memory statistics. The charts are kept in time sync, so if you highlight a given area or narrow the time period, all of the charts remain in the same context. This makes it easy to identify correlations between different metrics and events.
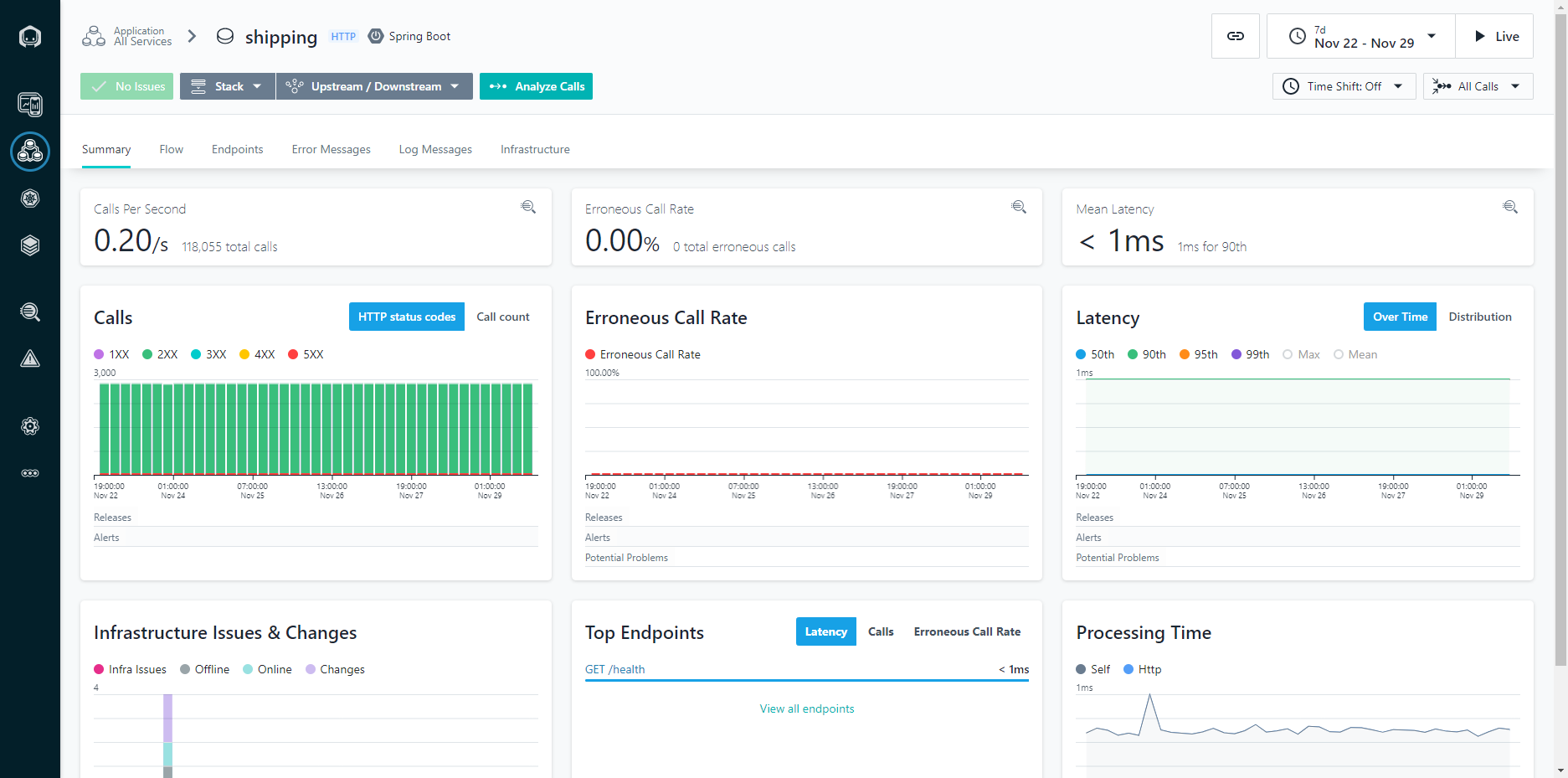
Figure 3: Application Calls View
Looking at the application calls allows you to see how a given application is performing over time. Being able to narrow down to a one second granularity means that you can actually follow individual calls through the system and see things like the parameters passed in the call. This can be incredibly helpful for troubleshooting intermittent application issues.
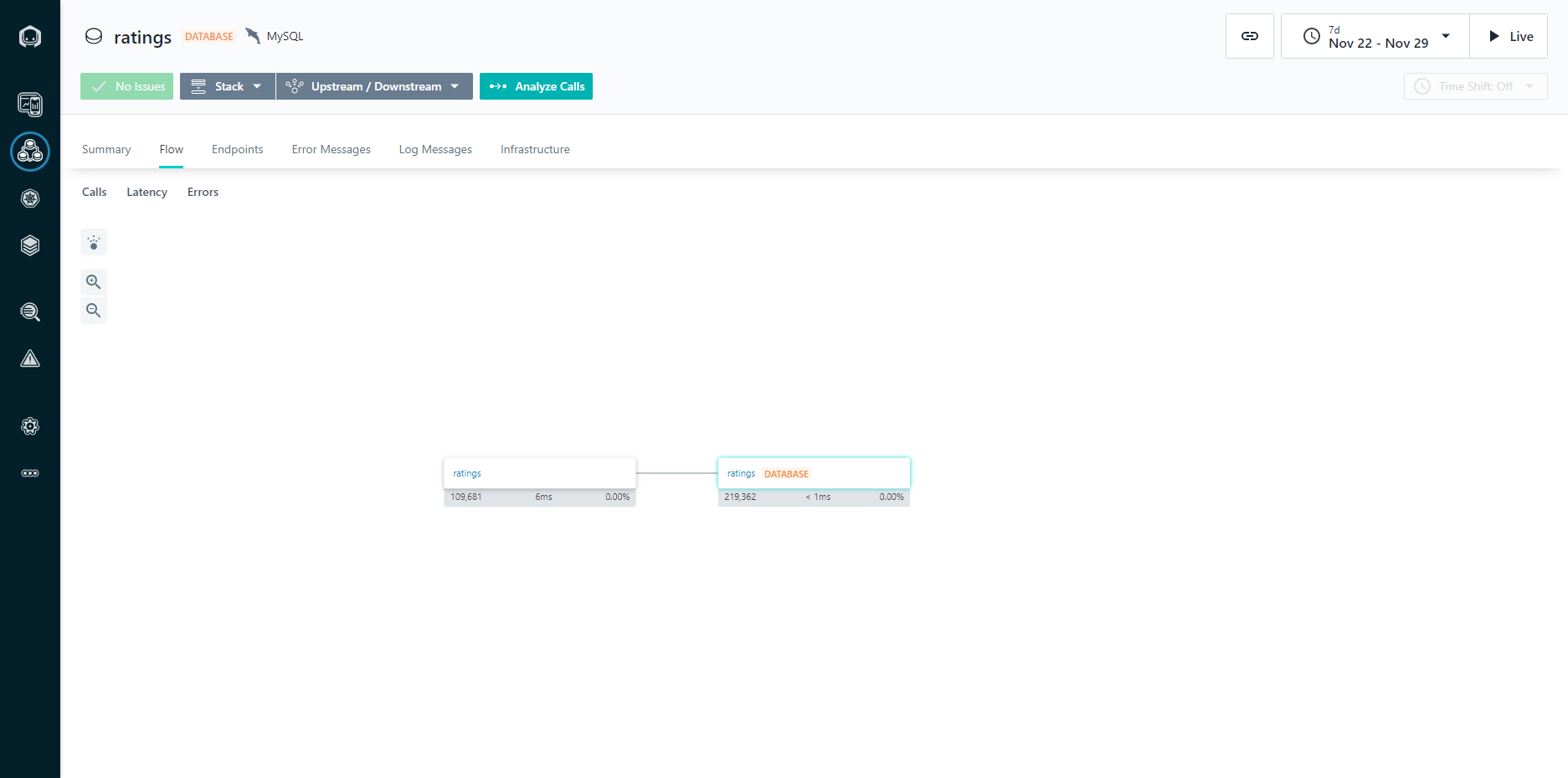
Figure 4: Application Dependencies View
The dependencies view gives you a graphical representation of all the components within a system and how they relate to each other, in a dependency diagram. This is critically important in modern application design because as you implement a larger number of more focused services, often created by different DevOps teams, it can be difficult to keep track of what services are being composed together.
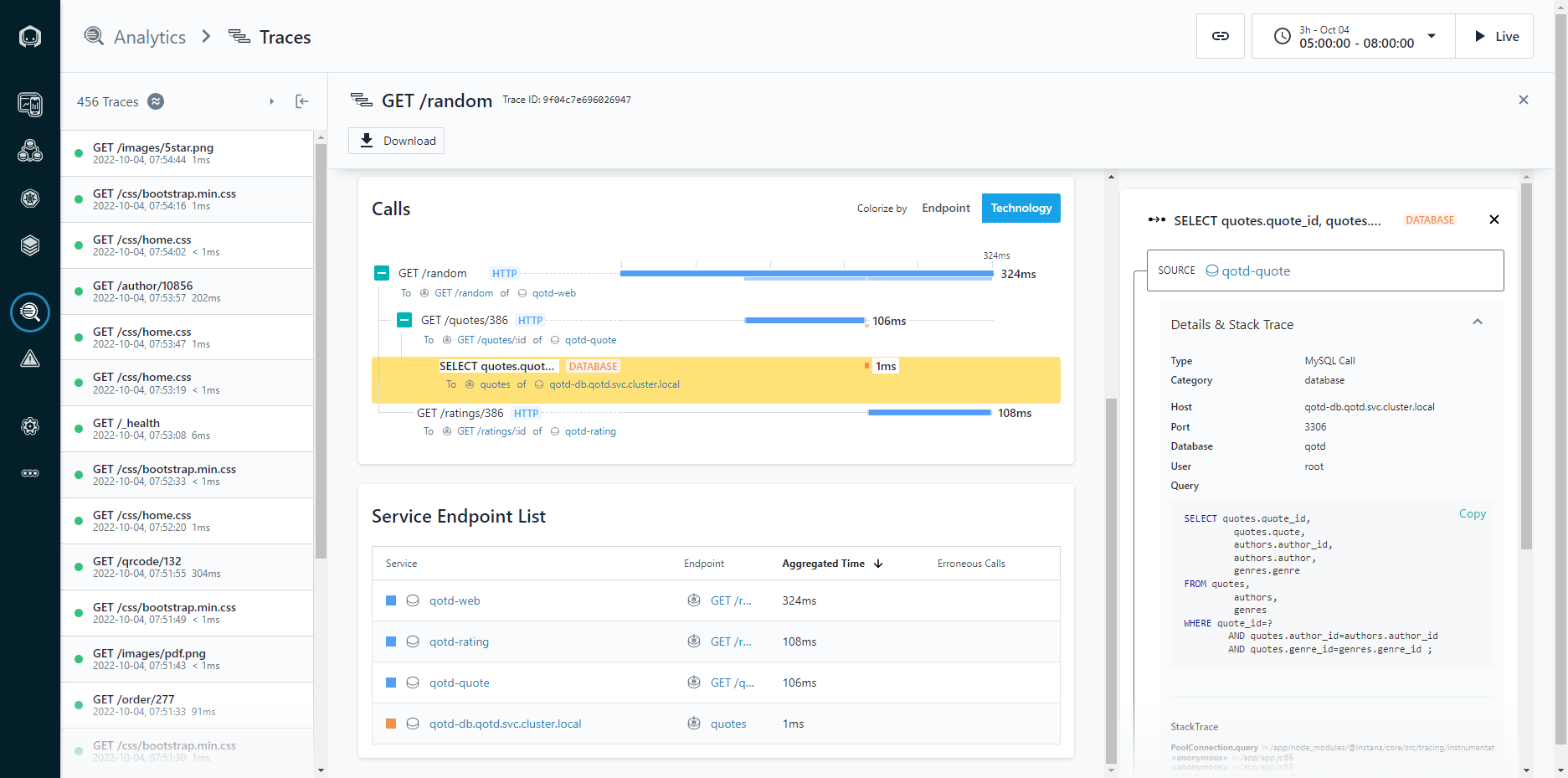
Figure 5: Application Stack Traces
The application stack trace allows you to walk the stack of an application to see what calls were made, and how much time each call took to complete. Knowing that a page load took five seconds can help indicate a problem, but being able to walk the stack and identify that 4.8 seconds was spent running a database query (and exactly what query that was) means that you can spend less time troubleshooting, because you already know exactly what needs to be fixed.
For more information about the Dell Validated Platform for Red Hat OpenShift, see our launch announcement: Accelerate DevOps and Cloud Native Apps with the Dell Validated Platform for Red Hat OpenShift | Dell Technologies Info Hub.
Author: Michael Wells, PowerFlex Engineering Technologist
Twitter: @SqlTechMike
LinkedIn