




Deploying Microsoft SQL Server Big Data Clusters on Kubernetes platform using PowerFlex

Introduction
Microsoft SQL Server 2019 introduced a groundbreaking data platform with SQL Server 2019 Big Data Clusters (BDC). Microsoft SQL Server Big Data Clusters are designed to solve the big data challenge faced by most organizations today. You can use SQL Server BDC to organize and analyze large volumes of data, you can also combine high value relational data with big data. This blog post describes the deployment of SQL Server BDC on a Kubernetes platform using Dell EMC PowerFlex software-defined storage.
PowerFlex
Dell EMC PowerFlex (previously VxFlex OS) is the software foundation of PowerFlex software-defined storage. It is a unified compute storage and networking solution delivering scale-out block storage service that is designed to deliver flexibility, elasticity, and simplicity with predictable high performance and resiliency at scale.
The PowerFlex platform is available in multiple consumption options to help customers meet their project and data center requirements. PowerFlex appliance and PowerFlex rack provide customers comprehensive IT Operations Management (ITOM) and life cycle management (LCM) of the entire infrastructure stack in addition to sophisticated high-performance, scalable, resilient storage services. PowerFlex appliance and PowerFlex rack are the preferred and proactively marketed consumption options. PowerFlex is also available on VxFlex Ready Nodes for those customers who are interested in software-defined compliant hardware without the ITOM and LCM capabilities.
PowerFlex software-define storage with unified compute and networking offers flexibility of deployment architecture to help best meet the specific deployment and architectural requirements. PowerFlex can be deployed in a two-layer for asymmetrical scaling of compute and storage for “right-sizing capacities, single-layer (HCI), or in mixed architecture.
Microsoft SQL Server Big Data Clusters Overview
Microsoft SQL Server Big Data Clusters are designed to address big data challenges in a unique way, BDC solves many traditional challenges through building big-data and data-lake environments. You can query external data sources, store big data in HDFS managed by SQL Server, or query data from multiple external data sources using the cluster.
SQL Server Big Data Clusters is an additional feature of Microsoft SQL Server 2019. You can query external data sources, store big data in HDFS managed by SQL Server, or query data from multiple external data sources using the cluster.
For more information, see the Microsoft page SQL Server Big Data Clusters partners.
You can use SQL Server Big Data Clusters to deploy scalable clusters of SQL Server and Apache SparkTM and Hadoop Distributed File System (HDFS), as containers running on Kubernetes.
For an overview of Microsoft SQL Server 2019 Big Data Clusters, see Microsoft’s Introducing SQL Server Big Data Clusters and on GitHub, see Workshop: SQL Server Big Data Clusters - Architecture.
Deploying Kubernetes Platform on PowerFlex
For this test, PowerFlex 3.6.0 is built in a two-layer configuration with six Compute Only (CO) nodes and eight Storage Only (SO) nodes. We used PowerFlex Manager to automatically provision the PowerFlex cluster with CO nodes on VMware vSphere 7.0 U2, and SO nodes with Red Hat Enterprise Linux 8.2.
The following figure shows the logical architecture of SQL Server BDC on Kubernetes platform with PowerFlex.
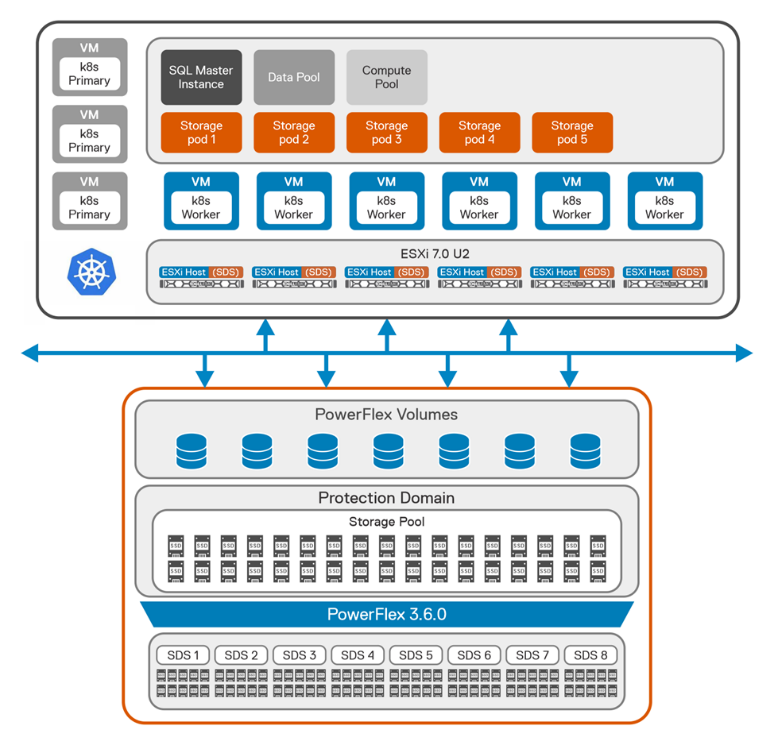
Figure 1: Logical architecture of SQL BDC on PowerFlex
From the storage perspective, we created a single protection domain from eight PowerFlex nodes for SQL BDC. Then we created a single storage pool using all the SSDs installed in each node that is a member of the protection domain.
After we deployed the PowerFlex cluster, we created eleven virtual machines on the six identical CO nodes with Ubuntu 20.04 on them, as shown in the following table.
Table 1: Virtual machines for CO nodes
Item | Node 1 | Node 2 | Node 3 | Node 4 | Node 5 | Node 6 |
Physical node | esxi70-1 | esxi70-2 | esxi70-3 | esxi70-4 | esxi70-5 | esxi70-6 |
H/W spec | 2 x Intel Gold 6242 R, 20 cores | 2 x Intel Gold 6242R, 20 cores | 2 x Intel Gold 6242R, 20 cores | 2 x Intel Gold 6242R, 20 cores | 2 x Intel Gold 6242R, 20 cores | 2 x Intel Gold 6242R, 20 cores |
Virtual machines | k8w1 | lb01 | lb02 | k8m1 | k8m2 | k8m3 |
k8w2 | k8w3 | k8w4 | k8w5 | k8w6 |
We manually installed the SDC component of PowerFlex on the worker nodes of Kubernetes. We then configured a Kubernetes cluster (v 1.20) on the virtual machines with three master nodes and eight worker nodes:
$ kubectl get nodes
NAME STATUS ROLES AGE VERSION
k8m1 Ready control-plane,master 10d v1.20.10
k8m2 Ready control-plane,master 10d v1.20.10
k8m3 Ready control-plane,master 10d v1.20.10
k8w1 Ready <none> 10d v1.20.10
k8w2 Ready <none> 10d v1.20.10
k8w3 Ready <none> 10d v1.20.10
k8w4 Ready <none> 10d v1.20.10
k8w5 Ready <none> 10d v1.20.10
k8w6 Ready <none> 10d v1.20.10
Dell EMC storage solutions provide CSI plugins that allow customers to deliver persistent storage for container-based applications at scale. The combination of the Kubernetes orchestration system and the Dell EMC PowerFlex CSI plugin enables easy provisioning of containers and persistent storage.
In the solution, after we installed the Kubernetes cluster, CSI 2.0 was provisioned to enable persistent volumes for SQL BDC workload.
For more information about PowerFlex CSI supported features, see Dell CSI Driver Documentation.
For more information about PowerFlex CSI installation using Helm charts, see PowerFlex CSI Documentation.
Deploying Microsoft SQL Server BDC on Kubernetes Platform
When the Kubernetes cluster with CSI is ready, Azure data CLI is installed on the client machine. To create base configuration files for deployment, see deploying Big Data Clusters on Kubernetes . For this solution, we used kubeadm-dev-test as the source for the configuration template.
Initially, using kubectl, each node is labelled to ensure that the pods start on the correct node:
$ kubectl label node k8w1 mssql-cluster=bdc mssql-resource=bdc-master --overwrite=true
$ kubectl label node k8w2 mssql-cluster=bdc mssql-resource=bdc-compute-pool --overwrite=true
$ kubectl label node k8w3 mssql-cluster=bdc mssql-resource=bdc-compute-pool --overwrite=true
$ kubectl label node k8w4 mssql-cluster=bdc mssql-resource=bdc-compute-pool --overwrite=true
$ kubectl label node k8w5 mssql-cluster=bdc mssql-resource=bdc-compute-pool --overwrite=true
$ kubectl label node k8w6 mssql-cluster=bdc mssql-resource=bdc-compute-pool --overwrite=true
To accelerate the deployment of BDC, we recommend that you use an offline installation method from a local private registry. While this means some extra work in creating and configuring a registry, it eliminates the network load of every BDC host pulling container images from the Microsoft repository. Instead, they are pulled once. On the host that acts as a private registry, install Docker and enable the Docker repository.
The BDC configuration is modified from the default settings to use cluster resources and address the workload requirements. For complete instructions about modifying these settings, see Customize deployments section in the Microsoft BDC website. To scale out the BDC resource pools, the number of replicas are adjusted to use the resources of the cluster.
The values shown in the following table are adjusted in the bdc.json file.
Table 2: Cluster resources
Resource | Replicas | Description |
nmnode-0 | 2 | Apache Knox Gateway |
sparkhead | 2 | Spark service resource configuration |
zookeeper | 3 | Keeps track of nodes within the cluster |
compute-0 | 1 | Compute Pool |
data-0 | 1 | Data Pool |
storage-0 | 5 | Storage Pool |
The configuration values for running Spark and Apache Hadoop YARN are also adjusted to the compute resources available per node. In this configuration, sizing is based on 768 GB of RAM and 72 virtual CPU cores available per PowerFlex CO node. Most of this configuration is estimated and adjusted based on the workload. In this scenario, we assumed that the worker nodes were dedicated to running Spark workloads. If the worker nodes are performing other operations or other workloads, you may need to adjust these values. You can also override Spark values as job parameters.
For further guidance about configuration settings for Apache Spark and Apache Hadoop in Big Data Clusters, see Configure Apache Spark & Apache Hadoop in the SQL Server BDC documentation section.
The following table highlights the spark settings that are used on the SQL Server BDC cluster.
Table 3: Spark settings
Settings | Value |
spark-defaults-conf.spark.executor.memoryOverhead | 484 |
yarn-site.yarn.nodemanager.resource.memory-mb | 440000 |
yarn-site.yarn.nodemanager.resource.cpu-vcores | 50 |
yarn-site.yarn.scheduler.maximum-allocation-mb | 54614 |
yarn-site.yarn.scheduler.maximum-allocation-vcores | 6 |
yarn-site.yarn.scheduler.capacity.maximum-am- resource-percent | 0.34 |
The SQL Server BDC 2019 CU12 release notes state that Kubernetes API 1.20 is supported. Therefore, for this test, the image that was deployed on the SQL master pod was 2019-CU12-ubuntu-16.04. A storage of 20 TB was provisioned for SQL master pod, with 10 TB as log space:
"nodeLabel": "bdc-master",
"storage": {
"data": {
"className": "vxflexos-xfs",
"accessMode": "ReadWriteOnce",
"size": "20Ti"
},
"logs": {
"className": "vxflexos-xfs",
"accessMode": "ReadWriteOnce",
"size": "10Ti"
}
}
Because the test involved running the TPC-DS workload, we provisioned a total of 60 TB of space for five storage pods:
"storage-0": {
"metadata": {
"kind": "Pool",
"name": "default"
},
"spec": {
"type": "Storage",
"replicas": 5,
"settings": {
"spark": {
"includeSpark": "true"
}
},
"nodeLabel": "bdc-compute-pool",
"storage": {
"data": {
"className": "vxflexos-xfs",
"accessMode": "ReadWriteOnce",
"size": "12Ti"
},
"logs": {
"className": "vxflexos-xfs",
"accessMode": "ReadWriteOnce",
"size": "4Ti"
}
}
}
}
Validating SQL Server BDC on PowerFlex
To validate the configuration of the Big Data Cluster that is running on PowerFlex and to test its scalability, we ran the TPC-DS workload on the cluster using the Databricks® TPC-DS Spark SQL kit. The toolkit allows you to submit an entire TPC-DS workload as a Spark job that generates the test dataset and runs a series of analytics queries across it. Because this workload runs entirely inside the storage pool of the SQL Server Big Data Cluster, the environment was scaled to run the recommended maximum of five storage pods.
We assigned one storage pod to each worker node in the Kubernetes environment as shown in the following figure.
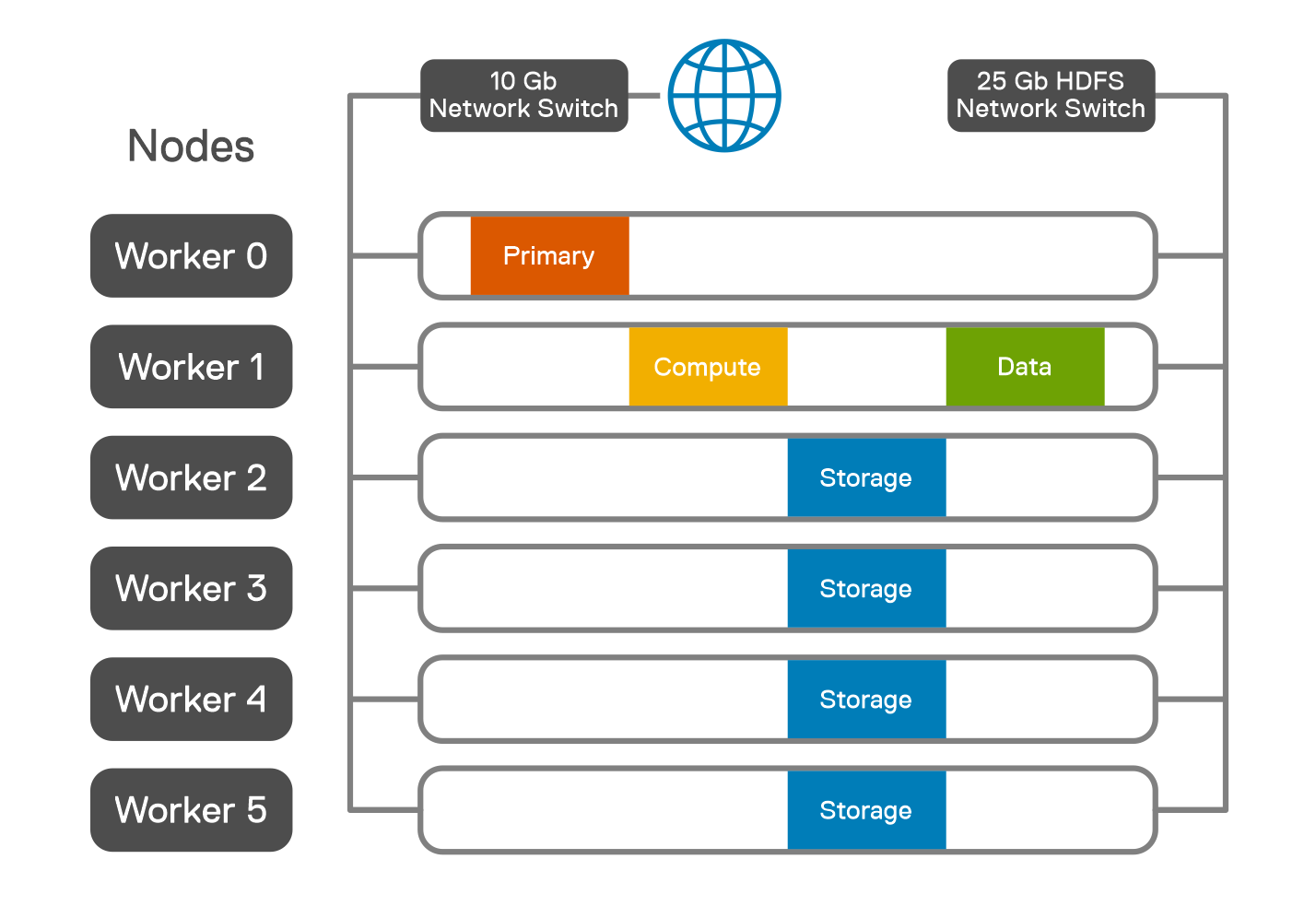
Figure 2: Pod placement across worker nodes
In this solution, Spark SQL TPC-DS workload is adopted to simulate a database environment that models several applicable aspects of a decision support system, including queries and data maintenance. Characterized by high CPU and I/O load, a decision support workload places a load on the SQL Server BDC cluster configuration to extract maximum operational efficiencies in areas of CPU, memory, and I/O utilization. The standard result is measured by the query response time and the query throughput.
A Spark JAR file is uploaded into a specified directory in HDFS, for example, /tpcds. The spark-submit is done by CURL, which uses the Livy server that is part of Microsoft SQL Server Big Data Cluster.
Using the Databricks TPC-DS Spark SQL kit, the workload is run as Spark jobs for the 1 TB, 5 TB, 10 TB, and 30 TB workloads. For each workload, only the size of the dataset is changed.
The parameters used for each job are specified in the following table.
Table 4: Job parameters
Parameter | Value |
spark-defaults-conf.spark.driver.cores | 4 |
spark-defaults-conf.spark.driver.memory | 8 G |
spark-defaults-conf.spark.driver.memoryOverhead | 484 |
spark-defaults-conf.spark.driver.maxResultSize | 16 g |
spark-defaults-conf.spark.executor.instances | 12 |
spark-defaults-conf.spark.executor.cores | 4 |
spark-defaults-conf.spark.executor.memory | 36768 m |
spark-defaults-conf.spark.executor.memoryOverhead | 384 |
spark.sql.sortMergeJoinExec.buffer.in.memory.threshold | 10000000 |
spark.sql.sortMergeJoinExec.buffer.spill.threshold | 60000000 |
spark.shuffle.spill.numElementsForceSpillThreshold | 59000000 |
spark.sql.autoBroadcastJoinThreshold | 20971520 |
spark-defaults-conf.spark.sql.cbo.enabled | True |
spark-defaults-conf.spark.sql.cbo.joinReorder.enabled | True |
yarn-site.yarn.nodemanager.resource.memory-mb | 440000 |
yarn-site.yarn.nodemanager.resource.cpu-vcores | 50 |
yarn-site.yarn.scheduler.maximum-allocation-mb | 54614 |
yarn-site.yarn.scheduler.maximum-allocation-vcores | 6 |
We set the TPC-DS dataset with the different scale factors in the CURL command. The data was populated directly into the HDFS storage pool of the SQL Server Big Data Cluster.
The following figure shows the time that is consumed for data generation of different scale factor settings. The data generation time also includes the post data analysis process that calculates the table statistics.
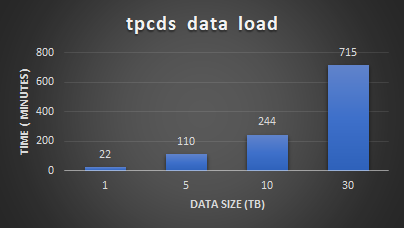
Figure 3: TPC-DS data generation
After the load we ran the TPC-DS workload to validate the Spark SQL performance and scalability with 99 predefined user queries. The queries are characterized with different user patterns.
The following figure shows the performance and scalability test results. The results demonstrate that running Microsoft SQL Server Big Data Cluster on PowerFlex has linear scalability for different datasets. This shows the ability of PowerFlex to provide a consistent and predictable performance for different types of Spark SQL workloads.
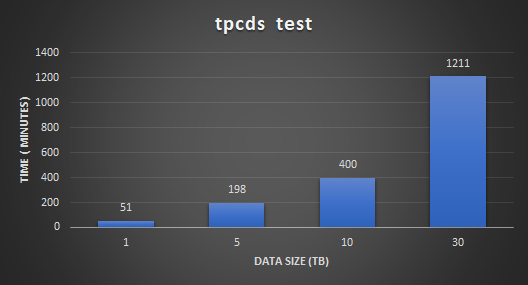
Figure 4: TPC-DS test results
A Grafana dashboard instance that is captured during the 30 TB run of TPC-DS test is shown in the following figure. The figure shows that the read bandwidth of 15 GB/s is achieved during the tests.
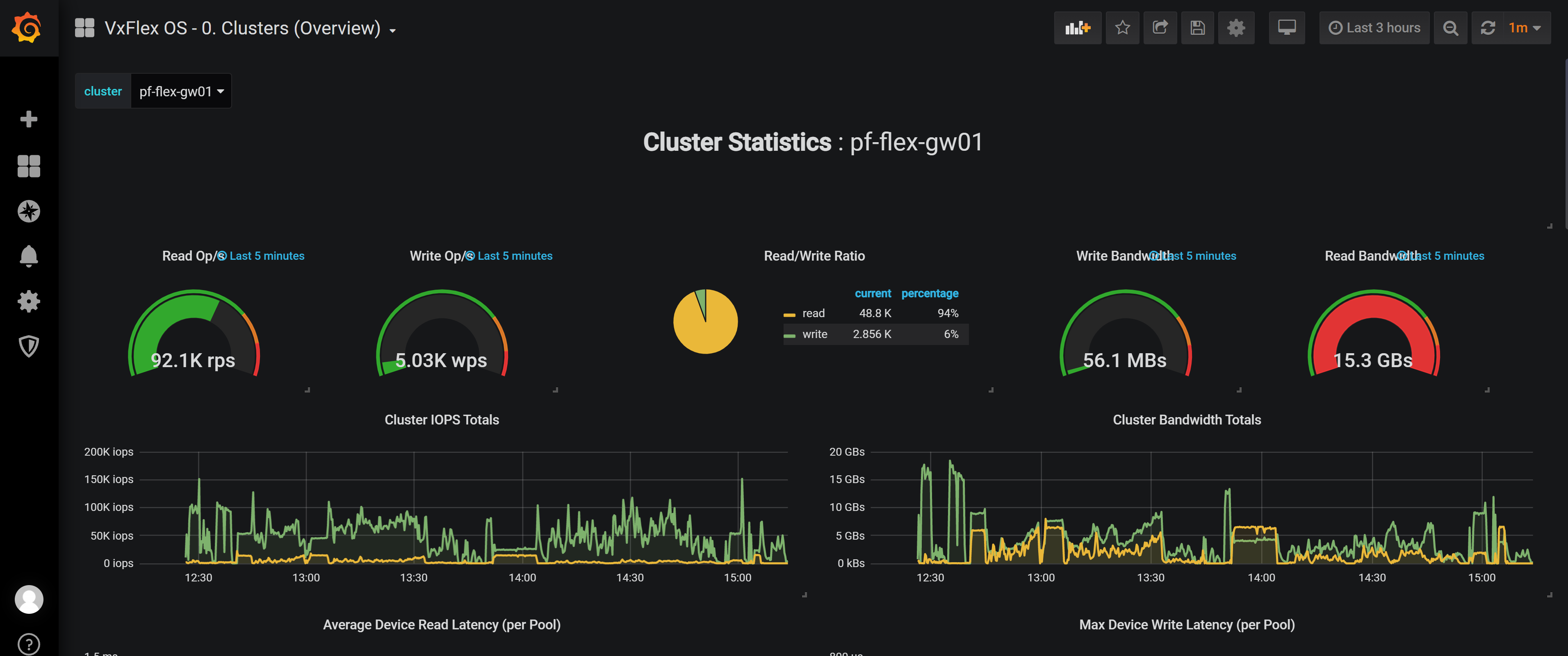
Figure 5: Grafana dashboard
In this minimal lab hardware, there were no storage bottlenecks for the TPC-DS data load and query execution. The CPU on the worker nodes reached close to 90 percent indicating that more powerful nodes could enhance the performance.
Conclusion
Running SQL Server Big Data Clusters on PowerFlex is a straightforward way to get started with modernized big data workloads running on Kubernetes. This solution allows you to run modern containerized workloads using the existing IT infrastructure and processes. Big Data Clusters allows Big Data scientists to innovate and build with the agility of Kubernetes, while IT administrators manage the secure workloads in their familiar vSphere environment.
In this solution, Microsoft SQL Server Big Data Clusters are deployed on PowerFlex which provides the simplified operation of servicing cloud native workloads and can scale without compromise. IT administrators can implement policies for namespaces and manage access and quota allocation for application focused management. Application-focused management helps you build a developer-ready infrastructure with enterprise-grade Kubernetes, which provides advanced governance, reliability, and security.
Microsoft SQL Server Big Data Clusters are also used with Spark SQL TPC-DS workloads with the optimized parameters. The test results show that Microsoft SQL Server Big Data Clusters deployed in a PowerFlex environment can provide a strong analytics platform for Big Data solutions in addition to data warehousing type operations.
For more information about PowerFlex, see Dell EMC PowerFlex. For more information about Microsoft SQL Server Big Data Clusters, see Introducing SQL Big Data Clusters.
If you want to discover more, contact your Dell representative.