




Deploy Virtualized NVIDIA Omniverse Environment with Dell PowerEdge R760xa and NVIDIA L40 GPUs

Related publications
This blog is part one of the blog series Dell Technologies PowerEdge R760xa with NVIDIA Omniverse:
- Part Two: Developing Digital Twin 3D Models on Dell PowerEdge R760xa with NVIDIA Omniverse virtualized platform
- Part Three: Synthetic Data Generation with Dell PowerEdge R760xa and NVIDIA Omniverse Platform
The following related technical white paper is also available:
A Digital Twin Journey: Computer Vision AI Model Enhancement with Dell Technologies Integrated Solutions & NVIDIA Omniverse
Introduction
Digital Twins (DT) and Artificial Intelligence (AI) are driving a massive increase in the volume of data organizations need to manage. Harnessing the insight potential from within this data is a constant challenge that drives the need for evermore performant and flexible solutions.
This article describes how hardware from Dell Technologies running NVIDIA Omniverse software can be deployed using GPU virtualization to provide more flexibility and performance for DT and AI applications.
The Technical Challenge
A key challenge for IT administrators is providing optimized infrastructure hardware and software that can support the integration of complex new technologies such as AI and DT.
NVIDIA Omniverse offers an integrated ecosystem of solutions harnessing hardware acceleration plus software designed for DT workloads and 3D modeling collaboration.
Omniverse
The NVIDIA Omniverse platform offers developers a vast increase in creativity and efficiency potential. It is a scalable, multi-GPU, real-time reference development suite for 3D modeling and design collaboration based on the Pixar Universal Scene Description (USD) framework and NVIDIA RTX technology.
Designers, artists, and creators can use the power of Omniverse to accelerate their DT and high-fidelity 3D workflows. It provides real-time ray tracing and AI-enhanced graphics, quintessential for simulating the real world within a DT environment.
Dell PowerEdge R760xa Server
The PowerEdge R760xa server shines for both DT and AI applications. Coupled with either 4x NVIDIA L40 or L40S PCIe, 48 GB GPUs and enabled by Intel Xeon Scalable processors, this server provides the processing muscle for reliable, precise, and fast 3D Graphics and Compute centric workloads.
The PowerEdge R760xa server is positioned perfectly to meet the diverse needs of DT requirements such as 3D modeling, physics simulations, image rendering, computer vision, robotics, edge computing, AI training and Inferencing.
 Figure 1: Front view of the Dell PowerEdge R760xa server
Figure 1: Front view of the Dell PowerEdge R760xa server
 Figure 2: Top View of the Dell PowerEdge R760xa server
Figure 2: Top View of the Dell PowerEdge R760xa server
Laying the Foundation for A Digital Twin Environment:
Omniverse installations come in two deployment flavors: Omniverse Workstation or Enterprise. This article concentrates on the deployment of Omniverse Enterprise on Dell PowerEdge R760xa servers.
Deploying Omniverse Enterprise as a virtualized instance enables a flexible infrastructure configuration that is tailored to individual requirements, such as splitting physical GPUs resources into vGPU partitions. This flexibility can prove immensely beneficial when DT or AI workload needs are likely to change during development.
NVIDIA’s Omniverse Install Guide references three key components, all of which can be served within the confines of a virtualized environment.
| Component | Description |
|---|---|
| Licensing | Mechanism to procure and enable Omniverse software. |
| Enterprise Nucleus | The central database and collaborative engine of Omniverse. Enables users to share and modify representations of virtual worlds. |
| Launcher | The native client for downloading, installing, and updating Omniverse Apps, Extensions, and Connectors. |
Some prerequisites before you start:
- NVIDIA Enterprise or Developer Account.
- Suitable Graphics Capable GPU, such as NVIDIA Lovelace GPU series
- NVIDIA GPU driver (≥471.11)
- Suitable OS—Linux or Windows
- Note that each Launcher Application may have its own unique system requirements.
Setting Up a Virtualized Omniverse
NVIDIA’s Virtualized Deployment Guide outlines several foundational steps needed to create a virtualized Omniverse solution.
- VMware vSphere ESXi Hypervisor
- VMware vCenter
- NVIDIA vGPU Manager (VIB)
- NVIDIA License System (NLS)
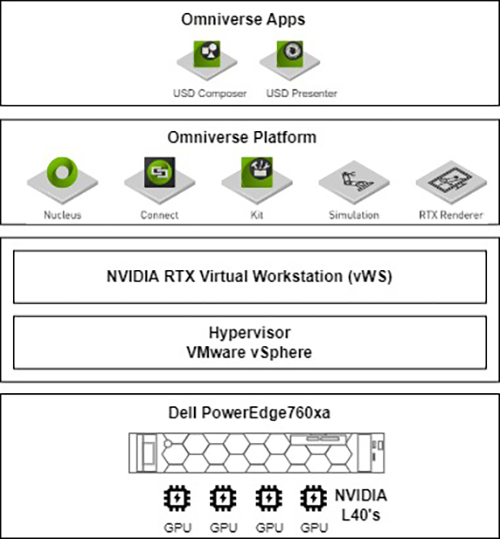 Figure 3: Virtualized Omniverse Stack
Figure 3: Virtualized Omniverse Stack
Virtualized Omniverse environments that are built on top of high-performant infrastructure like the Dell PowerEdge R760xa server create a foundation for building 3D, DT, and AI solutions.
| Platform | Dell PowerEdge 760xa | |
| CPU | 2x Intel(R) Xeon(R) Gold 6438M | |
| GPU | 4x NVIDIA L40 | |
| FP32(Tera Flops) | 90 | |
| Memory (GB) | 48 GDDR6 w/EEC | |
| Media Engines | 3 Video Encoder 3 Video Decoder 4 JPEG Decoder | |
| Power (Watts) | 300 | |
| Memory | 512 GB DDR5 | |
| Software Stack | VMware ESXi, 8.0.1 Windows 10 Enterprise 10.0.19045 NVIDIA vGPU Grid Driver 16.1 Omniverse USD Composer 2023.2.0 Omniverse Launcher 1.8.11 Omniverse Nucleus 2023.1.0 | |
Post-Deployment Configuration Example.
The following figure shows a VMware vCenter Omniverse USD Composer Virtual Workstation configured with 4 x L40 vGPUs.
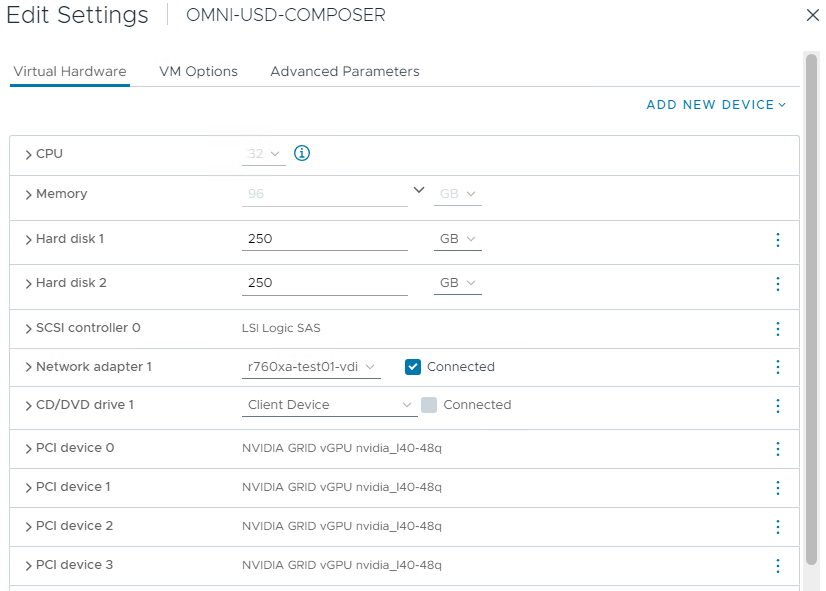 Figure 4: Omniverse USD Composer Virtual Workstation configured with 4 x vGPUs
Figure 4: Omniverse USD Composer Virtual Workstation configured with 4 x vGPUs
A sample 3D scene being rendered within the Omniverse USD Composer application is shown in the following figure.
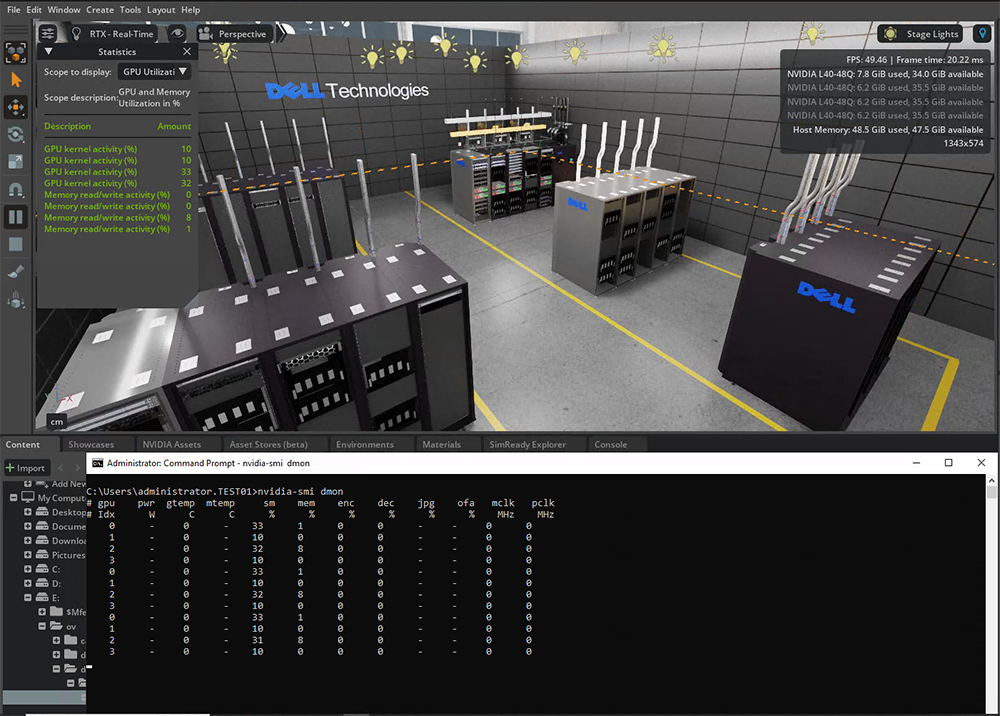 Figure 5: Omniverse USD Composer App using 4 x L40 GPUs
Figure 5: Omniverse USD Composer App using 4 x L40 GPUs
The NVIDIA-SMI command-line utility shows 4 physical L40 GPUs configured in vGPU mode with Virtual Workstation vWS profile (Enabling both graphic and compute acceleration). Natively the USD Composer App consumes all available GPU resources to render the depicted 3D scene.
A more realistic virtualized Omniverse configuration might be, 1 to 2 GPUs assigned to rendering tasks with other GPUs being assigned to other 3D or DT tasks, such as PhysX simulations or AI model training.
Conclusion
Complex DT workloads encapsulate the integration of 3D models, simulations, and AI software components, each with their own unique system requirements. NVIDIA Omniverse is not a one-size-fits-all solution but rather a dynamic 3D ecosystem for collaboratively creating shared virtual worlds.
Often in development scenarios, system requirements may not be fully understood and thus the need for a flexible infrastructure solution. Omniverse can be easily configured and customized for various applications and customer needs as development evolves.
We found that virtualized Omniverse deployment allows for amazing flexibility to meet numerous workload requirements!
References
Virtual Workstation Interactive Collaboration with NVIDIA Omniverse