




Dell PowerEdge HS5610—Cold Aisle Service: Blind Mate Rail Kit
Download PDFThu, 20 Apr 2023 15:39:35 -0000
|Read Time: 0 minutes
Summary
Large scale data centers are often designed with contained hot aisles to manage ambient temperature. Hot aisle/cold aisle layout involves lining up server racks in alternating rows with cold air intakes, the fronts of servers, facing each other (the “cold aisle”) and hot air exhausts, the backs of servers, facing each other (the “hot aisle”). While this approach to data center design increases control over temperature and power consumption, it can also lead to safety (OSHA) and management efficiency concerns for the technicians who administer data center infrastructure. To address these issues, customers are pushing for cold-aisle-serviceable configurations to reduce the need to enter the hot aisle.
What are blind mate power rails?
Blind mate power rails are static rails that include extra power pass-through bracket assemblies to allow for the ability to connect power and then remove or service the HS5610 without needing hot-aisle access. These rails do not allow for hot-swapping of internal components or in-rack serviceability and are not compatible with strain relief bars (SRBs) or cable management arms (CMAs).
Blind mate power rails:
- Support stab-in installation of the chassis to the rails
- Support tool-less installation in 19-inch EIA-310-E compliant square or unthreaded round hole 4-post racks including all generations of Dell racks
- Support tooled installation in 19-inch EIA-310-E compliant threaded hole 4-post racks
- Support tooled installation in Dell Titan or Titan-D racks
These rails are compatible with the HS5610 cold-aisle-service configuration only.
Customer installation for static rails
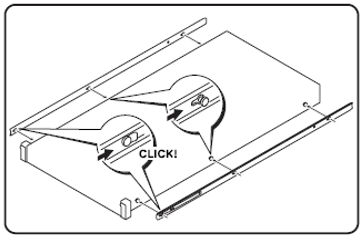
Step 1: Install chassis members onto server.
- Install chassis rail members with extra length behind server for inner bracket.
- Attach inner bracket to rail chassis members, using supplied screws and a Phillips screwdriver.
- Plug the power cord pigtails into the PSUs.
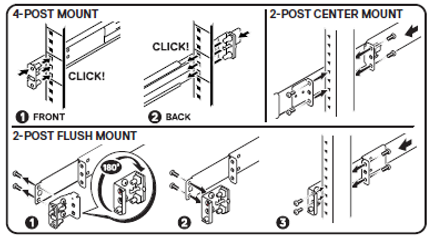
Step 2: Install cabinet members into rack.
- Attach the outer bracket to installed rail cabinet members by aligning the t-nut and pogo-pin features (should “snap in” both sides).
- Plug external power to the outer bracket receptacles, just as you would an installed server.
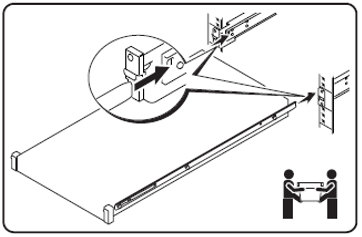
Step 3: Stab-in the chassis to the cabinet guides, and slide it back until rack ears latch to rail mounting brackets. Go around to the hot aisle and plug in the PSUs to power on the server.

Limits
Any cables that do not come out the front need to have blind-mate functionality. Having cables without blind-mate functionality limits our ability to have in-rack service (and an on-rails “service position”), which limits our rails to “static” designs.
Conclusion
Once the cabinet members are installed and powered, service no longer requires hot-aisle access.
References
For more information about PowerEdge HS5610, see the PowerEdge HS5610 Specification Sheet.
For more information about the PowerEdge HS5610 blind mate rail kit, see A22 Rail Installation Guide.