




Bringing AMD to the Datacenter
Download PDFMon, 16 Jan 2023 23:56:53 -0000
|Read Time: 0 minutes
Summary
IT administrators are excited to reap the benefits of these high core count processors but are unsure of how to best incorporate a second x86 architecture in their datacenter. This Direct from Development tech note discusses compatibility between Intel and AMD processors, workload migrations and scheduler support for heterogenous environments.
Introduction
Today we have more capabilities than ever before coming from our IT departments. They operate datacenters and manage workloads that provide collaboration, insight and enable operations. As customers look to expand these services, they often ask about the 2nd generation of AMD EPYC processors (Rome), how their workload will perform, and what it means to operate a datacenter where two different x86 vendors are present. In this Direct from Development tech note we briefly cover the AMD EPYC 7002 series of processors before going over best practices and key considerations operating two x86 instruction sets in your datacenter.
AMD EPYC 7002 series
AMD EPYC 7002 series processors have the highest core density currently offered in the x86 market with the AMD EPYC 7742 containing 64 cores. In addition to this extreme core count, the EPYC CPU lineup also offers several SKUs that have configurations optimized for a specific workload such as the recently announced 7Fxx series which support up to 32 cores at boost frequencies of 3.9Ghz, a half gigahertz increase over what is offered by other EPYC CPUs. The 7Fxx lineup of CPUs is targeted at hyper converged infrastructure, high performance computing and relational database management systems such as SQL.
Deploying and Managing EPYC in the Data Center
Introducing new hardware in the datacenter requires careful consideration. IT operations teams will likely want to first test and validate several workloads as a prototype before deploying into the production environment, and tooling + procedures will need to be put in place to manage the lifecycle of these servers. For Dell EMC customers this is a relatively seamless process – both the Intel and AMD line of 14G PowerEdge servers contain iDRAC9. This enables operations teams to use the same familiar interface to deploy, manage and secure all PowerEdge servers. Customers who use OpenManage Enterprise will find that it puts all of the systems in a single pane of glass for management and updates and provides granularity to support different firmware baselines.
Even with a universal management framework through iDRAC9 there are other considerations for how to cluster these systems, the impact on workload scheduling and how to migrate workloads. Before discussing that, a bit on iDRAC telemetry. As you deploy new systems and manage a diverse set of applications it becomes increasingly difficult to monitor the performance and health of these workloads. With the iDRAC9 Data Center edition you can stream telemetry information into databases such as Graphana or Prometheus. With all systems streaming telemetry into a single database you can better understand the health of workloads in your datacenter and respond to issues quicker. As you make decisions about which applications to deploy on AMD systems, this data can be used to compare metrics that are relevant to application performance and allow you to make data driven decisions on where to deploy.
Mixed CPU Cluster Compatibility
Most customers who are purchasing their first AMD system have an existing footprint of x86 processors. This drives concerns and questions from our customers about the compatibility of their clusters across the two different x86 instruction sets. Services that operate in a clustered fashion are generally a homogenous configuration for ease of management and to provide consistent performance. As we move to a world that consists of not just the core datacenter but also the cloud and edge, it is becoming increasingly common for services to operate a collection of clusters, the configuration of which will be optimized for both site (edge, core, cloud) and function.
There are several reasons IT administrators may want to avoid a mixture of processor generations and vendors in a clustered system. One is that migration tools such as vMotion Live Migration do not work due to differences in the instruction set architecture between x86 vendors. This doesn’t apply to generations of processors from the same vendor if supported by Enhanced vMotion Compatibility (EVC) mode but enabling this has a performance cost [1]. Another reason is that maintenance windows will be hard to keep up with when you have BIOS and microcode updates coming from two different vendors. Multiple generations of processors can make updates difficult because of the additional effort that is needed to complete increased amount of testing that must be done, which is at least one for each generation of processor.
IT leaders now have more options for x86 processors and should evaluate each new system deployment and consider if Intel or AMD processors would be optimal for the workload and environment. For example, a large network service provider has deployed AMD due to the benefits they saw in the large L3 cache present on AMD EPYC processors. Conversely a major retail customer of Dell EMC looking to deploy AI services at 400 edge locations selected Intel Xeon Cascade Lake processors for their support of DLBoost, a technology that allows twice as many AI inference operations at 8-bit precision.
Workload Migration
IT administrators move workloads between systems and clusters for a variety of reasons, some planned and some unplanned. As touched on earlier, some workload migration techniques such as VMware vMotion Live Migration are not compatible between Intel and AMD systems. This is an important limitation that must be accounted for when considering high availability, fault capacity and how you conduct general day to day activities such as cluster balancing and planned maintenance.
In the event it is necessary to migrate a workload between Intel and AMD processor-based systems, there are a few options. For VMware environments, while vMotion Live Migration does not work, you can do a cold migration after shutting down the virtual machine. In other cases, you can use application specific migration techniques. Most applications support backup/restore functionality that can be used in conjunction with tools like load balancers to allow migration with little or no downtime.
Heterogenous Scheduling
Workload schedulers such as Slurm, kube-scheduler and Hadoop all support various methods of gaining awareness and preference when determining which CPU to schedule a workload. With Slurm, nodes are divided into partitions and it is trivial to separate Intel and AMD systems into different partitions. Hadoop 3 and kube-scheduler support a variety of features that enable exposing CPU information and grouping similar systems using labels, namespaces and roles.
For now, schedulers still require explicit definition of whether to run a workload AMD or another processor if you want consistent performance, though policy-based rules can provide default definitions. Capacity planning is also challenging when attempting to do heterogenous scheduling, and because of this complexity it is a good idea to avoid heterogenous scheduling for real time applications and instead only use this for non-real-time applications such as data processing and batch workloads.
In Conclusion
Dell EMC offers several PowerEdge servers that support AMD EPYC 7002 series processors. The PowerEdge R6515 and R7515 support a single 7002-series processor and the PowerEdge C6525, R6525 and R7525 support two processors. The C6525 for those unfamiliar with it is a 2U server with 4 compute sleds. Configured with two 64-core AMD processors per sled this chassis can provide 512 CPU cores in a 2U footprint. All the PowerEdge models listed also have support for PCIe 4.0, though the number of expansion slots varies by model.

To effectively make use of these systems’ capacity, administrators should use homogenous configurations for clustered services and ensure they have a tested procedure to migrate their workloads. Heterogenous collections of systems are best suited for batch workloads. Finally, customers can optimize the performance of their workload by using processor SKUs that have specific features and capabilities for enhanced performance.
https://www.vmware.com/content/dam/digitalmarketing/vmware/en/pdf/techpaper/vmware-vsphere-evc- performance-white-paper.pdf
Related Documents

Understanding the Value of AMDs Socket to Socket Infinity Fabric
Tue, 17 Jan 2023 00:43:22 -0000
|Read Time: 0 minutes
Summary
AMD socket-to-socket Infinity Fabric increases CPU-to-CPU transactional speeds by allowing multiple sockets to communicate directly to one another through these dedicated lanes. This DfD will explain what the socket-to-socket Infinity Fabric interconnect is, how it functions and provides value, as well as how users can gain additional value by dedicating one of the x16 lanes to be used as a PCIe bus for NVMe or GPU use.
Introduction
Prior to socket-to-socket Infinity Fabric (IF) interconnect, CPU-to-CPU communications generally took place on the HyperTransport (HT) bus for AMD platforms. Using this pathway for multi-socket servers worked well during the lifespan of HT, but developing technologies pushed for the development of a solution that would increase data transfer speeds, as well as allow for combo links.
AMD released socket-to-socket Infinity Fabric (also known as xGMI) to resolve these bottlenecks. Having dedicated IF links for direct CPU-to- CPU communications allowed for greater data-transfer speeds, so multi-socket server users could do more work in the same amount of time as before.
How Socket-to-Socket Infinity Fabric Works
IF is the external socket-to-socket interface for 2-socket servers. The architecture used for IF links is a combo of serializer/deserializer (SERDES) that can be both PCIe and xGMI, allowing for sixteen lanes per link and a lot of platform flexibility. xGMI2 is the current generation available and it has speeds that reach up to 18Gbps; which is faster than the PCIe Gen4 speed of 16Gbps. Two CPUs can be supported by these IF links. Each IF lane connects from one CPU IO die to the next, and they are interwoven in a similar fashion, directly connecting the CPUs to one- another. Most dual-socket servers have three to four IF links dedicated for CPU connections. Figure 1 depicts a high- level illustration of how socket to socket IF links connect across CPUs.
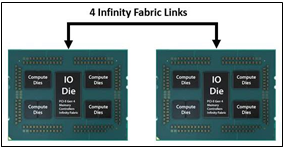
Figure 1 – 4 socket to socket IF links connect two CPUs
The Value of Infinity Fabric Interconnect
Socket to socket IF interconnect creates several advantages for PowerEdge customers:
- Dedicated IF lanes are routed directly from one CPU to the other CPU, ensuring inter-socket communications travel the shortest distance possible
- xGMI2 speeds (18Gbps) exceed the speeds of PCIe Gen4, allowing for extremely fast inter-socket data transfer speeds
Furthermore, if customers require additional PCIe lanes for peripheral components, such as NVMe or GPU drives, one of the four IF links are a cable with a connector that can be repurposed as a PCIe lane. AMD’s highly optimized and flexible link topologies enable sixteen lanes per socket of Infinity Fabric to be repurposed. This means that 2S AMD servers, such as the PowerEdge R7525, have thirty-two additional lanes giving a total of 160 PCIe lanes for peripherals. Figure 2 below illustrates what this would look like:
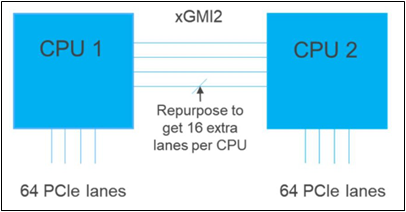
Figure 2 – Diagram showing additional PCIe lanes available in a 2S configuration
Conclusion
AMDs socket-to-socket Infinity Fabric interconnect replaced the former HyperTransport interconnect in order to allow massive amounts of data to travel fast enough to avoid speed bottlenecks. Furthermore, customers needing additional PCIe lanes can repurpose one of the four IF links for peripheral support. These advantages allow AMD PowerEdge servers, such as the R7525, to meet our server customer needs.

Understanding Confidential Computing with Trusted Execution Environments and Trusted Computing Base models
Tue, 17 Jan 2023 00:35:08 -0000
|Read Time: 0 minutes
Summary
As the value of data increases, it becomes essential to protect data in- use from unauthorized access. Confidential Computing provides various levels of protection options to mitigate different kinds of threat vectors.
Introduction
Data is the new oil. As the value of data increases, it becomes increasingly important to protect data in-use to perform computations. Data in use is often stored in the clear in memory (DRAM) and accessed via unencrypted memory buses. Whether data in use is a machine learning data set or relates to keeping a secret in memory, data in-use can be vulnerable to threats vectors that can snoop on the contents of memory or the access bus. Data- in-use protection is necessary to secure computations that are increasingly operating on large data sets in memory. Additionally, code executing on the data must be trusted, tamper-free with facilities to separate trusted and non-trusted code execution environments with respect to data in-use.
Trusted Execution Environments and Trusted Computing Base models
With per country regulation requirements on data confidentiality increasing, data generators and users need secure TEEs (Trusted Executions Environments) to satisfy data privacy and protection regulations. Hosting and Infrastructure providers must enable trusted execution environment to guarantee data confidentiality of client data. This requires that entities outside the trust boundary should not be able to access the data in-use
To mitigate against increasing threat vectors combined with usage models that range from multi-tenant environments to edge deployments, trust boundaries need to shrink. Data owners and clients should prefer to keep a small TCB (Trusted Computing Base) to minimize attack coordinates and data misuse by untrusted elements. They should look closely at what TCB levels they can trust for their usage model. A TCB level informs the code footprint that can be trusted
While a reduced TCB can be achieved using software techniques, silicon-aided features can greatly aid the creation, separation and protection of TEEs with reduced TCBs. Silicon features are needed to minimize TCB to a Trusted Host Execution Environment, Trusted Virtual Machine Execution environment, and a Trusted Application Execution Environment for new and emerging deployments
Picking an appropriate TCB footprint level
To consider an appropriate TCB footprint level, one should determine if the entity hosting the code and data execution environment can be trusted and has the facility to separate trusted and non- trusted components. For e.g., a data center level TCB can imply a data center administrator is a trusted operator for the data in use. This means the entire data center execution environment is trusted and applications users can employ a data center wide application/workload deployment policy. A Platform/Host level TCB requirement can imply a system administrator is a trusted operator for the data and the code running on the platform and can deploy a trusted Host execution environment for the workloads. A VM level TCB footprint requirement implies a trusted guest machine user for data in use running in a trusted Guest Execution Environment. An App level TCB footprint requirement can imply only the App owner is trusted with data in use access. See Figure 1 for a representation of various TCB footprint levels. If you observe carefully, as TCB footprint shrinks, the application owner has fewer layers of trusted software.
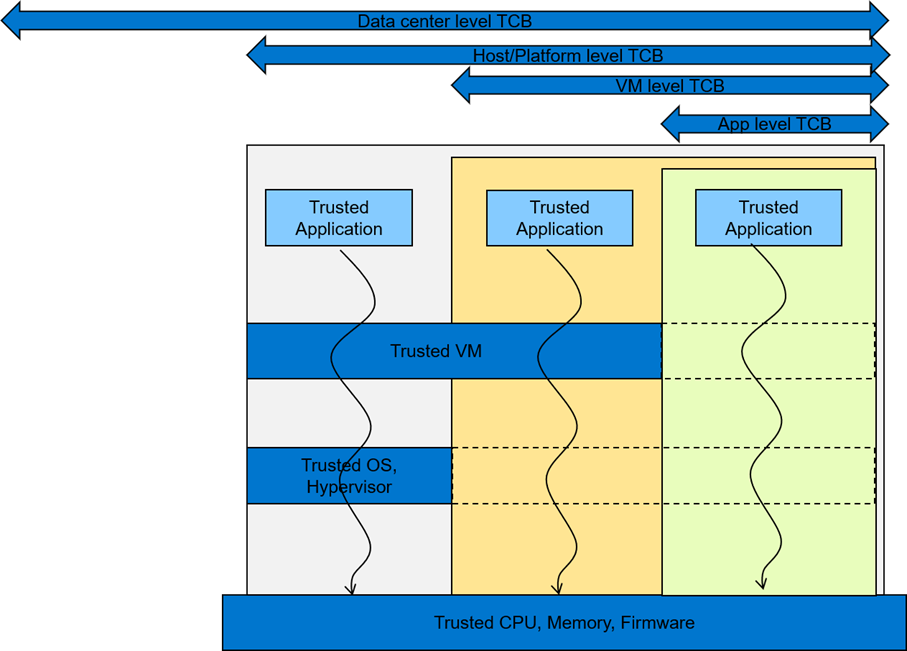
Figure 1 A view of various TCB footprint levels
These levels come with varying degree of usability to application deployments. They have unique advantages and tradeoffs when it comes performance, application mobility, trust granularity and integration with management stacks.
In general, to enable these TEEs, silicon enables memory encryption such that trusted, differentiated and secure memory access is possible for data in use. Data/app owners must be able to independently attest to the integrity of the platform and the TCB levels supported by the underlying infrastructure.
Dell believes in the power of choice when it comes to offering a trusted execution environment with a level of TCB needed to run your applications. Dell’s breadth of technologies including the enhanced cyber resilient architecture that is part of the latest generations of PowerEdge servers enables usages at the edge, core and the cloud.
Conclusion
To maximize protection of data in-use, consideration should be given to the TCB footprint that is appropriate for the use case. Dell EMC PowerEdge servers are loaded with top notch security features to provide maximum protection for your data. In addition, Dell Technologies is pleased to partner with key vendors to support features like SME, SEV-ES, and SGX, etc. with various levels of confidential computing usage models that cater to various Trusted Execution Environments