




Breaking down the barriers for VDI with VxRail and NVIDIA vGPU
Wed, 21 Apr 2021 15:17:54 -0000
|Read Time: 0 minutes
Desktop transformation initiatives often lead customers to look at desktop and application virtualization. According to Gartner, “Although few organizations planned for the global circumstances of COVID-19, many will now decide to have some desktop virtualization presence to expedite business resumption.”
However, customers looking to embrace these technologies have faced several hurdles, including:
- Significant up-front CapEx investments for storage, compute, and network infrastructure
- Long planning, design, and procurement cycles
- High cost of adding additional capacity to meet demand
- Difficulty delivering a consistent user experience across locations and devices
These hurdles have often caused desktop transformation initiatives to fail fast, but there is good news on the horizon. Dell Technologies and VMware have come together to provide customers with a superior solution stack that will allow them to get started more quickly than ever, with simple and cost-effective end-to-end desktop and application virtualization solutions using NVIDIA vGPU and powered by VxRail.
Dell Technologies VDI solutions powered by VxRail
Dell Technologies VDI solutions based on VxRail feature a superior solution stack at an exceptional total cost of ownership (TCO). The solutions are built on Dell EMC VxRail and they leverage VMware Horizon 8 or Horizon Apps and NVIDIA GPU for those who need high-performance graphics. Wyse Thin and Zero client, OptiPlex micro form factor desktop, and Dell monitors are also available as part of these solutions. Simply plug in, power up, and provision virtual desktops in less than an hour, reducing the time needed to plan, design, and scale your virtual desktop and application environment.
VxRail HCI system software provides out-of-the-box automation and orchestration for deployment and day-to-day system-based operational tasks, reducing the overall IT OpEx required to manage the stack. You are not likely to find any build-it-yourself solution that provides this level of lifecycle management, automation, and operational simplicity
Dell EMC VxRail and NVIDIA GPU a powerful combination
Remote work has become the new normal, and organizations must enable their workforces to be productive anywhere while ensuring critical data remains secure.
Enterprises are turning to GPU-accelerated virtual desktop infrastructure (VDI) because GPU-enabled VDI provides workstation-like performance, allowing creative and technical professionals to collaborate on large models and access the most intensive 3D graphics applications.
Together with VMware Horizon, NVIDIA virtual GPU solutions help businesses to securely centralize all applications and data while providing users with an experience equivalent to the traditional desktop.
NVIDIA vGPU software included with the latest VMware Horizon release, which is available now, helps transform workflows so users can access data outside the confines of traditional desktops, workstations, and offices. Enterprises can seamlessly collaborate in real time, from any location, and on any device.
With NVIDIA vGPU and VMware Horizon, professional artists, designers, and engineers can access new features such as 10bit HDR and high-resolution 8K display support while working from home by accessing their virtual workstation.
How NVIDIA GPU and Dell EMC VxRail power VDI
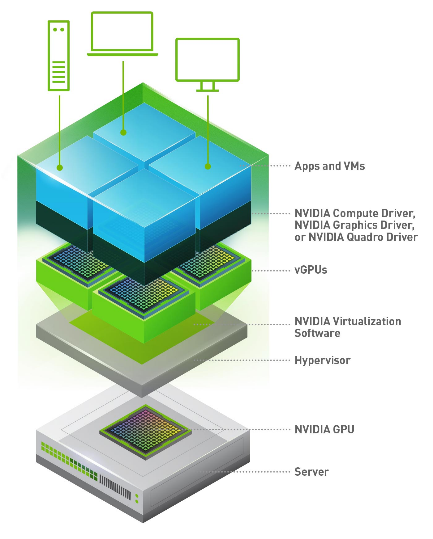
In a VDI environment powered by NVIDIA virtual GPU, the virtual GPU software is installed at the virtualization layer. The NVIDIA software creates virtual GPUs that enable every virtual machine to share a physical GPU installed on the server or allows for multiple GPUs to be allocated on a single VM to power the most demanding workloads. The NVIDIA virtualization software includes a driver for every VM. Because work that was previously done by the CPU is offloaded to the GPU, the users, even demanding engineering and creative users, have a much better experience.
Virtual GPU for every workload on Dell EMC VxRail
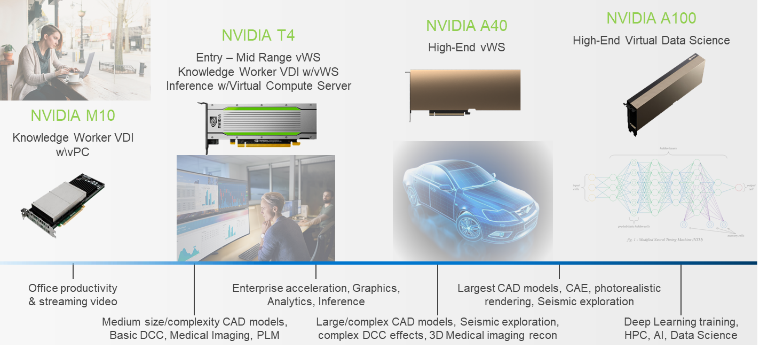 As more knowledge workers are added on a server, the server will run out of CPU resources. Adding an NVIDIA GPU offloads CPU operations that would otherwise use the CPU, resulting in an improved user experience and performance. We used the NVIDIA nVector knowledge worker VDI workload to test user experience and performance with NVIDIA GPU. The NVIDIA M10, T4, A40, RTX6000/8000 and V100S, all of which are available on Dell EMC VxRail, achieve similar performance for this workload.
As more knowledge workers are added on a server, the server will run out of CPU resources. Adding an NVIDIA GPU offloads CPU operations that would otherwise use the CPU, resulting in an improved user experience and performance. We used the NVIDIA nVector knowledge worker VDI workload to test user experience and performance with NVIDIA GPU. The NVIDIA M10, T4, A40, RTX6000/8000 and V100S, all of which are available on Dell EMC VxRail, achieve similar performance for this workload.
Customers are realizing the benefits of increased resource utilization by leveraging GPU-accelerated Dell EMC VxRail to run virtual desktops and workstations. They are also leveraging these resources to run compute workloads, for example AI or ML, when users are logged off. Customers who want to be able to run compute workloads on the same infrastructure on which they run VDI, might leverage a V100S to do so. For the complete list, see NVIDIA GPU cards supported on Dell EMC VxRail.
Conclusion
With the prevalence of graphics-intensive applications and the deployment of Windows 10 across the enterprise, adding graphics acceleration to VDI powered by NVIDIA virtual GPU technology is critical to preserving the user experience. Moreover, adding NVIDIA GRID with NVIDIA GPU to VDI deployments increases user density on each server, which means that more users can be supported with a better experience.
To learn more about measuring user experience in your own environments, contact your Dell Account Executive.
Useful links
Video: VMware Horizon on Dell Technologies Cloud
Dell Technologies Solutions: Empowering your remote workforce
Certified GPU for VxRail: NVIDIA vGPU for VxRail[
Everything VxRail: Dell EMC VxRail
VDI Design Guide: VMware Horizon on VxRail and vSAN Ready Nodes
Latest VxRail release: Simpler cloud operations and more deployment options!