




Accelerating AI Performance: MLPerf 3.0 Training Results with Dell PowerEdge
Download PDFWed, 28 Jun 2023 00:02:48 -0000
|Read Time: 0 minutes
Executive Summary
The PowerEdge XE9680 is a high-performance server designed and optimized to enable uncompromising performance for artificial intelligence, machine learning, and high-performance computing workloads. Dell PowerEdge has launched our innovative 8-way GPU platform with advanced features and capabilities.
- 8x NVIDIA H100 80GB 700W SXM GPUs or 8x NVIDIA A100 80GB 500W SXM GPUs

- 2x Fourth Generation Intel® Xeon® Scalable Processors
- 32x DDR5 DIMMs at 4800MT/s
- 10x PCIe Gen 5 x16 FH Slots
- 8x SAS/NVMe SSD Slots (U.2 or E.3) and BOSS-N1 with NVMe RAID
We are thrilled to share this insightful report that provides performance insights into the exceptional capabilities of the PowerEdge XE9680. Through rigorous testing and evaluation using MLPerf 3.0 benchmarks from MLCommons, this document offers a detailed analysis of the PowerEdge XE9680's outstanding performance in AI model training.
MLPerf is a suite of benchmarks that assess the performance of machine learning (ML) workloads, focusing on two crucial aspects of the ML life cycle: training and inference. This tech note delves explicitly into the training aspect of MLPerf 3.0.
Performance
The Dell performance labs conducted MLPerf 3.0 Training benchmarks using the latest PowerEdge XE9680 with 8x NVIDIA H100 80GB SXM GPUs. For comparison, we also ran these tests on the previous generation PowerEdge XE8545, equipped with 4x NVIDIA A100 80GB SXM GPUs.
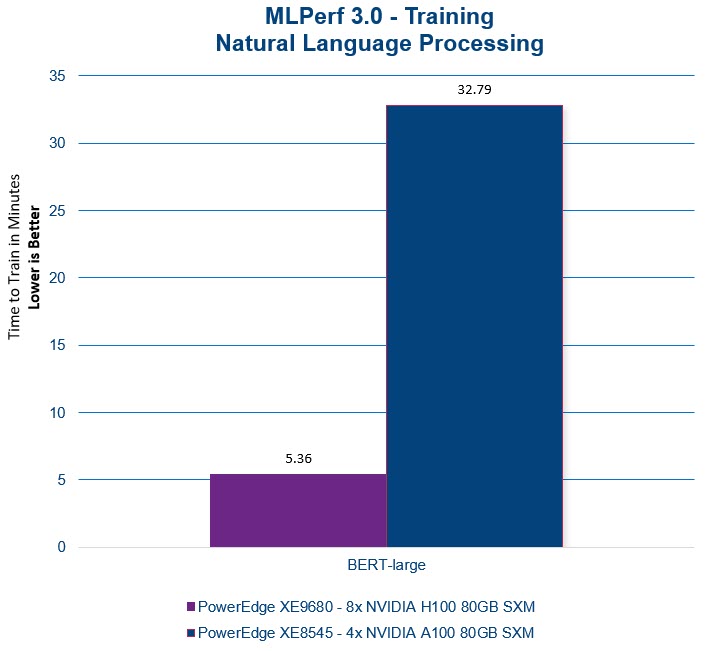
BERT (Bidirectional Encoder Representations from Transformers) is a transformer-based neural network model introduced by Google in 2018. It is designed to understand and generate human-like text by capturing the context and meaning of words in each sequence. We are thrilled that the PowerEdge XE9680 with H100 GPUs delivered a 6x time-to-train performance improvement in the MLPerf NLP benchmark results using the BERT-large model with the Wikipedia dataset. This translates to accelerated time-to-value as we help our customers unlock the potential of remarkably faster model training.
Please note that throughout this report, a lower time-to-train value indicates improved efficiency and faster model convergence. As you analyze the graphs and performance metrics, remember that achieving lower time-to-train values demonstrates the PowerEdge XE9680's ability to expedite AI model training, delivering enhanced speed and efficiency results.
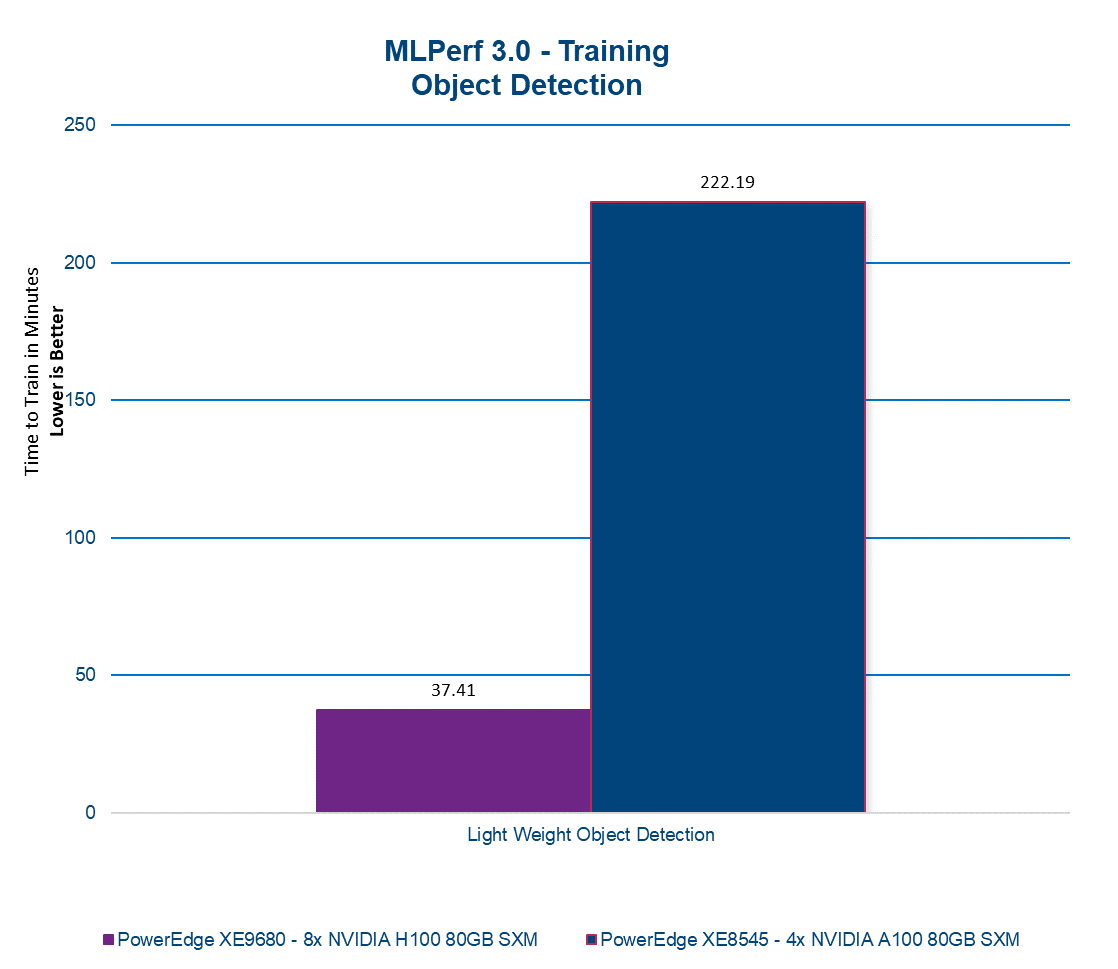
In MLPerf 3.0, the RetinaNet model leverages the Open Images dataset of millions of diverse images. In this benchmark, we observed an impressive, nearly 6x enhancement in training time for the model.
By utilizing the RetinaNet model with the Open Images dataset, MLPerf enables comprehensive evaluations and comparisons of system capabilities. The scale and diversity of the dataset ensure a robust assessment of object detection performance across various domains and object categories.
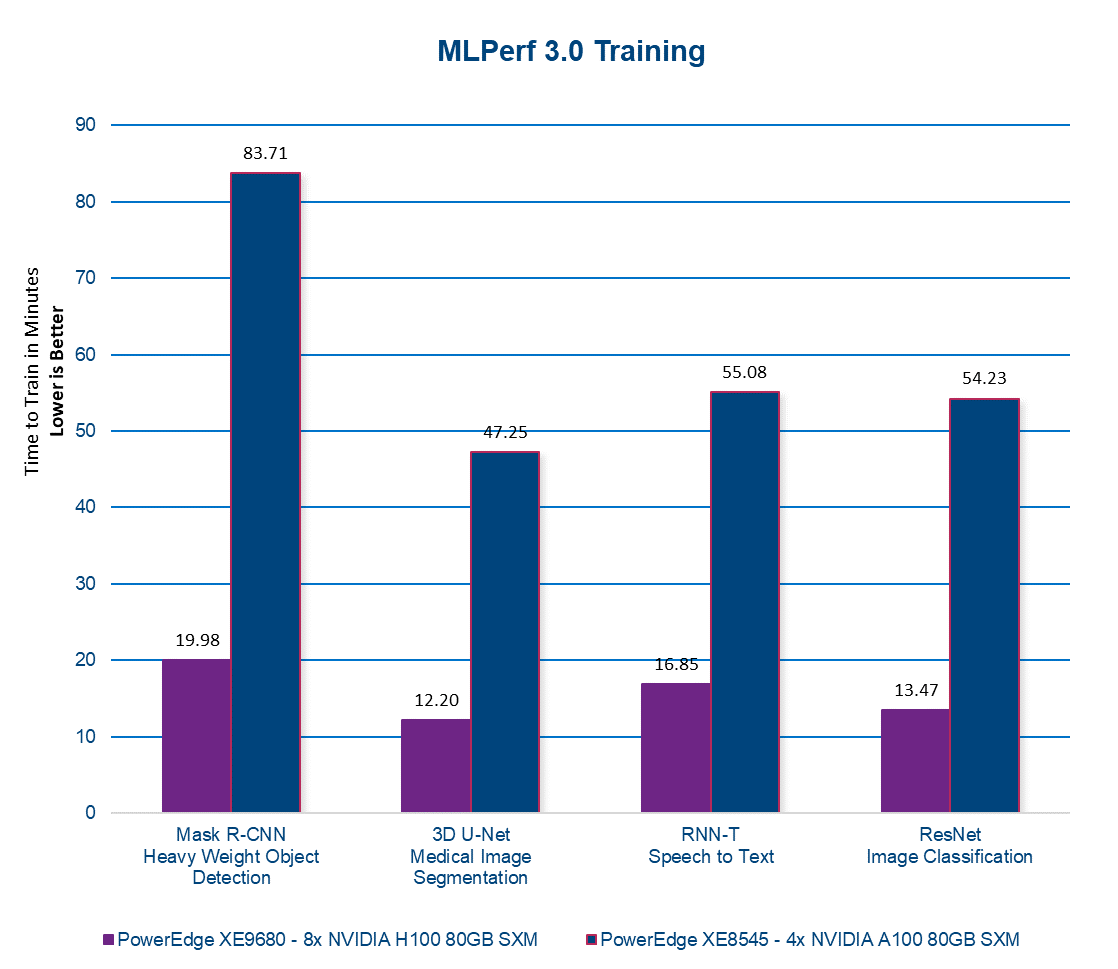
The PowerEdge XE9680 consistently delivers remarkable results across the entire MLPerf 3.0 Training benchmark suite, as depicted in the following figure. This robust performance underscores the server's exceptional capabilities and reliability in tackling a wide range of demanding machine learning tasks.
Conclusion
The PowerEdge XE9680 server surpasses our previous generation offering by delivering up to a 6x performance boost. This remarkable advancement translates into significantly accelerated AI model training, enabling your team to complete training tasks faster. To learn more about this server, we encourage you to contact your dedicated account executive or visit www.dell.com.
Table 1. Server configuration
PowerEdge XE8545 | PowerEdge XE9680 | |
CPU
| 2x AMD EPYC 7763 64-Core Processor | 2x Intel® Xeon® 8470 52-core Processor |
GPU | 4x NVIDIA A100-SXM-80GB (500W) | 8x NVIDIA H100-SXM-80GB (700W) |
- Testing conducted by Dell in June of 2023. Performed on PowerEdge XE9680 with 8x NVIDIA H100 SXM4-80GB and PowerEdge XE8545 with 4x NVIDIA A100-SXM-80GB. MLPerf v3.0 Training results in models BERT Large, Mask R-CNN, ResNet, RetinaNet, RNN-T, and 3D U-Net. The MLPerf name and logo are trademarks of MLCommons Association in the United States and other countries. All rights reserved. Unauthorized use is strictly prohibited. See www.mlcommons.org for more information. Individual results will vary.