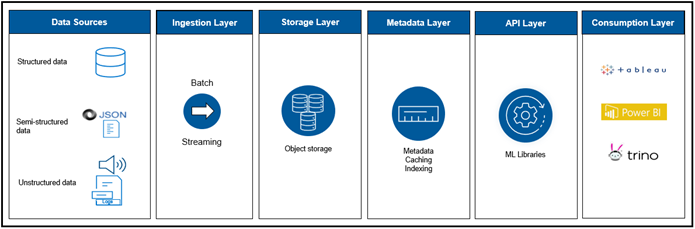
Designing a robust modern data stack requires careful planning and a well-structured architecture. In general, a modern data stack consists of five layers:
- Ingestion layer—This layer pulls data from various sources, including databases, IoT devices, applications, logs, and many more, and deliver it to the storage layer. There are tools to import data from RDBMS and NoSQL databases while streaming data can be imported using Apache Kafka or other open-source tools.
- Storage layer—In a modern data stack design, the storage layer is meant to keep all types of data in inexpensive object storage. This capability enables the client tools to work with these objects directly using open file formats.
- Metadata layer—The foundation of a modern data stack is the metadata layer. Its purpose is to provide a catalog to store metadata of the data and provides a data lineage which tracks data origin and transformation history of the data. This layer makes it possible to implement data management such as ACID compliance, data versioning, caching, indexing, and more.
- API layer—This layer hosts various types of APIs for data analytics. It also hosts machine learning libraries like TensorFlow and Spark MLlib which can read open file formats such as Parquet and query the metadata layer directly.
- Consumption layer—This layer hosts different tools and applications such as Tableau, Power BI, and others to access data stored in the data lake. This layer is where the users perform analytics activities such as running SQL queries, BI, and data visualization.
Modern data stack layers illustrates the layers of a modern data stack.