Comparative evaluation with ML regression methods
Comparative evaluation with ML regression methods
-
Over the last decade, machine-learning based regression methods have been widely deployed in multiple fields for regression and classification tasks. Recent advances in computer architecture have made it possible to train complex machine learning regression models on large datasets. While these regression models have been actively used for fields such as weather forecasting, e-commerce, and finance, not much progress has been made in the performance modeling domain. Malakar et al. [16] performed a detailed study on the efficiency of the machine learning regression methods for performance modeling of scientific applications. They evaluated multiple machine learning regression methods, ranging from simple multi-variate linear regression to instance-based methods such as nearest-neighbor regression [17], kernel-based methods [18], decision tree based methods [19] such as random forests, and, deep learning neural networks. Based on their evaluation on multiple Mantevo [20] HPC benchmarks, they determined that complex ML methods such as bagging, boosting, and Deep Neural Network models performed well while generating accurate performance models for HPC applications.
In this paper, we perform a comparative evaluation of our symbolic regression based approach with these ML regression methods. Based on the work described by Malakar et. al [16], we have selected XGBoost (xgb), random forest (rfr), extremely randomized trees (ert), and Deep Neural Networks (dnn) for memory consumption modeling. For this study, the Python Scikit library package was used to build the ML regression models. Using the MinMaxScaler transformation, normalization on the training data was performed as a part of the data pre-processing. For all the decision tree methods, the default values were used, and the number of trees set to 1000. As with symbolic regression, configuration parameters play a significant role in the model generation process, but a detailed study on the impact of configuration parameters on the model performance is out of scope for this paper. However, for consistency, the configuration parameters were set to default for all the ML regression methods. For Deep Neural Networks, the Keras library was used to build the network that runs on top of Tensorflow. We used a three-layer feed forward network with dropout layers in between. Finally, an Adam optimizer was used and the models were trained for 100 epochs.
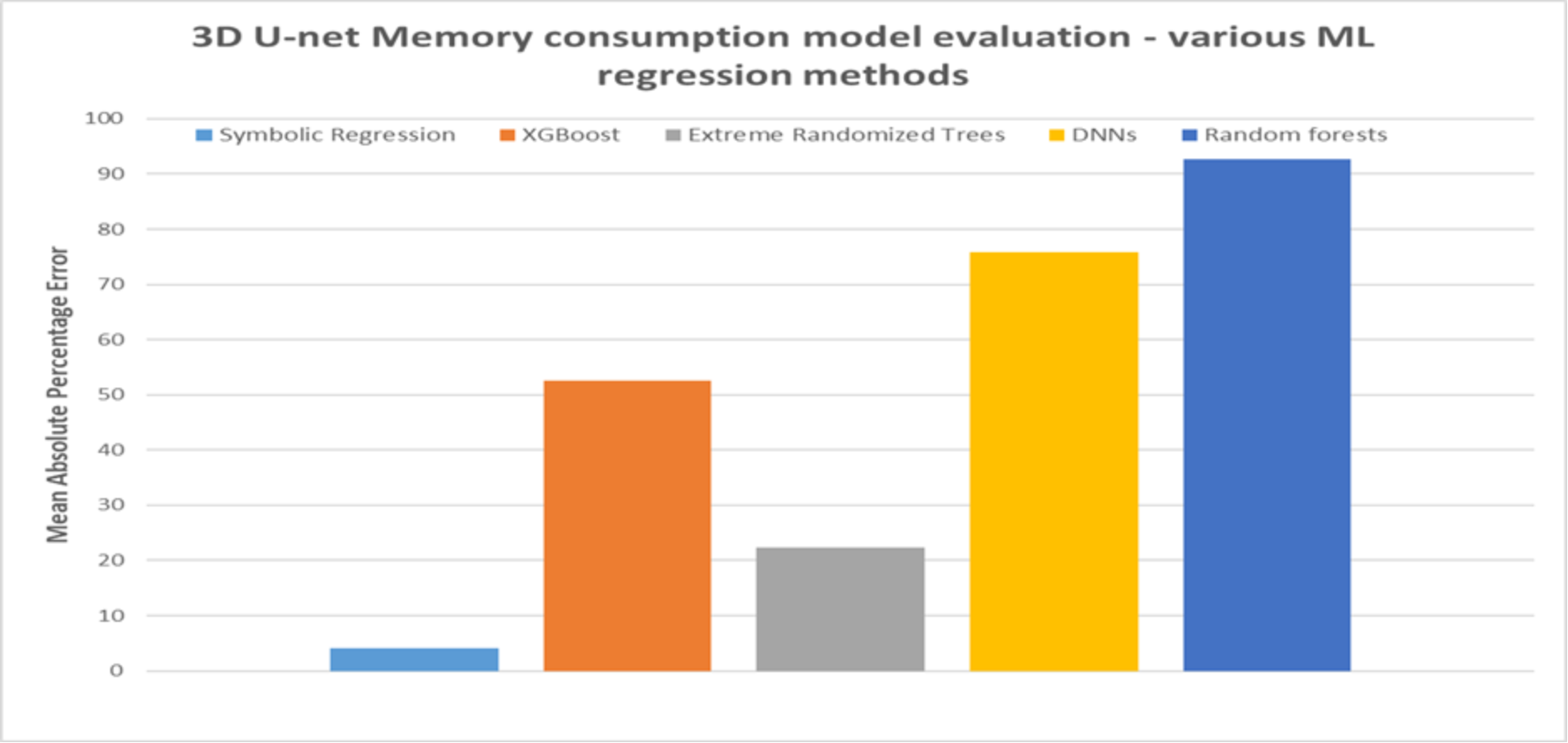
Figure 9 compares the accuracy of the model generated by symbolic regression with the selected ML regression methods. As shown in the figure, the symbolic regression model performed significantly better than the other ML methods using the same performance samples. The symbolic regression model has a MAPE of 4.15%, whereas ert, rfr, xgb, and dnn have a MAPE of 22.35%, 92.75%, 52.56%, and 75.91%, respectively.
Again, the results shown in Figure 9 is based on using the same performance samples for all the modeling methods. If we vary the size and other characteristics of the sampled data, the results may not be the same. Detailed study on the impact of varying different sampling and model parameters on the model performance is outside the scope of this paper. Interested readers are referred to such extensive comparison in our earlier study, the results of which are consistent with the results shown in Figure 9. In that earlier study, we applied the symbolic regression modeling approach to develop performance models for a petascale HPC application called CMT-nek [24] and two HPC mini-apps (Cloverleaf [22] and LULESH [23]) which capture the key computation patterns in many real-world scientific applications. We also showcase the ability of our modeling approach to determine the true function accurately by using a set of synthetic test functions. In our findings, we observed that, in general, symbolic regression performed significantly better than other ML regression techniques for a given number of performance samples. We also varied the size of the performance samples and observed that on average, increasing the performance samples for training improved the model accuracy for the other ML regression methods, but at the cost of longer training time. And, at some point, some of the ML based regression methods may equal or outperform symbolic regression. However, as we stated in Pandora – symbolic regression based modeling tool, one of the three desirable characteristics that are crucial for performance modeling of large-scale systems is feasible model generation time. In general, we observed that with a limited number of performance samples, our symbolic regression-based modeling approach was able to generate the most accurate models.