
Design Guide—Virtualized Computer Vision for Smart Transportation with Genetec
Performance results and findings
Performance results and findings
-
Genetec performance tests
Archiver performance tests
- Test specification
-
- 4 vCPU
- 16 GB Memory
- 1 - 200 GB local vSAN disk
- 1 - 60 TB remote PowerScale drive for video archiving
- 1 - 10 Gb Network card
The data for one of the Archivers under load with 75 cameras is shown below:
Figure 6. Archiver under load with 75 cameras 
- Findings
-
- Archivers processing 75 cameras have total bandwidth consumption below the 300 Mb/s threshold. The average is ~32,500 KB/s or 260 Mb/s.
- CPU utilization is not a concern at less than 25%
- Memory utilization is not a concern at 50%
- Overall
- The Archivers are processing the video recording workload up to the design limits without showing signs of resource exhaustion.
Aggregate Archiver test for a VxRail node
- Test specification
-
- Validate that 3 Archivers can run on a single VxRail host without exceeding the 1200 Mb/s limit threshold set by Genetec.
- Stream 225 Cameras at 3.7 Mb/s to a single VxRail node and collect performance metrics for design validation.
The test VxRail Host contained 3 Genetec Archivers:
- genetec-rec-1
- genetec-rec-4
- genetec-rec-5
Figure 7. VxRail host with 3 Genetec Archivers 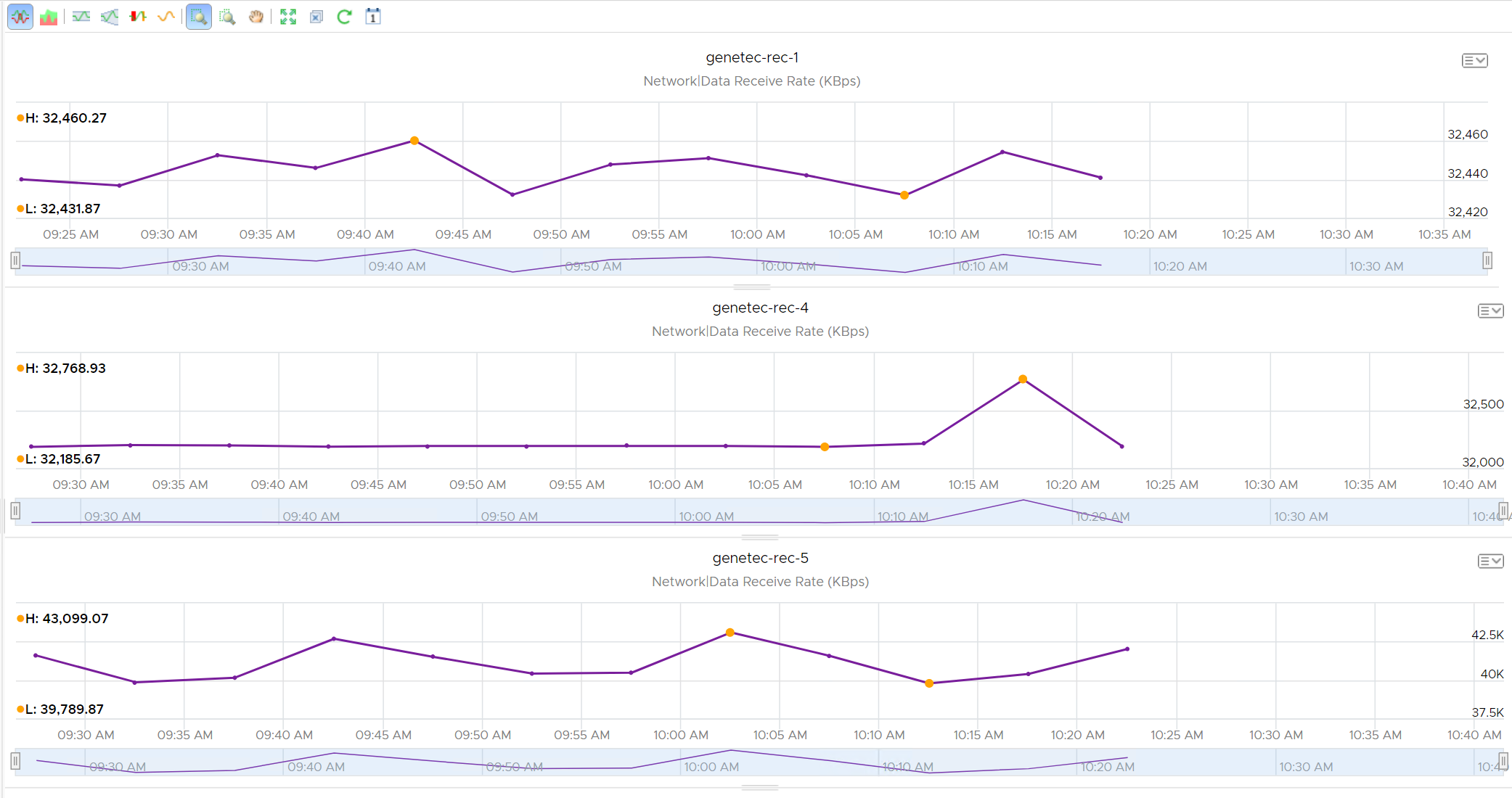
- Findings
-
- The maximum total inbound camera stream bandwidth consumed was 108,327 KB/s or 866 Mb/s, below the 1200 Mb/s limit.
- Overall
-
The CV testing can proceed with this Genetec design.
BriefCam performance tests
Our performance testing in support of the recommendation in this Design Guide was focused on the BriefCam RESPOND real-time analytics feature (Alert Processing Service). The integration between the RESPOND functionality and the Genetec VMS uses the Real-Time Streaming Protocol (RTSP) interface to access video streams with the lowest latency possible.
A real-time task processing request goes through several preprocessing steps before being able to generate alerts. The BriefCam RESPOND user interface allows operators to monitor the status of real-time tasks to track how many are queued, recovering (between the queued and processing state), and actively processing alerts. We tested performance by adding requests for new real-time alert processing tasks until we began to detect queued requests increasing but were not able to change state to processing.
- Test specification
-
- Determine the maximum number of real-time alert processing tasks that can be supported by a single VM with a full Nvidia A40 vGPU.
- Determine the maximum number of real-time alert processing tasks that can be supported by a 3-node active/active cluster of BriefCam Alert Processing servers that are hosted on virtual machines each with a full Nvidia A40 vGPU.
- Use a combination of CV face recognition (60) and restricted area/person detection (40) workloads and collect performance metrics.
Single VM test results
We tested both the maximum numbers of a single-use case workload stream (face recognition or person detection in a restricted zone) plus various mixtures of the workload specifications. In all tests, the results were consistent. In this test, five cameras were added every 3 to 4 minutes until we began to see that new streams were remaining in a queued state.
The total CPU and GPU Utilization in the build-up to processing for 30 Face Recognition Cameras are as follows:
Figure 8. CPU and GPU Utilization for 30 Face Recognition Cameras 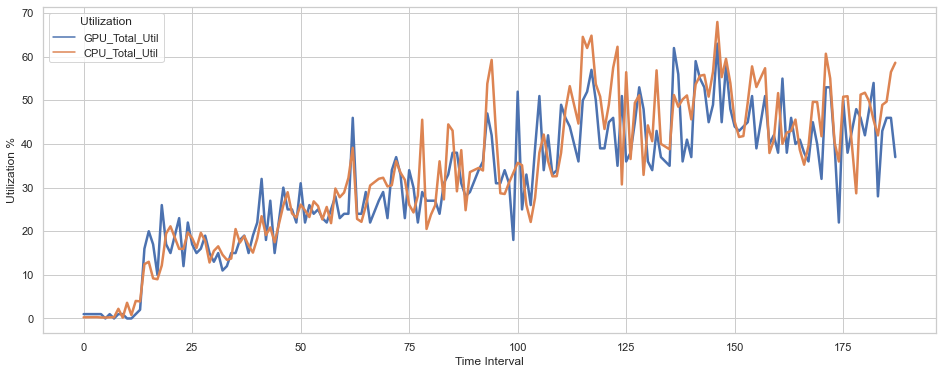
Detailed GPU utilization metrics are shown below:
Figure 9. Detailed GPU utilization metrics 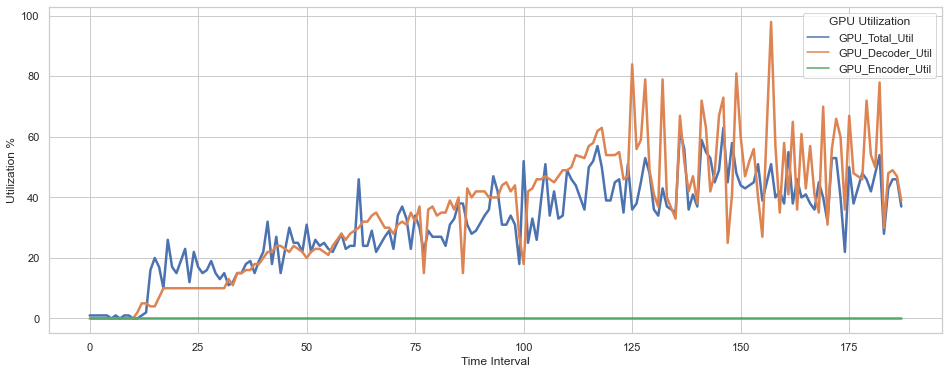
The green line in the above chart indicates that there is a problem with data collection for the % utilization of the A40 hardware encoder. The counter was available in our monitoring tool, however, we only received zero values although we know this is an important GPU feature for CV applications. Upgrading to the latest vGPU bundle from Nvidia and VMware is expected to resolve this issue.
VM cluster test results
The BriefCam Alert Processing Service can function as a scale-out active/active cluster by installing and configuring multiple instances of the service that run on different servers. When multiple service instances are available, a cluster mesh service detects how many service instances are running and on what machines. When new real-time alert processing tasks are requested, the request is queued using the PostgreSQL database. The service mesh then assigns tasks from the queue to available servers that are running the alert processing service.
We configured 3 VMs running the BriefCam server components to process real-time alerts. Our goal was to compare the total number of streams that could be processed with a 3-node cluster compared with the single VM results. The maximum number of streams for the cluster was 95 before new requests started to build up in the queue.
- Findings
-
- The maximum number of real-time alert processing tasks was 30 for a single node. We also validated that this result was consistent across the 3 VxRail nodes that were allocated for CV application hosting.
- The CPUs utilization closely follows the GPU utilization and was not the bottleneck. The test used 16 vCPUs running at 3 GHz.
- The GPU utilization was at ~55% but the GPU Hardware Decoder was spiking to 100% and no further-incoming video streams were accepted.
- The GPU Encoder metrics were not returned by the Nvidia driver. Upgrading to the latest vGPU release may resolve this.
- Overall
- A maximum of 30 cameras can be achieved per node with BriefCam, but it is recommended to size for 25 Cameras per node to ensure the system is not running at 100% all the time.
Ipsotek performance tests
The Ipsotek testing that was performed contained a mixture of Face Recognition and Object Detection scenarios. The Ipsotek platform support multiple tracking modes that can be configured for a camera:
- Video Analytics: Traditional pixel-based analytics.
- AI - Normal: AI based tracking of full people. This was used for Object detection tests.
- AI - Crowded: AI based tracking for crowded scenes where head and shoulders are tracked.
- Face Detection: Focus on detecting faces. This was used for Face Recognition tests.
A "Face in Watchlist" rule was created to report for people on a watchlist and used for all Face Detection cameras. An "In Zone" rule was created to detect people entering a restricted zone.
Ipsotek uses the Nvidia GPU encoder to reencode the video received from different cameras and generate synchronized video with I-Frames produced every second at a fixed bit rate.
This allows Ipsotek to:
- Estimate storage requirements based on retention policy.
- Access video and images on disk to an exact second without needing to seek in mp4 segments.
- Stream video over HLS protocol with minimum buffering time of 2 s to be viewed on web interface.
- Ensure that we get a low latency user experience when an operator is requesting to random access images and video on disk.
- Test specification
-
- Determine the maximum number of real-time alert processing tasks that can be supported by a single VM with a full Nvidia A40 vGPU.
- Determine the maximum number of real-time alert processing tasks that can be supported by a 3-node active/active cluster of Ipsotek Processing servers hosted on virtual machines each with a full Nvidia A40 vGPU.
- Use a combination of 45 face recognition and 45 restricted area/person detection workloads and collect performance metrics. In particular, focus on GPU Encoder and Decoder usage.
Single VM test results
We tested both the maximum numbers of a single-use case workload stream (face recognition vs person detection in a restricted zone) plus various mixtures of the workload specifications. In all tests, the results were consistent. Cameras were added 5 at a time until the max of 30 cameras were active.
The total CPU and GPU Utilization in the build-up to processing for 30 Face Recognition Cameras are as follows:
Figure 10. CPU and GPU Utilization for 30 Face Recognition Cameras 
The breakdown of GPU utilization is as follows:
Figure 11. GPU utilization 
VM cluster test results
The Ipsotek platform does not currently support vGPUs, so all GPU resources must be assigned to the VM as a passthrough device. This means that it is not possible to migrate VMs as was shown in High availability validation. To build a viable Ipsotek cluster in a virtualized environment, it is necessary to provision all Ipsotek Processing nodes at system setup time. The goal is then to load the system so that sufficient capacity exists across the cluster to ensure that during a failover the cameras can migrate to an available node and continue processing.
In this testing, the approach was to load three of the four nodes in the cluster to their maximum. This ensures that there is sufficient capacity to disperse the workload across the cluster in a failure scenario. A total of 45 Face Recognition Cameras and 45 Object detection cameras were enabled.
The maximum count of active cameras across three processing nodes was 86.
- Findings
-
- The maximum number of real-time alert processing tasks was 30 for a single node. We also validated that this result was consistent across the three VxRail nodes that were allocated for CV application hosting.
- The CPU was ~30% when all cameras were processing so 8 CPUs per Ipsotek processing node is sufficient.
- When 30 cameras were enabled on a single node, the GPU utilization was at ~50% but the GPU Hardware Encoder reached 100% and no further-incoming video streams were accepted.
- Overall
- A maximum of 30 cameras can be achieved with Ipsotek on a single node, but it is recommended to size for 25 Cameras per node to ensure the system is not running at 100% all the time.
Full system performance tests
The purpose of this test was to validate if a combination of three applications from three different vendors can share a common platform using VxRail and VMware without introducing processing delays. We have the individual application results from above for our baseline. Our performance data for this test was collected while the following workloads were processed in parallel.
- A total of 675 cameras are being recorded in Genetec.
- 75 BriefCam real-time alert processing tasks analyzing camera streams from the Genetec Real-Time Streaming Protocol (RTSP).
- 75 Ipsotek face recognition and object detection tasks analyzing camera streams from Genetec.
Overall cluster performance results
The following chart shows the relative utilization of each host in the cluster while the system was processing the full load of 675 cameras streams, 150 of which were running real-time analytics.
Figure 12. Resource usage by host 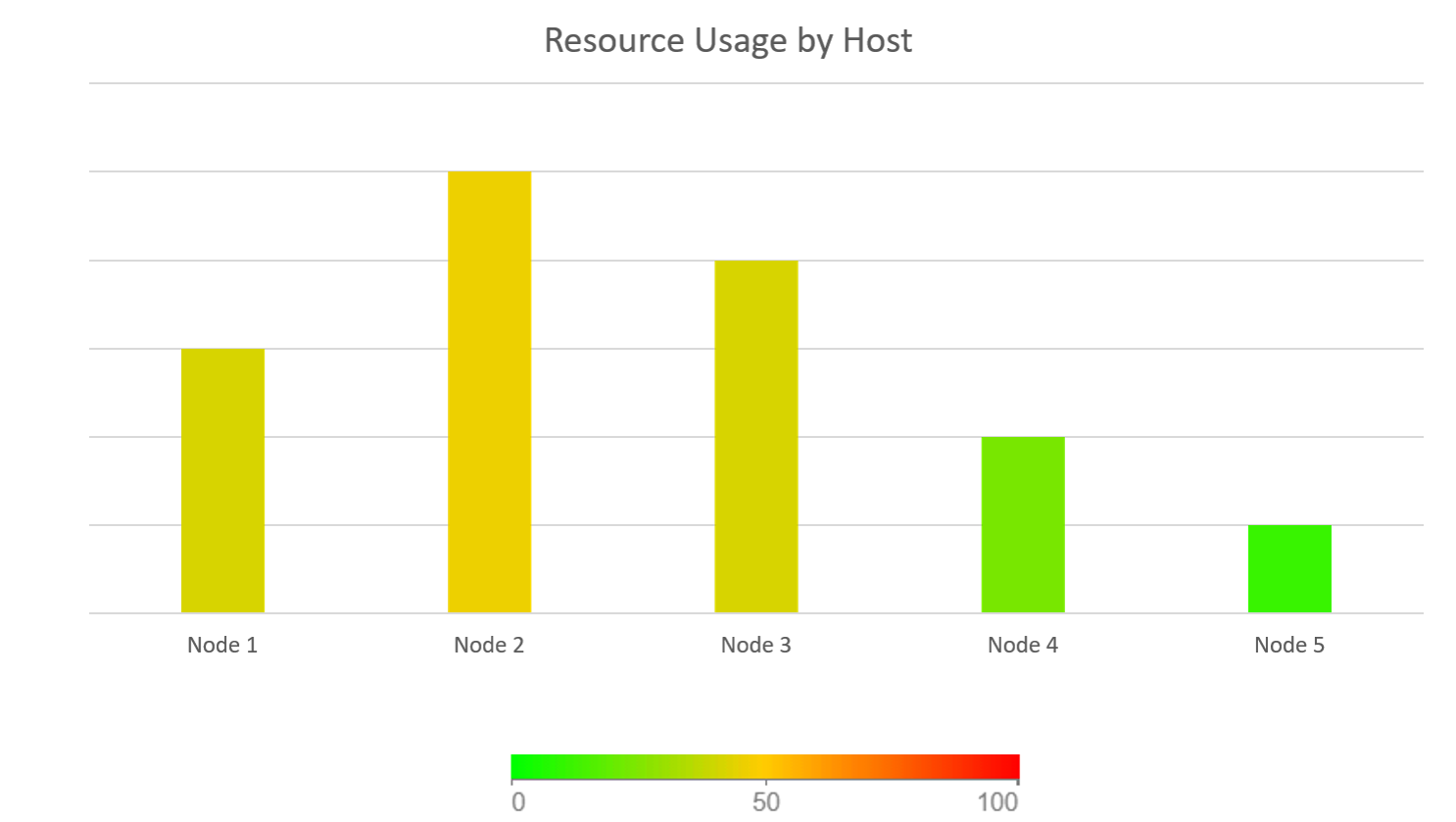
- Findings
-
- Processing 675 cameras with a 4-node system works without issues.
- The required Management VMs do not cause performance problems.
- The active nodes 1-3 are at ~50% CPU/Memory utilization.
- Node 4 is less active since this was used for failover testing.
- Node 5 was held in reserve and in maintenance mode for this test.
VM level view
When the system was under full load, a snapshot was taken of the utilization of the VMs running across the VxRail cluster.
Figure 13. Child VMs distribution by CPU, Memory, and Latency 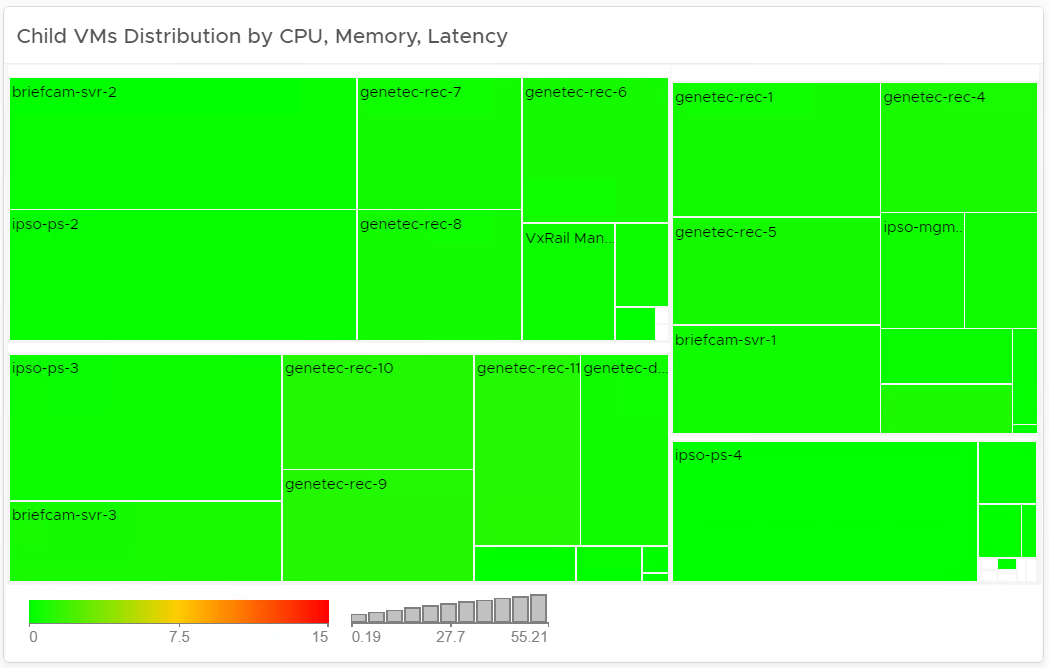
- Findings
-
- No VM in the system was considered a performance risk.